-
-
Settings
-
Analysis 1
-
Cached Words
-
Analysis 2
-
Home


Inspiration
When learning a language, language learners often spend countless hours reading content that is either immensely above their level or extremely below it. This phenomenon can lead to both frustration and stagnation in the language acquisition process.
The sweetspot is what linguist Stephen Krashen introduces as Comprehensible Input: Language that is understandable to a learner, even if they don't know every word or grammatical structure.
As a language learner myself (mainly Japanese), I had trouble finding content that would fit my level. Tools like JPDB work as reference metrics; however, they lack personalization. You might know where you roughly stand in the JLPT scale through targeted reading, but the knowledge gaps will remain hidden until you read it yourself.
What it does
NoveLV solves three problems at once:
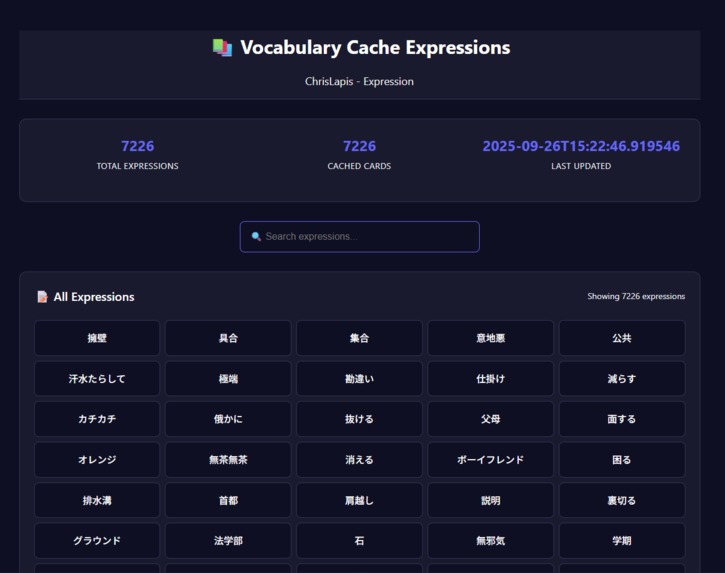
