-
-

Drishti overview
-
Drishti Relief directions and compliance
-
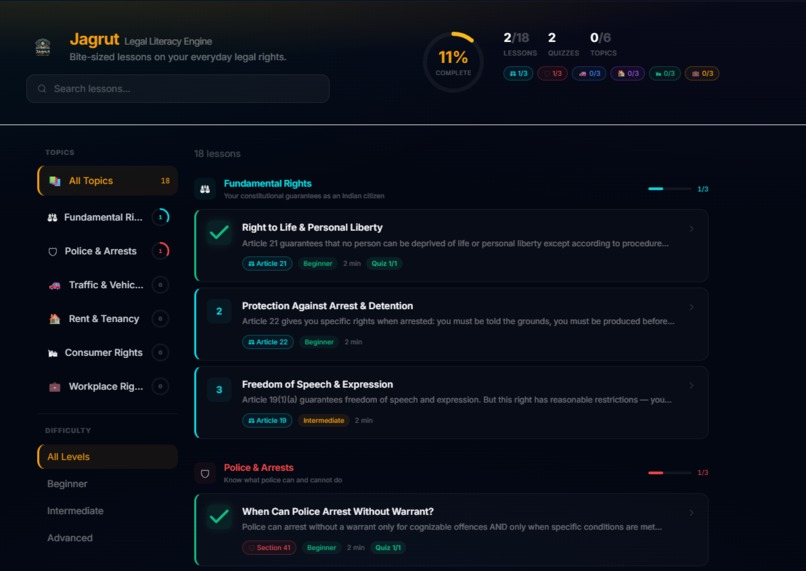
Jagrut Quiz
-
Drishti Timeline
-
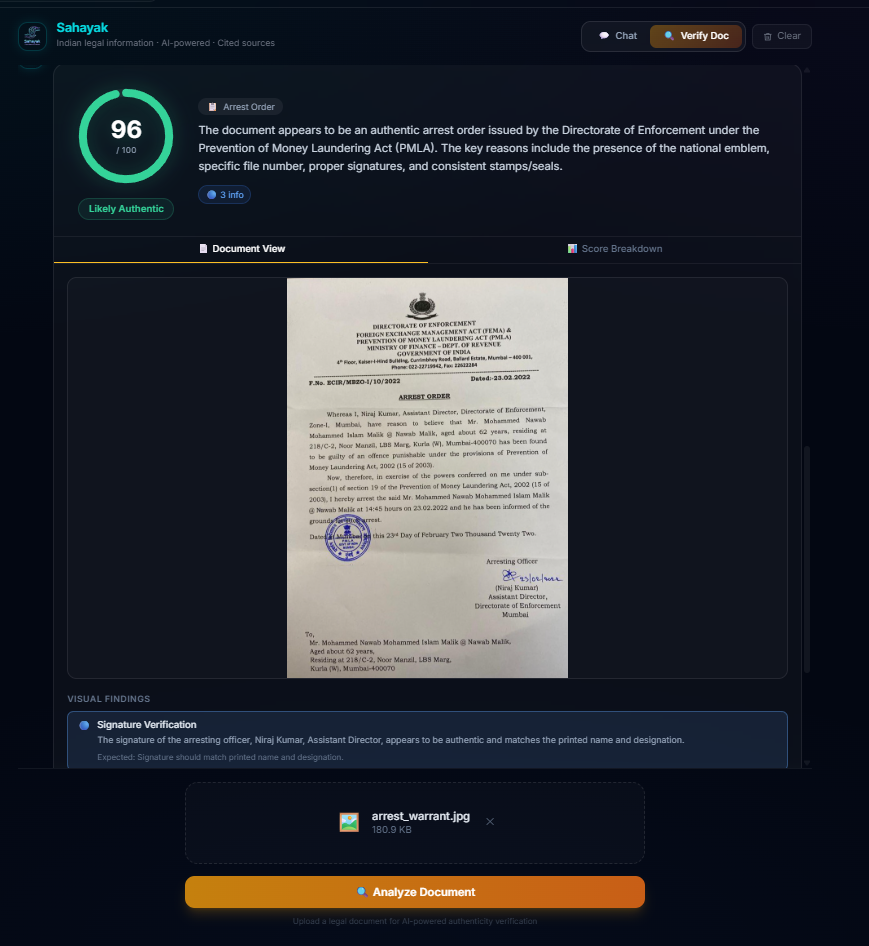
Sahayak doc verify fake notice
-

Jargrut Content
-
Drishti Precedent Graph
-
Drishti Argument Duel
-
NyayaSetu Homepage
-
Know your Rights card preview
-
Jagrut Module Overview
-
Know your Rights card overview
-
Drishti Module Analysis
-
Sahayak doc verify legitimate warrant
-
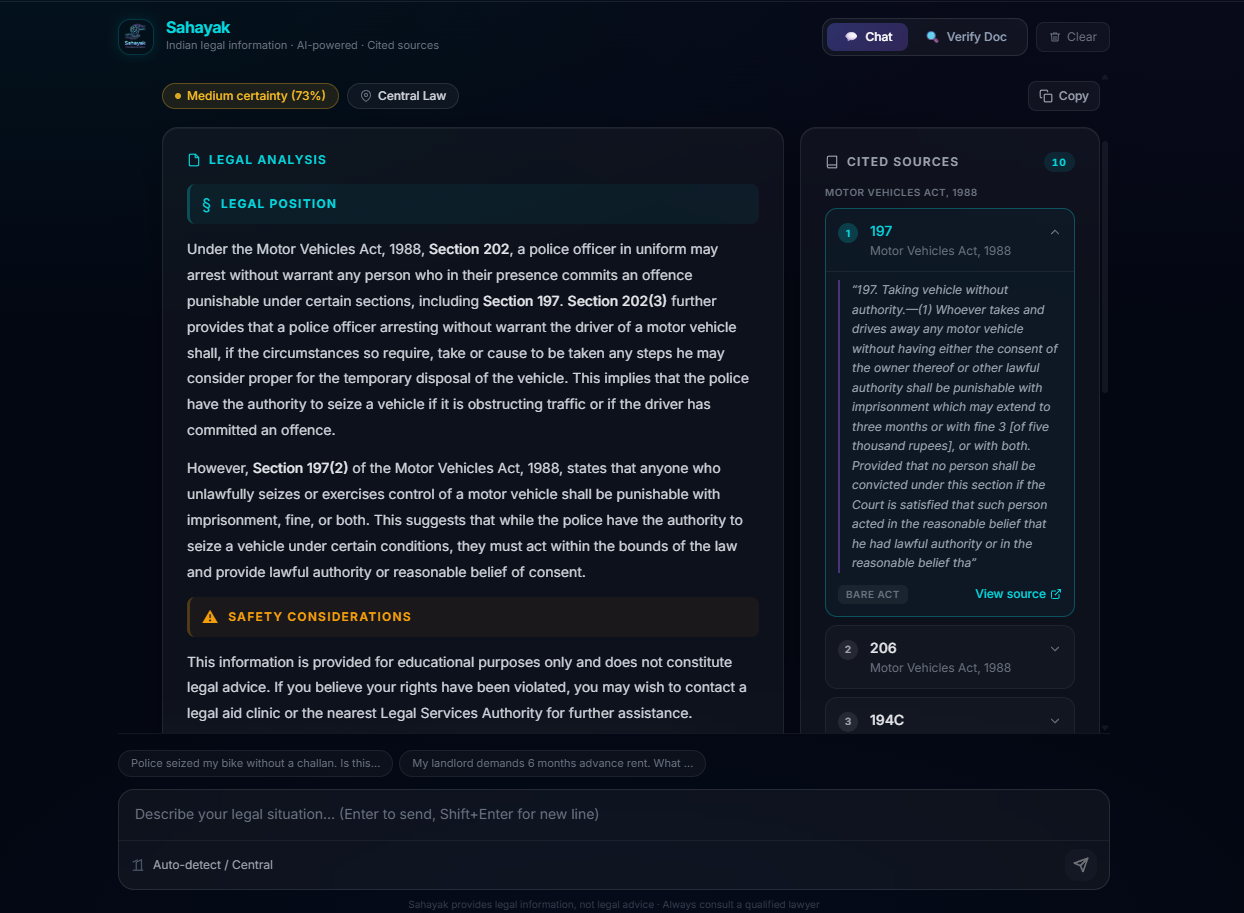
Sahayak Answer preview


Inspiration
It started with a road trip gone wrong. While traveling from West Bengal to Jharkhand in a rental cab, we were stopped and ran into issues over vehicle documentation permits, registration papers, inter-state transit rules. We didn't know our rights. We didn't know what documents the driver was legally required to carry. We didn't know if the authorities were acting within their jurisdiction or overstepping. And we had no way to quickly find out.
