-
-
Nova
NovaOrator — Project Story
Inspiration
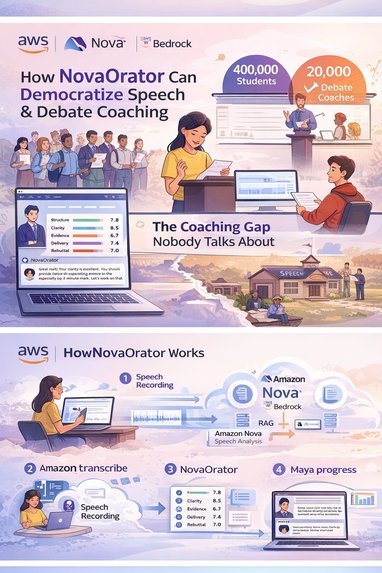
Over 150,000 students compete in NSDA (National Speech & Debate Association) events each year in the United States alone. They practice Original Oratory in front of mirrors, time Extemporaneous Speaking with phone stopwatches, and get feedback maybe once a week from an overworked volunteer coach juggling dozens of students.
The gap between students with access to dedicated coaching and those without is enormous. A student at a well-funded school might get hours of one-on-one feedback per week. A student at a rural school might get none.
We asked ourselves: what if every student had an AI coach available 24/7? One that could listen to their speech, score it against the same rubrics real judges use, point out the exact moment where they lost clarity, and then have a conversation about how to get better?
When Amazon Nova launched on Bedrock with strong reasoning capabilities and structured JSON output, we realized we could build exactly that. Amazon Transcribe could handle the speech-to-text pipeline (both real-time and batch), and Nova Pro could handle everything that requires understanding — scoring, feedback, and coaching conversations.
The inspiration was simple: make expert-level speech coaching accessible to every student, regardless of their school's budget or geography.
What it does
NovaOrator is a full-stack web application that guides a student through a complete coaching session:
Format Selection — The student picks their NSDA event format (Original Oratory, Extemporaneous Speaking, etc.). Each format has official time limits and custom rubric weights.
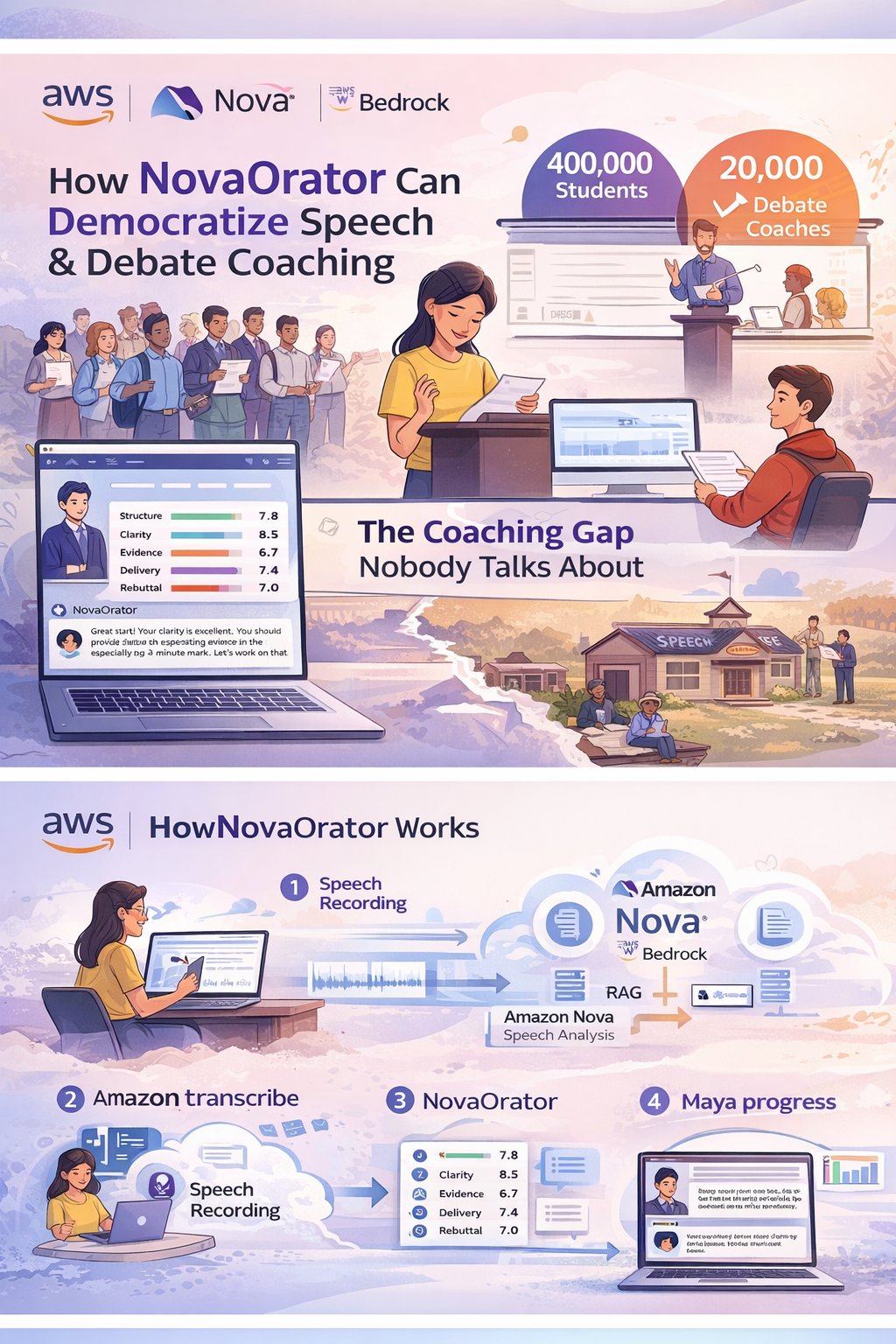
Speech Recording with Live Transcription — The student records their speech directly in the browser. As they speak, a live transcript appears in real-time via Amazon Transcribe Streaming, giving immediate visual feedback.
Batch Transcription — After recording stops, the audio is sent through Amazon Transcribe's batch pipeline for a high-accuracy transcript with word-level timestamps and confidence scores.
