-
-
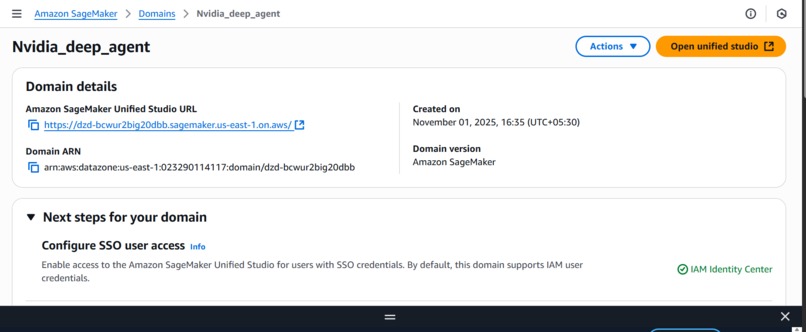
Deployed AWS Sagemaker Successfully, But link is not working some IAM access issues
-
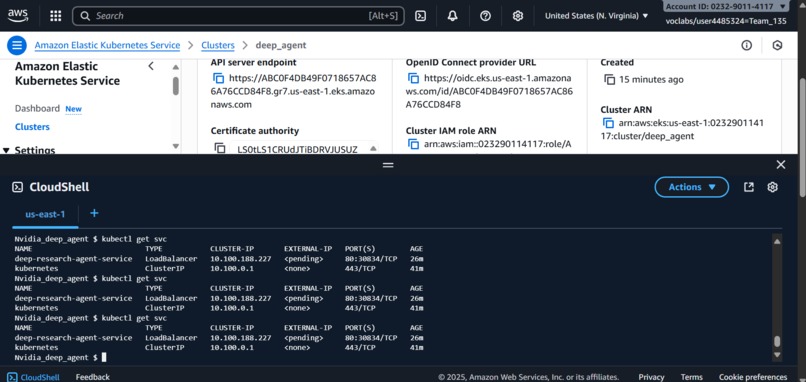
Trued deploying using EKS as well but external IP seems pending
-
AWS EKS
-
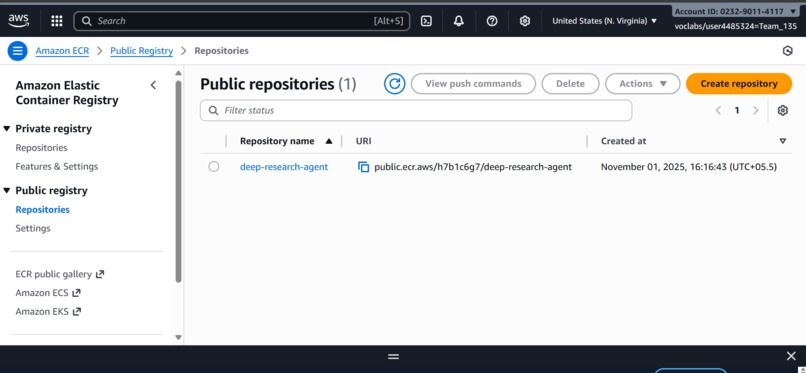
Public AWS ECR repo having code
-
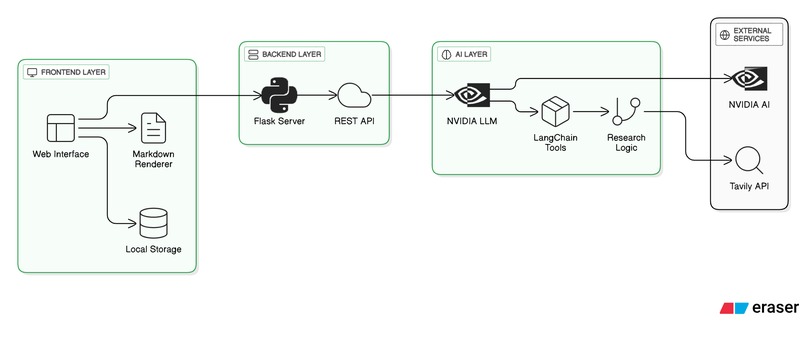
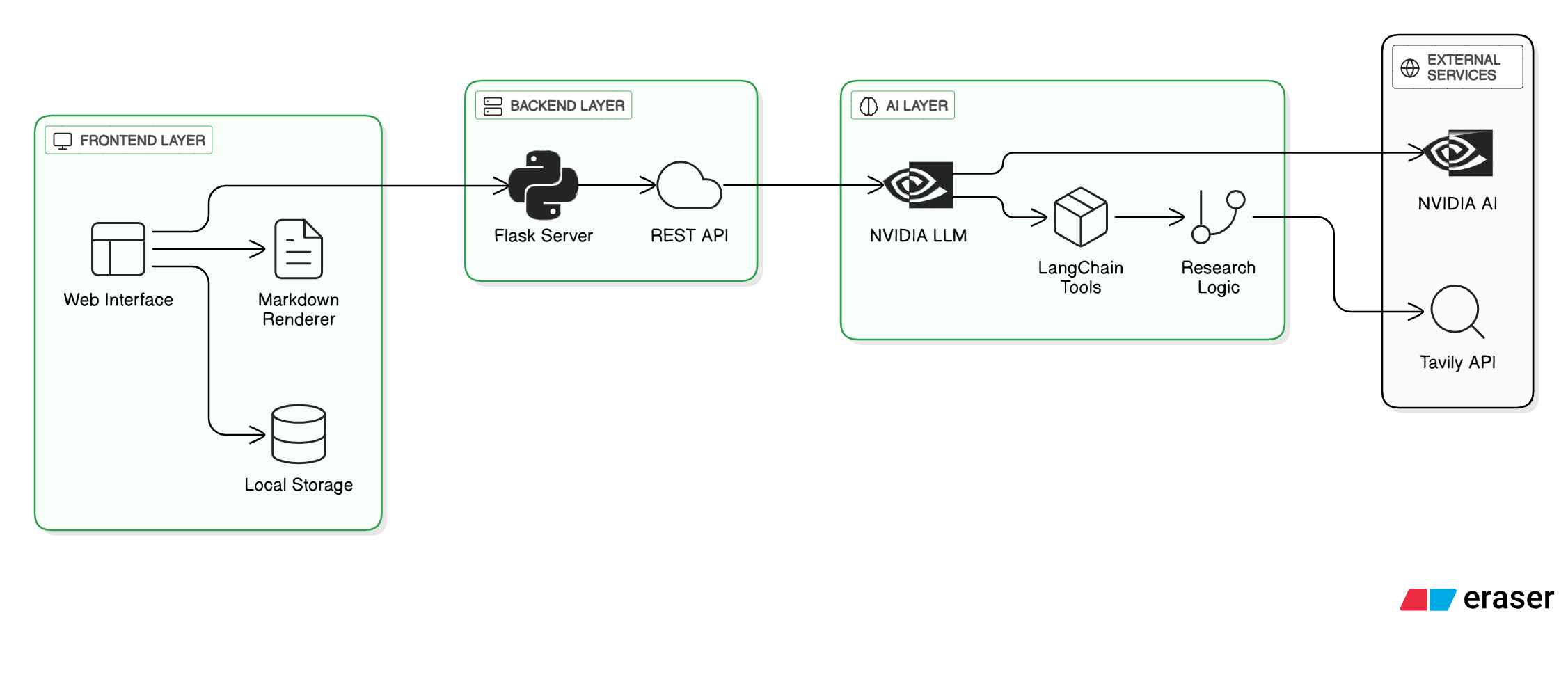
Architecture Diagram (indetailed Architecture is present In Github Repo readme file
Inspiration
The exponential rise of information and complexity in AI calls for research tools that go far beyond a simple search box. Inspired by the need for actionable science—where agents don't just retrieve answers but synthesize, verify, and present them in professional formats—this project channels NVIDIA's advancements in LLMs and agentic architectures. Our goal: give researchers, students, and innovators an AI agent capable of end-to-end deep research, live synthesis, and interactive workflow, all in a modern NVIDIA-branded UI.
What it does
NVIDIA Deep Research Agent is an advanced, AI-powered tool that performs comprehensive, multi-step research on any topic using: Multi-query intelligent web search (with Tavily API) Autonomous source aggregation, verification, and analysis Large language model reasoning (NVIDIA Llama 3.1 70B/8B, Mixtral…) One-click report generation: executive summary, detailed sections, citations Modern, responsive UI with local history, export to Markdown, and real-time progress tracking Simply enter a question; the agent handles the rest—searching, analyzing, and producing a beautifully formatted research report.
How we built it
Frontend: HTML5, CSS3, JavaScript ES6+ (with responsive NVIDIA-themed design) Backend: Python (3.8+), Flask 3.x, Flask-CORS, streaming REST API AI/Agents Framework: LangChain Core + LangGraph for orchestrating multi-step agent flows LLM Integration: NVIDIA NIM endpoints (Llama 3/1-Nemotron) with dynamic model selection Information Retrieval: Tavily API for real-time, multi-query web search and retrieval embeddings for citations Report Generation: Markdown synthesis, source citation, and export functionality Deployment: Amazon EKS or SageMaker (cloud-native microservices, inference endpoints)
