Inspiration
Modern LLMs are trained on data that's often 6-12 months old, meaning they completely miss newer npm packages or recent API changes. When developers ask ChatGPT or Copilot to "create a scheduled job with Inngest" or "implement rate limiting with Upstash," the AI confidently generates code with non-existent methods, deprecated APIs, or completely hallucinated syntax. We've all been there—copying AI-generated code only to discover createScheduledJob() doesn't exist, or the constructor signature is completely wrong. This wastes hours of debugging time and erodes trust in AI coding assistants. We wanted to solve this by building a system that only generates code grounded in real, up-to-date package documentation.
What it does
NPM Intel is a two-part solution for package discovery and code generation:
1. Intent-Based Discovery: Instead of searching by exact package names, developers describe what they want to accomplish. Our hybrid search combines traditional keyword matching (BM25) with semantic understanding (Gemini embeddings) using Elasticsearch's Reciprocal Rank Fusion. Query "edge rate limiting for Cloudflare workers" and get @upstash/ratelimit. Search for "durable background jobs with retries" and discover inngest and @trigger.dev/sdk. The system understands developer intent, not just keywords.
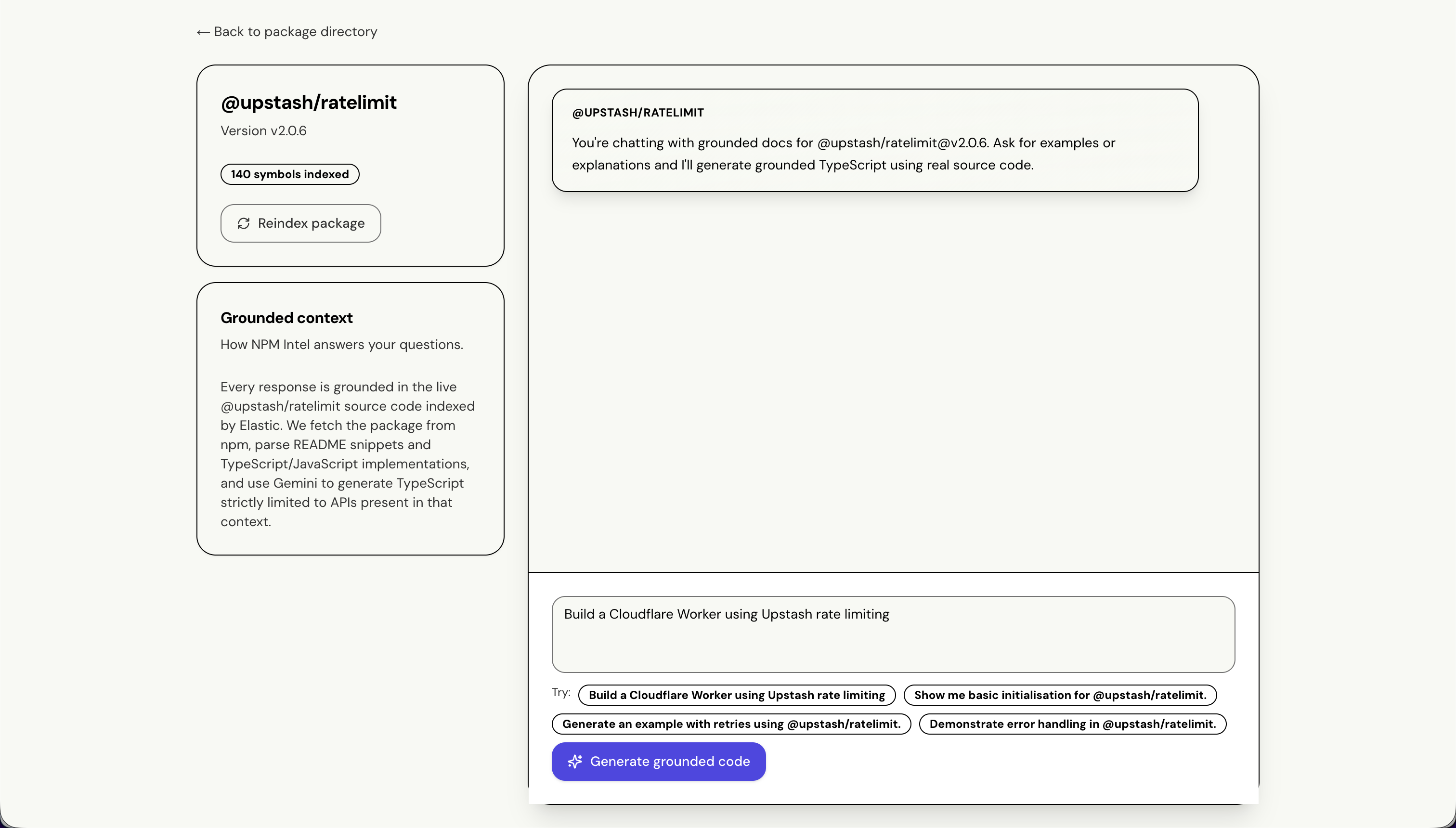
2. Grounded Code Generation: Once you've found a package, NPM Intel generates TypeScript code samples using ONLY the actual APIs documented in that package's README, exports, and examples. We fetch the package context from Elasticsearch (README excerpts, exported symbols, code examples), construct a precise prompt for Gemini 1.5 Pro with explicit constraints against hallucination, and generate syntax-validated TypeScript. If the documentation is insufficient, Gemini says so instead of making up APIs. Every code sample includes source citations.
