-
-

Picture 1: Dracula visualization vs Gothic literature corpus - composite keywords
-

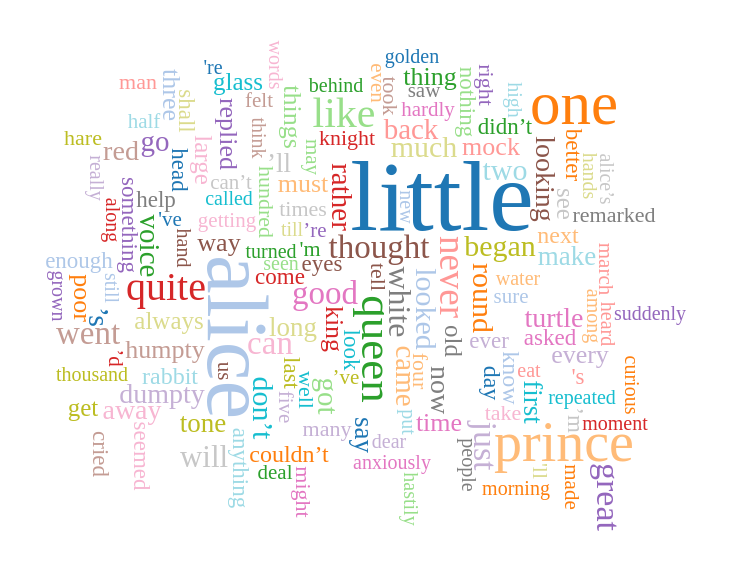
Picture 2: Alice in Wonderland - WordCloud example single word keywords
-
Picture 3: Alice in Wonderland - 10 phrase abstract
-
Picture 4: Alice in Wonderland - chapter1 vs Full book abstract
-
Picture 5: Alice in Wonderland - 20 composite keywords score=WEIGHTED_DEGREE