Rubric-Based Scoring — Amazon Nova Pro evaluates the transcript against five rubric dimensions — Structure, Clarity, Evidence, Delivery, and Rebuttal Readiness — producing a score from 1–10 for each, along with a justification and an actionable improvement tip.
Timestamped Feedback — Nova Pro generates feedback items tied to specific moments in the speech. Each item includes the timestamp, an excerpt of what was said, a concrete suggestion, and the rubric dimension it relates to.
Dual-Agent Chat — The student can chat with two AI personas:
- A Judge — strict, formal, references rubric dimensions and specific transcript moments
- A Coach — warm, supportive, provides practice drills and encouragement
The scoring model uses format-specific rubric weights. For example, Original Oratory weights Delivery at 30% because performance is paramount, while Extemporaneous Speaking weights Evidence at 25% because citing sources is critical. The weighted score for a session can be expressed as:
$$S_{\text{weighted}} = \sum_{i=1}^{5} w_i \cdot s_i$$
where $w_i$ is the rubric weight for dimension $i$ and $s_i \in [1, 10]$ is the score. This ensures the AI judge evaluates each format the way a real NSDA judge would.
How we built it
Backend — FastAPI + Python 3.13
The backend is a FastAPI server with five service modules:
transcription.py— Uploads audio to S3, starts an Amazon Transcribe batch job, polls for completion, parses word-level results with confidence scoresstreaming_transcription.py— Uses the Amazon Transcribe Streaming SDK to pipe real-time PCM audio from a WebSocket into Transcribe and return partial/final resultsscoring.py— Builds a rubric-aware prompt with format-specific weights, calls Nova Pro via Bedrockinvoke_model(temperature $= 0.1$), and parses the structured JSON response into validated Score objectsfeedback.py— Formats the transcript with timestamps ([1.5s] Hello [2.0s] world), combines it with scores, calls Nova Pro (temperature $= 0.3$), and parses timestamped feedback itemsagents.py— Implements the Judge and Coach agents using distinct system prompts but the same Nova Pro model (temperature $= 0.4$), with full session context (format, transcript, scores) injected into each conversation
All data models use Pydantic v2 for strict validation. Sessions are stored in-memory (no database dependency for the MVP).
