-
-
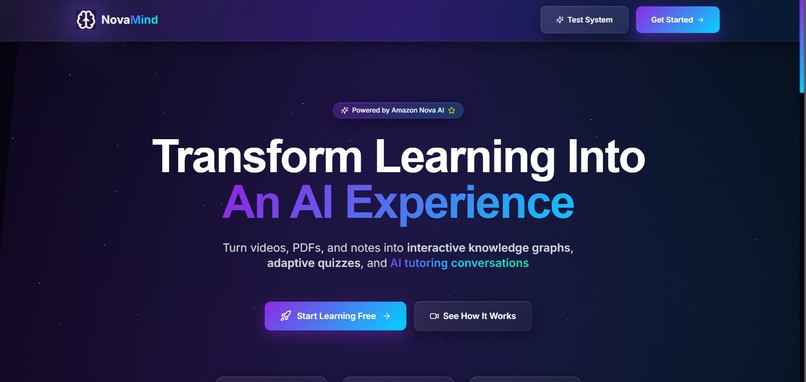
HOMEPAGE
-

-

-
-
-
-


Inspiration
NovaMind started from a simple frustration: students spend hours sitting through lectures, flipping through handwritten notes, and trying to piece together disconnected concepts before an exam. A two-hour lecture might contain only a handful of core ideas, but finding those ideas again across videos, PDFs, screenshots, and notes is slow and mentally exhausting.