-
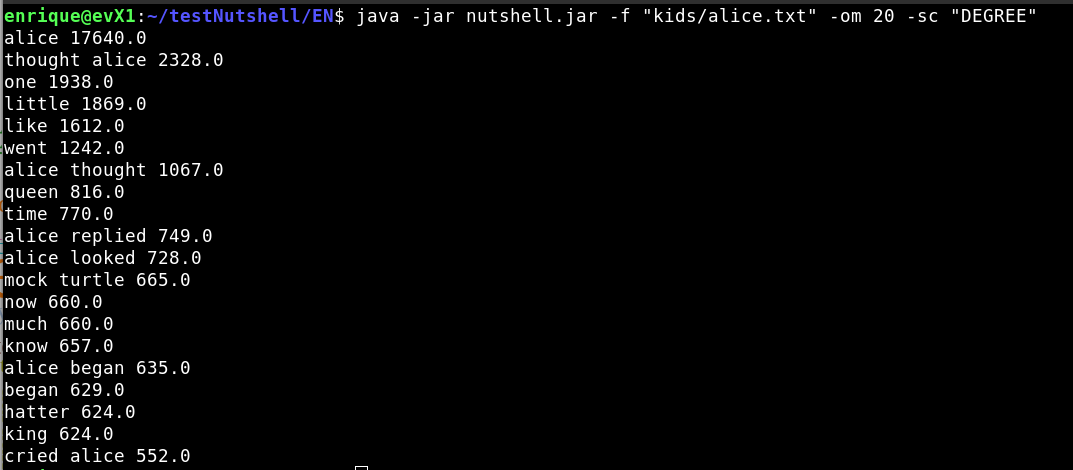
Picture 6: Alice in Wonderland - 20 composite keywords score=DEGREE
-
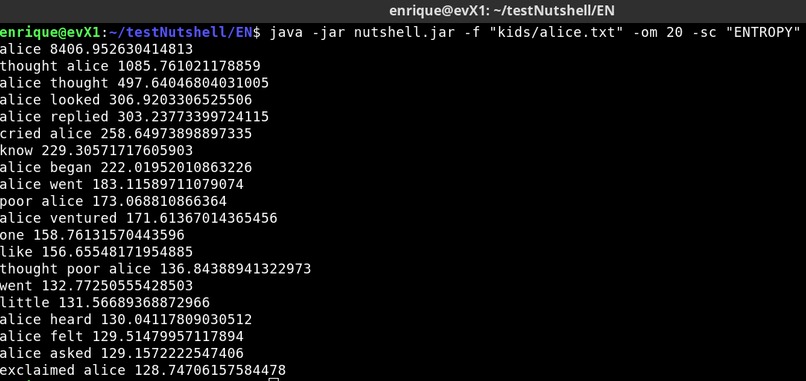
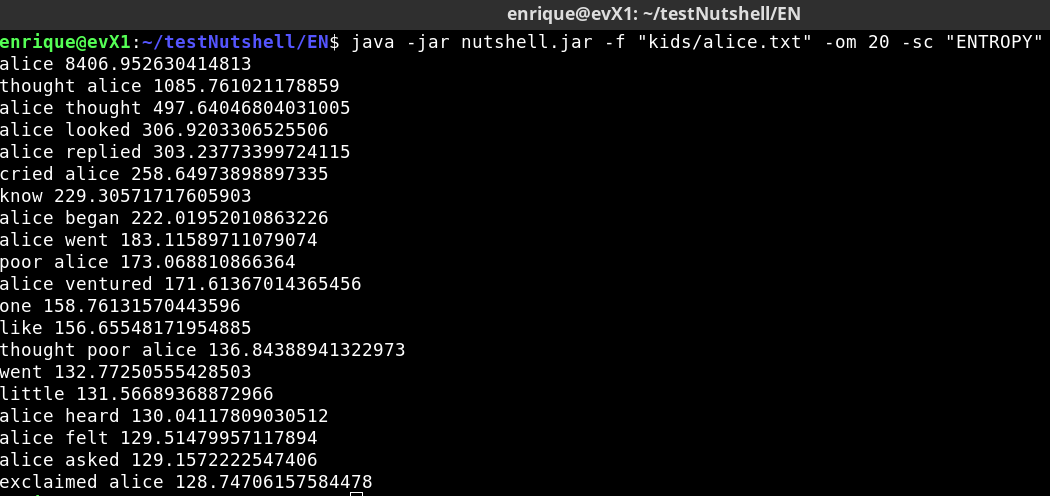
Picture 7: Alice in Wonderland - 20 composite keywords score=ENTROPY
-
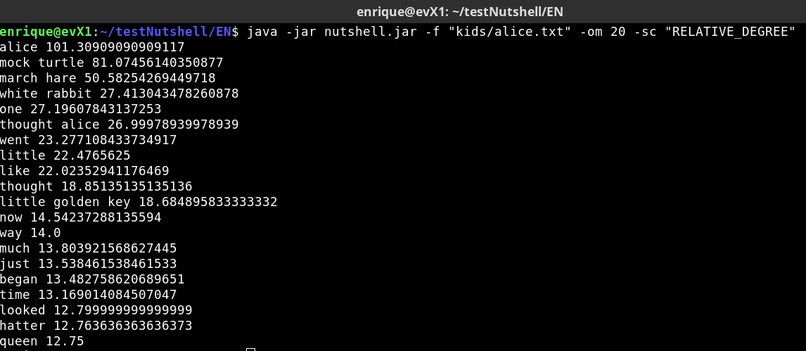
Picture 8: Alice in Wonderland - 20 composite keywords score=RELATIVE_DEGREE
-
