
Numen — Intelligent Team Knowledge Automation
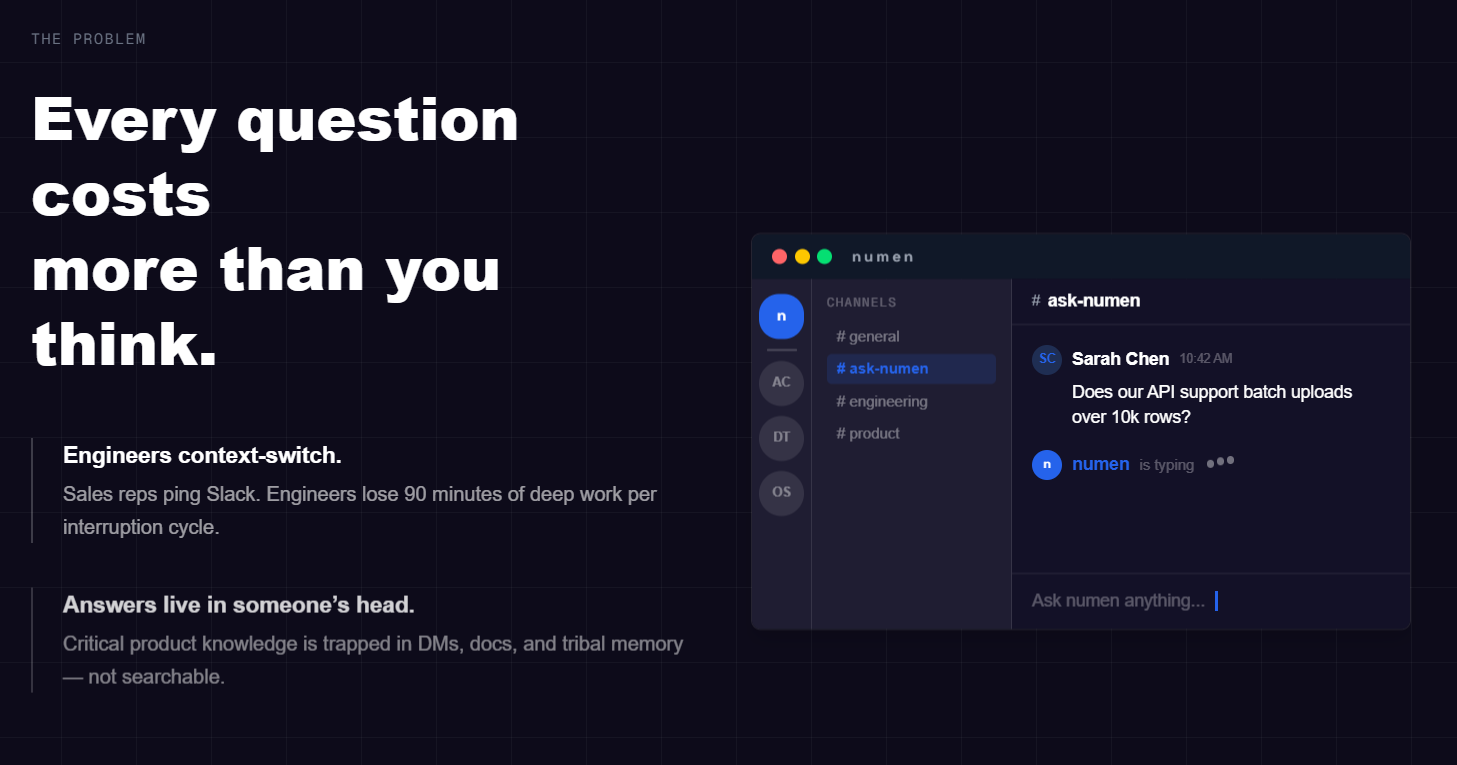
Every ping costs 90 minutes of deep work. We built the system that answers before anyone has to ask.
The Problem (Why We Built This)
Engineers lose ~90 minutes of focused work every time someone pings them on Slack with a question. Meanwhile, the answer often already exists — buried in DMs, stale docs, or someone's head. Critical product knowledge lives trapped and unsearchable. Teams wait on Slack threads. Context gets lost. Flow gets shattered.
We wanted to change that: a system that learns from the codebase, docs, and past conversations, then answers questions automatically — so engineers stay in flow and no one waits.
What Numen Does
Numen is an intelligent team knowledge automation platform. Here's the flow:
- Teams create workspaces and connect their GitHub repos.
- Numen builds a living knowledge graph that auto-updates on every PR merge.