I wanted to build something that turns passive studying into active learning. Instead of treating lectures, slides, and notes as separate files, NovaMind treats them as one connected learning system. The idea was to use Amazon Nova's multimodal capabilities to help students upload raw study material and turn it into something searchable, explainable, and quiz-ready.
What it does
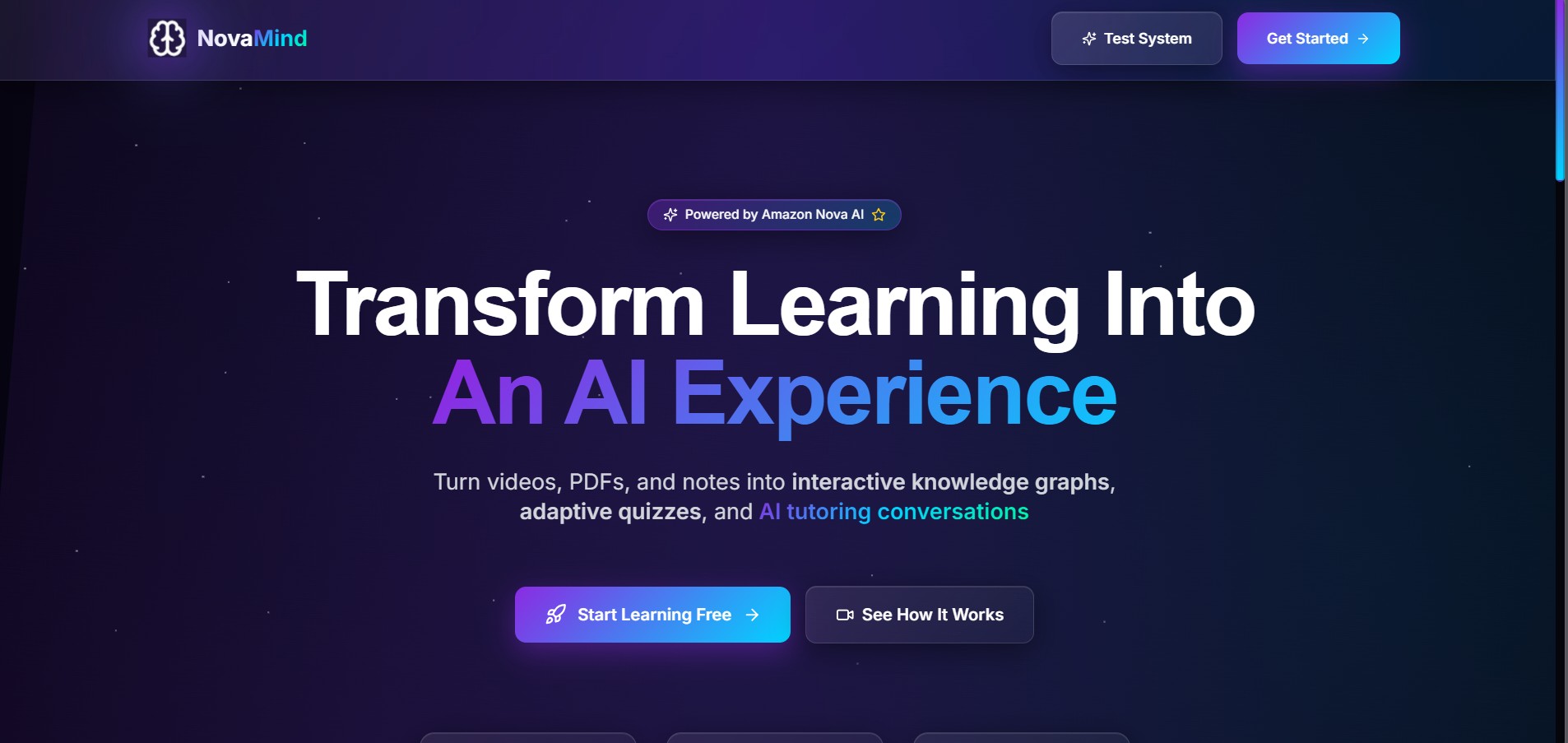