That experience sent me down a rabbit hole. I started researching legal literacy in India and discovered a staggering gap: India is the world's largest democracy with 1.4 billion citizens, yet most people have no practical understanding of the laws that govern their daily lives. Fake legal notices are rampant loan recovery agents routinely send fabricated "court orders" with pasted government emblems to terrorize people into paying. Citizens get intimidated by police because they don't know their rights during traffic stops, arrests, or property disputes. The law exists to protect people, but it can't protect anyone who doesn't know it exists.
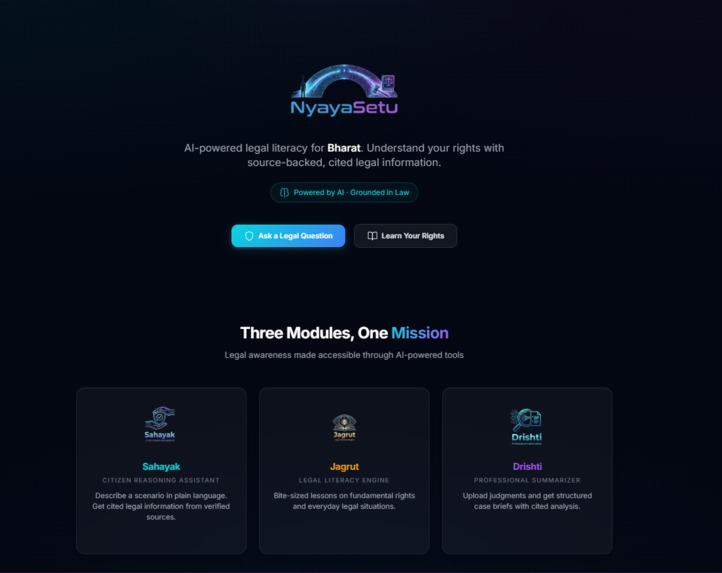
NyayaSetu — literally "Bridge to Justice" in Hindi was born from that frustration.
What it does
NyayaSetu is an AI-powered legal literacy platform with four specialized modules:
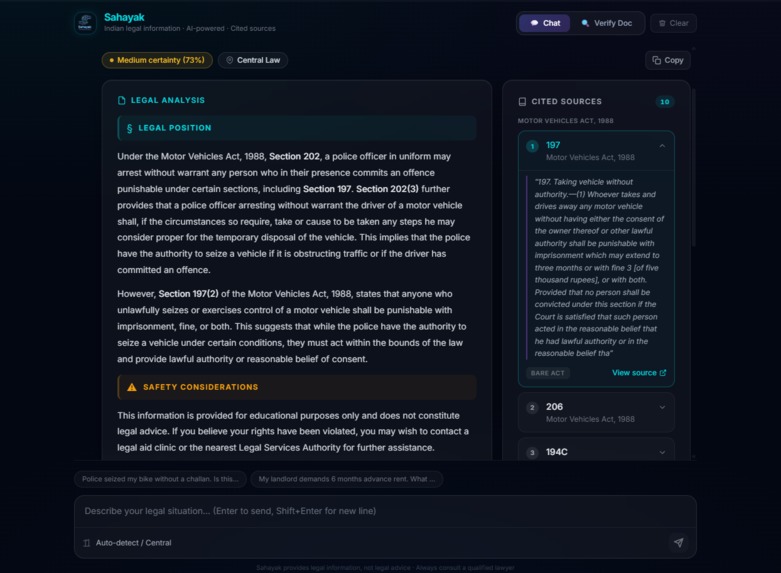
Sahayak (Helper): Ask any legal question in plain language. Describe your situation, "Police seized my bike without giving a challan, is this legal?" and Sahayak identifies the relevant jurisdiction, retrieves applicable laws from its knowledge base, and explains the legal position with citations to specific sections and Acts. It never gives advice. It tells you what the law says, cites exactly where, and lets you decide.
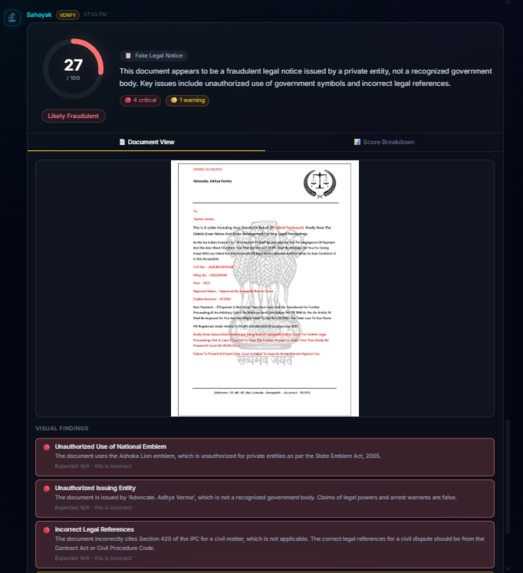
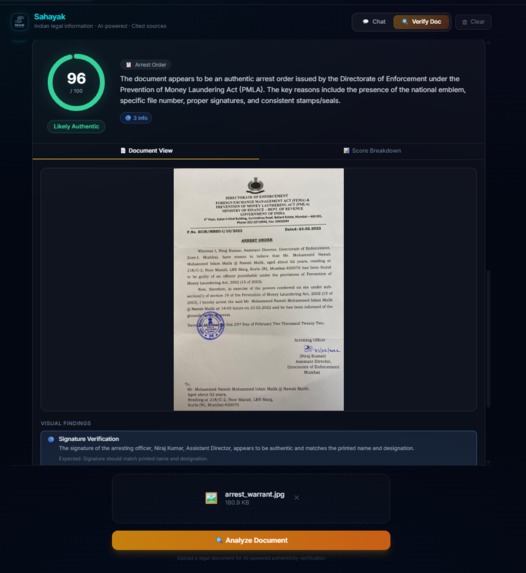
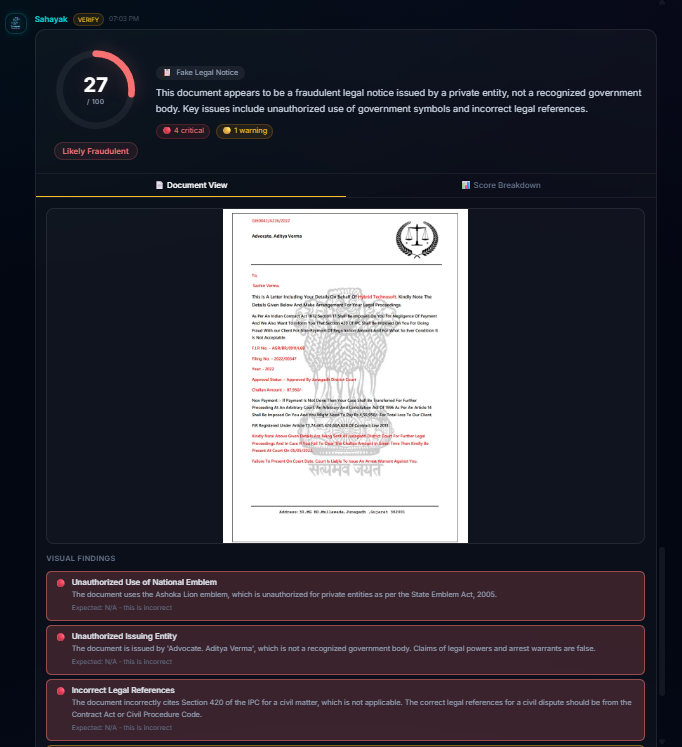
Sahayak Verify: Upload any legal document (PDF, image, or DOCX) and get an instant authenticity analysis. The system examines formatting, language, dates, signatures, legal references, metadata, and internal consistency across 7 categories. It knows the difference between a real Directorate of Enforcement arrest order (where the national emblem is expected) and a fake loan recovery scam (where the emblem is unauthorized). Suspicious text is highlighted inline with severity-coded colors, and a forensic score breakdown shows exactly what raised red flags.
