-
-
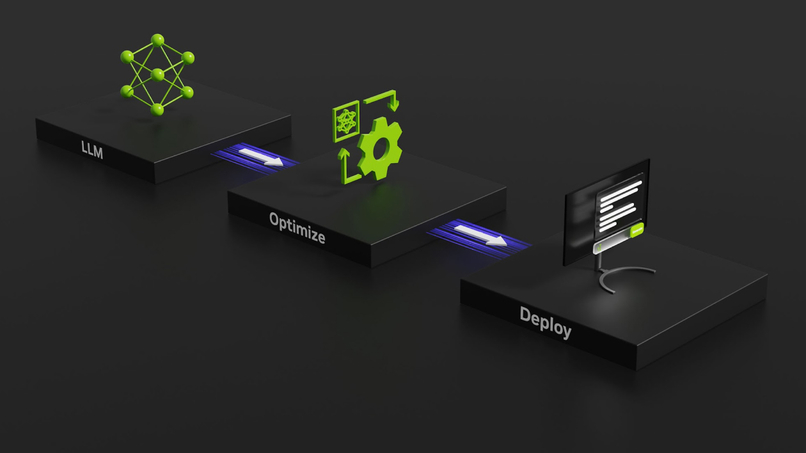
Quick overview of container workflow using TensorRT-LLM
-
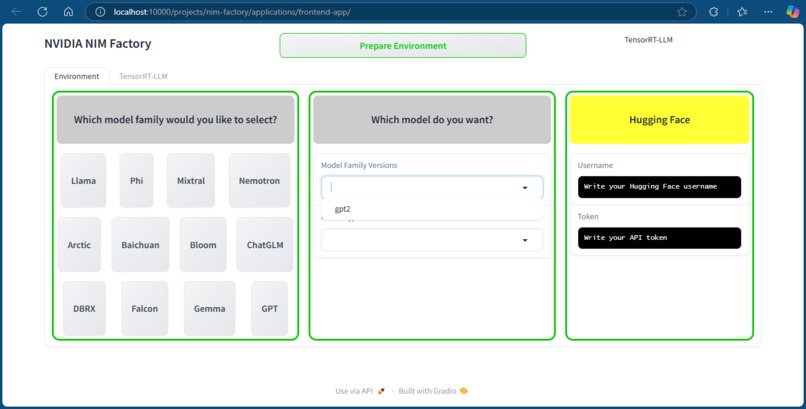
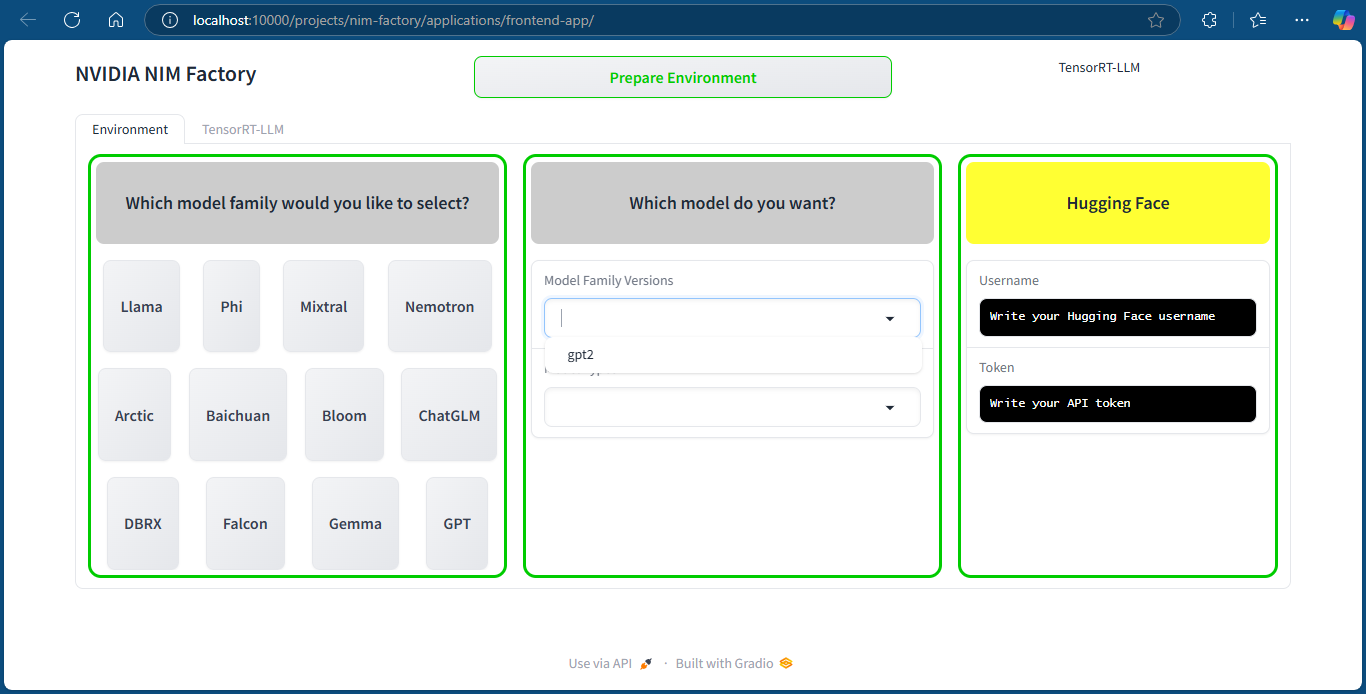
Home page of the application where we prepare and install required dependencies
-
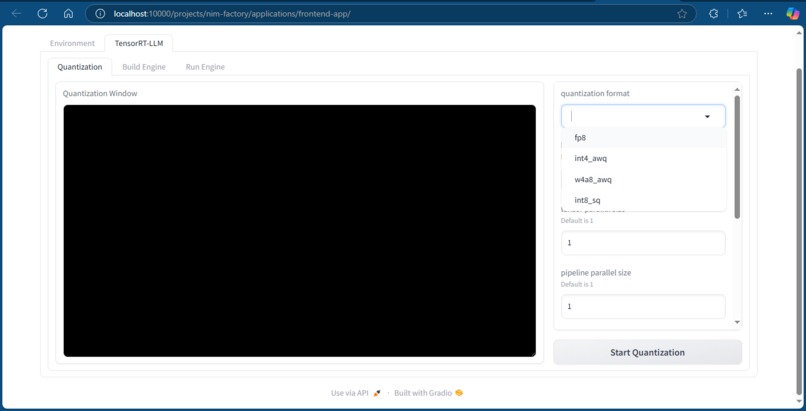
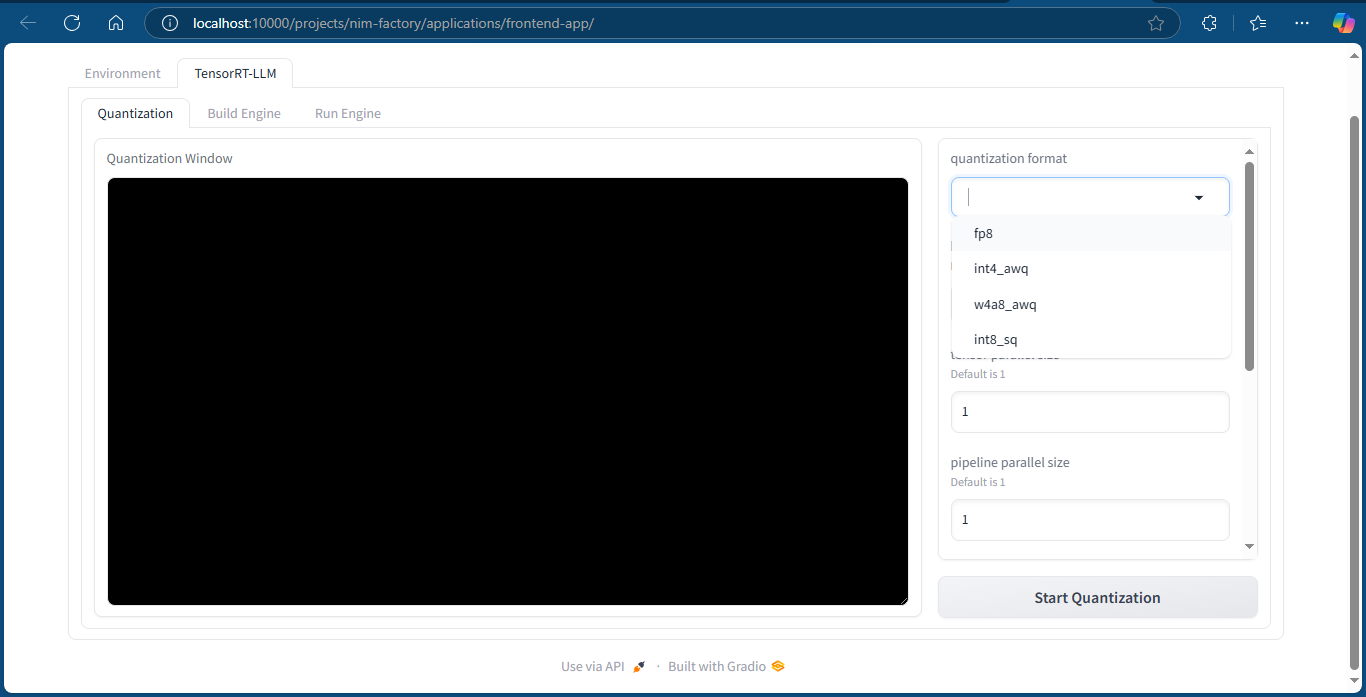
Quantization page where we build our quantized model (black screen is live output log screen)
Inspiration
Over the past few years Generative AI models have popped up everywhere - from creating realistic responses to complex questions, to generating images and music to impress art critics around the globe. However, there are still some users or businesses who cannot use Generative AI due to limited resources, high cost for compute power or simply overweight their business goals. In this project, we enable them to quantize almost any AI model into different sizes and build an optimized inference engine using TensorRT-LLM.
What it does