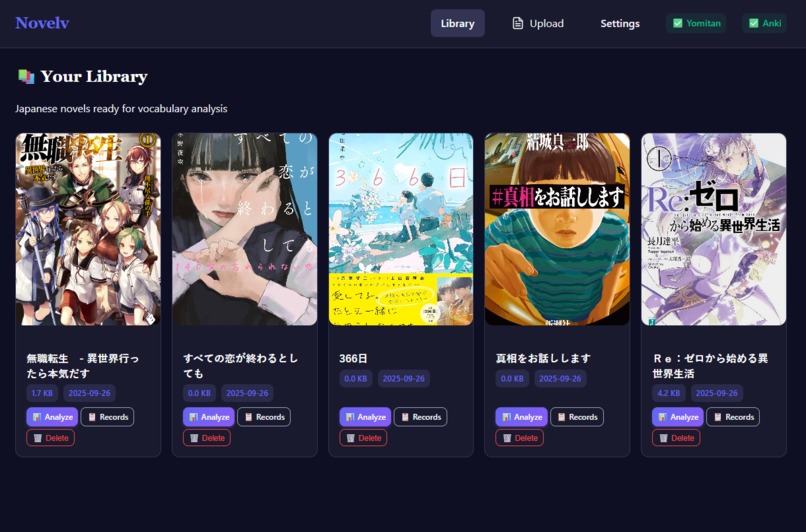
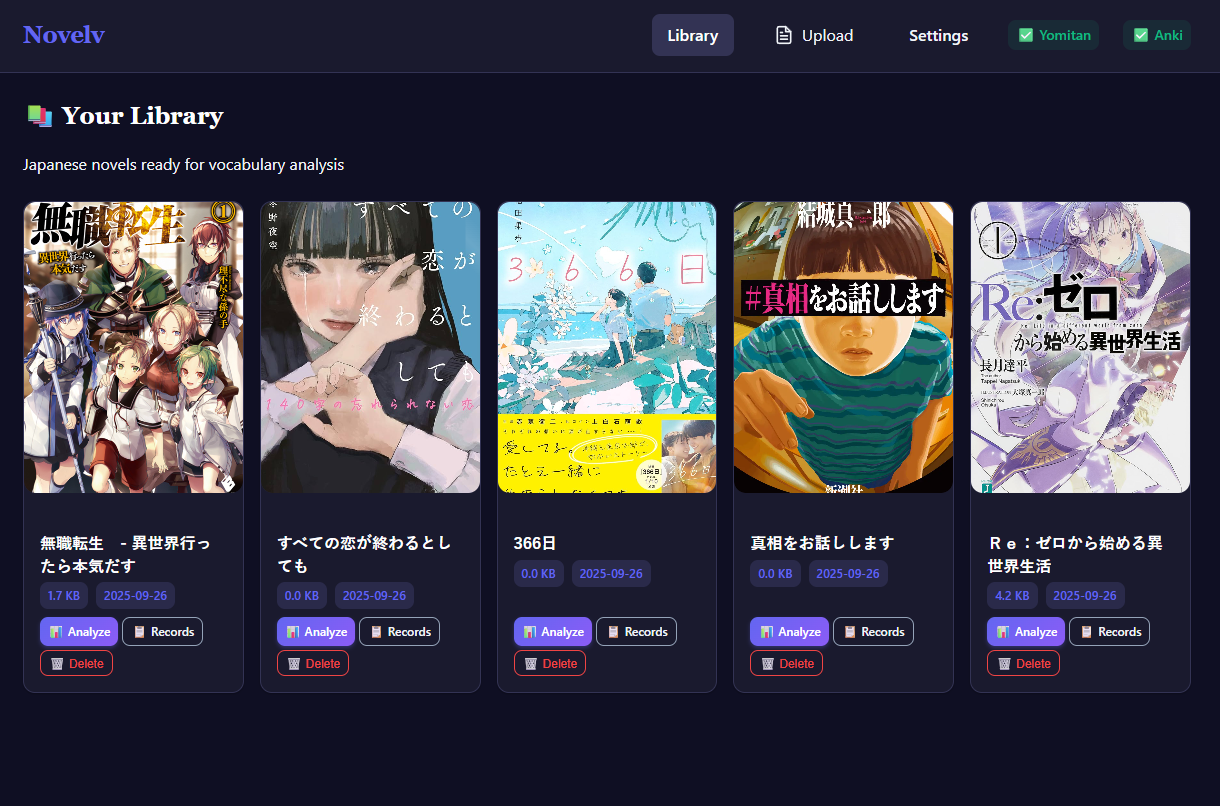
- You get a personalized experience by easily importing the words you know from Anki and parsing them using your own dictionaries and frequency lists from Yomitan.
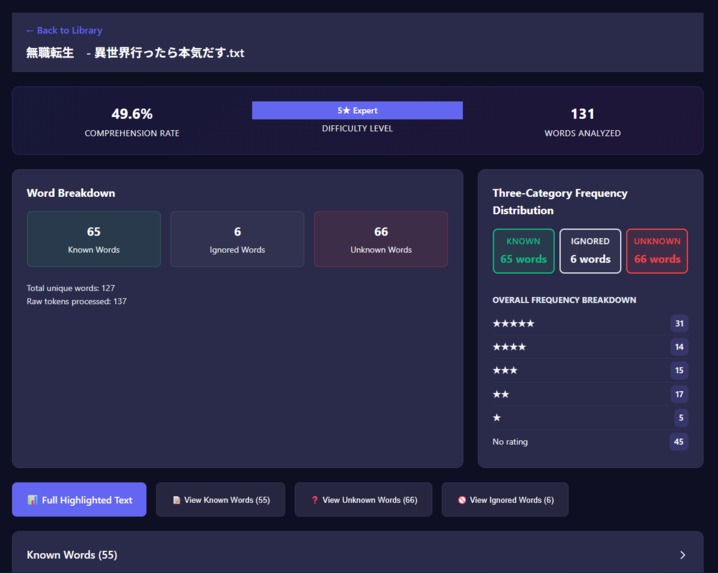
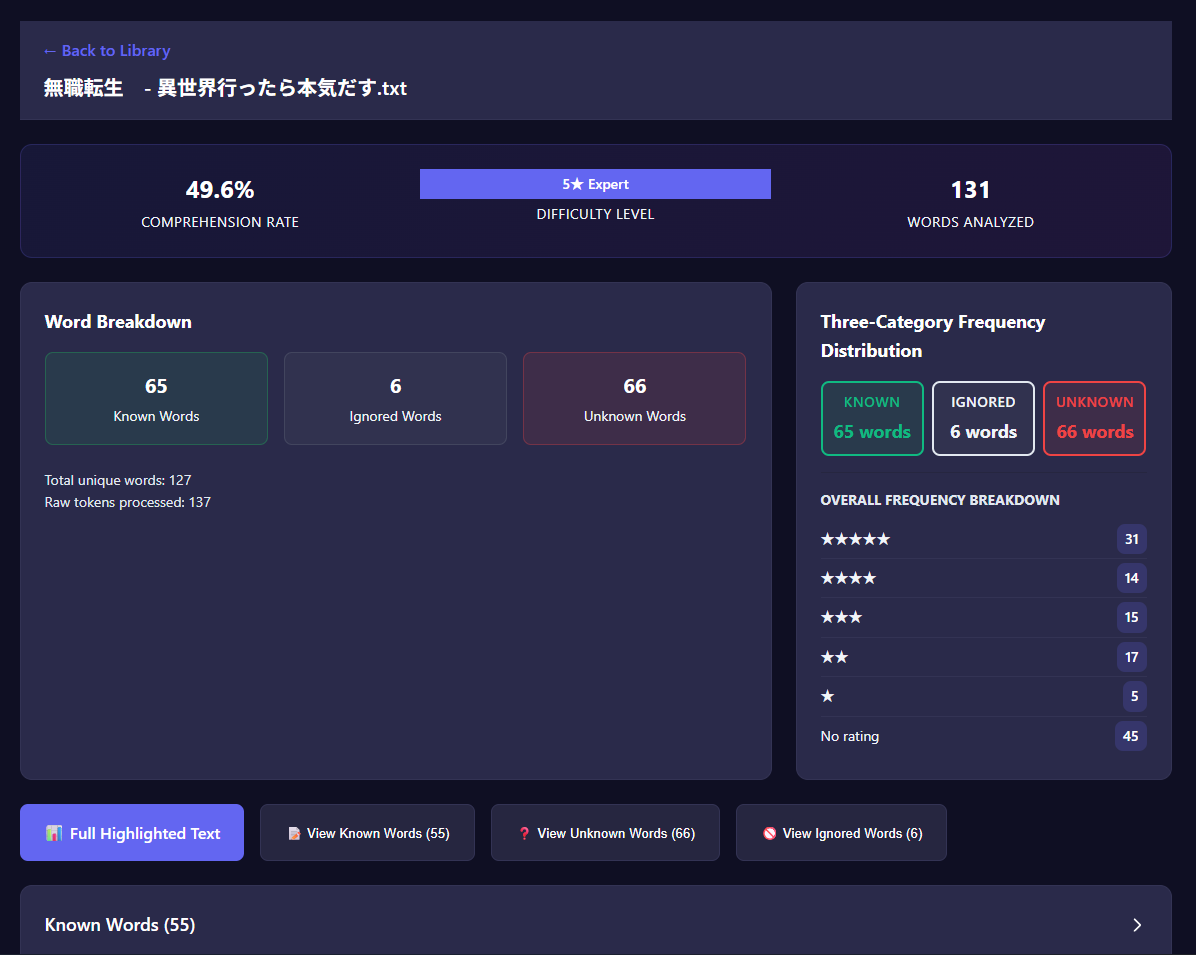
- You can easily find content in the sweetspot of learning where you gain the most out of reading by checking your comprehension score.