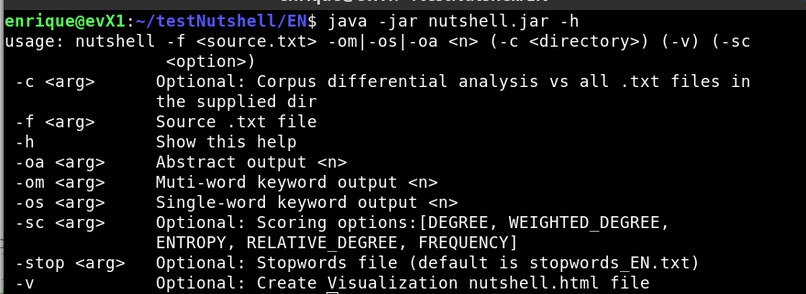
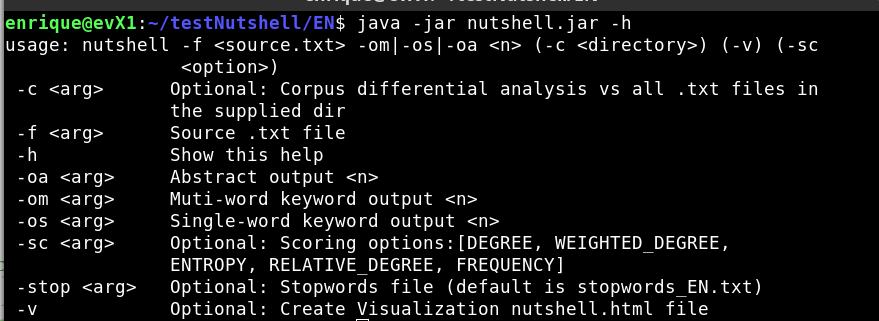
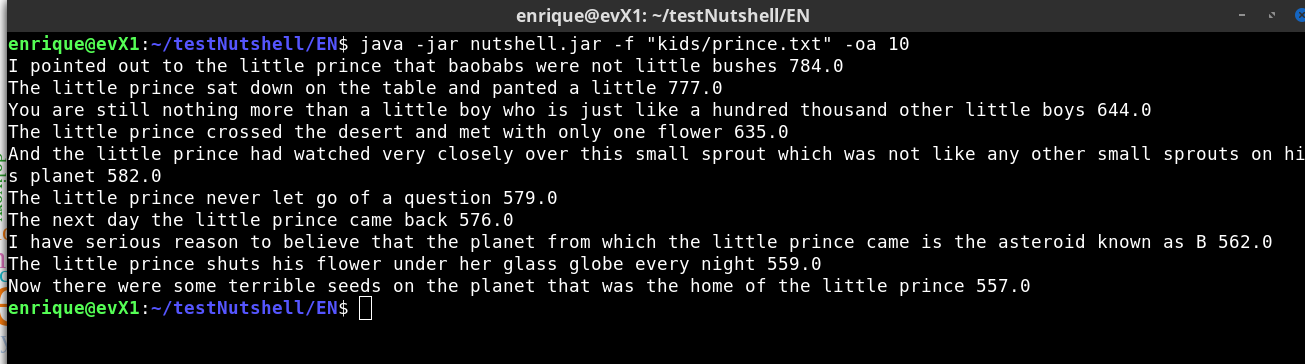
Picture 9: Nutshell CLI - help
-
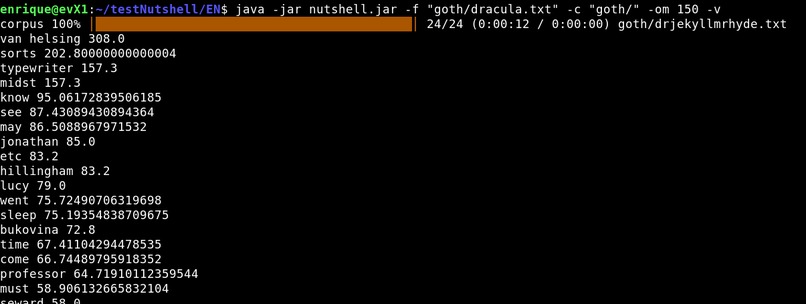
Picture 10: Dracula - Analysis vs corpus of gothic literature
-
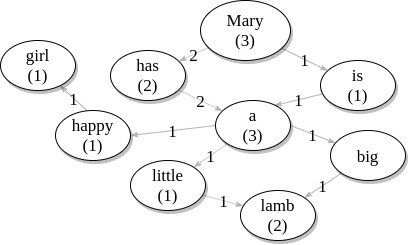
Picture 11: WordGraph example - text = "Mary has a little lamb, Mary has a big lamb, Mary is a happy girl."