Frontend — Next.js 14 + React + TypeScript
The frontend is a single-page wizard built with six components:
FormatSelector— Dropdown grouped by NSDA category with custom time overrideSpeechRecorder— MediaRecorder for audio capture + AudioContext for PCM streaming + WebSocket for live transcriptionTranscriptView— Full text display with collapsible word-level timestampsScoreCard— Color-coded score cards with progress bars and improvement tipsFeedbackPanel— Timestamped feedback cards with rubric dimension badgesAgentChat— Tabbed chat interface for Judge and Coach agents
The main page.tsx orchestrates a state machine: select-format → record → transcribing → transcript-ready → scoring → scored → generating-feedback → complete.
AWS Services
| Service | Role |
|---|---|
| Amazon Bedrock (Nova 2 Lite) | Scoring, feedback generation, agent chat |
| Amazon Transcribe | Batch speech-to-text with word timestamps |
| Amazon Transcribe Streaming | Real-time live transcription |
| Amazon S3 | Temporary audio storage for batch transcription |
Testing
We used pytest with Hypothesis for property-based testing on the backend (136+ tests) and Vitest for the frontend (56+ tests). Property-based tests validate invariants like "scores are always between 1 and 10" and "transcript serialization round-trips perfectly."
Challenges we ran into
1. The Transcription API Mismatch
Our initial design assumed Amazon Nova could handle speech-to-text directly via invoke_model. It can't — Nova is a text reasoning model, not an audio model. We hit a ValidationException on the first real test. The fix was rearchitecting the transcription pipeline to use Amazon Transcribe (S3 upload → batch job → poll → parse), which actually gave us better results: word-level timestamps and per-word confidence scores that Nova alone couldn't provide.
2. Audio Quality and Short Recordings
Amazon Transcribe requires a minimum audio duration of 0.5 seconds. Students clicking "Record" and immediately "Stop" would trigger failures. We added a minimum 1-second duration check in the frontend and changed the backend to return transcripts with quality warnings (instead of hard failures) when confidence was low:
$$\text{avg_confidence} = \frac{1}{n} \sum_{j=1}^{n} c_j$$
If $\text{avg_confidence} < 0.3$, the transcript is returned with a warning rather than rejected. This respects the student's effort while being transparent about quality.
3. Live Transcription PCM Encoding
The browser's MediaRecorder outputs compressed audio (WebM/Opus), but Amazon Transcribe Streaming expects raw PCM (16-bit, 16kHz, mono). We had to set up a parallel audio pipeline: AudioContext at 16kHz sample rate, ScriptProcessorNode to capture raw float32 samples, manual conversion to Int16 PCM, and streaming over WebSocket. Getting the sample rate, bit depth, and endianness right took several iterations.
4. Prompt Engineering for Consistent Scoring
Early scoring prompts produced wildly inconsistent results. The same transcript might score 4/10 on Structure one time and 8/10 the next. The fix was a combination of:
- Very low temperature ($T = 0.1$) for scoring
- Explicit JSON schema in the prompt with exact field names
- Including rubric weights so the model understood relative importance
- Requesting both justification and improvement tips to force deeper reasoning
5. CORS and Frontend-Backend Communication
The Next.js dev server runs on port 3000, FastAPI on port 8000. Without CORS middleware, every API call from the frontend was blocked. A simple CORSMiddleware addition to FastAPI resolved it, but it was a classic "why isn't this working" moment during initial integration.
Accomplishments that we're proud of
The full pipeline works end-to-end in under 60 seconds. A student can pick a format, record a speech, see live transcription, get scored across 5 dimensions with improvement tips, receive timestamped feedback tied to specific moments, and chat with an AI judge or coach — all in a single session without leaving the page.