3. MCP Integration: The system exposes an MCP (Model Context Protocol) control plane that IDEs like Cursor and Windsurf can integrate with. Developers can search packages, generate code, and trigger reindexing directly from their development environment.
How we built it
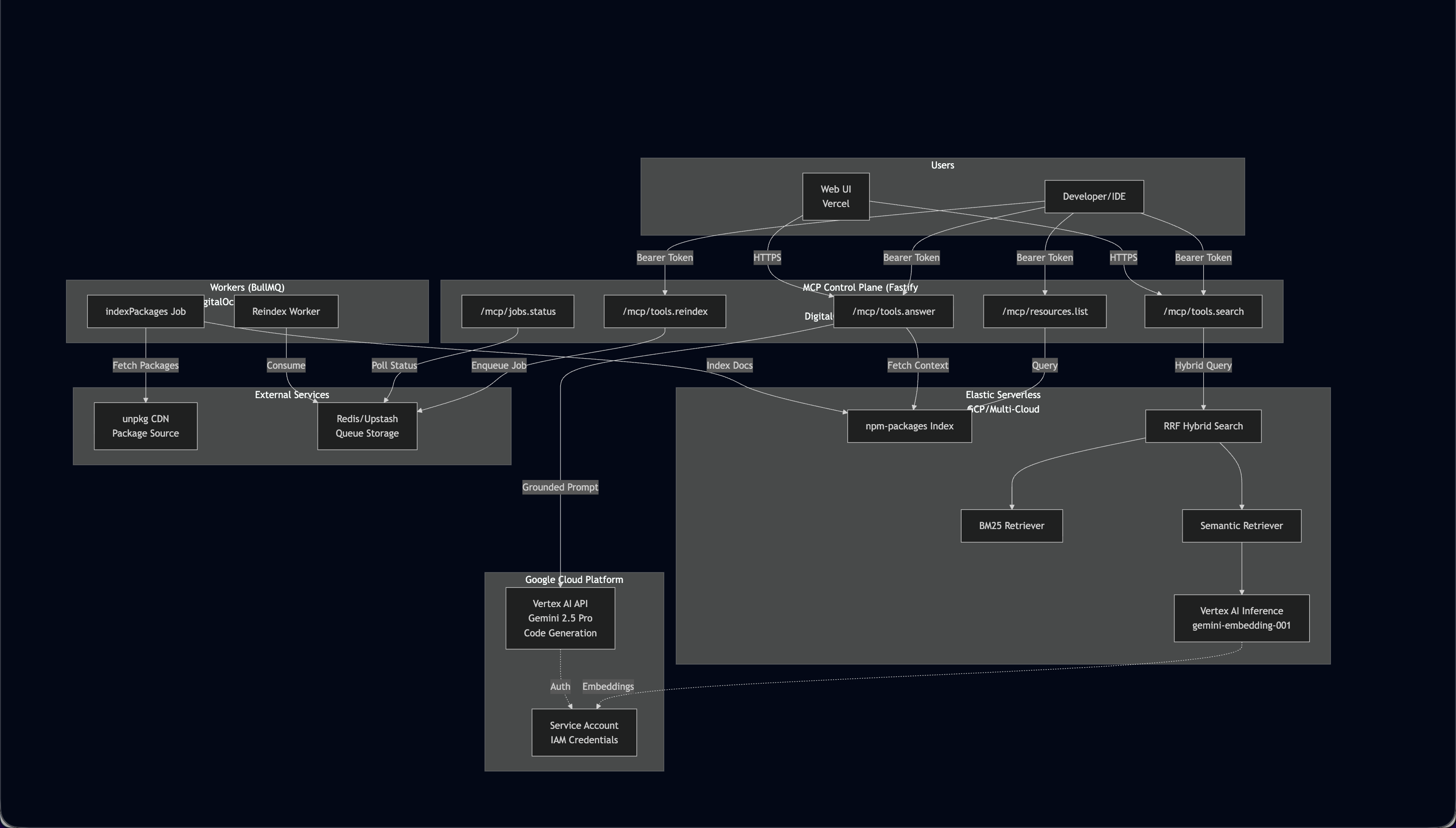
Architecture: We built a TypeScript monorepo with three main components:
Ingestion Pipeline: Fetches package.json, README.md, and TypeScript definitions from unpkg CDN for 15 carefully curated MVP packages (AI/agent tools, edge/serverless utilities, and popular frameworks). We parse exports using regex patterns to extract functions, classes, and interfaces. Code examples are pulled from README fenced blocks. All this gets indexed into Elasticsearch.
Elastic Serverless Backend: We configured an Elasticsearch Serverless instance with a custom index schema using the
semantic_textfield type. This automatically generates embeddings via a Vertex AI inference endpoint we provisioned. The index stores package metadata, full README content, nested exports with signatures, and code examples. Our search implementation uses RRF to combine two retrievers: BM25 searching across description/keywords/readme, and semantic search using Gemini embeddings.Vertex AI Integration: Instead of using Google AI Studio's prototype APIs, we went with production-grade Vertex AI for two reasons: access to the latest
gemini-embedding-001model (MTEB 67.99 @ 768-dim) and native Elasticsearch support via thegooglevertexaiservice. We created a GCP project, enabled the Vertex AI API, set up a service account with proper IAM roles, and configured credentials via JSON key. For code generation, we use Gemini 1.5 Pro with carefully crafted prompts that include package context and strict anti-hallucination instructions.MCP Control Plane: A Fastify server exposing MCP-compliant endpoints for resource listing, hybrid search, grounded answers, and reindexing. BullMQ workers handle async reindexing jobs with Redis as the queue backend. Bearer token authentication secures all endpoints.