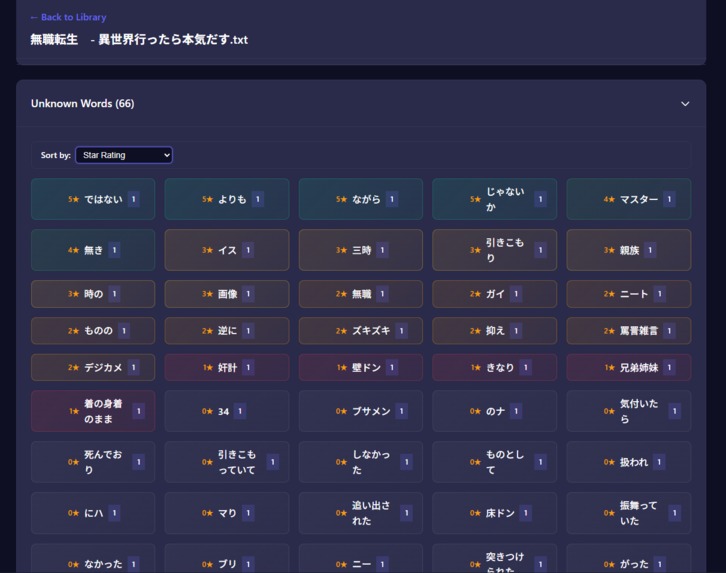
- You can find unknown words (knowledge gaps) in any text in a matter of seconds.
How we built it
The system is a Monolithic web application with external server dependencies. It has a frontend and backend layer (Flask), a Data Processing Pipeline (Python), a Data Storage Layer (JSON, SQLite & Local File System), and external integrations (Yomitan & Anki).
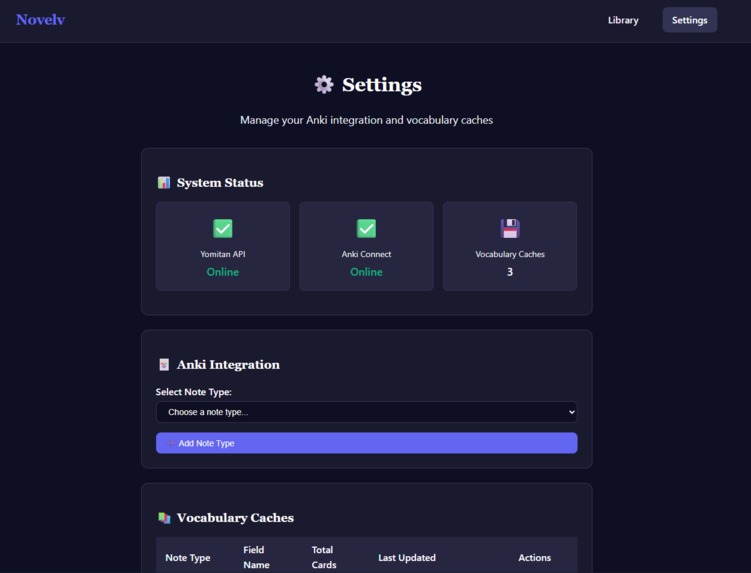
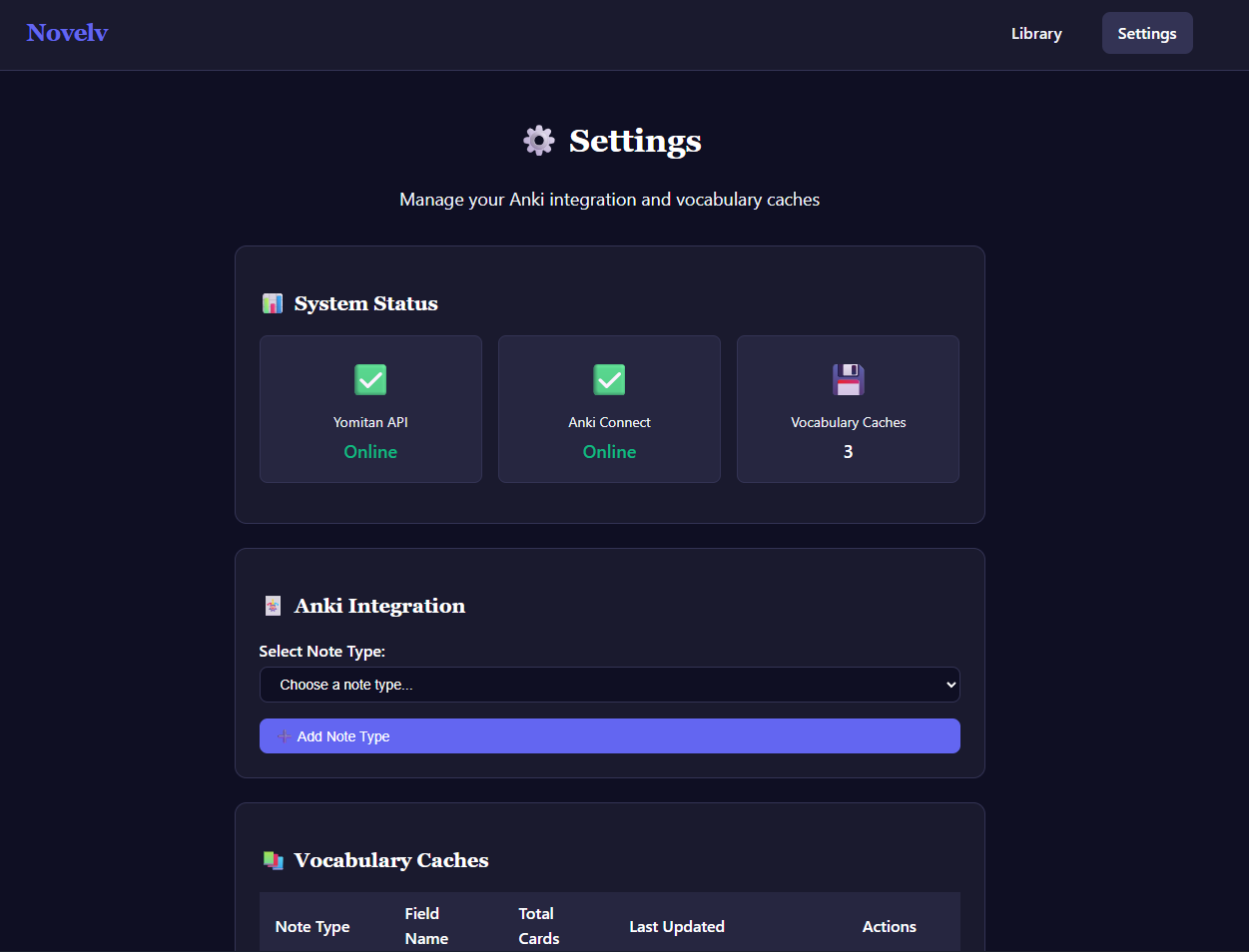
The Flask implementation consists of several layers, ranging from routing to logic handling and templates. Templates for the home, analysis, cache status, settings, and Anki setup pages were built using CSS and HTML.
Determining how to obtain the User's card information from Anki was accomplished by using the Anki Connect addon, which opened a port for HTTP requests locally. This data was then stored in a pickle file for fast access times.
The Yomitan API enabled text parsing, allowing for customized parsing while maintaining consistency. It utilizes prefix trees, specifically lattices, to build a graph of all possible morpheme combinations.
With both external sources, the comparison algorithm compares them one by one, utilizing numerous regular expression rules to account for irregular character placements and special characters.
For every comparison, the analysis is stored in a SQLite database that contains the file name, its contents, the comprehension rate, and other relevant information.
Challenges we ran into
Initially, the parser was intended to be built locally using a program called MeCab; however, this proved to be quite a challenge, as the incomplete database was either too granular or too coarse-grained, making it difficult to obtain an accurate value. Switching to the Yomitan API not only provides the end-user with the customizability they need but also yields a more accurate output.
Accomplishments that we're proud of
NoveLV is the first program to utilize both the Anki API and Yomitan API together to create a customized, user-dependent workflow for language learners. The Architecture successfully builds off the most common applications for language learning, which means there is no need to change ecosystems. (cough cough Migaku).
What we learned
We learned a great deal about HTTP requests, databases, and parsing algorithms. This project would not be possible without the implementation of accurate scanning provided by prefix trees, which this project heavily relies on.
What's next for NoveLV
For now, only the Japanese language is supported; however, the foundations are already in place for any language as long as it has an index dictionary and a frequency list. Furthermore, the media should not be limited to only text. Audio/video files should also be granted support through advanced AI transcription algorithms.
Built With
- anki
- flask
- javascript
- json
- python
- sqlite
- yomitan


Log in or sign up for Devpost to join the conversation.