Inspiration
48 million Americans have low health literacy. This means they cannot parse “% daily value," or decode “partially hydrogenated oils.” For the 34 million Americans with diabetes, the 108 million with hypertension, and the 55 million adults over 65, a nutrition label is not informative; rather, it is a wall of jargon in 8-point font on a crinkled wrapper under fluorescent lighting.
Existing solutions fail this population. Apps like Yuka provide generic ratings that ignore medical conditions, and critically, never speak aloud. For an elderly shopper with low vision standing in a grocery aisle, a silent app solves nothing.
We built NutriScan out of a straightforward conviction: the moment a person picks up a product and hasn’t yet put it in their cart is the only moment where a health intervention can actually change an outcome. Every food diary app in existence tracks what you already ate. NutriScan intervenes at the point of decision.
NutriScan is not a food diary. It is a shopping intelligence platform: the first tool designed specifically for the grocery aisle, not the kitchen.
What it does
NutriScan turns any food package into a personalized health briefing.
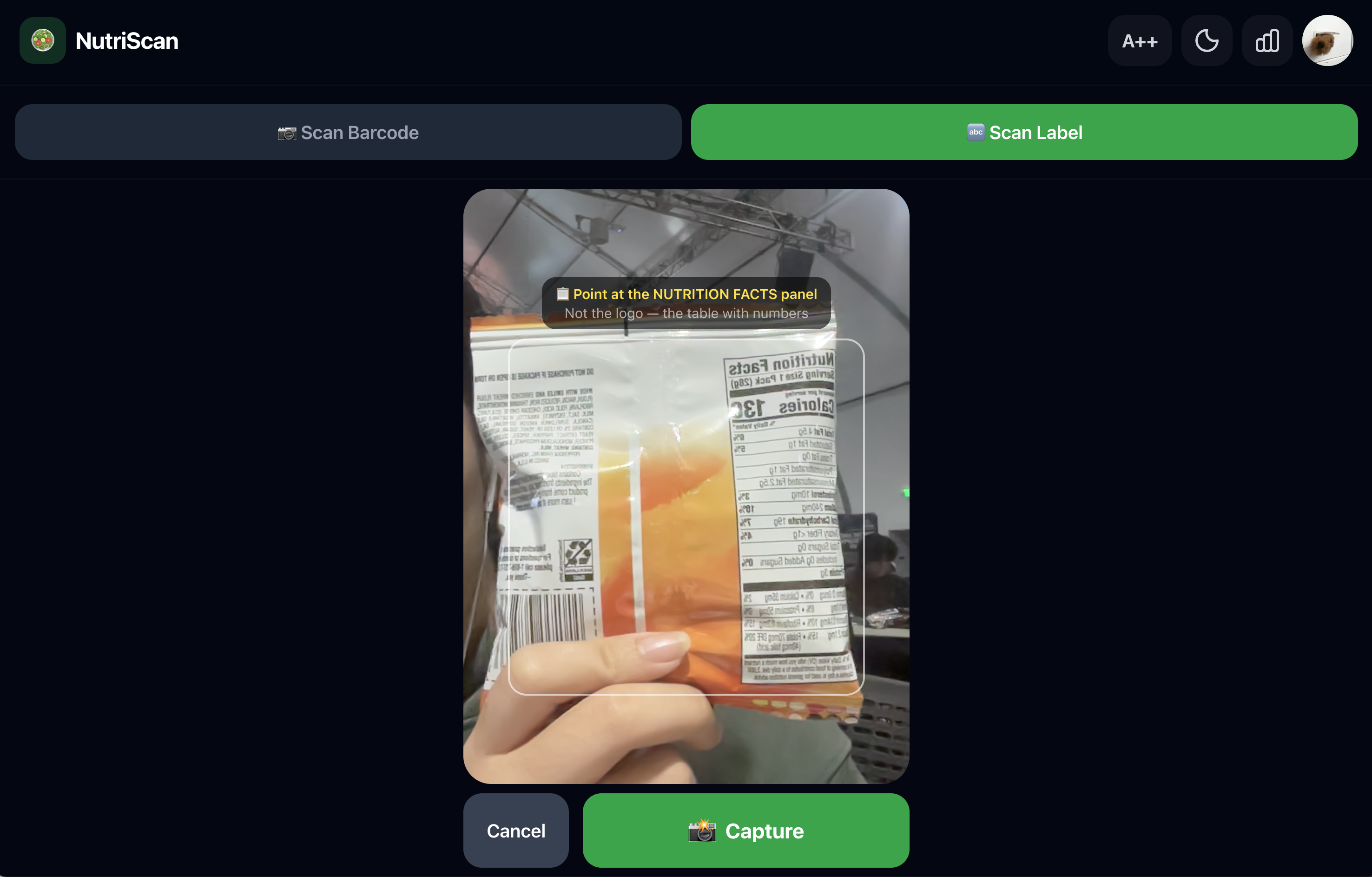
Scan: Point your camera at any nutrition label. NutriScan’s custom-trained YOLOv8 model instantly locates the nutrition facts panel. If the label is obscured, crinkled, or hard to read, switch to barcode mode: scan the product barcode and NutriScan instantly retrieves the full product data from the Open Food Facts database. Either way, tap once to analyze.