NovaMind is an AI-powered study companion that helps students organize and learn from multimodal educational content.
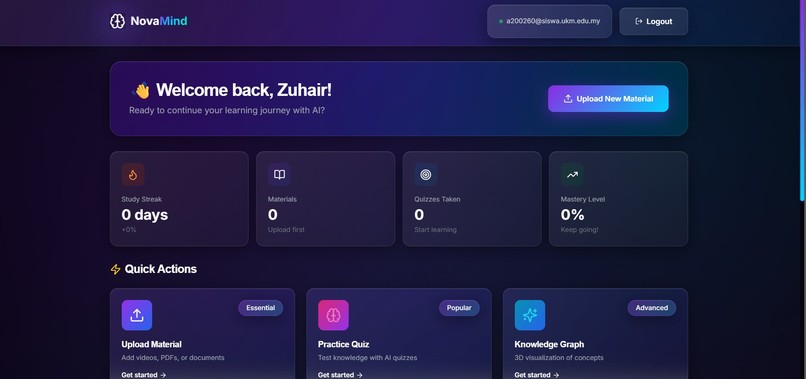
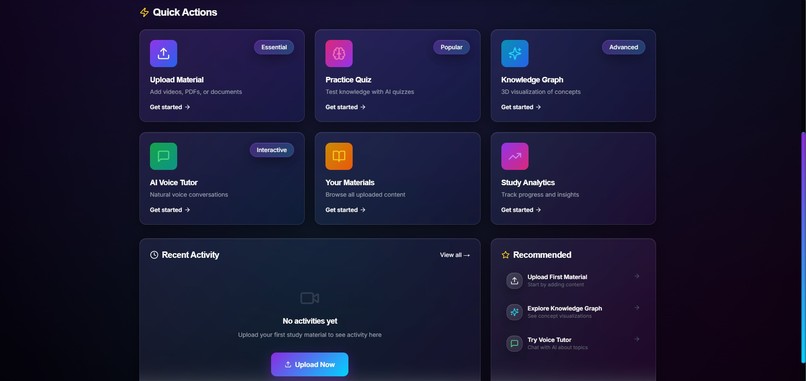
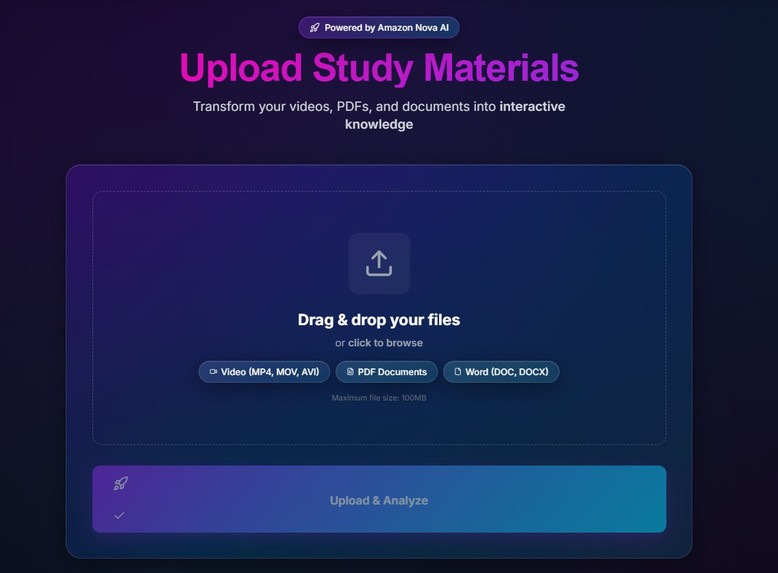
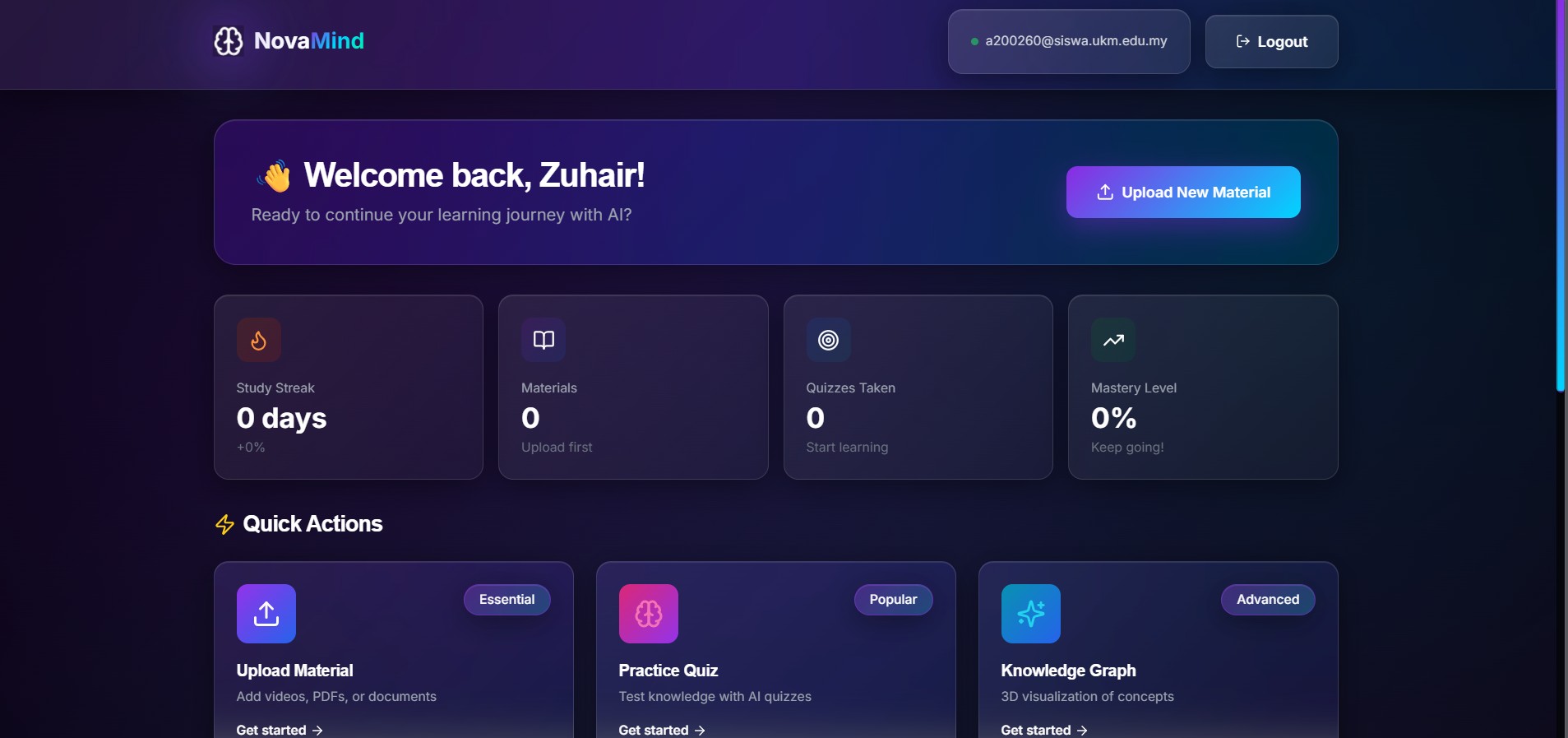
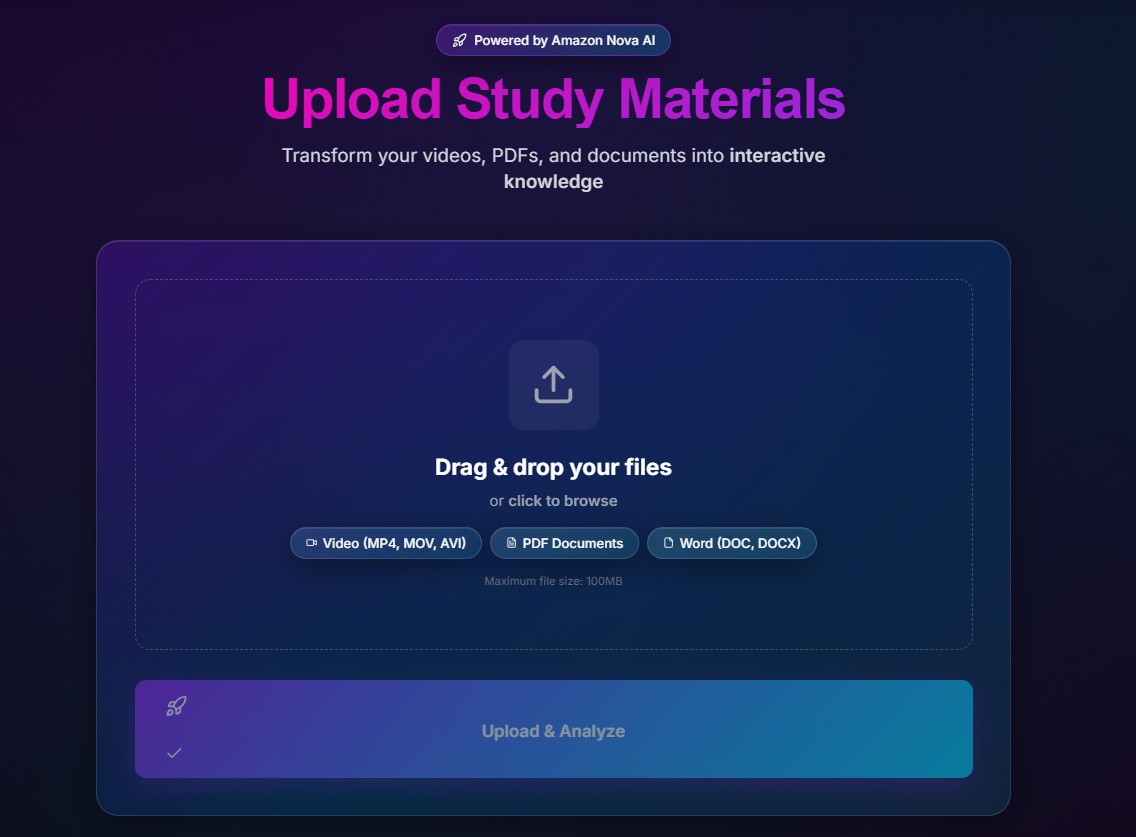
It lets users upload lecture videos, PDFs, and notes, then processes that material into structured study assets such as searchable content, concept