-
Picture 12: The Little Prince - 10 words abstract
-

Picture 13: Corpus Processing - Progress Bar in action
-
Picture 14: Scoring demo - using stopwords to build candidate keywords
-

Picture 15: Extracting keywords of Chapter 1 vs Full Book on Alice in Wonderland
-
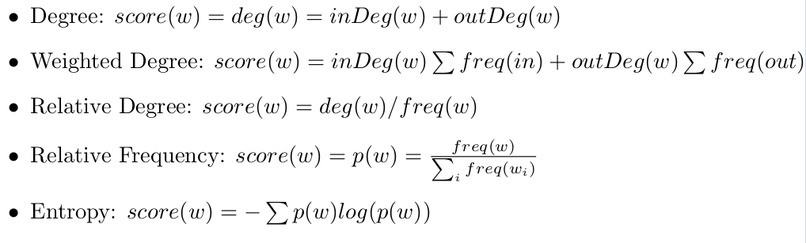
Picture 16: Different scoring systems







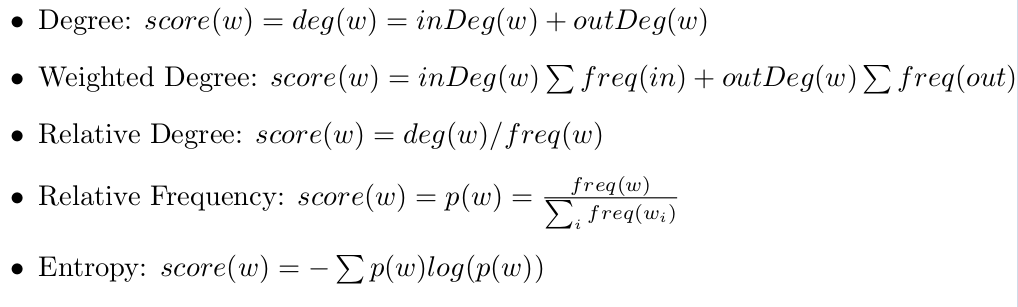
Project team
Enrique Vargas (jevargas@seas.upenn.edu)
The idea
Extract the key context keywords and phrases from a text either as individual text or as part of a larger corpus. As there are many different approaches described in the literature, ensure is flexible and efficient to test different ones changing program arguments. Provide key modules for the underlying data-structure, text-analysis and visualization that are easy to reuse by other users, as there are not many good NLP libraries in java. (See pictures 1 and 2)
The inspiration
NLP processing is an area I believe can have a huge impact on helping society as there is much more information being generated vs the information humans can really process. Automatic text extraction has many potential uses such as: providing a consisting criteria to analyze texts, automating abstract generation, analyzing text on real-time (particularly useful on social networks), providing a summary or keywords from a file a user uploads to a web-site.
I spent a couple of weeks reading literature resources on keywords extraction and I found it a very interesting topic.
I have a passion for automating repetitive tasks, also I wanted a project in which I could apply the concepts learned in 591, 592, 593 and 594. Graph data structures are very interesting to me and I definitely want to use one in my project.