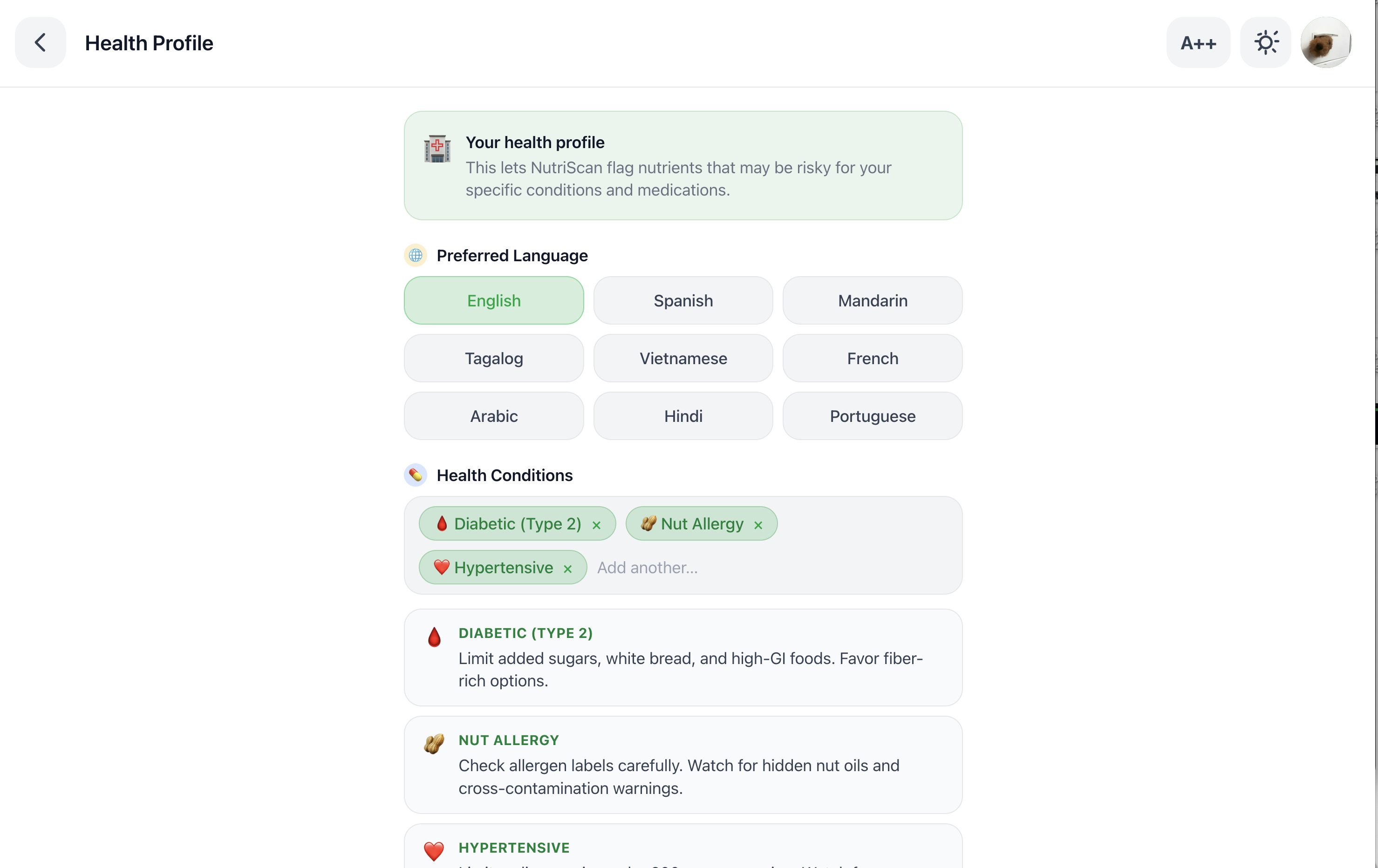
Understand: Within two seconds, you hear a plain-English verdict personalized to your health condition: “Avoid this: 28 grams of sugar per serving, three times your daily limit for diabetes.” Large text. Spoken aloud. No jargon, or percentages. Just a clear answer in your language.