Format-aware scoring is genuinely useful. Because each NSDA format has custom rubric weights, the scoring feels appropriate. An Original Oratory gets judged heavily on Delivery. An Extemporaneous speech gets judged heavily on Evidence. This isn't generic "your speech was good" feedback — it's format-specific evaluation.
The dual-agent system creates a real coaching dynamic. Students can get the harsh truth from the Judge and then switch to the Coach for encouragement and practice tips. Both agents see the full session context, so the conversation is grounded in the actual speech, not generic advice.
Privacy by default. Audio is deleted immediately after transcription unless the student explicitly opts in to storage. Consent is recorded with a timestamp. No dark patterns, no pre-checked boxes.
Comprehensive test coverage. 136+ backend tests (including property-based tests with Hypothesis) and 56+ frontend tests with Vitest. The property-based tests validate invariants like score ranges, transcript round-trip serialization, and rubric weight normalization.
What we learned
Amazon Nova Pro is remarkably good at structured output. With the right prompt, it consistently returns valid JSON matching our exact schema. The key was being extremely explicit about the expected format — including example JSON in the prompt — and using low temperature for deterministic tasks.
Temperature is a product decision, not just a technical parameter. We use three different temperatures across the app:
- $T = 0.1$ for scoring (consistency matters)
- $T = 0.3$ for feedback (slightly creative suggestions)
- $T = 0.4$ for agent chat (natural conversation)
Each value was tuned to match the expected behavior of that feature. Temperature directly affects user experience.
Real-time features transform the UX. Before live transcription, recording felt like shouting into a void. After adding the WebSocket streaming pipeline, students could see their words appear as they spoke. It made the app feel alive and responsive, even though the "real" transcription happens after recording stops.
Consent should be a first-class feature. Building audio deletion as the default from day one was easier than retrofitting it later. The consent checkbox, timestamp recording, and conditional storage logic added about 20 lines of code but fundamentally changed the trust equation with users.
Property-based testing catches edge cases humans miss. Hypothesis found edge cases in our transcript serialization that unit tests never would have — empty word lists, zero-length timestamps, Unicode characters in transcripts. Writing properties like "serialize then parse always returns the original" is more powerful than writing individual test cases.
What's next for NovaOrator
More formats. The format registry already contains all 24 NSDA events with rubric weights and time limits configured. Enabling a new format is a single enabled=True flag change. We plan to enable Debate formats (Public Forum, Lincoln-Douglas) next, which will require tuning the Rebuttal Readiness dimension more heavily.
Session history and progress tracking. Currently sessions are in-memory and lost on restart. Adding persistent storage (DynamoDB) would let students track their scores over time and see improvement trends:
$$\Delta S_i = S_i^{(t)} - S_i^{(t-1)}$$
Visualizing $\Delta S_i$ per dimension over multiple sessions would show students exactly where they're improving and where they're plateauing.
Audio playback synced with transcript. Click a word in the transcript, hear that moment. Click a feedback item's timestamp, jump to that point in the audio. This requires storing audio (with consent) and building a synchronized playback UI.
Tournament simulation mode. Randomized topics, strict timing, no do-overs — simulating real tournament conditions so students can practice under pressure.
Peer benchmarking. Anonymous, aggregate score distributions per format so students can see where they stand relative to others practicing the same event. No individual data shared — just percentile ranges.
Multi-language support. Amazon Transcribe supports dozens of languages. Expanding beyond English would open NovaOrator to international debate formats and non-English-speaking students.
NovaOrator is built with Amazon Nova on Bedrock, Amazon Transcribe, Amazon S3, Next.js, and FastAPI. It demonstrates how generative AI can democratize access to expert-level coaching in speech and debate education.
Built With
- amazon-bedrock
- amazon-nova
- amazon-transcribe
- amazon-web-services
- boto3
- fastapi
- hypothesis
- kiro
- next.js
- pydantic
- python
- react
- tailwind-css
- typescript
- vitest

Log in or sign up for Devpost to join the conversation.