Jagrut (Awakened) - Two sub-modules for legal education:
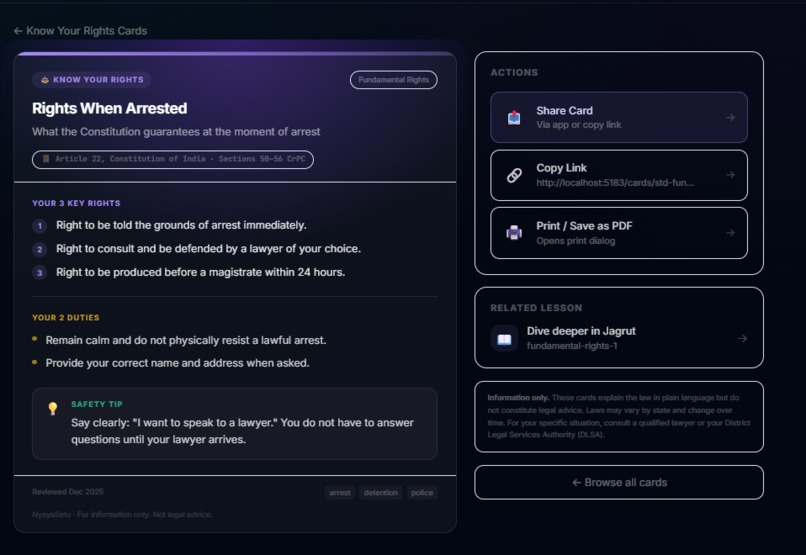
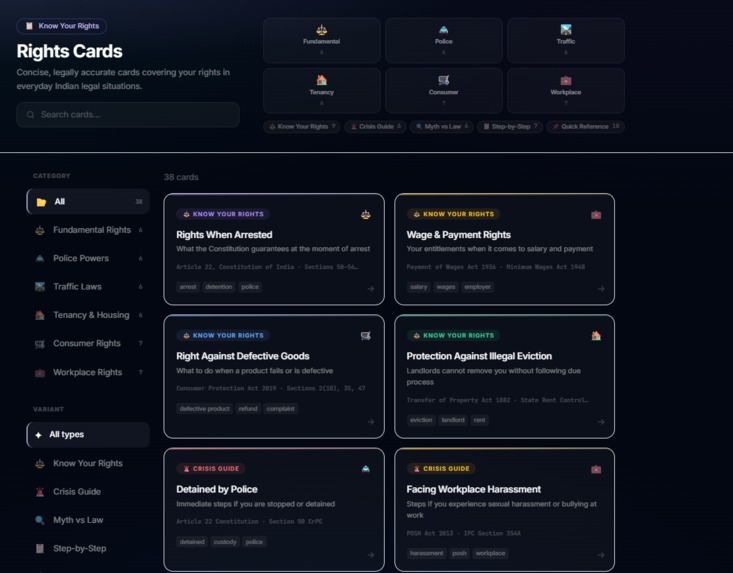
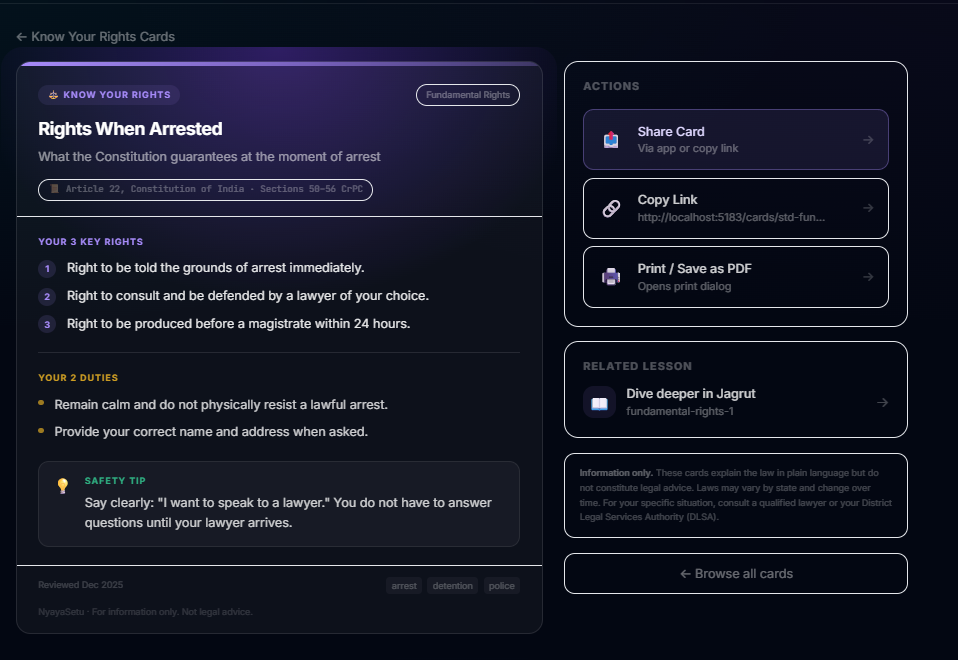
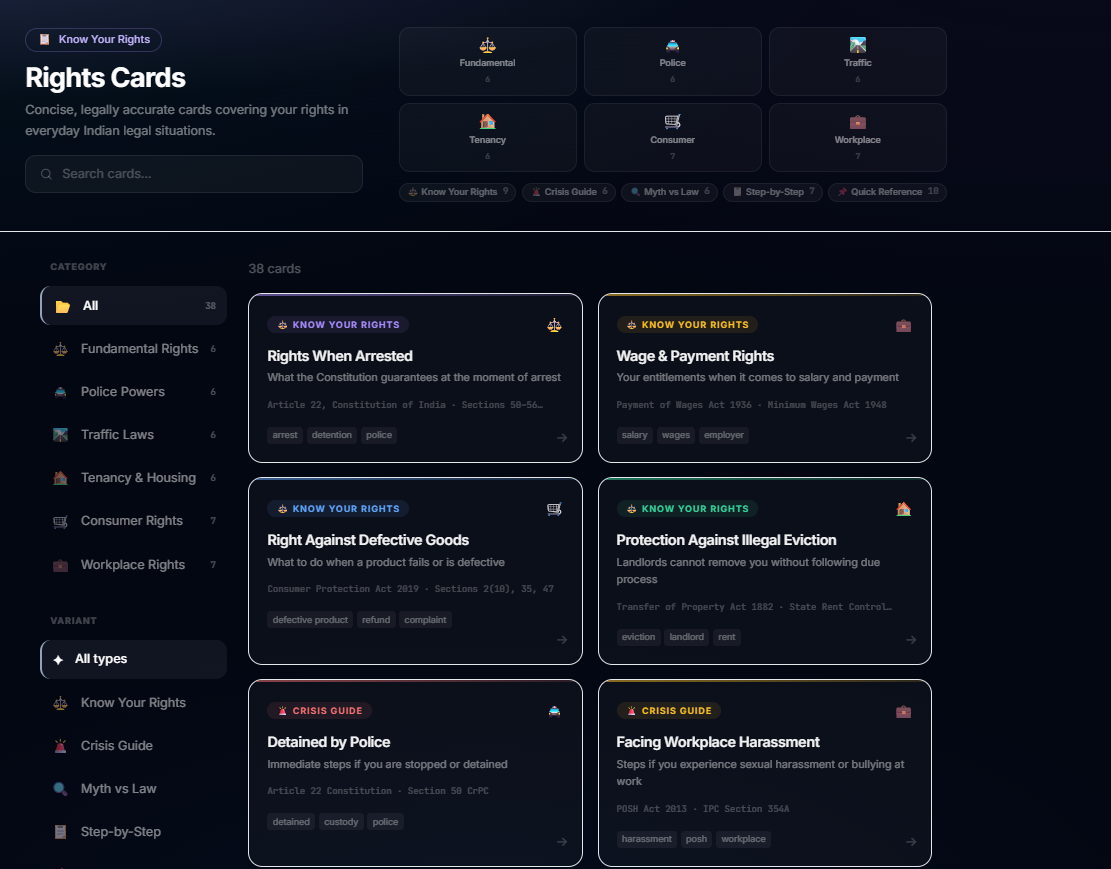
- Know Your Rights: Printable, shareable cards covering Rights When Arrested, Tenant Protections, Consumer Rights, Worker Safety, and more. Each card distills complex law into numbered rights, duties, and a safety tip.