What it does
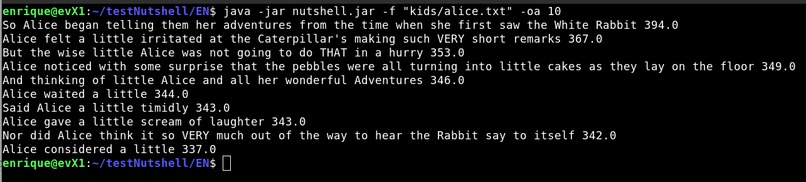
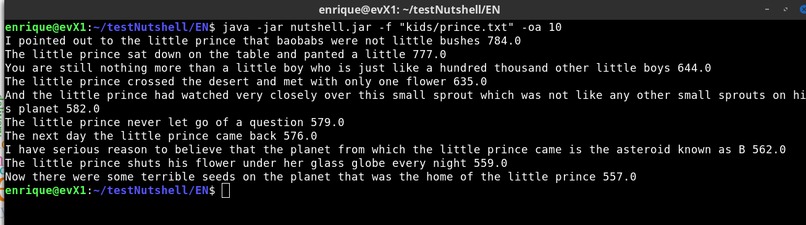
User provides a list of stopwords and a text file, program automatically extracts keywords it finds more relevant in the text file (picture 5) or extracts a list of key phrases to form an abstract. (picture 3)
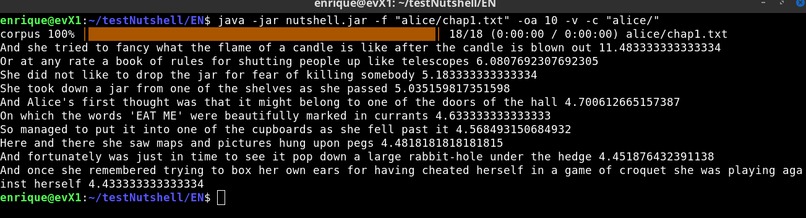
Optionally the user can provide a full text corpus in which case the program aims to find relevance vs such corpus. (Pictures 4 and 10)
Program outputs results with relative weight to the console in a way that program can be easily used as part of a more comprehensive analysis or project, this output only requires saving into a text file and can be exported to excel or matlab for example.
As an extra feature program may output a HTML file with a wordcloud visualization. (Pictures 1 and 2)
Implementation
Al the project is implemented in Java using Maven for handling dependencies and operate s through command line arguments only, use Apache Commons CLI for handling command line arguments. Program displays a progress bar for operations that take long. (See Picture 9 with CLI help) There is an option to output a HTML file with visualization of key results.
On RAKE [1] original paper and several other resources [2], it is suggested to do a matrix representation of word co-ocurrences, given that I intend nutshell to operate on large corpus, used Adjacency- List representation to make it more memory efficient and faster on adding new nodes. This data structure can be an alternate skeleton for further NLP projects.
Key Modules
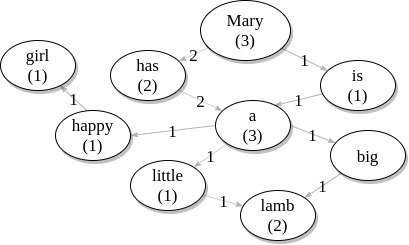
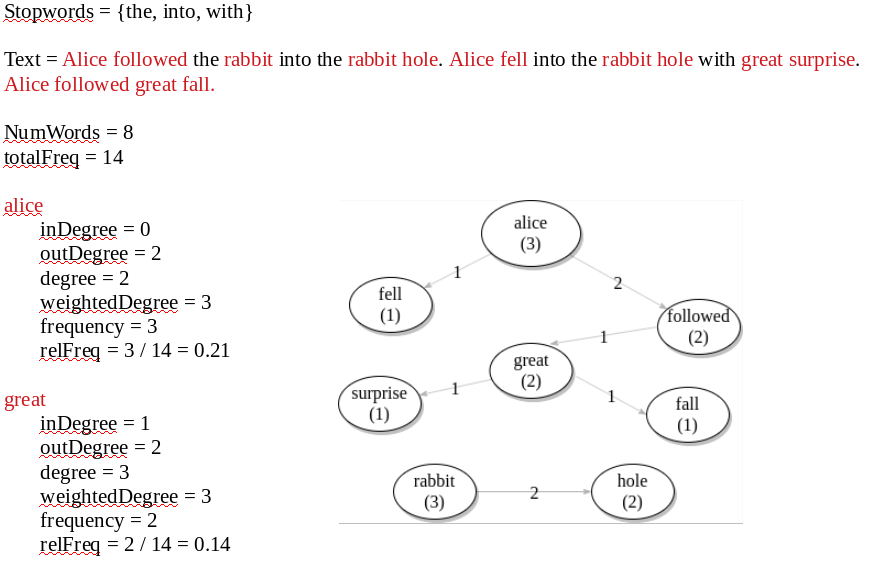
A weighted directed graph with words as nodes and relationships between words as weighted edges on frequency. • Node – word text, frequency of word, degree of word, probability of ocurrence. • Edge – word1–word2, frequency. See picture 11 for an example of how this data structure works.
