


Inspiration
Getting engagement is hard. People only read about 20% of the text on the average page.

After viewing the percent of article content viewed it shows that most readers scroll to about the 50 percent mark, or the 1,000th pixel, in Slate stories (a news platform).
This is alarming. Suppose if a company is writing an article about an event that they have sponsored. Having negligible engagement is not valued within the goals of any company spending money on marketing purposes.
Rather, what if this article was brought into a one minute format which would bring about to a much better engagement rate as compared to long pieces of text.
What it does ⚡️
nu:here, an online platform for people of all age levels to create and distribute customizable videos based on Wikipedia articles created via Artificial Intelligence 👀. With our platform, we allow users to customize many different video aspects within the platform and share it with the world.
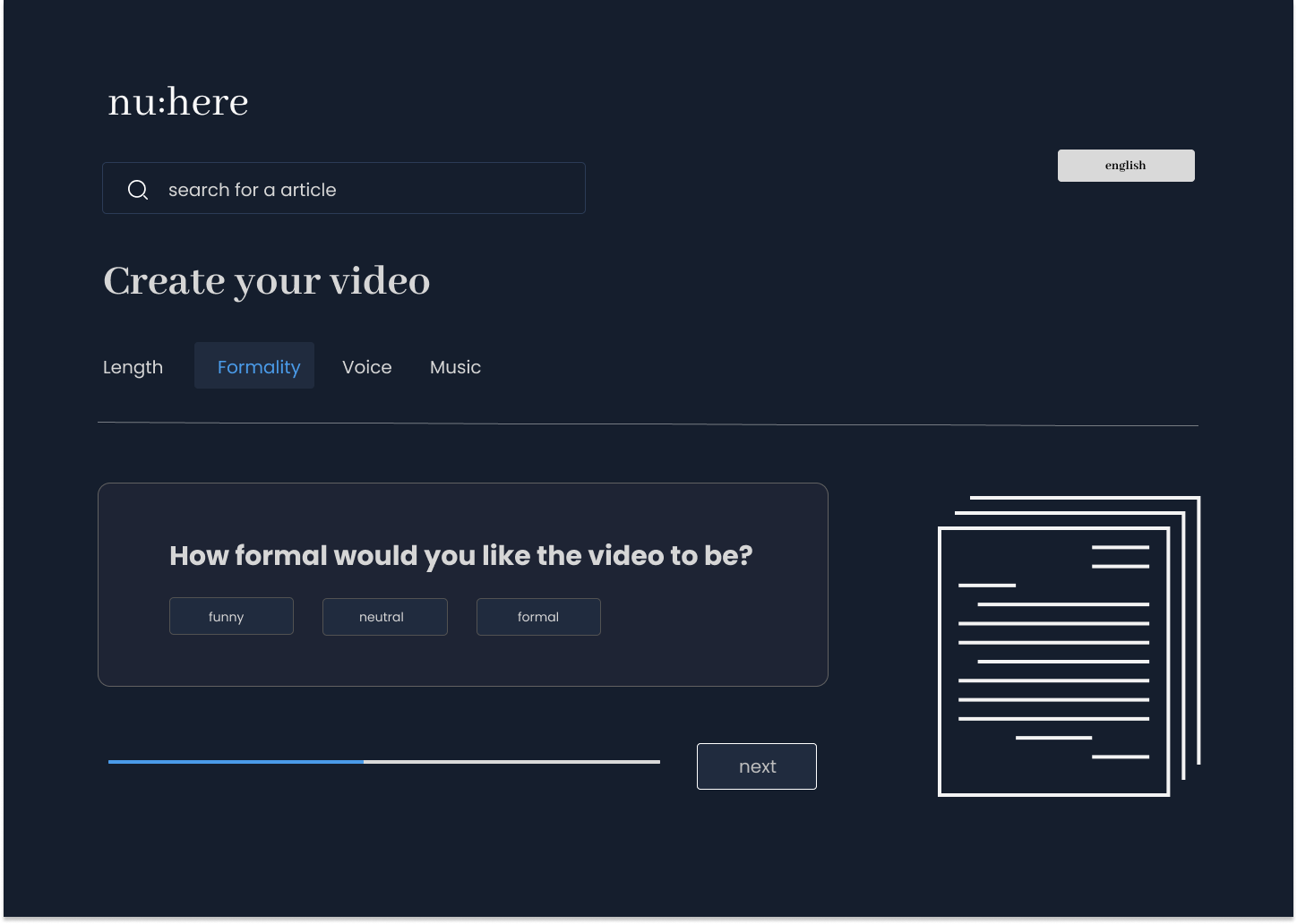
The process for the user:
- User searches for a Wikipedia article on our platform
- The user can start our video generation platform by specifying the length of the video that is wanted
- The user can specify the formality of the video depending on what the target audience is (For the classroom, for sharing information on TikTok & Instagram, etc.)
- The user can specify what voice model they want to use for the audio, using IBM’s text-to-speech API, the possibilities are endless
- The user can then specify what kind of background music they want playing in the video
- Once this step for the user is done, we are able to generate a short version of the Wikipedia article via co:here, create audio for the video via Watson AI, and generate keywords to use while finding GIFs, videos, and images on Pexels and Tenor, and put them in a video format.
How we built it ⚡️
We mashed up many cutting-edge services to help bring our project to life.
- Firebase Storage - Store Audio files From Watson in the Cloud ☁️
- Watson Text-to-Speech - Generate audio for the video 🎵
- Wikipedia API - Get all the information from Wikipedia ℹ️
- co:here Generate API - Generate summaries for Wikipedia articles. The generate API is also used to find the best visual elements for the video. 🤖
- GPT-3 - Help generate training data for co:here at scale 🤖
- Pexels API - Find images and videos to put into our generated video 🖼
- Remotion - React library to help us play and assist in generating a video 🎥
- Tailwind CSS - CSS Framework ⭐️
- React.js - Frontend Library ⚛️
- Node.js & Express.js - Frameworks 🔐
- Figma - Design 🎨
Challenges we ran into ⚡️
co:here