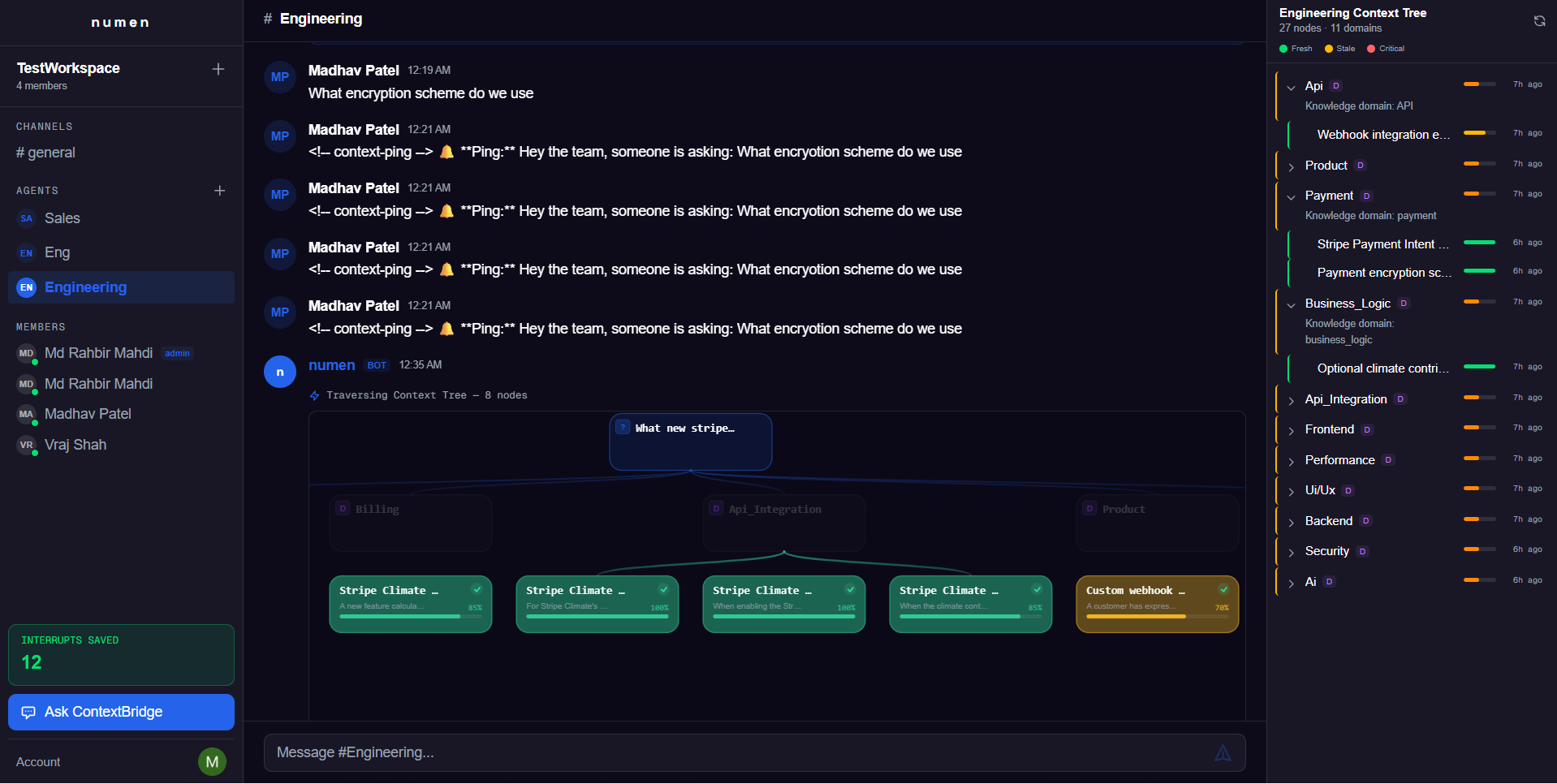
- Someone asks a question in plain English.
- Numen searches across code, documentation, and past answers — in under 5 seconds.
- If it finds a match: Returns an AI-generated answer with traceable sources and a visual answer path showing exactly how it reasoned through the codebase.
- If it can't answer: Smart-routes the question to the right engineer with pre-packaged context — no cold pings.
- Managers get visibility — question volume, auto-answer rates, knowledge gaps — all in one dashboard.
Multi-agent support lets teams spin up specialized agents for engineering, sales, and custom domains, each with scoped extraction and search.