Text Analyzer Takes a list of user provided stopwords. There are several online resources with sets of keywords in different languages, for testing will use those provided in link
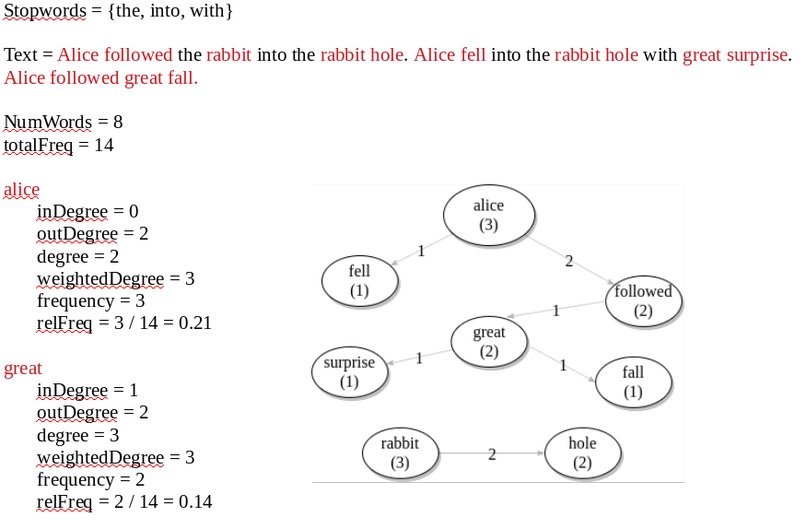
Given the several ways to extract keywords in the literature nutshell provides several scoring systems for a word (w) so the user can test and compare them. See pictures 14 ans 16
Challenges I ran into
Unit testing required much more time than I anticipated, since I was testing and adjusting my idea at the same time. I was stuck on learning to use Maven within my IDE. Keyword extraction is a very wide topic, took some time to digest the info and develop a tailored proposal to my needs.
Accomplishments that I'm proud of
The data structure is very efficient, for example parsing all the text in moby dick (not even removing stopwords) takes about 3 seconds.
I downloaded a dataset from Kaggle with several books of gothic literature, parsing the whole corpus and analyzing a book only takes around 11s in my computer. See link
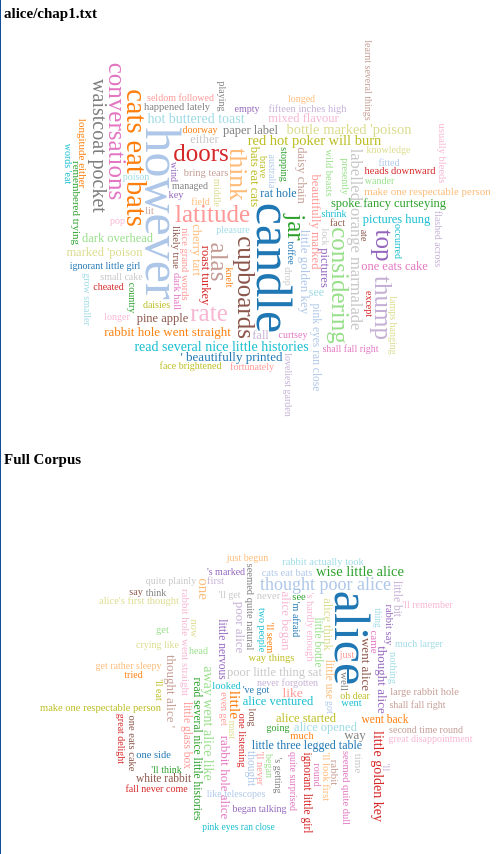
Program provides useful results, for example I compared keywords of a particular chapter in the book Alice in Wonderland using the whole book as corpus. see Picture 15: Extracting keywords of Chapter 1 vs Full Book on Alice in Wonderland.
