-
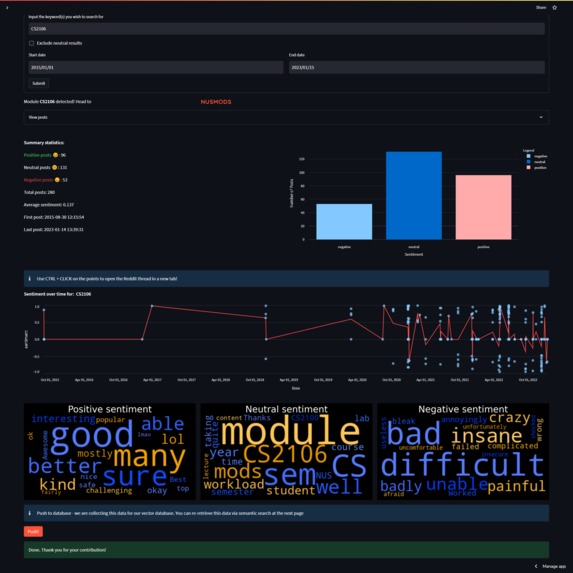
Main Dashboard - Keyword query: CS2106
-
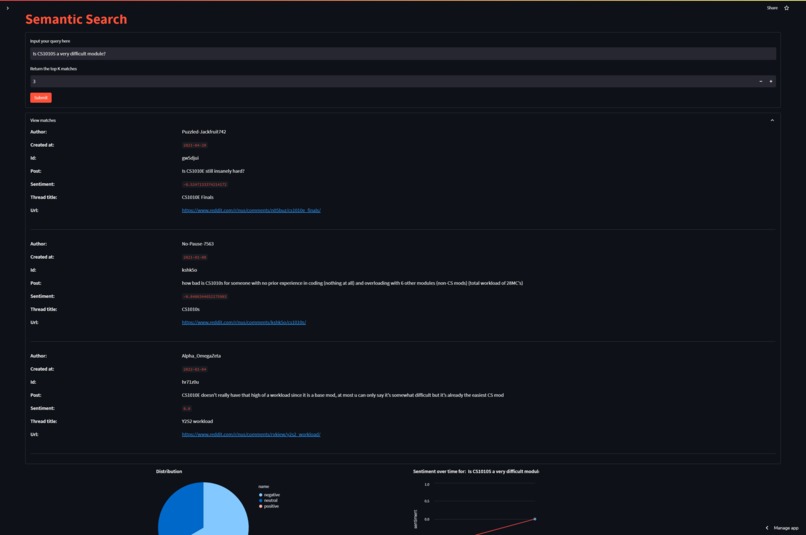
Semantic Search Page- Natural language query: Is CS1010S a very difficult module?


Inspiration
As NUS students, we are (unfortunately) all too familiar with r/NUS. Just like with many other NUS students, module registration at the start of every semester means days spent on Reddit constantly searching for things like modules, professors, and reviews. Our own NUS Reddit is often a very good source of information for us; however, with Reddit search being as troublesome it is, research is extremely painful. Therefore, we wished to create something that would make the process of learning people's opinions of NUS-related topics easier.
What it does
NUS-Sentiment is a sentiment checker which takes in keyword(s) and scrapes r/NUS for posts and comments containing the keyword(s). These posts and comments are run through a Sentiment Analysis Pipeline, which helps gauge people's sentiment toward the keyword(s).
These results are collected, and a quick summary is displayed via various data visualization methods. They can also be pushed to a vector database where in the SemanticSearch page of the web app, users can make natural language queries. Top ranked matches by cosine similarity will be returned in a user-friendly format.
How we built it
Coffee. LOTS of coffee. ☕
But seriously,
Model: The main model we used to predict the sentiment of post/comment is a pre-trained
cardiffnlp/twitter-roberta-base-sentimentfrom HuggingFace Transformers. Pre-processing tokens for our WordCloud was done withTextBlobData: All data used is scraped from r/NUS using
PRAWCharts: Altair, Matplotlib, Plotly Express
Database: We used Pinecone, a vector database to power our semantic search engine.Deta Base, a key-value store was also used to keep track of the most common keywords searched.
Frontend: Streamlit
Challenges we ran into
Accuracy 🎯 of our sentiment checker was affected when multiple NUS-related keywords were mentioned in the same post/comment. This was because the sentiment checker was unable to detect which keyword the sentiment detected should be attributed to. We fixed this by filtering our data to avoid such issues.
Language 🔤 is incredibly complex! If you think about it, you'll be able to come up with an unlimited amount of edge cases like the one above1. We contemplated heavily on how to consolidate this fact. In the end, we decided to mostly leave it up to the weights, biases and large samples.
Data 📊. Various functions on our site run on stored data. Thus, we needed to find ways to store data that we needed. We needed to store data for two main reasons: Semantic Search and Most Viewed Keywords. Therefore, we needed to learn how to use tools that would help us in storing and accessing said data. We did this by learning how to use the Deta and Pinecone to aid our features.
Rate Limits ⏱️. The way we scrape posts is by getting a top-level thread and then running BFS on its associated comment tree. Unfortunately, this approach very quickly triggers the 60 requests/min rate limit, so fetching posts for very popular keywords can take some time. Concurrent queries are also affected by this. A workaround for this is our SemanticSearch feature. This data is pushed to a database where it is essentially cached and can be fetched very quickly. With increased usage, the corpus of information in our database will eventually converge to what's available on Reddit.
Accomplishments that we're proud of
We are a very diverse team of people with different sets of skills, from different majors (DSA, Computer Science, Applied Math, Business Analytics). We were able to effectively put our skills together to create the best product we could deliver within 24 hours and learn a lot from each other.
What we learned
We became a lot more familiar with all the libraries and machine learning techniques used in our project. A lot of data wrangling with Pandas.
More importantly, we learned how to collaborate and work best with each other through the power of FRIENDSHIP!! 💪💪💪
What's next for NUS Sentiment
- Improve the accuracy of sentiment model by applying transfer learning.
- Further expand to allow scraping from other sources (Google, NUSWhispers, etc.).







Log in or sign up for Devpost to join the conversation.