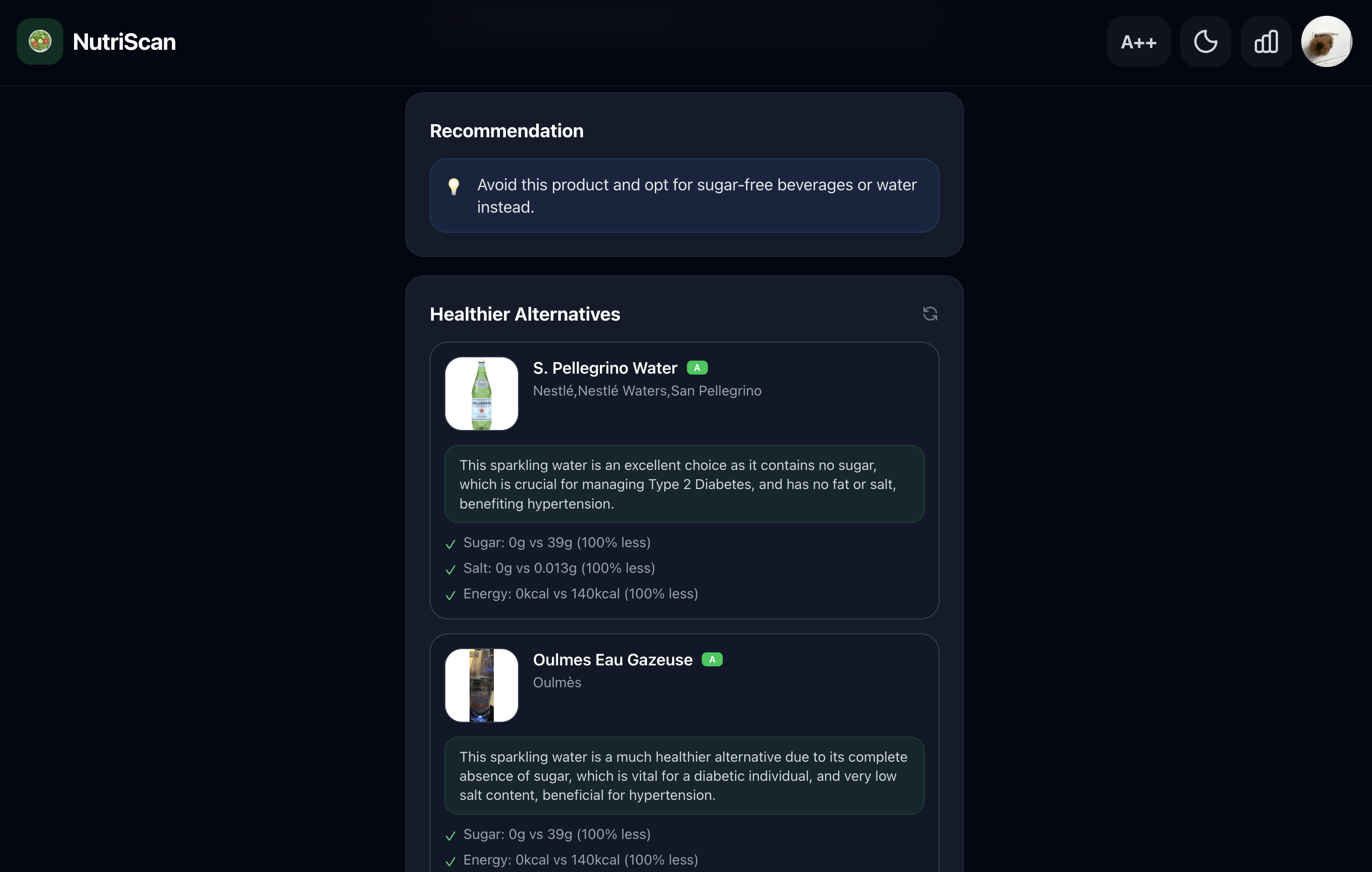
Choose better: NutriScan doesn’t stop at “this is bad.” It shows three real replacement products in the same category — sourced from Open Food Facts, with actual product photos and Nutri-Score grades — and explains exactly why each one is safer for your specific condition. A Coke replacement is always another beverage. A chip replacement is always another snack.