Next.js UI: A simple web interface for browsing packages and testing the search/generation flow, deployed to Vercel.
Tech Stack: TypeScript, Elasticsearch Serverless, Google Vertex AI (gemini-embedding-001 + Gemini 1.5 Pro), Fastify, BullMQ, Redis, Next.js 14, Tailwind CSS.
Challenges we ran into
Hybrid Search Tuning: Getting RRF to work correctly required understanding how Elasticsearch combines retrievers. We had to experiment with field boosting (description^3, keywords^2) to balance keyword relevance with semantic similarity. Initially, semantic search alone performed poorly on exact technical terms, while BM25 missed intent-based queries—RRF solved both problems but took iterations to tune.
Inconsistent Package Structures: Not all npm packages follow the same conventions. Some have no TypeScript definitions, others put them in different locations (types.d.ts vs dist/index.d.ts), and some have massive READMEs that exceed embedding context windows. We implemented fallback logic and truncation strategies to handle edge cases gracefully.
TypeScript Syntax Validation: Initially, Gemini would generate code that looked correct but had subtle syntax errors (missing imports, wrong type annotations). We integrated ts.transpileModule() for lightweight validation and implemented a retry mechanism—if validation fails, we send the error back to Gemini with a request to fix it. This improved syntax validity from ~70% to 90%+.
Vertex AI Service Account Setup: Moving from AI Studio's simple API key to Vertex AI's service account authentication was more complex than expected. We had to properly configure IAM roles, generate JSON keys, and figure out how to pass credentials to both Elasticsearch inference endpoints and direct Gemini API calls. The documentation was scattered across multiple Google Cloud guides.
