
Inspiration
I did not discover this problem through research. I grew up with it.
My friend's father worked as a peshkar — a court clerk who sits beside the judge — and from childhood I heard his stories. Cases delayed for years. Families waiting outside courtrooms for prisoners who had already served more than their maximum sentence. People who could not name the section of law that entitled them to go home. I absorbed these stories as background noise. I did not understand their scale.
A few weeks before this hackathon, the scale became personal. A neighbour filed a false case against my entire extended family — fifteen people across three households. I started reading the law. I found Section 479 of the Bharatiya Nagarik Suraksha Sanhita 2023. I found the Supreme Court's August 2024 ruling that made it retrospective. I found that 390,000 undertrial prisoners in India — 74% never convicted — were legally entitled to this remedy, and that most of them would never know it existed because no system surfaced it.
Then I read the Smart India Hackathon 2023 problem statements and saw this identified as an unsolved civic technology gap. That was the moment I stopped treating it as background noise.
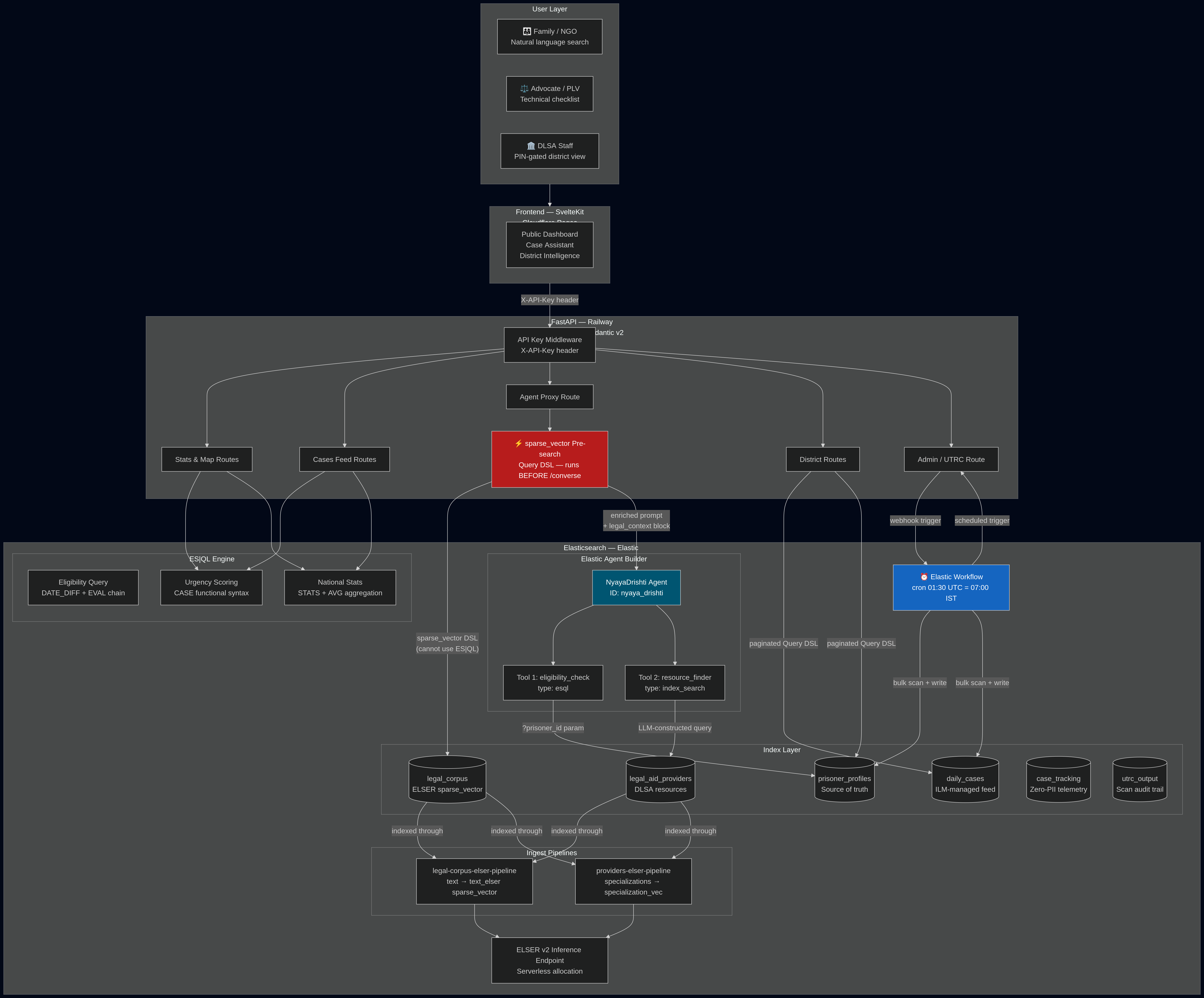
I chose Elasticsearch not because it was the default choice, but because the problem demanded it. Eligibility determination across 390,000 prisoners is not a form-filling problem or a dashboard problem. It is a query problem. Six simultaneous legal conditions — custody duration, charge classification, first-offender status, capital offense exclusion, multiple-case bars, UTRC category flags — evaluated per record, daily, at national scale. That computation belongs inside the data plane, not the application layer. Elasticsearch was the only foundation that made that architecture honest.