We were determined to use co:here in this project, but we ran into a few major obstacles.
First, every call to co:here’s generate API had to contain no more than 2048 tokens. Our goal was to summarise whole Wikipedia articles, which often contain far more than 2048 words. To get around this, we developed complex algorithms to summarize sections of articles, then summarize groups of summaries, and so on.
It was difficult to preserve accuracy during this process, because the models were not perfect. We tried to engineer prompts using few-shot learning methods to teach our model what a good summary was. We even used GPT3 to generate training examples at scale! However, we were always limited by the 2048-token limit. Training data uses up capacity that we need for input.
A strange consequence of few-shot learning is that the model would pick up on the contents and cause our training data to bleed into our summaries. For example, one of our training summaries was a paragraph about Waterloo. When we asked co:here to summarize an article about geological faults, it wrongly claimed that there was one in Waterloo.
We had a desire to fit our videos into a certain amount of viewing time. We tried to restrict the duration using a token limit, but co:here does not consider the limit when planning its summaries. It sometimes goes into too much detail and misses out on points from later on in the text.
Accomplishments that we're proud of ⚡️
- We are proud of using the co:here platform
- We are proud that we will be able to start sharing this platform after this hackathon is over
- We are proud that people will be able to use this
- We are proud of overcoming our obstacles
- We were able to accomplish all functionalities
- Most of all we had fun!
What we learned ⚡️
We learned so much throughout the course of the hackathon. Natural Language Processing is not a silver bullet. In order to get our models to do what we want, we have to think like them. We didn’t have much experience using NLP but now we will continue to explore more applications for it.
What's next for nu:here ⚡️
Adding features for users to customize and share videos is top priority for us on the engineering side. At the same time, we must address the elephant in the room: accuracy. In our quest to make information accessible and digestible, we must try as hard as we can to guard our users from mis-summarizations. Better models and user feedback can help us get there.
View Video Demo Here (if the Youtube Video does not work): Demo
Built With
- co-here
- figma
- firebase
- google-storage
- ibm-watson
- natural-language-processing
- pexels
- react
- tailwind
- wikipedia






Log in or sign up for Devpost to join the conversation.