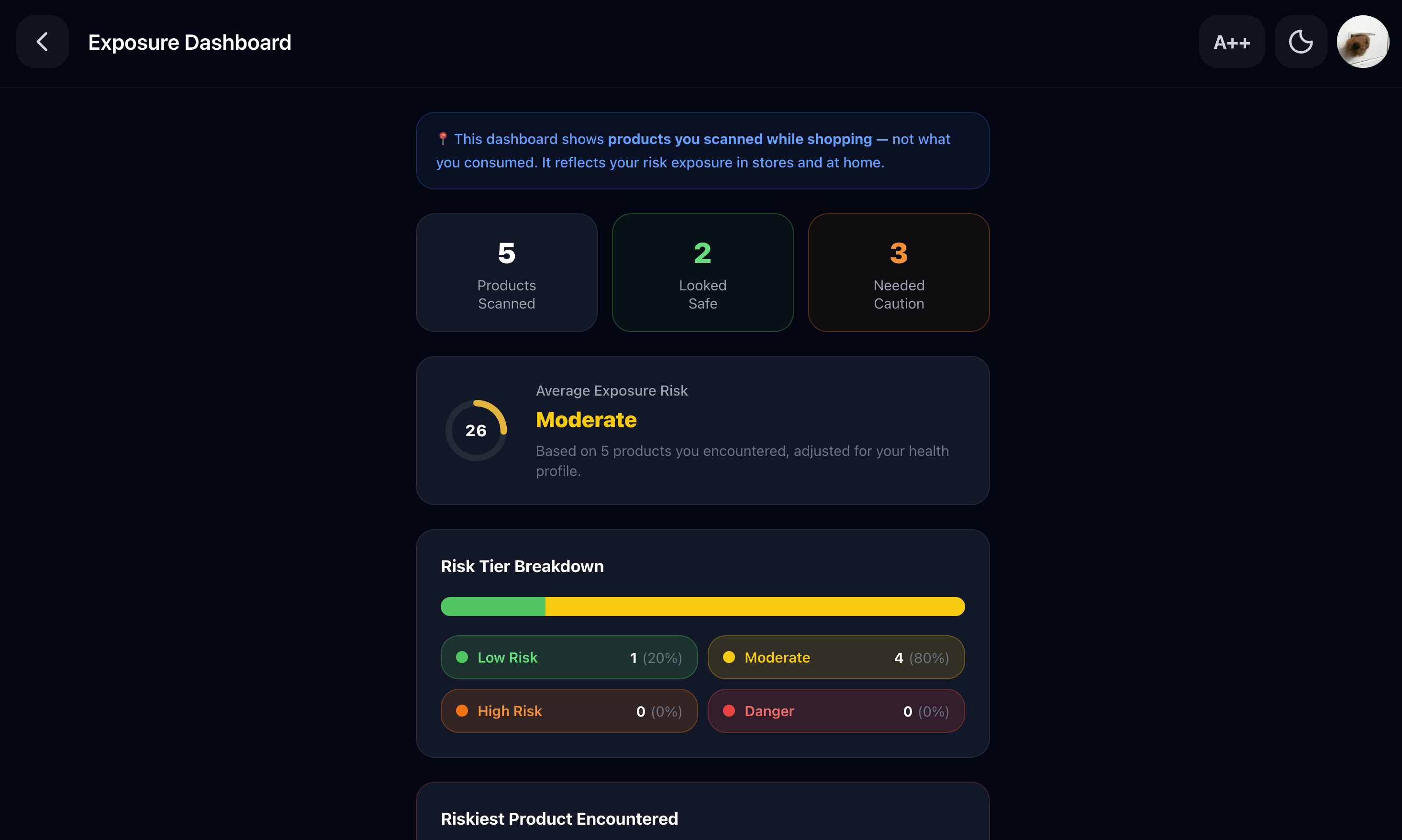
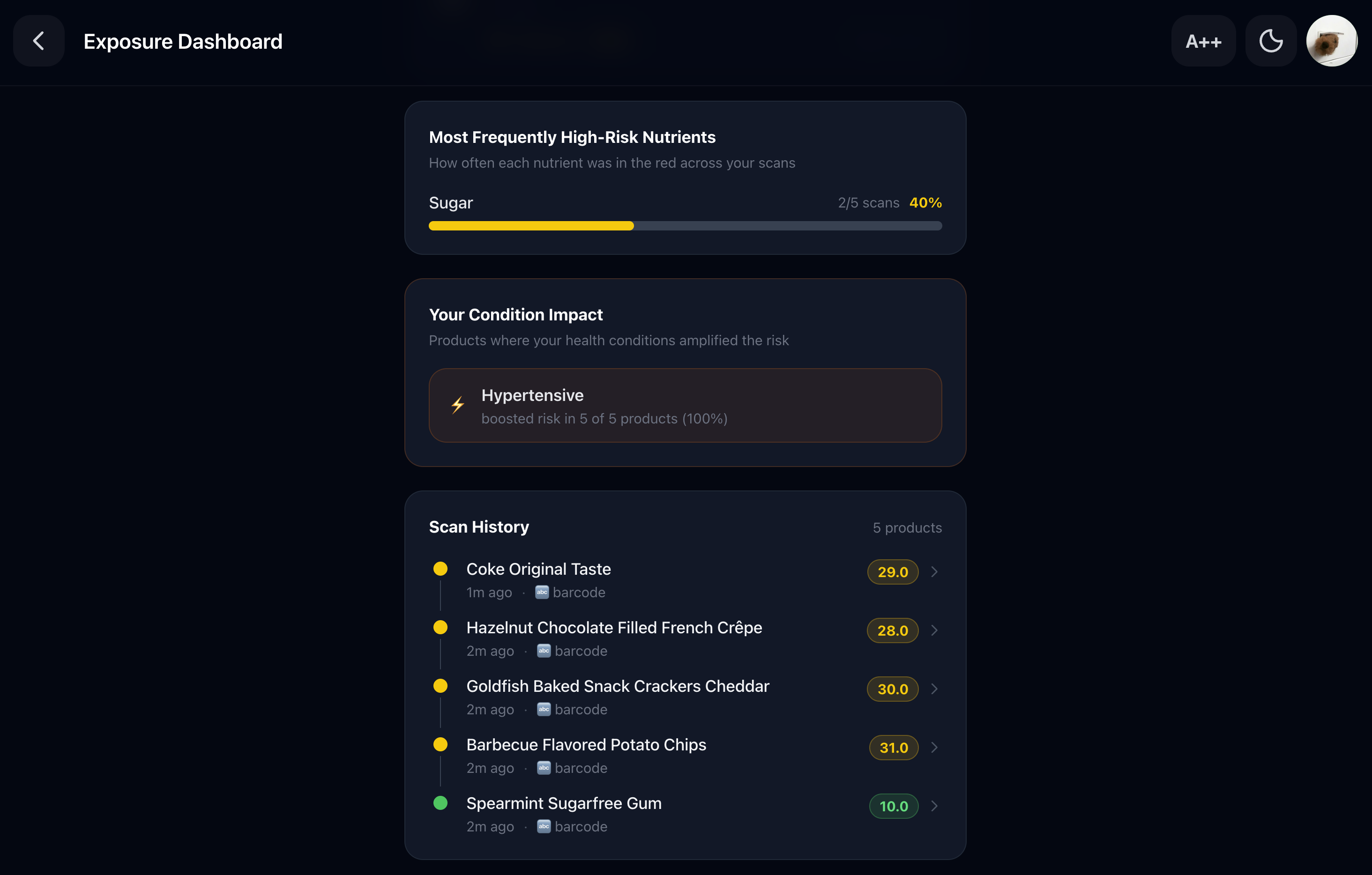
Track your shopping: Every scan is logged as a shopping exposure event on your personal dashboard. See how many high-risk products you encountered today, which specific risks you avoided, and get a weekly AI coaching summary: which product categories are most dangerous for your profile, and what one change would make the biggest difference.
How we built it
Custom Vision Model (YOLOv8): The browser captures a camera frame and sends it to our Flask backend. A self-trained YOLOv8 object detection model (Ultralytics 8.2) runs inference on the full image. The model was trained specifically to detect and localize FDA-format nutrition facts panels — not generic text, not barcodes, specifically the structured nutrition label layout. It returns a bounding box and a per-detection confidence score. Detections below 0.5 confidence are rejected, prompting the user to reposition rather than returning a degraded result.