How We Built It
| Layer | Technology |
|---|---|
| Frontend | Next.js 16, React 19, TypeScript, Tailwind CSS 4, Clerk, React Three Fiber (3D globe) |
| Backend | Python FastAPI, Uvicorn |
| Database | Supabase (PostgreSQL + RLS + Realtime) |
| AI | Google Gemini (embeddings, extraction, classification, Q&A) |
| Search | Moorcheh (vector search over PRs), pgvector (context tree) |
| Auth | Clerk (JWT verification) |
The frontend talks to the backend via REST. Workspace-scoped data access is enforced through Supabase RLS. GitHub webhooks trigger re-indexing on PR merges via Moorcheh, keeping the graph always current.
Architectural Workflow — The Technical Deep Dive
This is where the magic happens. Judges, read on.
High-Level System Architecture
┌─────────────────────────────────────────────────────────────────────────────────────┐
│ CLIENT (Next.js + React) │
│ Clerk Auth │ Supabase Realtime (messages) │ SSE Stream (bot answers) │
└─────────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────────┐
│ FASTAPI BACKEND │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────────────────┐ │
│ │ REST API │ │ Bot Pipeline│ │ Webhooks │ │ Background Processor │ │
│ │ workspaces, │ │ /ask (SSE) │ │ /github │ │ polls unprocessed messages │ │
│ │ agents, │ │ │ │ │ │ every 10s → extract → tree │ │
│ │ messages │ │ │ │ │ │ │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ └────────────────┬────────────────┘ │
│ │ │ │ │ │
│ └───────────────┼───────────────┼─────────────────────────┘ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────────────────────────────────────────┐│
│ │ ai.py │ context_engine.py │ bot_pipeline.py │ moorcheh.py │ supabase.py ││
│ └──────────────────────────────────────────────────────────────────────────────────┘│
└─────────────────────────────────────────────────────────────────────────────────────┘
│
┌───────────────────────────┼───────────────────────────┐
▼ ▼ ▼
┌─────────────────────┐ ┌─────────────────────┐ ┌─────────────────────┐
│ Supabase (Postgres) │ │ Google Gemini API │ │ Moorcheh API │
│ workspaces, agents, │ │ embeddings, extract │ │ vector search over │
│ tree_nodes, messages│ │ classify, Q&A │ │ GitHub PRs │
└─────────────────────┘ └─────────────────────┘ └─────────────────────┘
Workflow 1: Message → Knowledge Graph (Event-Driven Extraction)
How chat turns into searchable knowledge.
User sends message in workspace chat
│
▼
┌─────────────────────────────────┐
│ messages table │ ← processed = false
│ (Supabase Realtime notifies) │
└────────────────┬────────────────┘
│
▼ Background processor polls every 10s
┌─────────────────────────────────┐
│ process_message() │
│ 1. classify_message_type() │ → engineering | sales | general
│ 2. extract_context() │ → Gemini extracts structured facts
│ 3. upsert_tree_node() │ → generate embedding, cosine dedup
│ 4. mark processed │
└─────────────────────────────────┘
│
▼
tree_nodes (domain → module hierarchy, 768-dim embeddings)
Why it matters: The graph stays fresh. Every conversation feeds the system. No manual curation.
Workflow 2: Ask Pipeline — Classify → Search → Evaluate → Answer (Sub-5s)
The core loop that makes Numen feel instant.
User: "How does auth work for API keys?"
│
▼
POST /api/ask (SSE stream)
│
┌──────────────┴──────────────┐
│ Step 1: classify_question() │ → Gemini: question_type, domains, is_who_knows
└──────────────┬──────────────┘
│
┌──────────────┴──────────────────────────────────────────────────┐
│ Step 2: Route by type │
│ │
│ [Engineering + !who_knows] ──► Moorcheh fast path │
│ │ │ │
│ │ ├─ sync PRs to Moorcheh │
│ │ ├─ vector search over PRs │
│ │ └─ return answer + sources │
│ │ │
│ [Else] ──► Context tree path │
│ │ │ │
│ │ ├─ generate_embedding(question) │
│ │ ├─ cosine similarity over tree_nodes │
│ │ ├─ staleness_decay(confidence × e^(-days/14)) │
│ │ └─ sort by effective_confidence │
└──────────────┬──────────────────────────────────────────────────┘
│
┌──────────────┴──────────────┐
│ Step 3: Evaluate & Decide │
│ • confidence ≥ 0.82 → generate_answer() (Gemini) │
│ • 0.50–0.82 → answer with caveat │
│ • < 0.50 → route to expert (owner_id) │
│ • is_who_knows → find_experts() → return top 3 │
└──────────────┬──────────────┘
│
▼
SSE stream: status → traversal (node-by-node) → result
Frontend: ContextTraversal animates the reasoning path in real time
Why it matters: Judges see the full pipeline. Classify once, route smart. Engineering questions hit Moorcheh (PR index); everything else hits the context tree. Staleness decay keeps old nodes from over-ranking.