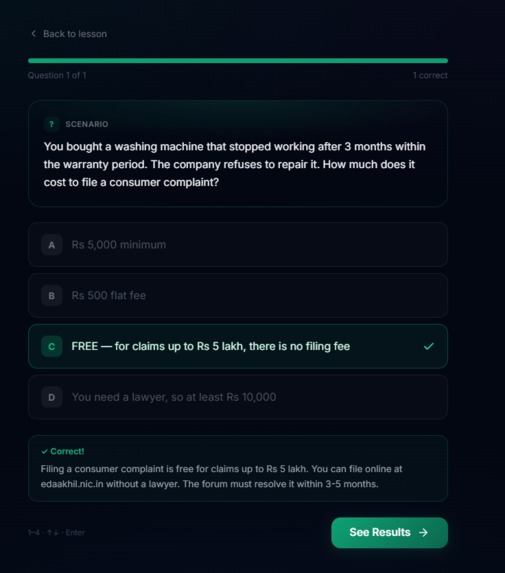
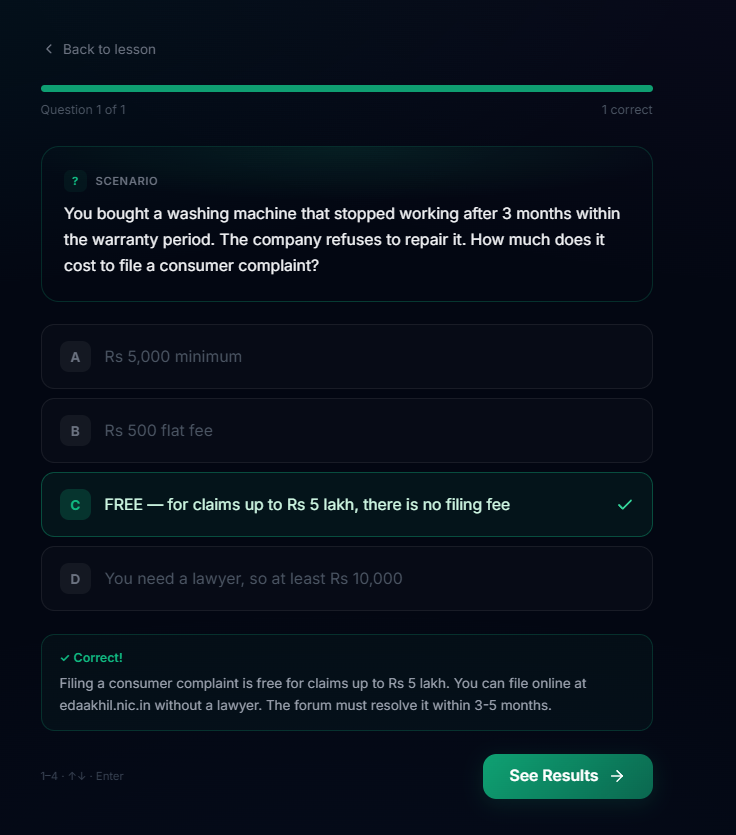
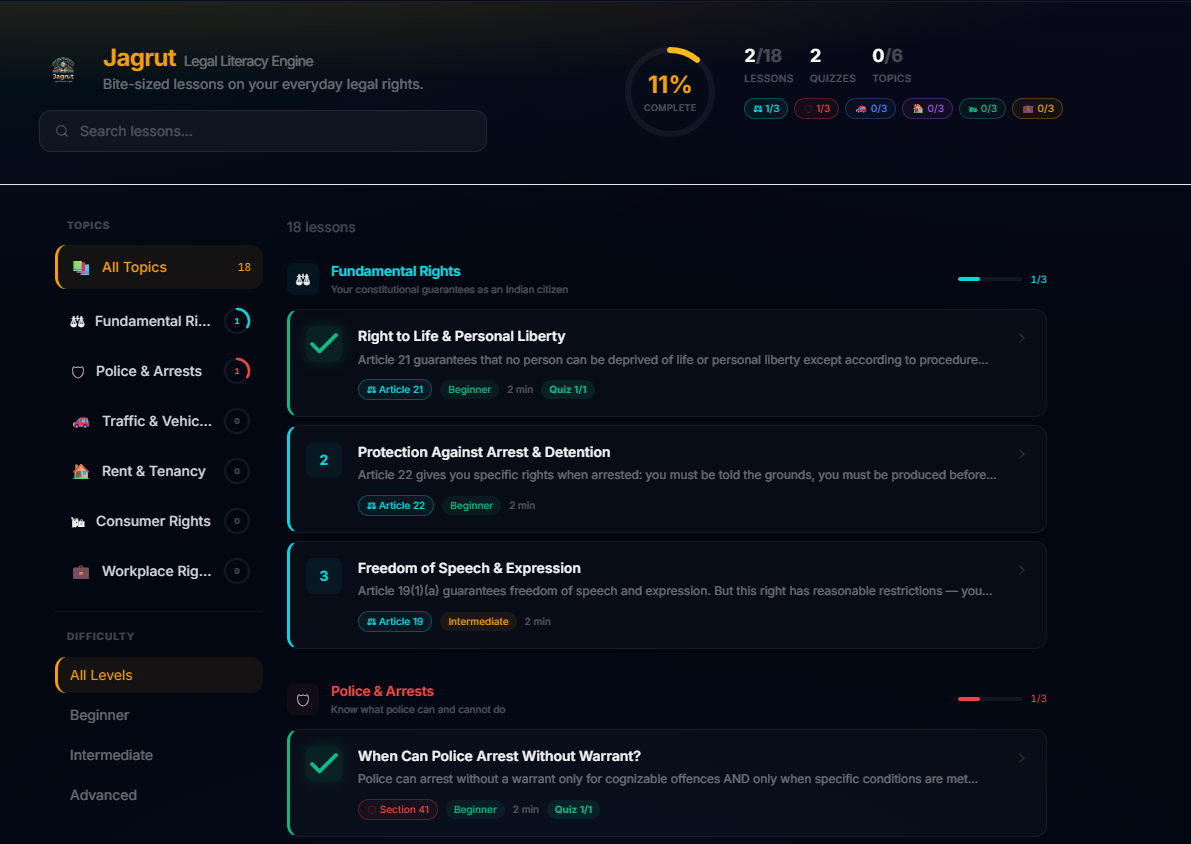
- Learn the Law: Structured micro-learning modules covering Fundamental Rights, Police Powers, Traffic Laws, Tenancy, Consumer Rights, and Workplace Rights. Each lesson teaches a concept in plain language, followed by quizzes. Progress is tracked across categories and difficulty levels.