Dual Input Path: NutriScan supports two input modes that cover the full range of real-world packaging conditions. In label scan mode, the YOLOv8 model localizes the nutrition facts panel, and the image crop is sent to Gemini for extraction. In barcode mode, the browser’s camera reads the product barcode and the backend queries the Open Food Facts API directly, returning structured nutrition data, product name, category, Nutri-Score, and ingredient list without any OCR or LLM extraction step required. Barcode mode is faster, requires no label to be visible, and draws from a database of over 3 million verified products. Both paths converge on the same risk scoring, Gemini summary, and RAG recommendation pipeline, so the user experience is identical regardless of input method.
Precision Crop + Gemini Vision: The detected region is cropped precisely to the bounding box and submitted as a JPEG to Google Gemini 1.5 Flash via the vision API. This is a deliberate architectural decision: Gemini receives only the isolated nutrition label, not the full product image. Cleaner input produces more accurate extraction and consumes fewer tokens. A structured extraction prompt returns verified JSON containing all key nutrient values, ingredients, allergens, and serving size.
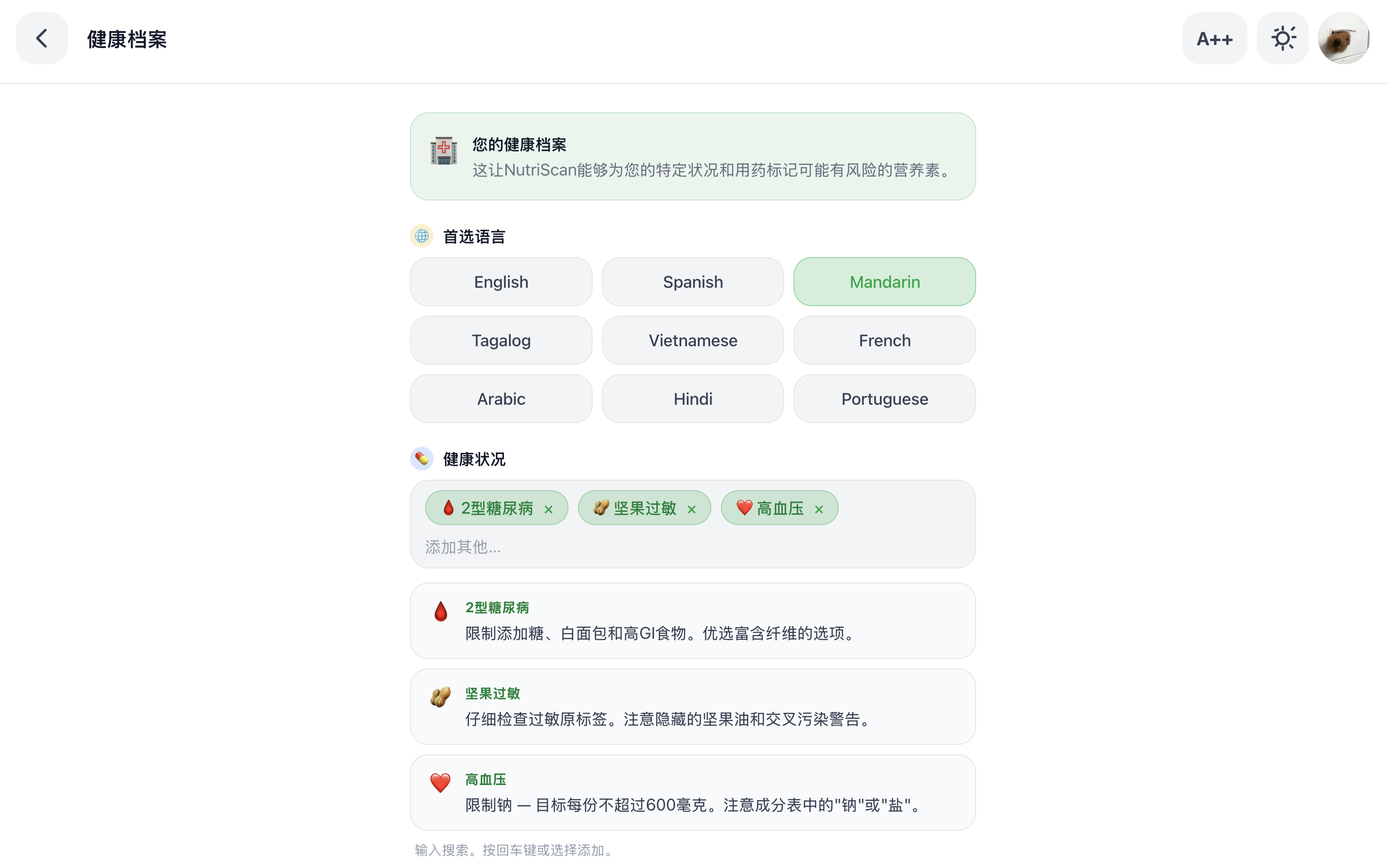
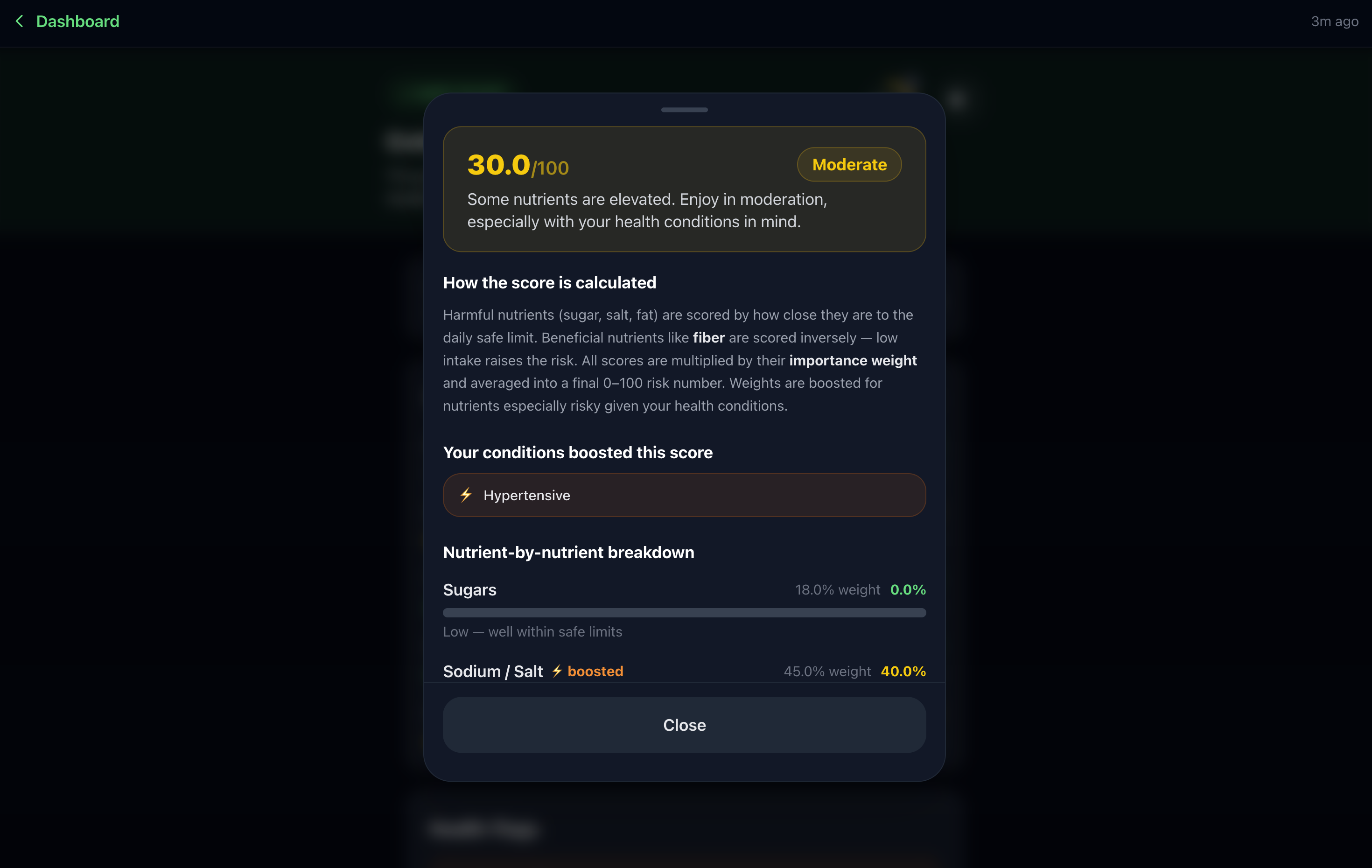
Condition-Weighted Risk Algorithm: Extracted nutrients are passed through a condition-weighted risk scoring algorithm. Each health condition carries a weight table calibrated to clinical dietary guidelines: for diabetics, sugar receives a 3× multiplier and fiber receives a −1.5× protective weight; for hypertensives, sodium receives a 3× multiplier and potassium a −1.0× protective weight. Weights are applied to normalized daily reference values, producing a 0–100 risk score that is specific to the user’s condition rather than generic. This score drives the verdict, the summary tone, and the swap ranking.