relationships, quizzes, and analytics. The platform is designed around a few core workflows:
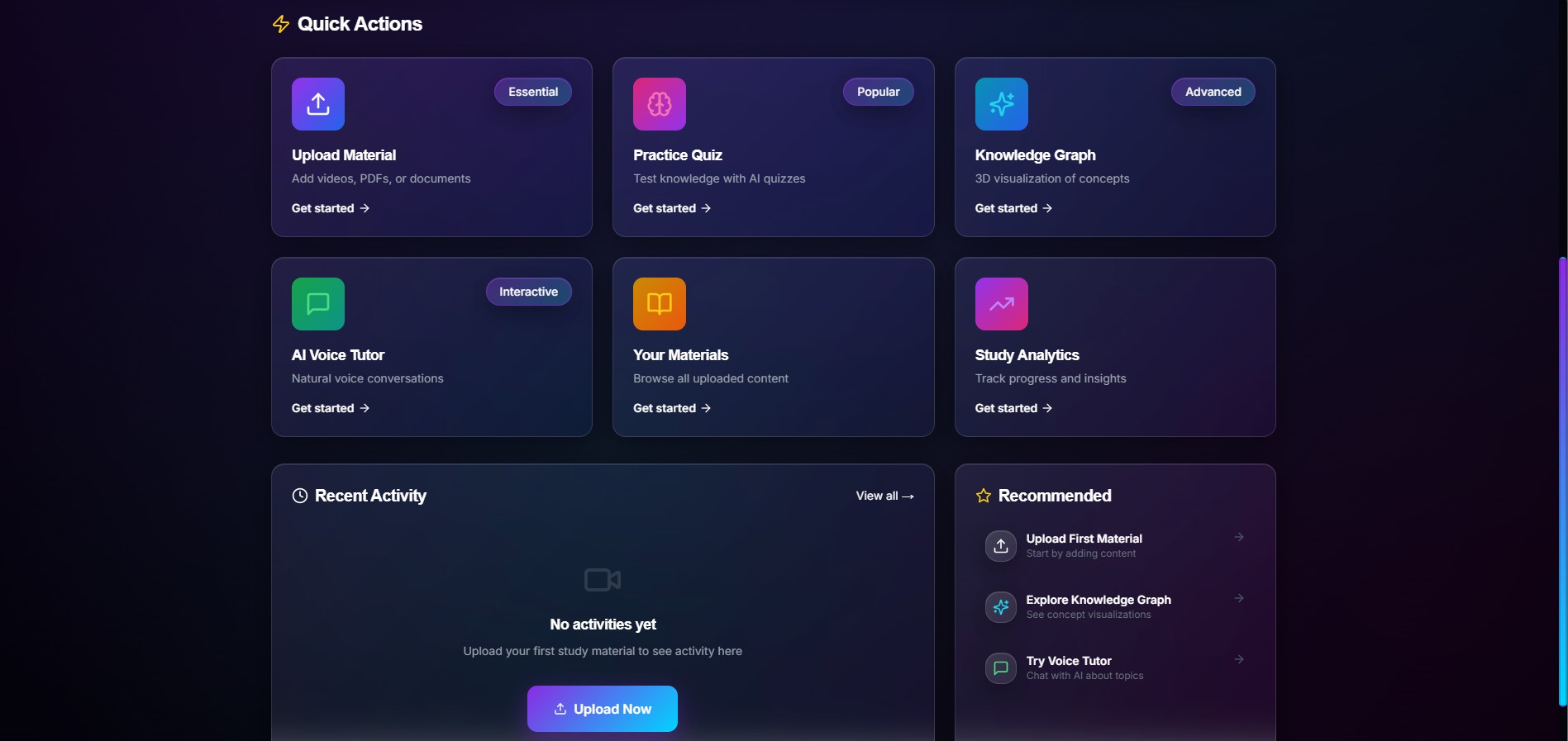
- multimodal ingestion for videos, documents, images, and notes
- semantic search across processed study material
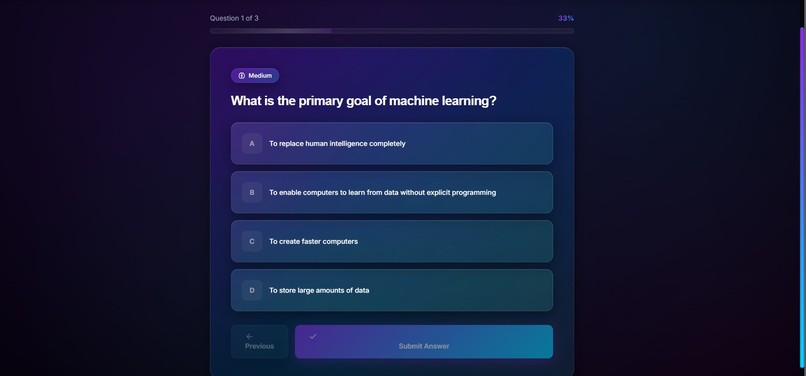
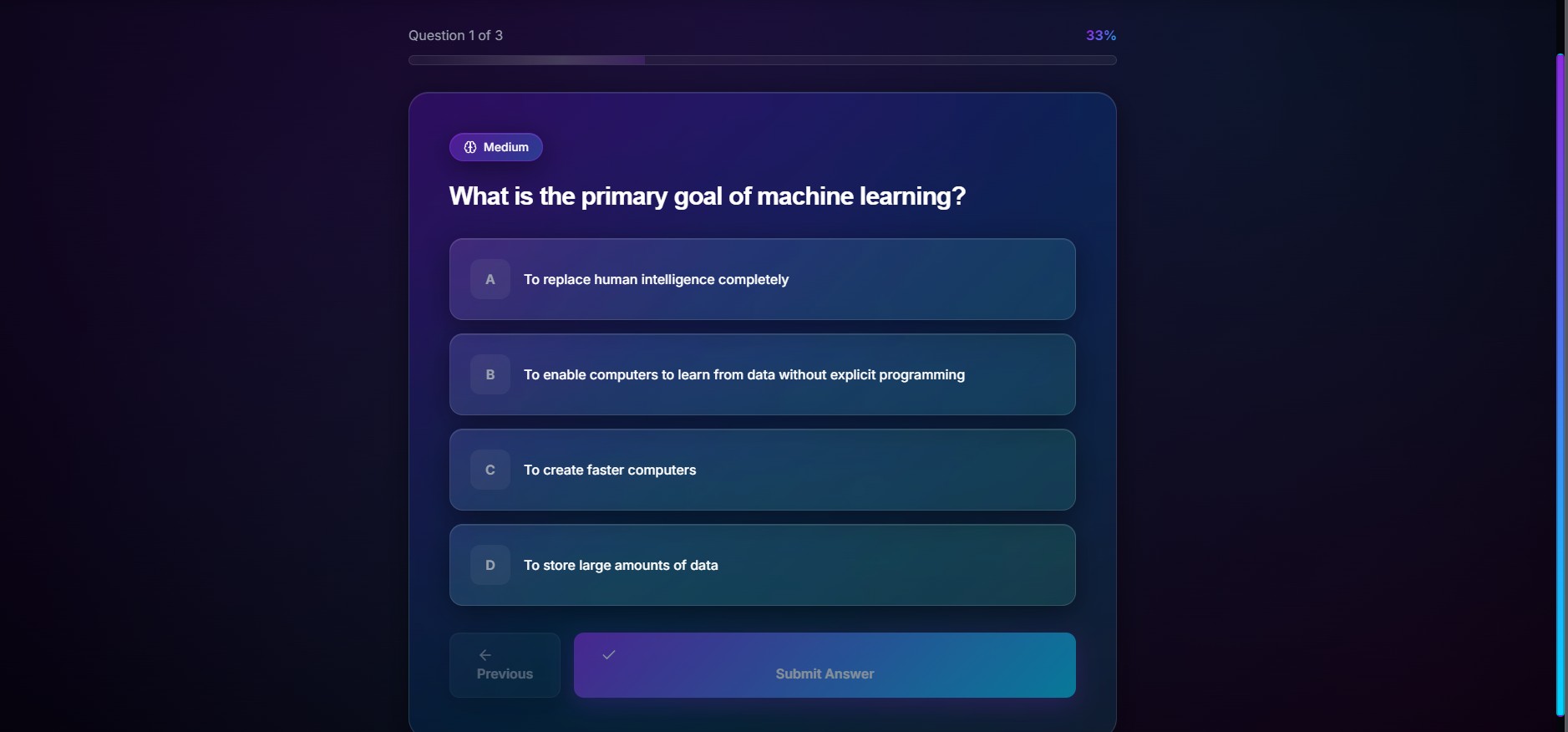
- quiz generation for active recall and reinforcement
- knowledge graph exploration to connect concepts visually
- analytics to track study behavior and progress
- voice-based tutoring experiences powered by Amazon Nova
The larger goal is to reduce time spent re-finding information and increase time spent actually learning. In practice, NovaMind is meant to move students closer to a system where study effectiveness improves as their material grows, instead of becoming more chaotic.
How we built it
We built NovaMind as a full-stack application with a modern web frontend, an async Python backend, cloud AI services, and a database designed for both structured learning data and semantic retrieval.
The frontend uses Next.js 14, React, TypeScript, and Tailwind CSS to power the dashboard, upload flow, analytics views, and knowledge graph experience. We also use libraries like Three.js, D3, Recharts, Framer Motion, and Zustand to support data visualization, motion, and interactive UI patterns.