Challenges we ran into
LLM Orchestration: Designing robust flows for multi-step search, verification, then synthesis required experimenting with LangGraph edge cases and async behavior. Scalability: Integrating NVIDIA's LLM inference as scalable microservices on EKS/SageMaker while keeping latency low for streaming output. Citation & Verification: Ensuring factual accuracy, deduplication of sources, and mapping retrieved data to synthesized report sections. UI/UX: Real-time updates, error handling (timeouts, API errors), and Markdown export—all in a clean NVIDIA theme, was tricky to balance.
Accomplishments that we're proud of
Delivered a fully functional, end-to-end autonomous research agent with seamless LLM and web search integration. Achieved professional, citation-rich Markdown report generation with executive summaries and source traceability. Rigorous error recovery—robust to third-party API failures, restarts, and interrupted searches. Modern, mobile-ready, NVIDIA-branded UI (with streaming, export, and session history).
What we learned
How to orchestrate multiple agent toolchains (search, analysis, synthesis) with LangGraph and handle error recovery gracefully. Practical tricks for calling NVIDIA LLMs as NIM inference microservices on AWS. Deepened expertise in combining Retrieval Augmented Generation (RAG) pipelines with real-time LLM workflows for factually grounded research. User-centric design: live progress feedback, export, and persistent session history matter a lot for research workflows.
What's next for NVIDIA Deep Agent
PDF/HTML Export: Multi-format, printable reports for academic/professional use. Voice & Multilingual Input: Speech-to-text, translation, and internationalization. Full API: Open endpoints for integrating Deep Agent research into other platforms. Better Personalization: User profiles, saved topics, and learning from past research sessions. Model Marketplace: Easy selection of models (NVIDIA/Mistral/Open) and custom toolchains. Analytics Dashboard: Usage tracking and topic trends for research managers.


Log in or sign up for Devpost to join the conversation.