What It Does
NyayaDrishti computes Section 479 BNSS bail eligibility as a native Elasticsearch query — not an application-layer calculation, not a manual spreadsheet, not a quarterly review that never happens.
For families who know nothing about law: a natural language search. Type "my husband has been in Tihar for three years for a cheating case." ELSER v2 sparse vector search resolves "cheating case" to IPC 420, retrieves the maximum sentence, computes whether custody has crossed the half-time threshold, and returns an eligibility verdict with a step-by-step action plan in English or Hindi. The family receives the nearest DLSA office address, visiting hours, and a printable document to bring.
For advocates and PLVs who need precision: the same query returns BNSS section citations, days remaining in the bail window, first-offender rule applicability, and a legal checklist formatted for court filing. The Elastic Agent Builder maintains multi-turn conversation context via conversation_id — an advocate can ask follow-up questions without re-establishing case context.
For DLSA officials who are legally required to conduct UTRC reviews quarterly but lack tooling to do it: a daily Elastic Workflow scans all prisoner profiles, scores each against Section 479 thresholds using ES|QL EVAL chains, and writes the results to the daily_cases index. The district view surfaces a ranked queue — critical cases at the top, window-closing dates visible, bulk action available. The workflow replaces a manual review process that was failing systemically not because officials were negligent, but because the computation was intractable without Elasticsearch.
Every feature is Elasticsearch executing intelligence that previously required either a lawyer or a bureaucratic process that rarely completed on time.
How We Built It
The architecture has one governing principle: intelligence runs where the data lives.
ES|QL Eligibility Engine
Section 479 eligibility is a deterministic multi-condition computation. I wrote it as a single ES|QL query using DATE_DIFF, EVAL chains, and CASE() functional syntax:
FROM prisoner_profiles
| EVAL custody_months = DATE_DIFF("month", arrest_date, NOW())
| EVAL half_max = max_sentence_years * 6
| EVAL fo_eligible = first_offender == true
AND custody_months >= (max_sentence_years * 4)
| EVAL section_479_eligible = (custody_months >= half_max OR fo_eligible)
AND is_capital == false
AND multiple_cases == false
Before I understood ES|QL, I would have written this as six conditional branches in Python — an O(n) scan with application-layer logic that scales poorly and is impossible to audit. In ES|QL, the computation runs inside the Elasticsearch data plane. The application receives only qualified records. The query planner handles distribution.
ELSER v2 Semantic Charge Resolution
Families do not say "IPC Section 420." They say "cheating case" or "fraud" or "mera paisa le gaya." ELSER v2 sparse vector embeddings on the legal_corpus index resolve colloquial descriptions to legal sections without a lexical lookup table. The model learns the semantic relationship at inference time — not at query design time. This matters because Indian legal terminology spans IPC 1860, CrPC 1973, and BNSS 2023, with overlapping concepts and inconsistent naming across record systems.
Elastic Workflows — UTRC Batch Automation
A scheduled Elastic Workflow fires daily at 07:00 IST, triggers a FastAPI webhook, and initiates a full scan of prisoner_profiles — scoring every eligible prisoner, computing urgency via CASE() chains, writing daily_cases documents in bulk. This replaced what was a manual quarterly process. Automation lives inside the Elastic stack, co-located with the data it produces.