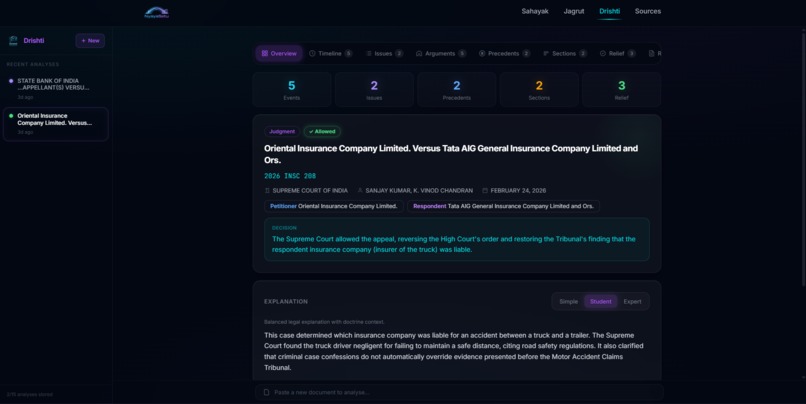
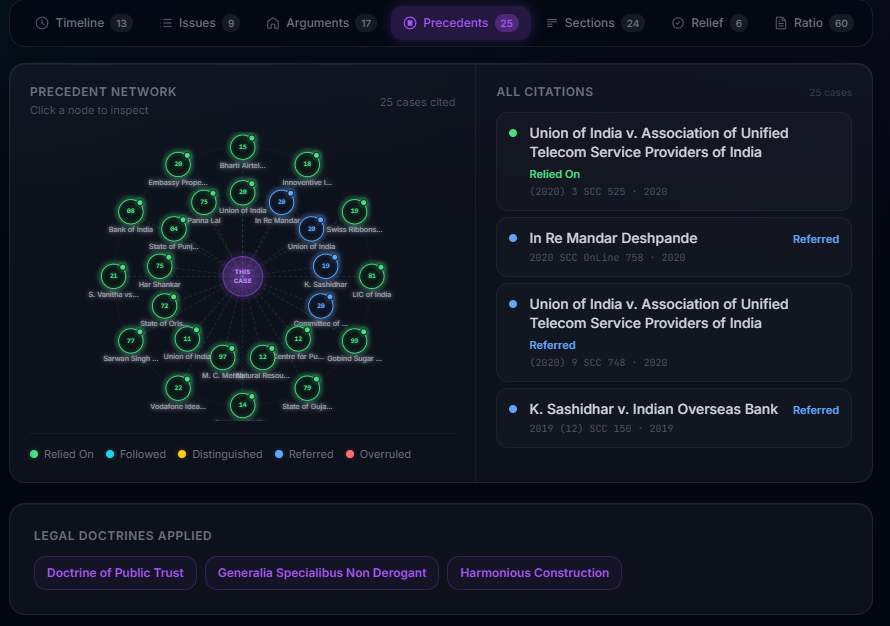
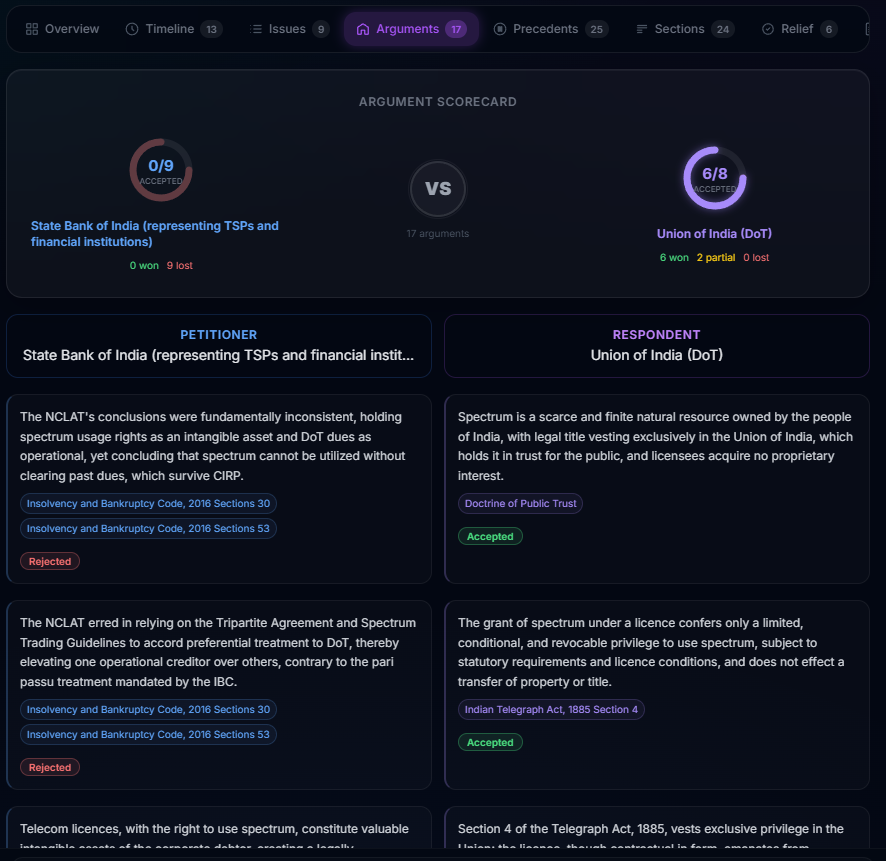
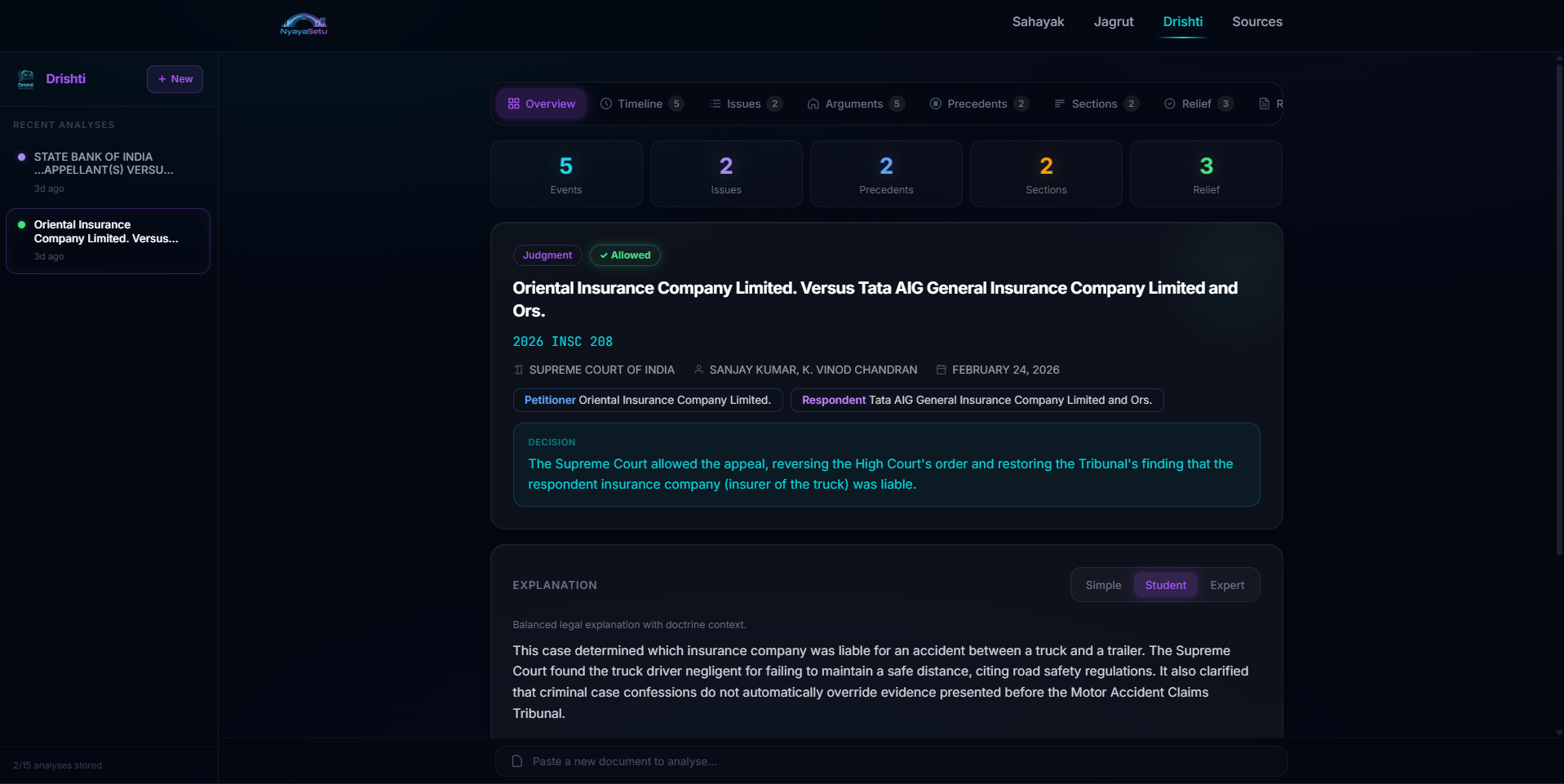
Drishti (Vision) - A professional-grade document intelligence engine for lawyers, law students, and researchers. Upload any court judgment, FIR, or legal document and get a comprehensive AI analysis across 8 interactive visualization tabs:
- Overview - Case metadata, one-line decision, three-level explanations (teenager → student → practitioner), facts in brief
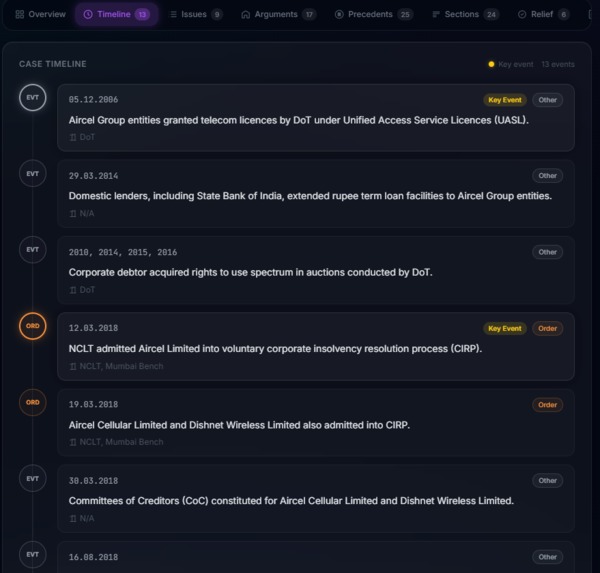
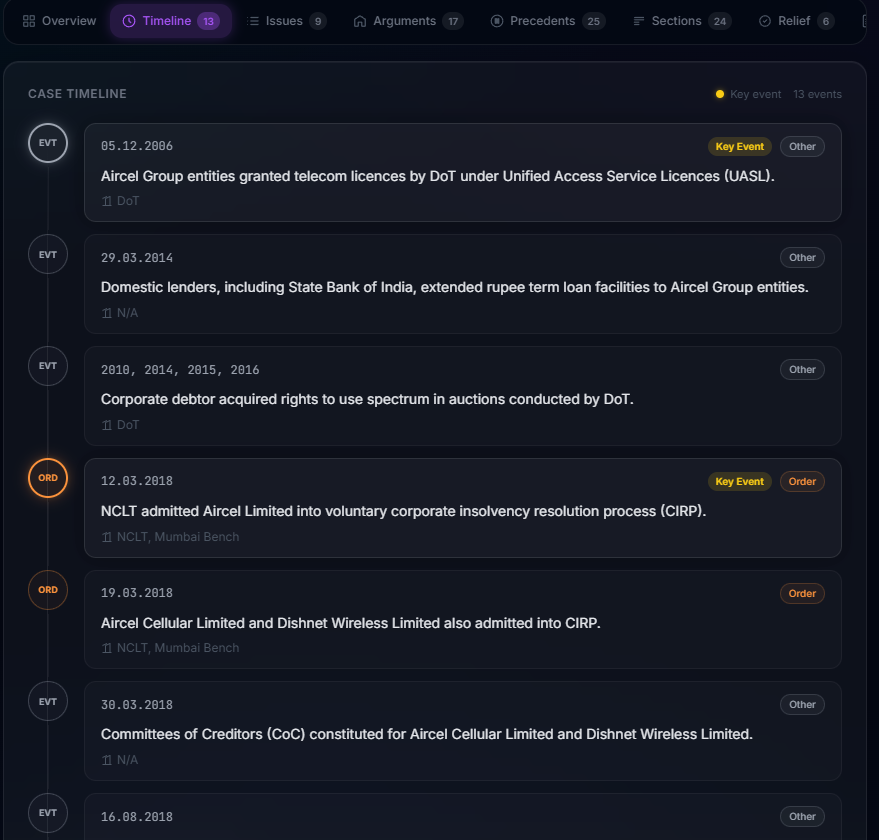
- Timeline - Chronological event visualization with color-coded nodes (filing, hearing, order, judgment, stay, remand, appeal)
- Issue Tree - Hierarchical legal questions with petitioner arguments, respondent arguments, court findings, and applied law at each node