Two-Stage LLM Pipeline with Hallucination Guardrails: A second Gemini call receives the structured nutrition JSON, the risk score, the user’s health profile, and real replacement products sourced from the Open Food Facts API. Gemini is instructed to produce a plain-English summary at a 5th-grade reading level, personalized to the user’s conditions. We use Gemini’s responseMimeType JSON mode to enforce structured output and prevent markdown-wrapped responses. A hallucination verification layer cross-checks all numeric values in the response against the source OCR text. Fabricated numbers are flagged and re-prompted.
Advanced Features
Custom YOLOv8 detection model: self-trained on real-world nutrition label images to localize FDA-format panels with 99.5% detection accuracy on a held-out validation set of 25 labels tested under poor lighting conditions, including crinkled packaging and handheld camera angles.
3-step Retrieval-Augmented Generation architecture for replacement recommendations: (1) Gemini classifies the scanned product into its Open Food Facts category; (2) OFF is queried for real products in the same category with Nutri-Score A or B, sorted by the nutrient most critical to the user's condition; (3) Gemini ranks and explains the retrieved products using actual nutrition numbers. Hallucination is structurally prevented since the LLM reasons over retrieved facts, not inventing them.
Multilingual output: the system prompt can be parameterized to any target language, delivering the same plain-English summary in Spanish, Cantonese, Tagalog, or any language supported by Gemini and the Web Speech API.
Shopping intelligence dashboard: every scan is logged as a product exposure event. The dashboard shows how many high-, medium-, and low-risk products the user encountered in a session, which risks they avoided, and their worst single exposure without assuming anything was consumed.
Challenges we ran into
Real-world OCR on consumer packaging: Nutrition labels appear on crinkled foil, curved surfaces, partially occluded by price tags, under mixed store lighting, and in a wide range of font sizes and layout variants. Training the YOLOv8 model to generalize across this variance required careful dataset curation and augmentation. Confidence gating was essential, since a model that sometimes fails gracefully is more trustworthy than one that always returns a result.
Preventing LLM hallucination in a health context: A nutrition app that fabricates numbers is worse than no app at all for a diabetic user making a real medical decision. We built a numeric verification layer that compares all values in the Gemini response against the source OCR text. We also enforced JSON mode via responseMimeType to prevent the model from wrapping structured data in markdown, which would cause silent parse failures.
What's next for NutriScan
On-device model inference: convert the YOLOv8 model to CoreML (iOS) and TFLite (Android) for fully offline label detection with zero latency and complete privacy.
Longitudinal health intelligence: with opt-in consent, aggregate anonymized exposure patterns across users to identify which product categories pose the highest condition-specific risk in a given geography, population-level dietary intelligence from point-of-purchase data.
Retail partnership API: provide grocery chains with an opt-in integration that surfaces NutriScan’s risk scores at the shelf edge display, giving every shopper the same information without requiring them to open an app.
Self-improving model: build a feedback loop where users flag incorrect label detections, creating a continuously improving training set from real-world usage without manual annotation overhead.
Impact
NutriScan addresses a problem that is simultaneously massive in scale and almost entirely ignored by the consumer technology industry.
- 48 million Americans have low health literacy. They cannot reliably interpret nutrition information presented in standard label format.
- 34 million Americans have diabetes; dietary management at the point of purchase is one of the highest-leverage interventions available.
- 108 million Americans have hypertension; sodium awareness at the grocery shelf directly affects cardiovascular outcomes.
- 55 million Americans are over 65; this population has the highest rate of diet-related chronic disease and the lowest rate of digital health app adoption, in large part because those apps were not designed for them.
Every food app in existence was designed for a user who can read a nutrition label, owns a smartphone, and has the digital literacy to navigate complex interfaces. NutriScan was designed for everyone else.
The intervention point matters. MyFitnessPal, Cronometer, and Lose It all operate after the decision — logging what was already consumed. NutriScan operates before it, at the shelf, when the outcome can still change. This is not an incremental improvement on existing tools. It is a different category of tool entirely.

Log in or sign up for Devpost to join the conversation.