-
-
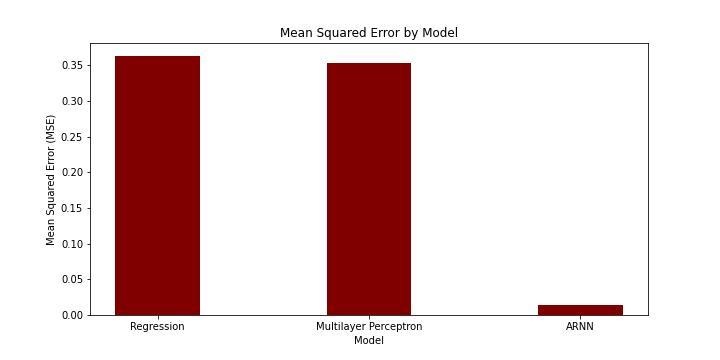
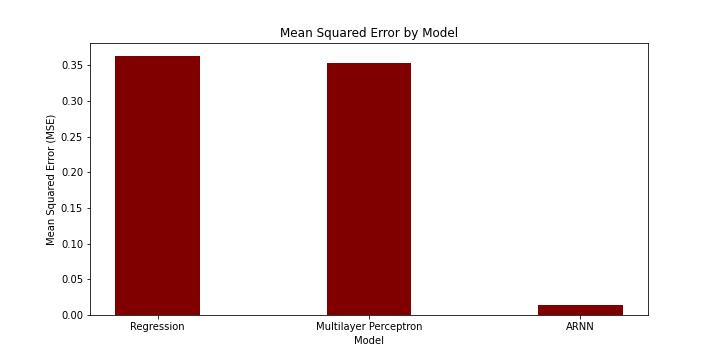
Untransformed MSEs from each model in testing.
-

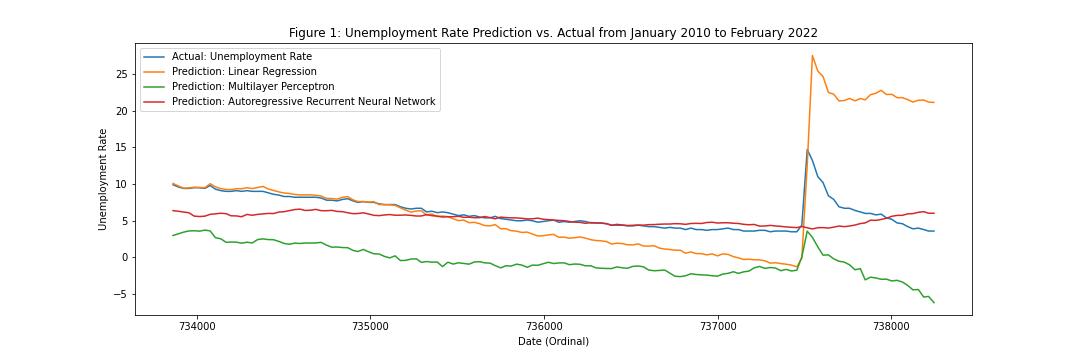
Predictions of unemployment from each model.
-
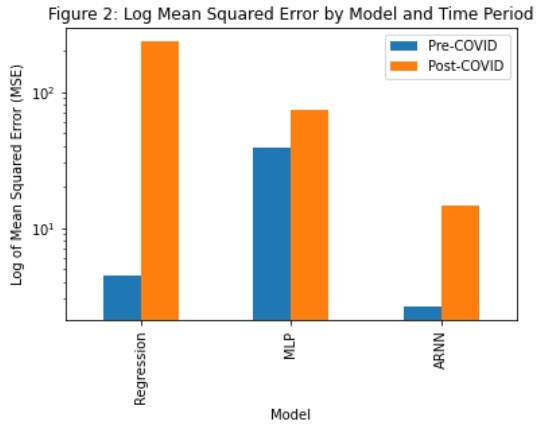
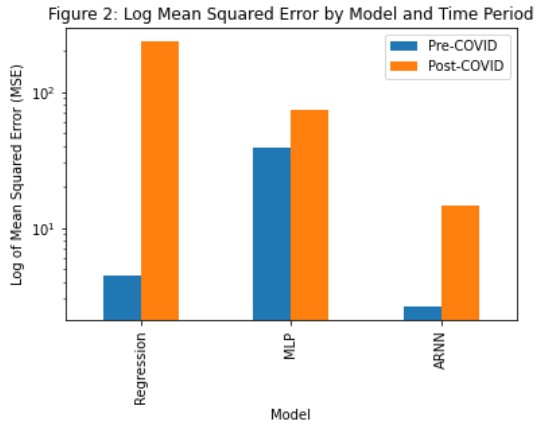
Transformed MSEs from each model in each sub-period in testing.
Introduction: The paper’s objectives are to enable more real-time determination of Gross Domestic Product, since these results are often released and revised several months after their period of study has ended. This will be a regression type problem, though we may use unsupervised learning techniques for selection of relevant variables.