Workflow 3: GitHub PR → Knowledge (Webhook-Driven)
How the codebase stays in sync.
GitHub: pull_request (opened | synchronize | closed)
│
▼
POST /api/github (X-Hub-Signature-256 verified)
│
├─ Resolve workspace by repo full_name
├─ Extract diff_url from payload
│
▼ Background task
┌─────────────────────────────────────────────────┐
│ summarize_and_store_pr() │
│ 1. httpx.get(diff_url) → fetch diff │
│ 2. Gemini: summarize technical changes │
│ 3. upsert github_pull_requests │
│ 4. process_pr_into_context() │
│ ├─ extract_pr_facts() (Gemini) │
│ └─ upsert_tree_node() per fact │
└─────────────────────────────────────────────────┘
│
▼
tree_nodes updated; Moorcheh namespace synced on next /ask
Why it matters: Zero manual indexing. Merge a PR → knowledge graph updates. The system learns from code changes automatically.
Data Model (The Graph Structure)
workspaces
├── workspace_members (user_id, role, display_name, github_username)
├── agents (type: engineering | sales | custom)
│ └── tree_nodes (label, summary, embedding[768], parent_id, owner_id)
├── messages (channel, content, processed, extracted_context)
├── questions (question_text, answer_text, was_routed, routed_to)
├── github_pull_requests (pr_number, title, summary, diff_url)
├── sales_records
├── onboarding_sessions
└── analytics_daily (auto_answered, routed, hours_saved)
Tree structure: Domain nodes (e.g. "Authentication") are parents; module nodes (e.g. "API key validation flow") are children. Embeddings enable semantic search; parent_id enables hierarchy.
Challenges We Ran Into
| Challenge | How We Solved It |
|---|---|
| Knowledge graph structure | Modeled as a traversable tree (domain → module) with embeddings. Context engine handles upsert + cosine dedup so similar facts merge instead of duplicate. |
| Answer quality vs. speed | Optimized the pipeline: classify once, route by type. Engineering → Moorcheh (fast). Else → tree search with staleness decay. Target: sub-5s. |
| PR indexing noise | Iterated on extraction prompts. Extract structured facts (domain, label, summary) instead of raw diff. Filter by confidence. |
| Multi-agent scoping | Each agent has type and domain_scope. Extraction prompts are type-specific. Search is agent-scoped. |
| SSE reliability | Server-sent events with proper headers (Cache-Control: no-cache, X-Accel-Buffering: no). Frontend uses EventSource-style fetch with abort for cleanup. |
Accomplishments We're Proud Of
- 60%+ auto-answer rate — Most team questions answered without engineer interruption.
- Living knowledge graph — Auto-updates from every PR merge; never stale.
- Full answer traceability — Users see exactly how Numen reasoned through the codebase (traversal events → visual path).
- Smart routing with context — When Numen can't answer, it routes to the right engineer with pre-packaged context — no cold pings.
- Multi-agent architecture — Engineering, Sales, General agents with scoped extraction and search.
- End-to-end automation — GitHub webhook → knowledge graph update → instant answer. No manual steps.
What We Learned
- Modeling org knowledge as a graph — Keeping it current through event-driven updates (messages, PRs) beats batch re-indexing.
- Balancing retrieval and latency — The classify → route → search flow lets us hit different backends (Moorcheh vs tree) without slowing down.
- Signal vs. noise in PRs — Extraction prompts matter. Structured facts (domain, label, summary) beat raw diffs.
- Traceability > black box — Teams don't just want an answer; they want to see why the system is confident. The traversal visualization was a game-changer.
What's Next for Numen
- Slack & Teams integration — Answer questions directly in chat without leaving the conversation.
- More source connectors — Confluence, Notion, Google Docs, internal wikis.
- Analytics dashboard — Question trends, knowledge gap detection, team productivity metrics.
- Fine-tuned agents — Let teams train domain-specific agents on their own terminology.
- Enterprise hardening — SSO/SAML, audit logs, RBAC, SOC 2 compliance.
Built With
- claude-api
- clerk
- fastapi
- gemini-api
- github-webhooks
- moorcheh.ai
- next.js
- ngrok
- postgresql
- pydantic
- pyjwt
- python
- railway
- react-19
- react-three-fiber
- server-sent-events-(sse)
- supabase
- tailwind-css-4
- three.js
- typescript
- vercel







Log in or sign up for Devpost to join the conversation.