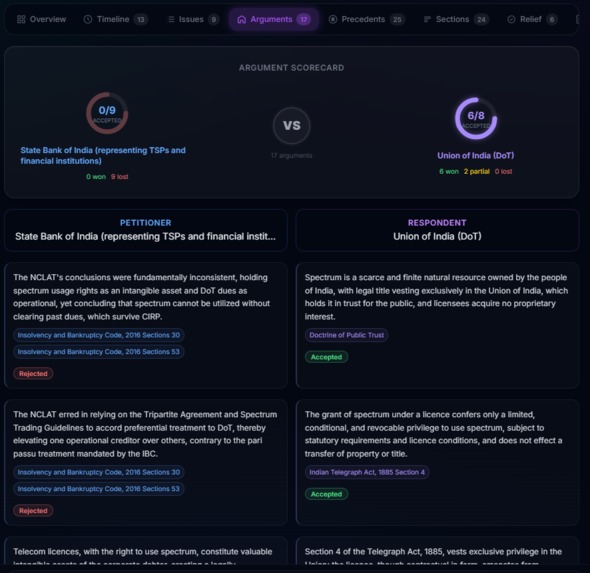
- Argument Duel - Side-by-side scorecard with circular progress arcs showing accepted/partial/rejected arguments for each party
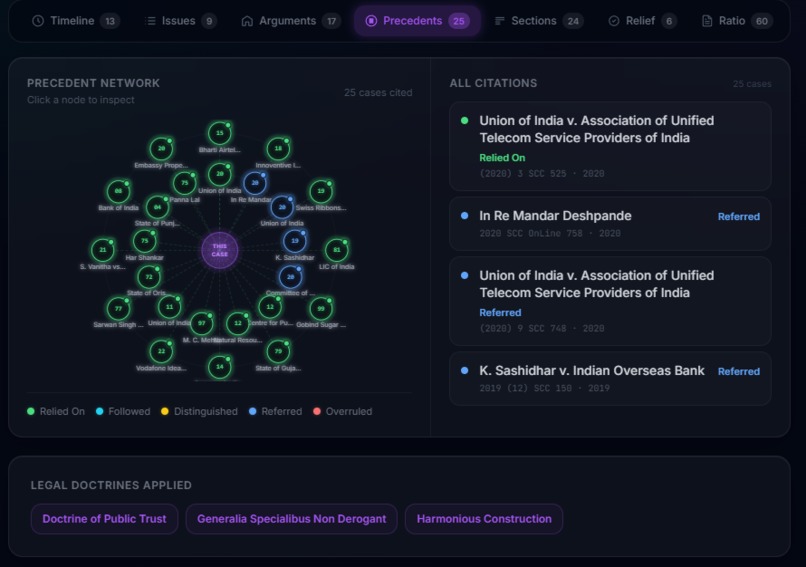
- Precedents - Radial citation graph showing relied-on, distinguished, overruled, and followed cases with relevance notes
- Section Heatmap - Statute analysis showing mention frequency, centrality scores, and role classification (holding, ratio, obiter, background)
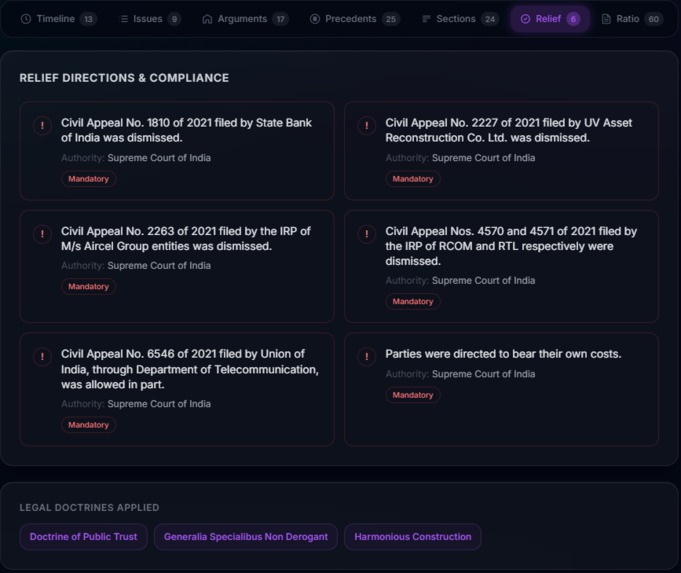
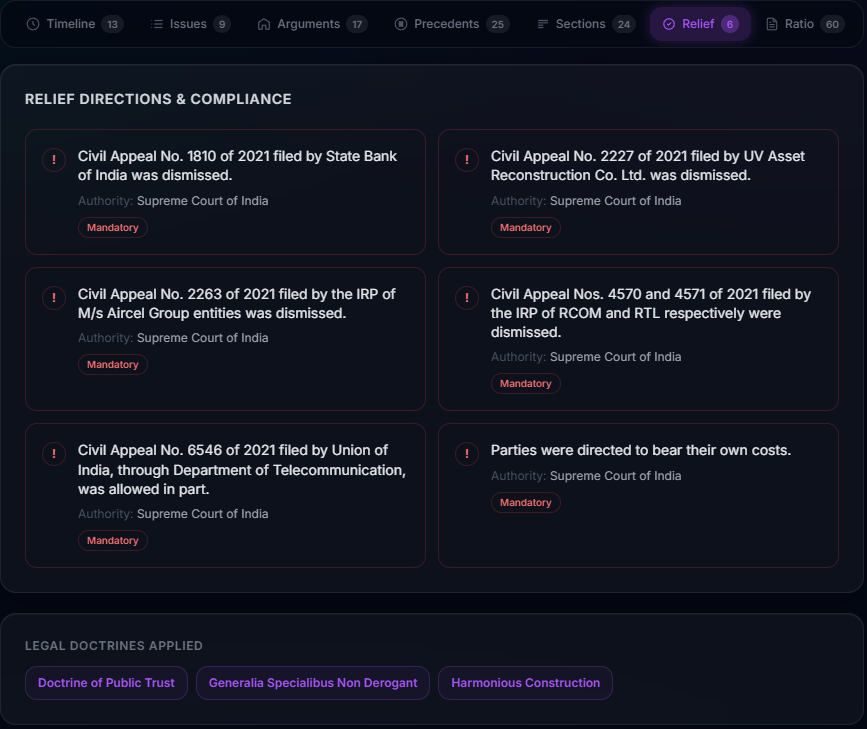
- Relief Tracker - Compliance checklist of court directions with authority, deadline, and enforcement type
- Ratio & Obiter - Tagged paragraph extraction separating binding precedent from commentary, with citation cross-references
Drishti extracts 50+ structured fields from a single document in under 20 seconds. Analyses are stored in user history and can be shared via encrypted links - public or password-protected - so lawyers can send case briefs to clients, students can share with study groups, and researchers can reference specific analyses with a permalink.
How we built it
Architecture: TypeScript monorepo (Turborepo + pnpm) with a React 19 + Vite frontend and Fastify 5 backend. Six shared packages handle domain logic independently these are types, RAG, jurisdiction, safety, prompts, and data preparation.
AI Stack: Amazon Nova Lite via AWS Bedrock powers all LLM tasks. Nova Multimodal Embeddings (1024-dim) drive the vector search. ChromaDB stores legal text embeddings locally, with Bedrock Knowledge Bases as the production option.
Legal Knowledge Base: We ingested bare Acts using section-boundary-aware chunking, each chunk preserves its Act name, section number, jurisdiction scope, and source URL.