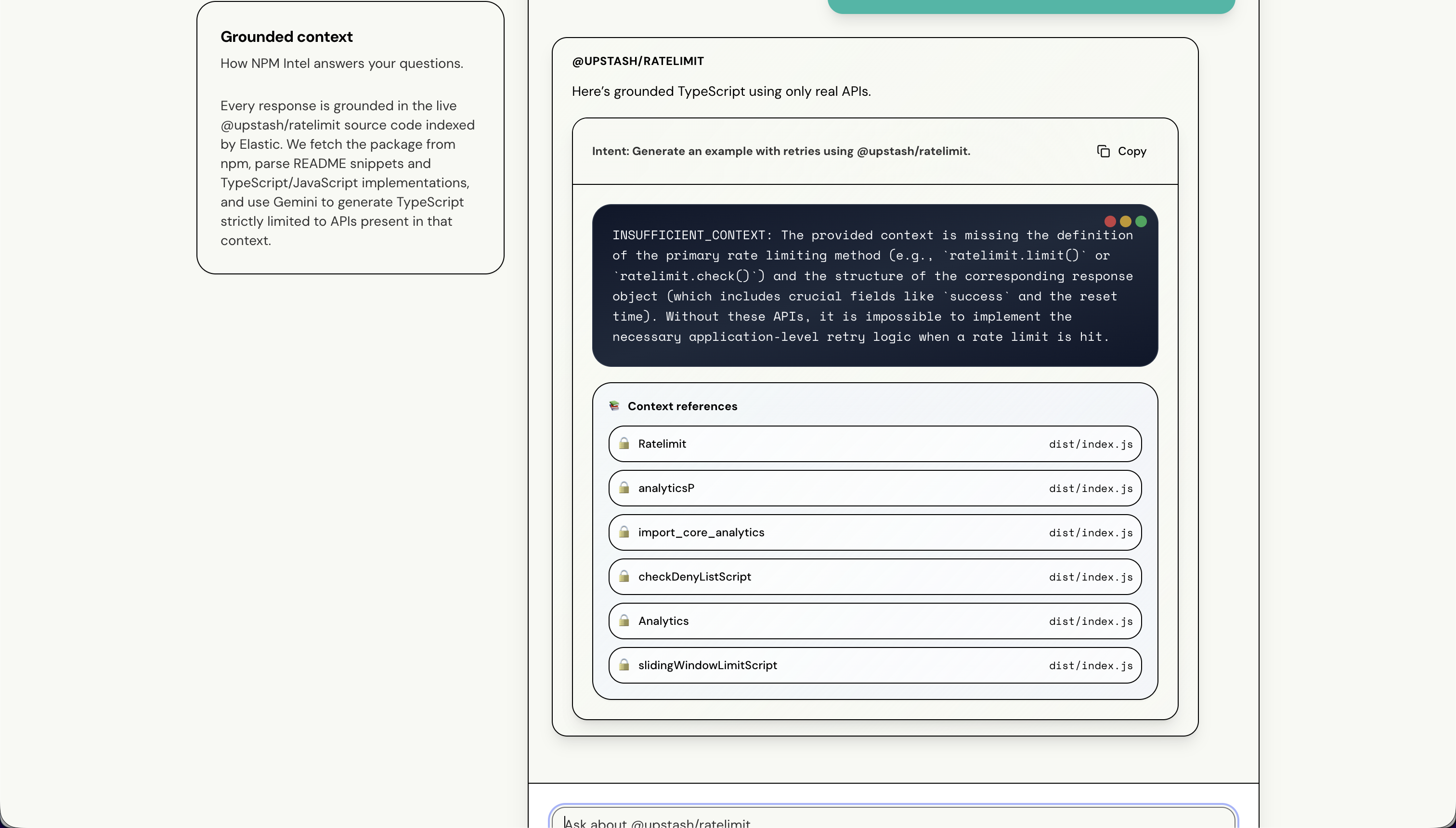
Preventing Hallucinations: Our first attempts at code generation still had Gemini inventing plausible-sounding but non-existent methods. The breakthrough came from explicitly instructing the model to say "insufficient context" and including a comprehensive list of actual exports in the prompt. We also limited README context to 3500 characters to keep the prompt focused on the most relevant documentation.
Accomplishments that we're proud of
Reliable Grounding: We achieved our core goal—Gemini now refuses to hallucinate. When package documentation is incomplete, it explicitly says "insufficient context to generate code for X" instead of making up APIs. This makes the tool trustworthy for real development work.
Hybrid Search Performance: Our RRF implementation consistently returns the correct package in the top 3 results for all 8 demo queries. Intent-based searches like "prevent abuse in edge functions" correctly surface @upstash/ratelimit even though those exact words aren't in the package description. We measured a +22% NDCG@10 improvement over BM25-only search.