Related Work: https://opportunityinsights.org/wp-content/uploads/2020/06/Short_Covid_Paper.pdf This paper accomplishes a similar goal of tracking economic data in real time. However, the model is not deep learning-based, and uses private sector data. We will use public sector data and use more complex techniques.
Data: What data are you using (if any)? We plan to use public economic data from the Federal Reserve Economic Data program at the Federal Reserve Bank of St. Louis, as well as public economic and demographic data from the U.S. Census Bureau's Current Population Survey. These datasets combined should be less than 500 MB, but significant preprocessing will be needed to ensure the datasets are all in the same shape.
Methodology: We are planning to use a recurrent neural network for our predictions.
Metrics: We plan to estimate our models for each month between January 2000 and December 2018. We will then compare our predictions to the actual, revised GDP figures to determine accuracy.
Ethics: What broader societal issues are relevant to your chosen problem space? More accurate now-casting of economic variables can help politicians develop more targeted, equitable, and informed public policy interventions to major problems.
Why is Deep Learning a good approach to this problem? Deep learning techniques allow us to have flat priors about which particular datasets and datapoints are useful, then to use these to inform our predictions.
Division of labor: Jay will be responsible for sourcing data and programming in R. Shivani and Jay will both be responsible for coding in Python.
-- REFLECTION 2: --
Github Repository Link: https://github.com/JayRPhilbrick/dl-economy-jayandshivani
Introduction: The paper’s objectives are to enable more real-time determination (nowcasting) and future determination (forecasting) of Gross Domestic Product and unemployment rates, since these results are often released and revised several months after their period of study has ended. This will be a regression type problem.
Challenges: What has been the hardest part of the project you’ve encountered so far? Our most significant challenge is determining the level of complexity with which to pursue and implement our models. There are many different packages that we could use to complete this regression-type task. Scikit-learn would be a streamlined solution, allowing us to implement our model in just a few lines, whereas coding it in keras would be far, far more involved. As of right now, we are implementing models from simplest to most complex, and will settle on the most complex solution we can manage.
What this means in practice is that we have implemented a regression and a regression-type multilayer perceptron in sklearn, and are implementing our autoregressive neural network in keras/tensorflow. As such, the two baseline models implemented in sklearn were very simple to write, whereas the ARNN is far more complicated: it is essentially a modification of a standard recurrent neural network, but it varies significantly from the one presented in class, given the very different datasets/use cases.
ARNNs are also just a bit conceptually difficult, but I believe we are well on our way to a working one.
Insights: Are there any concrete results you can show at this point? How is your model performing compared with expectations?
Yes: at this point, our linear regression model is yielding a mean squared error of 0.0028346. One prediction, for example, is labeled as 9.0 and is predicted as 9.024. Our multilayer perceptron, by contrast, performs terribly, yielding an MSE of 15481770.33229501 with the same example having an actual value of 9.0 and being precited as 2056.2517233851186.
We have not yet run our complex model, but it is odd that our multilayer perceptron model is performing worse (and so significantly worse) than our simple linear regression, so we will seek to investigate that further. After we have fixed this MLP model, we will use it as a close comparison model against our ARNN.
Plan: Are you on track with your project?
I would say we are on track: we have collected and preprocessed data, have shared the Devpost link containing a Github repo link with your mentor TA, and have almost finished implementing our model, so we are where the general expectations are. We feel good about finishing by the deadline.
We will need to dedicate more time to finishing our keras/tensorflow model, then performing ablation and testing. This shouldn't require much more time, but will be a complex undertaking. We also hope to generate good visualizations of our outputs, which will also take some time.
What are you thinking of changing, if anything?
It might make sense to implement an "unordered" version that predicts next month's GDP or unemployment rate given all input variables, as well as an "ordered" version that predicts any given month's GDP or unemployment rate given all input variables and the prior value of unemployment and GDP. This will illustrate differences between autoregressive and general prediction models, and allow us to get closer comparison groups between our simple and complex models. So far, we have focused on the unordered version, but we will implement both. In order to do this, we will probably need to build different starting datasets, so this will require some modifications to preprocessing. However, this is more of a "bonus" feature related to quality of life and incremental design, than anything related to core functionality.
-- FINAL REFLECTION: --
Title: Nowcasting and Forecasting Unemployment Rates with Publicly Available Data: Comparing Regression, Perceptron, and Autoregressive Neural Network Models
Who: Shivani Mendiratta and Jay Philbrick
Introduction: We choose to re-implement and extend two existing papers. One paper’s objectives are to enable more real-time determination of Gross Domestic Product, since these results are often released and revised several months after their period of study has ended, using distinct machine learning methods, with linear regression as a baseline. The other paper's objectives are to use an ensemble of machine learning and time series methods (such as ARIMA) to forecast unemployment rates. We use linear regression and another simple method as a baseline, then implement a machine learning time series method (an autoregressive recurrent neural network), and compare the three models.