Safety-First Pipeline (Sahayak): Every query passes through a 9-step pipeline with 4 independent safety layers:
- Prompt Constraints : system prompt forbids advisory language, requires citations, instructs refusal on uncertainty
- Retrieval Gate : no sources retrieved = automatic refusal (never generates from training data alone)
- Citation Verification: every section reference in the response is cross-checked against retrieved chunks; unverified claims are stripped
- Guardrails: language checker scans for 45+ directive phrases ("you should", "hire a lawyer", "file a complaint"); certainty threshold enforced at 0.8
Document Verification Pipeline: 8-stage forensic analysis: validate, extract text, split paragraphs, text analysis (Nova), visual analysis (Nova multimodal for stamps/seals/signatures), cross-reference legal citations against the vector DB, merge and score, assemble verdict. The prompt knows 30+ recognized Indian government bodies by name
Drishti Pipeline: Agentic document intelligence — extract text from PDF/DOCX/TXT → inject into a 1100+ line analysis prompt → Nova generates structured JSON with 50+ fields → parse and validate → normalize missing fields → persist to DynamoDB with TTL → render across 8 visualization components. The entire pipeline produces a comprehensive case brief in a single LLM pass.
Shareable Reports: Drishti analyses can be shared via short URLs (/drishti/s/a7x9kQ). Owners choose public or password-protected access (bcrypt-hashed), set expiration (24h / 7d / 30d / never), and optionally include the source document. Shared reports are denormalized in DynamoDB - they survive even if the owner deletes their history. Rate-limited password attempts prevent brute-force access.
Infrastructure: DynamoDB for persistence (user accounts, analysis history, learning progress), S3 for document storage, Terraform for IaC, JWT-based authentication, EC2 for API deployment.
Challenges we ran into
Balancing skepticism with accuracy in document verification. Our first prompt was too trusting, a blatantly fake scam notice scored 97/100. We rewrote it to be "skeptical by default" and then a real Enforcement Directorate arrest order scored 9/100, flagging the official government emblem as "unauthorized use." The breakthrough was teaching the system to identify the issuing entity first, the same emblem means completely different things on a government order vs. a private company's threat letter. Getting this balance right took three prompt iterations and a complete scoring algorithm redesign.
Preventing the AI from giving legal advice. There's a razor-thin line between "informing someone about the law" and "telling someone what to do." We built a 45-pattern language checker that catches directive phrases, but early versions were too aggressive they'd refuse responses containing phrases like "the court should" (discussing legal standards, not advising the user). Tuning the safety layer to be protective without being useless was an iterative process.
Jurisdiction-aware retrieval. Indian law is layered — central Acts, state amendments, local rules, and they can contradict each other. A question about rental agreements in West Bengal needs different law than the same question in Jharkhand. We built a symbolic jurisdiction resolver that runs before vector retrieval to scope the search, and then validates the response against jurisdiction-specific rules after generation.
Multimodal document analysis. PDFs contain both text and visual elements (stamps, seals, signatures, letterheads). Text extraction alone misses forged seals. We implemented dual-mode analysis text extraction for language/legal reference analysis plus image-based analysis via Nova multimodal for visual forensics, then merged the findings with deduplication.
Structured JSON extraction at scale. Getting Nova to consistently produce valid JSON with 50+ fields across 15+ nested types for Drishti was challenging. The LLM would intermittently wrap responses in markdown fences, omit required fields, or produce malformed arrays. We built a robust parse-validate-normalize pipeline that strips fences, fills missing optional fields with safe defaults, and catches refusal signals - turning an unreliable LLM output into a dependable structured analysis.
Scoring algorithm for real-world calibration. Translating "this document has 3 critical issues and 5 warnings" into a meaningful 0-100 score required weighted category scoring, tiered caps based on how many categories have critical findings, volume penalties, and averaging LLM self-assessment with deduction-based calculation. The thresholds went through multiple rounds of testing against real government documents and known scam samples.
Accomplishments that we're proud of
The safety architecture actually works. NyayaSetu will refuse to answer rather than risk giving wrong information. It strips unverified citations, catches advisory language, and adds disclaimers, all automatically, across every response. In a domain where wrong information can ruin someone's life, this matters more than any feature.
Document verification that understands context. The system doesn't just pattern-match, it reasons about whether the entity claiming authority actually has that authority. A real CBI summons with a government seal gets recognized as legitimate. A fake "Legal Department" notice with the same seal gets flagged as unauthorized use. This context-aware analysis is something we haven't seen in other document verification tools.
The full stack works end-to-end. From uploading a PDF to seeing a color-coded authenticity breakdown with inline highlights, from asking "can police search my car without a warrant?" to getting a cited legal position with jurisdiction tag everything connects beautifully. Four modules, six shared packages, two apps, all typed, all building, all working together.
Jurisdiction-aware legal reasoning. NyayaSetu knows that alcohol laws differ between states, that motor vehicle regulations have state-specific amendments, and that an inter-state travel scenario involves multiple jurisdictions. It tags every response with the applicable jurisdiction and flags multi-jurisdiction complexity.
Shareable, encrypted case briefs. A lawyer can share a password-protected Drishti analysis with their client via a simple link. No login required for the viewer, no screenshots, no PDFs — just a clean, interactive read-only view of the full analysis. The link can expire, can be revoked, and tracks view counts.
What we learned
AI safety in legal tech is an architecture problem, not a prompt problem. You can't make an LLM safe with just a good system prompt. You need retrieval gates, citation verification, language checking, and certainty thresholds independent layers that catch different failure modes. Defense in depth.
The hardest part of document verification isn't detecting fakes, it's not falsely flagging real documents. Anyone can build a system that calls everything suspicious. Building one that correctly identifies a legitimate government arrest order while catching a scam notice that mimics the same format is a fundamentally harder problem. It requires domain knowledge about Indian government bodies, their document formats, and their legal powers.
Legal data is messy. Indian bare Acts have inconsistent formatting, state amendments reference central sections by number without context, and judgment PDFs have wildly varying structures. Our section-boundary chunking strategy had to handle all of these gracefully.
Structured extraction needs defensive engineering. LLMs are unreliable JSON generators. The gap between "works in testing" and "works on every document" is filled with edge cases: markdown fences, missing fields, malformed arrays, and refusal signals disguised as valid JSON. Building a robust parse, validate, and normalize pipeline was essential.
Refusal is a feature, not a failure. Early in development, I kept trying to make the system answer more questions. The breakthrough was accepting that "I don't have reliable sources for this" is the correct answer when the knowledge base doesn't cover a topic. Users trust a system that admits its limits more than one that confidently makes things up.
What's next for NyayaSetu
Expand legal coverage. Expanding the legal knowledge base to all 28 states and 8 union territories, covering property law, family law, labor law, and RTI procedures.
Multilingual support. India has 22 scheduled languages. Legal literacy means nothing if the information isn't in the language people think in. Adding support for these languages would be the next priority.
Community-verified legal knowledge. Partner with law universities and legal aid organizations to expand and verify the knowledge base. Every chunk should trace back to a verified source with a verification timestamp.
Mobile-first PWA. Most Indians access the internet primarily through smartphones. A lightweight progressive web app optimized for low-bandwidth connections would make NyayaSetu accessible where it's needed most in police stations, government offices, and courtrooms.
Voice interface. Many potential users have limited literacy. A voice-based interface in regional languages describe your situation, hear the legal position would dramatically expand reach.
Built With
- amazon-dynamodb
- amazon-ec2
- amazon-web-services
- amazonnova
- chromadb
- fastify
- react
- terraform
- turborepo
- typescript

Log in or sign up for Devpost to join the conversation.