This project is a factory for NVIDIA NIM containers in which users/businesses can quantize many models and build their own TensorRT-LLM engine for optimized inference. This enables users/businesses with large hardware resources but smaller business goals to save compute power by quantizing LLMs into different sizes and build optimized inference engines.
How we built it
We built with native NVIDIA libraries such as TensorRT and TensorRT-LLM. TensorRT-LLM utilizes TensorRT library for conversion and quantization of model weights to build optimized engine. Since the base container "Python with CUDA 12.2" provides us with Python 3.x and CUDA 12.2 libraries, we build our project on top of that container.
Challenges we ran into
Initially, we wanted to customize NVIDIA NIM containers from bottom to top. After long research, we discovered that it is impossible to make NIM to run quantized models because they were created with precompiled TensorRT-LLM engine which is the fundamental component of NIMs. However, it opened a new opportunity to us enable users to build their own NIMs with the use of TensorRT-LLM which gives more freedom than ever.
What we learned
During hackathon, we gained a lot of knowledge about LLMs, experience with NVIDIA technologies like TensorRT-Model-Optimizer, TensorRT-LLM, NVIDIA NIM and more. All experiences we got from this hackathon greatly contributes to our development and opens the door to the future of technology.
What's next for NVIDIA NIM Factory
This project has a huge potential to be used by many consumers, from small to big ones like Microsoft, OpenAI, etc. because it gives more freedom of choice than traditional NIMs in which users have to comply with the model sizes and its workflows. We plan to reveal as many features of TensorRT-LLM as possible which will increase the freedom of building their "NIMs" and develop advanced error handling so that users/businesses could easily interpret them.
Built With
- bash
- gradio
- jupyter
- tensorrt-llm



Log in or sign up for Devpost to join the conversation.