Methodology:
We use a database of variables from the Federal Reserve Economic Data program at the Federal Reserve Bank of St. Louis, as well as public economic and demographic data from the U.S. Census Bureau's Current Population Survey. This dataset provides variables related to the National Income and Products Account (GDP, consumption, exports, imports, etc), industrial production, employment and unemployment, housing, inventories, orders, and sales, prices, earnings and productivity, interest rates, money and credit, household balance sheets, exchange rates, stock markets, non-household balance sheets, and more. We remove all variables related to employment and unemployment, and just make predictions for these values based on variables outside of this category to avoid endogenous predictions.
We use data from January 1959 to December 2009 as our training set, and data from January 2010 to February 2022, since this represents an 80:20 test-train split, while also allowing us to model the "future" based on the "past". As part of pre-processing, we use min-max scaling to normalize our features, and convert timestamps to ordinals.
We implement two simple models to determine a baseline level of prediction accuracy. In particular, we use a multivariate linear regression and a multilayer perceptron to predict unemployment levels from the set of predictors. Afterwards, we use a multi-feature autoregressive recurrent neural network (ARNN), which consists of windowing and rolling our datasets, then running data through a long short-term memory cell and a dense layer.
We calculate the mean squared error as our principal error metric for all three models, and use mean absolute error as our loss function for the ARNN. We train for 15 epochs with a batch size of 50 units, based on experimentation with various batch sizes and epoch numbers, seeking to minimize squared errors and match the shape of the unemployment curve.
Results: The ARNN results in the lowest mean squared error compared to both the multilayer perceptron and the linear regression prediction models across the full testing period from January 2010 to February 2022, as well as in each of the sub-periods before and after March 2020. For the pre-COVID period, the MSEs of ARNN, MLP, and regression were 4.425, 39.019, and 2.623 respectively. For the post-COVID period, the MSEs of ARNN, MLP, and regression were 238.179, 73.017, and 14.654 respectively.
The ARNN predicts pre-COVID unemployment rates well, whereas the linear regression underestimates it slightly, and the multilayer perceptron severely underestimates it. After COVID-19, the linear regression severely overestimates unemployment, while the ARNN underestimates and then overestimates it, and the multilayer perceptron severely underestimates it, even predicting negative unemployment for some months.
However, the ARNN seems to capture the overall shape of the unemployment, with its spike in March of 2020, worse than both the linear regression and the multilayer perceptron. Overall, the ARNN outputs remain relatively flat, only increasing significantly in the post-COVID period.
Challenges: Our most significant challenge was determining the level of complexity with which to implement our models. Although we ended up implementing two simple models in scikit-learn and one complex model in tensorflow and keras, more time would have afforded the opportunities to make our simpler models more interactive through a lower-level package. Additionally, time proved to be quite constraining, although we did accomplish our planned goals.
Reflection: Ultimately, we were satisfied with how our project turned out. We met our target goals of implementing two baseline models and one complex model, and comparing them, giving us insight into their strengths, weaknesses, and use cases. I was surprised that our ARNN model did not better model the shape of the unemployment graph, and essentially did not predict the spike in unemployment that occurred during the COVID-19 pandemic.
We did not have any major pivots, but we believe our original ideas were a bit ambitious in terms of forecasting both unemployment and gross domestic product and using additional models, but these were pared back relatively early in our project. If we were to start over, we think spending more time trying to investigate ARNN architectures could have been interesting, and would have allowed us to add additional stages of our model, but we believe ours was quite sufficient!
With more time, we could have changed many aspects of the model. For example, features such as a convolution layer either in the model or preprocessing stages could help assist with feature extraction from the set of inputs, potentially improving the shape of the ARNN predictions and allowing it to better forecast the unemployment rate in the wake of the COVID-19 pandemic. We could also have experimented with adding more layers and tweaking hyperparameters. Additionally, more time dedicated to feature selection and in determining which variables most contribute to accurate could inform future predictions. Finally, the fact that different models have different strengths in this task suggests that implementing an ensemble method could lead to better predictions -- for example, a scaling and combining of the regression and MLP approaches could potentially have led to somewhat accurate predictions.
The biggest takeaways from this project were that it is quite important to get preprocessing out of the way as soon as possible, given how time-consuming it often is, and how everything else depends on it. Additionally, it is quite important to be able to systematically investigate different architectures and iterated changes across models. We ended up doing much of this by hand, but I suspect with more time in the future, it would be great to automate.
OTHER IMPLEMENTATIONS: https://www.tensorflow.org/tutorials/structured_data/time_series#advanced_autoregressive_model https://towardsdatascience.com/deep-autoregressive-models-41b21c8a140c
Built With
- keras
- python
- sklearn
- tf

Log in or sign up for Devpost to join the conversation.