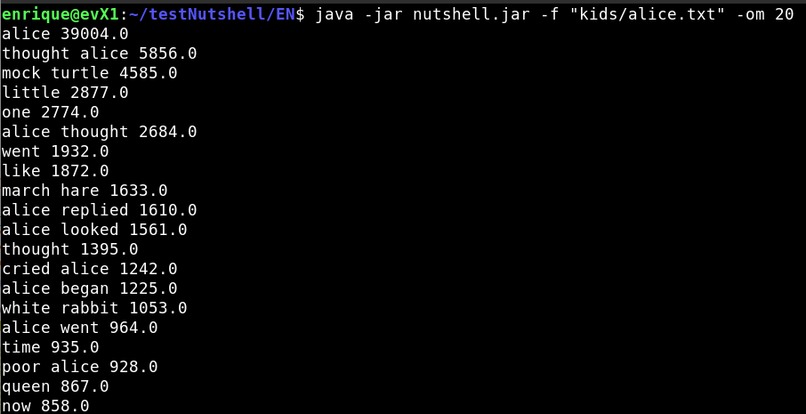
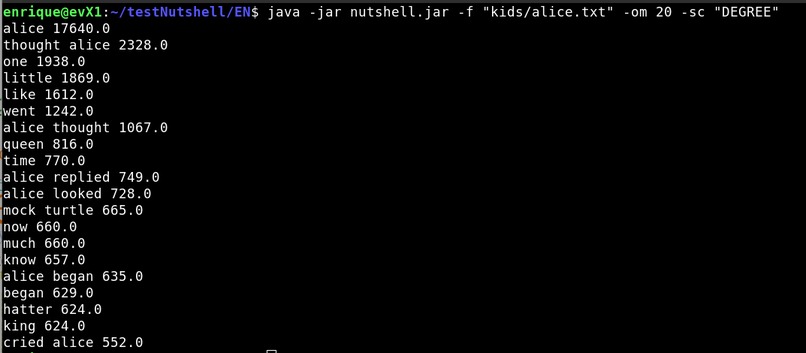
Was able to test several different scoring methods such as Word degree, Weighted degree, Relative frequency and Entropy. It is very interesting to see that different scoring methods are more suitable for certain texts opening the door to further improve keyword extraction. See Pictures 5 to 8
What I learned
Learned about keyword extraction. Also for this project I learned how to use Maven for handling dependencies, Apache Commons CLI, Progress Bar.
What's next for Nutshell
- Do quantitative comparisons of the different scoring methods with different texts kinds such as books, articles, etc. For defining which scoring system is best for what.
- Develop a comparative visualization of the different scoring system.
- Automatic generation of stopwords
- Compare results in different languages
- Develop more helper methods in WordsGraph (e.g. analyze paths, multiword nodes) to aid in developing different text analyzers
References
[1] Rose, Stuart Engel, Dave Cramer, Nick Cowley, Wendy. (2010). Automatic Keyword Extraction from Individual Documents. 10.1002/9780470689646.ch1. [2] Keyword Extraction https://monkeylearn.com/keyword-extraction/ [3] Website with stopwords in many languages https://www.ranks.nl/stopwords [4] Jason Davies Wordcloud library https://github.com/jasondavies/d3-cloud



Log in or sign up for Devpost to join the conversation.