Inspiration
A casual chat with my lawyer friend who practices at the Supreme Court of India quickly turned into a passionate rant about how existing legal chatbots often provide out-of-context answers and lack specificity when it comes to Indian law. That conversation sparked my curiosity—and that's when the idea for Nyaya AI was born. "Nyaya" means justice in Hindi, and I began developing it as a side project to build a more accurate, India-focused legal assistant.
What it does
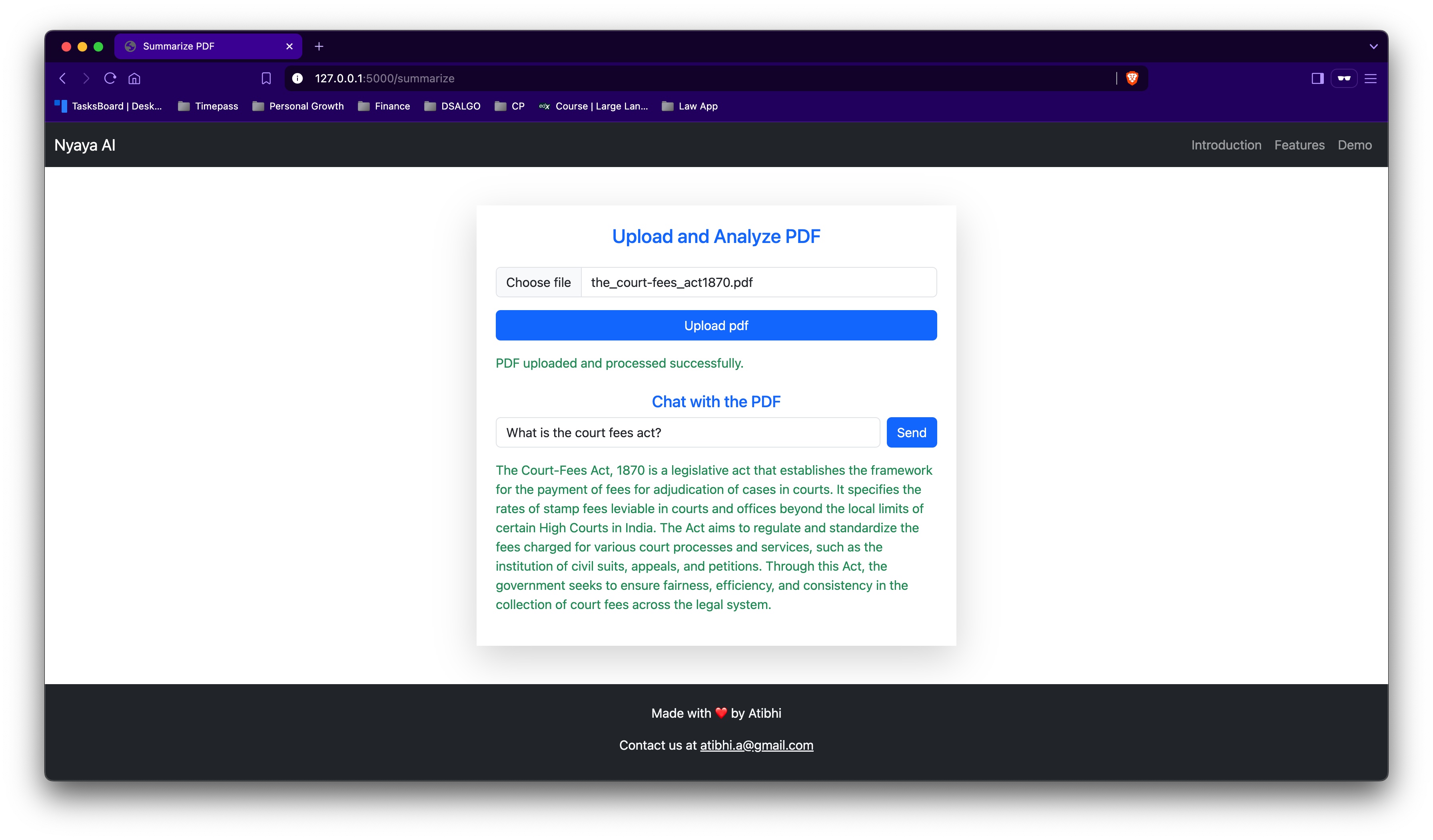
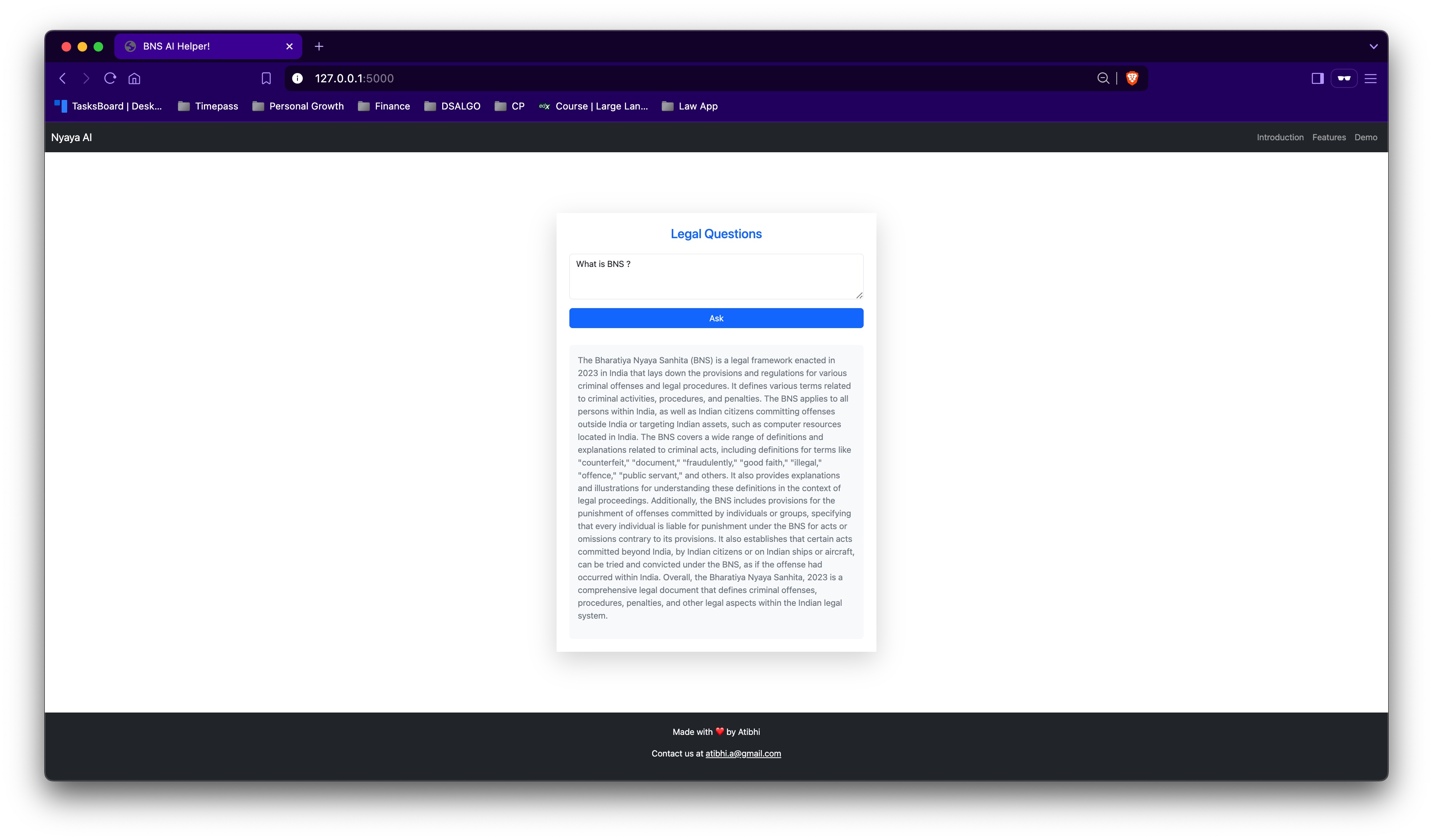
Nyaya AI currently answers legal questions based on the latest Indian laws (with limited coverage) and can analyze legal PDF documents. The question-answering feature was built earlier, while the PDF document analysis capability is being developed as part of this hackathon.
How I built it
- I used Flask for the backend and a simple HTML/CSS frontend to keep the interface lightweight and user-friendly.
For the question-answering capability, I integrated the OpenAI API, but what really made a difference was the extensive data cleaning and manual data annotation I did. My lawyer friend, after trying several other legal chatbots, found Nyaya AI significantly better—and I believe that’s largely due to how thoughtfully the legal data was structured and fed into the model.
During the hackathon, I wanted to build the ability to upload legal PDFs and get contextual analysis from them. I am building this using OpenAI APIs again.
Challenges I ran into/am running into