Elastic Agent Builder — Constrained Tool Separation
Two tools. No overlap.
eligibility_check_tool (ES|QL type): deterministic. Takes a prisoner ID, returns computed eligibility fields. No hallucination possible — the query satisfies the EVAL chain or it does not.
resource_finder_tool (index_search type): semantic. LLM constructs the search query from conversation context, returns nearest DLSA resources.
Separation is deliberate. Mixing deterministic legal computation with semantic search inside one tool makes the agent's reasoning unauditable. The eligibility verdict always comes from a verified ES|QL query — never from the model's parametric memory of Indian law.
Persona injection uses a hybrid prompt structure — XML tags wrapping markdown content — giving the agent parser-friendly boundaries between tone instructions, legal context, and user intent.
ILM + Ingest Pipelines
Two ingest pipelines normalize documents through ELSER inference at index time: legal-corpus-elser-pipeline for legal section text, providers-elser-pipeline for DLSA specialization metadata. Inference happens once at write time. ILM policy on daily_cases manages 30-day case rotation through open → claimed → filed lifecycle phases.
Stack: Python 3.12 + FastAPI backend with Pydantic v2 strict typing. Svelte 5 + TypeScript + Zod frontend. All response schemas shared between layers as a typed contract.
Challenges We Ran Into
The sparse_vector wall
The original architecture had three Agent Builder tools: a charge analyzer using ES|QL, an eligibility checker, and a resource finder. I built the charge analyzer first. Then I tried to register it and discovered that sparse_vector fields cannot be queried via ES|QL — only Query DSL supports sparse vector retrieval. This is not a documentation footnote. It is a hard constraint of the current ES|QL specification.
The tool had to be removed. But the charge context it provided — max_sentence_years, is_capital, legal section metadata — was essential for accurate eligibility computation. Without it, the agent would infer legal facts from parametric memory, which is unacceptable for a system making legal eligibility determinations.
The solution was a pre-search architecture: FastAPI runs a sparse_vector Query DSL search against legal_corpus before calling /converse, extracts the charge metadata, and injects it as a structured <legal_context> block into the Agent Builder prompt. The constraint produced a better design — the charge analysis step became explicit, independently testable, and auditable outside the agent's reasoning chain.
CASE() syntax is not SQL
ES|QL CASE uses functional syntax — CASE(condition, value, condition, value, default) — not the SQL CASE WHEN ... END form. I discovered this during query verification using the Elastic AI Agent. The SQL form parses without throwing an error but produces incorrect evaluation. The urgency scoring query — which uses nested CASE() chains across five thresholds and three bonus conditions — would have silently miscored every prisoner in the dataset. Catching this before the seed ran prevented a scoring failure that would have been invisible in the output but wrong in the data.
Legal terminology inconsistency across IPC and BNSS
Indian prison records reference IPC 1860 section numbers. BNSS 2023 renumbered significant portions of the code. The Supreme Court's August 2024 ruling on Section 479 BNSS explicitly addressed this transition, ruling that the new section applies retrospectively — meaning a prisoner charged under the old CrPC framework is evaluated against the new BNSS thresholds. The legal_corpus index holds documents covering both frameworks, with cross-reference metadata linking IPC and BNSS equivalents. ELSER handles the semantic ambiguity — a query for "IPC 302 murder" and "BNSS Section 103 homicide" resolve to equivalent legal weight in the charge analysis step.
ES|QL has no OFFSET
Paginating the UTRC batch scan — which processes up to 390,000 records in pages of 100 — requires OFFSET support that ES|QL does not currently have. All paginated operations use Query DSL from_ + size. This is not a workaround — it is the correct tool. ES|QL handles analytics. Query DSL handles record retrieval. The constraint clarified which tool belongs in which role.
Accomplishments That We're Proud Of
Eligibility is a query, not a conditional tree
Six legal conditions, evaluated across a national prisoner dataset, returning only qualified records — implemented as a single ES|QL query with no application-layer logic. The query is the reasoning. This is what I mean when I say Elasticsearch is the computational substrate: the intelligence does not sit in the application and ask Elasticsearch for data. The intelligence runs inside Elasticsearch and returns answers.