The backend is built with FastAPI and organizes the system into API routes for upload, materials, quiz, voice, search, analytics, and knowledge-graph features. For AI functionality, we integrated AWS Bedrock through Boto3 and structured the app around multiple Amazon Nova model roles:
- Amazon Nova Premier for multimodal understanding
- Amazon Nova Lite for reasoning and content generation
- Amazon Nova Sonic for conversational voice interactions
- Nova Multimodal Embeddings for semantic search
On the data side, we designed a PostgreSQL schema around materials, transcripts, concepts, concept relationships, quiz attempts, flashcards, study sessions, and embeddings. Supabase provides authentication and database infrastructure, while pgvector enables vector similarity search over embedding data.
For content processing, we combined tools like OpenCV, FFmpeg, Pillow, PyPDF2, and pdfplumber to handle document parsing, image workflows, and media processing. The result is a platform that can move from raw study inputs to structured, AI-usable knowledge.
Challenges we ran into
he biggest challenge was orchestration. Multimodal AI projects are not just about calling one model; they require stitching together different processing stages, data representations, and UX expectations into one coherent experience.
A few specific challenges stood out:
- designing a schema that could connect materials, transcripts, concepts, quizzes, embeddings, and study sessions without becoming brittle
- balancing fast, responsive frontend interactions with heavier backend processing like document parsing and media analysis
- structuring different Amazon Nova model roles so each one has a clear job instead of turning the backend into a single overgrown AI endpoint
- making semantic search meaningful across different content types, not just text blobs
- building around real student workflows, where source traceability matters and answers need to map back to timestamps, pages, and concepts
Another challenge was product scope. Once you can ingest videos, notes, and documents, it becomes tempting to build everything at once. A lot of the work was deciding which experiences should be core to the first version and which ones belong in the roadmap.
Accomplishments that we're proud of
We are proud that NovaMind is not just a single demo prompt wrapped in a UI. It is structured as a real product architecture with a dedicated frontend, backend routes, database design, multimodal processing pipeline, and a learning-focused feature set.
Some highlights we are especially proud of:
- a cohesive product concept that connects ingestion, retrieval, assessment, and analytics in one system
- a clear multimodal AI architecture built around the strengths of different Amazon Nova models
- a knowledge-graph-first approach that helps students see relationships between ideas instead of only consuming summaries
- support for active recall workflows through quiz generation and spaced-repetition-friendly data structures
- a technical foundation that can scale into richer tutoring, collaboration, and study planning experiences
What we learned
We learned that building effective AI products for education is as much about structure as intelligence. Good outputs depend on how well the system organizes context, tracks user progress, and keeps source material grounded.
We also learned that multimodal learning products need to preserve traceability. Students do not just want an answer; they want to know where it came from, whether that is a lecture timestamp, a slide, or a note. That requirement shaped both the database design and the product experience.
On the technical side, we learned how important it is to separate AI responsibilities. Using different Amazon Nova capabilities for understanding, generation, embeddings, and voice creates a more maintainable system than forcing one model path to do everything.
On the learning-science side, we kept coming back to the idea that retention improves when study becomes active. A useful mental model for NovaMind is that learning impact increases when retrieval, feedback, and review are connected:
$$ \text{learning gain} \propto \text{retrieval practice} + \text{feedback quality} + \text{review timing} $$
That principle heavily influenced our design decisions.
What's next for NovaMind
The next step for NovaMind is turning the current foundation into a more adaptive and collaborative study system.
Near-term priorities include:
- deeper end-to-end pipelines for lecture and note processing
- stronger voice tutoring flows with richer conversational context
- more advanced semantic retrieval across text, images, and time-based media
- personalized quiz difficulty and review scheduling based on user performance
- a more immersive knowledge graph with clearer learning recommendations
Beyond that, we see NovaMind evolving into an academic copilot that can generate personalized study plans, support collaborative learning spaces, and help students move from information overload to mastery.
Built With
- amazon-web-services
- bedrock
- boto3
- celery
- fastapi
- framermotion
- next.js
- opencv
- pgvector
- pillow
- postgresql
- pypdf2
- python
- react
- rechart
- redis
- sql
- supabase
- tailwind
- typescript
- zustand


Log in or sign up for Devpost to join the conversation.