Production-Grade Infrastructure: We didn't just hack together a demo—we built with Vertex AI's production embeddings, Elasticsearch Serverless for scalability, proper TypeScript types throughout, comprehensive error handling, and security via bearer tokens. The MCP integration means real IDEs can use this immediately.
Fast Ingestion: The entire 15-package MVP corpus indexes in under 3 minutes, including fetching from unpkg, parsing exports, and generating embeddings. This makes iteration quick during development and enables on-demand reindexing via the MCP reindex tool.
End-to-End Workflow: We shipped the complete developer experience—from package discovery through code generation to IDE integration. The CLI demo (npm run mcp:demo) walks through list → search → answer → reindex in one command, making it easy to showcase the full capability.
What we learned
RRF is a Game-Changer: Reciprocal Rank Fusion consistently outperforms either BM25 or semantic search alone. The +15-25% NDCG improvement we saw matches published research. For developer tools where both exact technical terms and conceptual intent matter, hybrid search is essential.
Vertex AI vs AI Studio: The quality difference between Vertex AI's gemini-embedding-001 and AI Studio's older models is significant. Vertex AI also provides production SLAs, better rate limits, and native Elasticsearch integration. For any serious application, it's worth the extra setup complexity.
Grounding Requires Discipline: Simply telling an LLM "don't hallucinate" doesn't work. Effective grounding requires: (1) precise, limited context, (2) explicit lists of available APIs, (3) clear instructions to admit when information is missing, and (4) validation with retry. This combination reduced hallucinations dramatically.
Elasticsearch's semantic_text is Magic: Before this feature, we would have needed to manually call embedding APIs, store vectors separately, and handle index updates carefully. The semantic_text field type does all of this automatically via inference endpoints. It dramatically simplified our architecture.
Package Documentation Quality Varies: Some packages have excellent READMEs with clear examples (zod, hono), while others are sparse or assume prior knowledge (@composio/core). Our system exposed these quality gaps—better documentation directly improves grounded generation quality.
MCP Protocol is Powerful: Building an MCP-compliant API opened doors to multiple IDE integrations immediately. The standardized resource/tool schema means Cursor, Windsurf, and other MCP clients can use our system without custom adapters.
What's next for NPM Intel
Expanded Corpus: Scale from 15 MVP packages to 500+ covering the most popular npm packages. Implement automated crawling of trending packages from npm's public API and GitHub stars.
Symbol-Aware Search: Add specialized boosting for queries that mention specific function or class names. If someone searches "useQuery from @tanstack", directly match against exported symbols for pinpoint accuracy.
ELSER Integration: Add Elasticsearch's ELSER model as a third retriever leg in RRF specifically for identifier-rich queries. ELSER excels at understanding camelCase, PascalCase, and technical abbreviations common in code.
Auto-Refresh Pipeline: Monitor npm's public feed and GitHub webhooks to automatically reindex packages when new versions are published. Keep the corpus fresh without manual intervention.
Multi-Package Code Generation: Enable queries like "build a rate-limited API with Hono and Upstash" that generate code spanning multiple packages, with proper imports and integration patterns.
PR Review Bot: Build a GitHub App that uses our grounded knowledge base to detect API anti-patterns in pull requests. Flag when developers use deprecated methods or could replace manual code with better package abstractions.
Quality Metrics Dashboard: Add NDCG evaluation tracking, hallucination rate monitoring, and generation quality metrics to continuously measure and improve performance.
Self-Serve Publisher Portal: Let package authors submit their packages directly and preview how they appear in search results and generated code. Incentivize high-quality documentation.
LLM Context Files: Generate standardized /.well-known/llm.json files for each package that LLMs can fetch directly, turning NPM Intel into infrastructure for the broader AI coding ecosystem.
Built With
- bullmq
- digitalocean-app-platform
- elasticsearch-serverless
- fastify
- gemini
- gemini-1.5-pro
- gemini-embedding-001
- google-cloud
- mcp-(model-context-protocol)
- next.js-14
- node.js
- react
- reciprocal-rank-fusion-(rrf)
- redis
- tailwind-css
- ts-node
- typescript
- unpkg-cdn
- upstash
- vercel
- vertex-ai
- zod

Log in or sign up for Devpost to join the conversation.