Semantic charge resolution across legal framework inconsistency
A family member typing "mera bhai cheating case mein hai" receives an accurate eligibility computation. ELSER resolves the natural language to IPC 420, retrieves the correct maximum sentence, and the eligibility query runs against that structured fact. This works across IPC and BNSS terminology without a lookup table, without keyword matching, and without requiring the user to know the difference between the two frameworks.
Agent reasoning that cannot hallucinate the verdict
The eligibility verdict in NyayaDrishti cannot come from the LLM's parametric memory. The tool separation architecture guarantees this — eligibility_check_tool is an ES|QL query registered in Agent Builder, not a prompt asking the model to calculate. The reasoning is constrained, auditable, and legally traceable to a specific query result. For a system that affects whether a person goes home or stays in prison, this is not an optional property.
Production architecture as a solo build
Pydantic v2 strict response schemas shared as a typed contract with the Svelte 5 + Zod frontend. Idempotent seed scripts with Gate 1 verification (8/10 semantic queries must pass before deployment is considered valid). ILM lifecycle management. Async bulk indexing with error handling. Ingest pipelines. Elastic Workflows. Agent Builder provisioning via script. Solo built, production-ready.
What We Learned
Before this project, I had a complicated relationship with Elasticsearch. The JSON query DSL frustrated me — deeply. As someone who has spent time reading server logs on Linux, I understood the value of fast text search. grep on massive log files is slow, brittle, and falls apart the moment you need cross-field correlation. I knew Elasticsearch was faster. I did not know it was a different category of tool.
ES|QL changed how I think about query-as-logic. The realization that a six-condition legal eligibility check could run as a single EVAL chain inside the data plane — with no round trips, no application-layer filtering, no serialization overhead — was not what I expected. I had been thinking about Elasticsearch as a fast document store. ES|QL revealed it as a computation engine. That is a different mental model, and it changes what problems you reach for Elasticsearch to solve.
ELSER changed how I think about semantic search in domain-specific contexts. I had worked with embedding-based search before and understood the general principle. What I had not seen was sparse vector retrieval applied to a domain with genuinely inconsistent terminology — IPC vs BNSS, colloquial vs legal, Hindi vs English. ELSER handled the semantic gap without fine-tuning, without a custom vocabulary, and without a lookup table. The pruning configuration was the only tuning required. That surprised me.
Agent Builder changed how I think about constrained AI reasoning. My initial instinct was to give the agent as much capability as possible — more tools, more context, more freedom. The sparse_vector constraint forced the opposite: a pre-search step that structured the agent's input before the reasoning began. The result was a more auditable, more reliable system than the unconstrained version would have produced. I learned that constraining an agent's reasoning path is not a limitation — it is an architectural decision about where trust is earned.
I came into this hackathon knowing Elasticsearch was powerful. I am leaving it knowing specifically why, and knowing which problems it solves structurally rather than incidentally.
What's Next for NyayaDrishti
I will present NyayaDrishti to STPI — Software Technology Parks of India — as a civic technology initiative. I will coordinate directly with Indian state governments and work through proper channels with the Indian court system to explore real-world deployment. I understand that operating a system that surfaces legal eligibility data requires explicit permission from judicial authorities and careful review by practising advocates to avoid causing harm through incorrect eligibility signals. I will not deploy this without those permissions.
I intend to maintain this project long-term. Not as a portfolio piece — as a live system, if the institutional path opens.
Before this project, I did not understand the scale of what I had grown up hearing about. I knew the stories. I did not know there were 390,000 of them. These are isolated people — in the most literal sense. Separated from families, unable to navigate a legal system that has a written mandate to release them, without the technical infrastructure to identify them and act. The Supreme Court issued the mandate. The law exists. The gap is computational and institutional — exactly the kind of gap that Elasticsearch is suited to close.
On the technical roadmap: expanding coverage to all 36 Indian states and union territories requires district-level DLSA data that is currently scattered across state government portals. Elastic's NLP capabilities — language identification, named entity recognition — could extend the interface to regional languages beyond Hindi and English. Real-time integration with eCourts case data would replace synthetic seed data with verified production records. Elastic Watcher could trigger advocate alerts when a prisoner's window approaches critical thresholds, without any manual monitoring.
The infrastructure is built. The query runs. What remains is permission, partnership, and time.
Built With
- elastic-ai-agent
- es|ql
- fastapi
- python
- svelte
- typescript

Log in or sign up for Devpost to join the conversation.