Data cleaning and annotation: Preparing legal data for the model involves a lot of tedious, manual/automated work. Legal texts are complex and unstructured, so making them usable required significant effort.
Controlling LLM context: Even with fine-tuned data, large language models tend to drift or hallucinate. Ensuring they stay within the boundaries of Indian law is a constant challenge.
Keeping models up to date: Laws evolve, and ensuring that the underlying model reflects the latest legal changes—without having to retrain everything from scratch—is an ongoing issue.
Token Limits by APIs
Accomplishments that I am proud of
Built a functional legal assistant tailored to Indian law, something that many generic chatbots fail to do effectively and got validation that it is better.
Created the end to end backend and front-end for uploading legal pdfs and analysis during the hackathon!
What I learned
Domain knowledge is crucial for building meaningful AI tools Prompt engineering matters—the quality of chatbot responses depends heavily on how the data is fed and how prompts are framed.
Preprocessing is just as important as modeling
A bit about LLMs, building products using LLMs and APIs.
What's next for Nyaya AI
- Improve guardrails and hallucinations.
- Integrate document pre-processing into analyse section of project.
- I want to integrate features such as precision source attribution that links answers directly to specific sections of legal texts, and comprehensive citation retrieval that delivers complete details when anyone reference specific statutes or precedents, more data cleanup and limiting context window.
- Launch it for Indian lawyers. :)

Log in or sign up for Devpost to join the conversation.