-
-
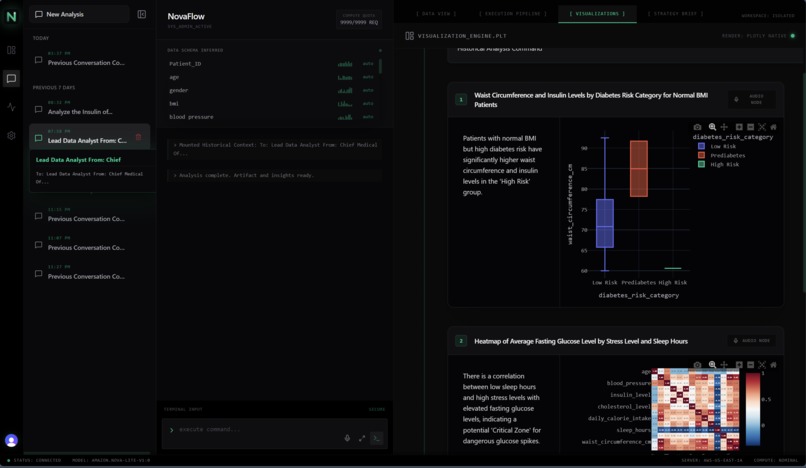
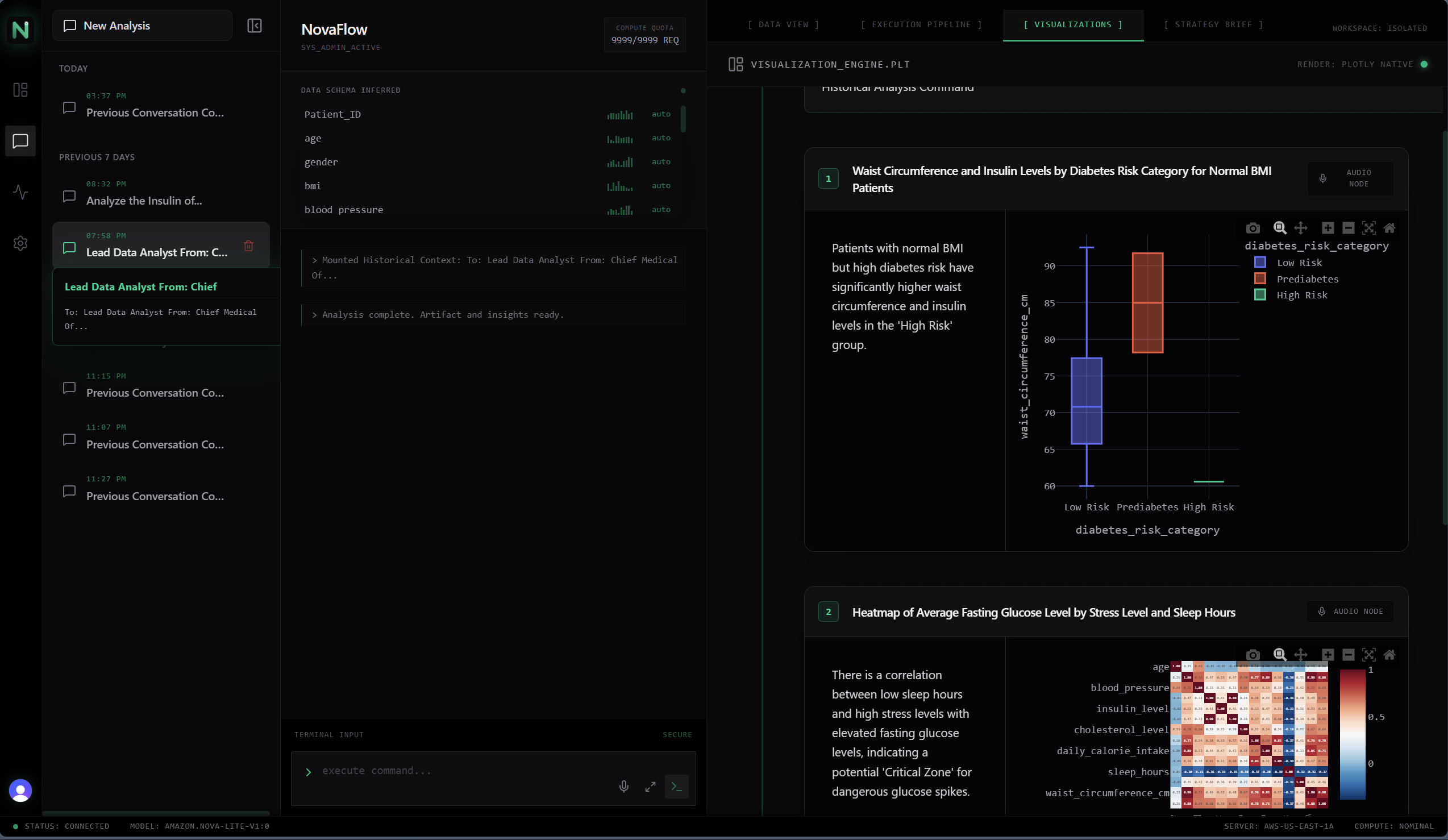
NovaFlow's interactive Plotly graphs
-
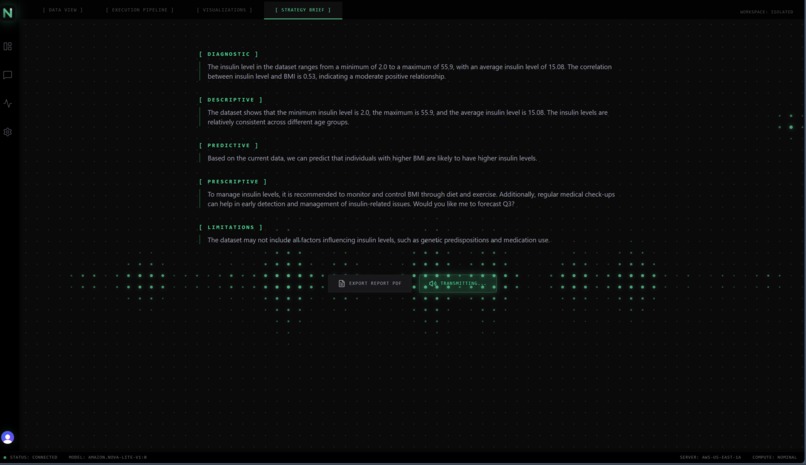
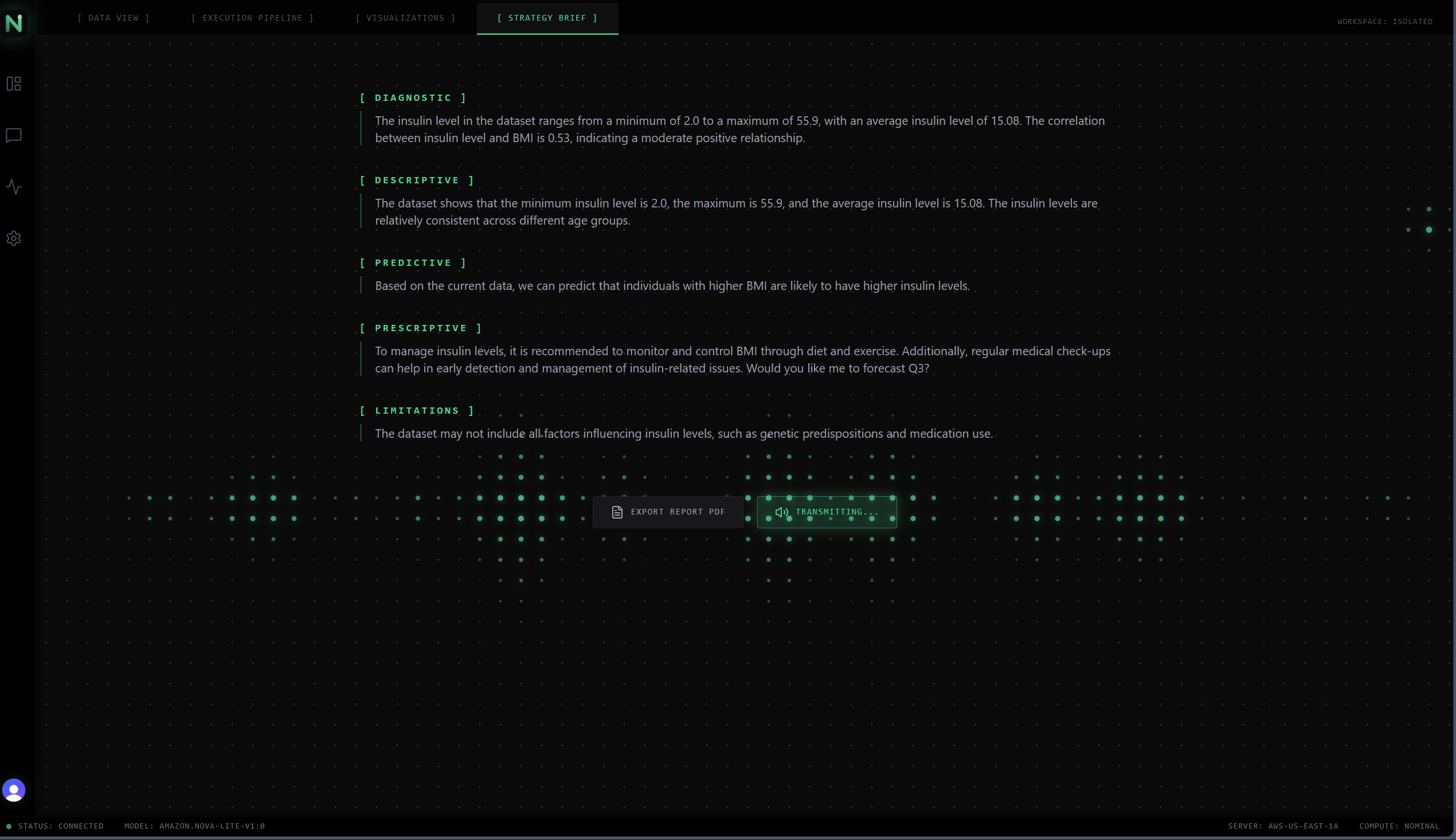
NovaFlow's Audio Brief
Inspiration
Let's be brutally honest about the current state of Business Intelligence: the traditional data pipeline is a bureaucratic nightmare. A business leader asks a question, a Jira ticket is filed, an analyst spends days cleaning a messy CSV, writes the boilerplate SQL, and three weeks later, a static dashboard is delivered. By the time the data is rendered, the business question has already changed.
As a 3rd-year B.Tech Data Science student, I realized a terrifying truth: my future career was going to be spent as a manual data laborer. I was exhausted by endless ETL pipelines, fixing schema mismatches, and debugging Python tracebacks just to generate a simple Plotly chart for someone else.
I realized that data pipelines shouldn't hold business intelligence hostage. I didn't want to build another thin AI wrapper, and I definitely didn't want to build another chatbot. I wanted to build the analyst.
NovaFlow was born purely out of developer fatigue. The mission was to collapse a three-week Jira ticket lifecycle into a 30-second, zero-idle serverless execution loop. I built this so I could stop being the data laborer, and finally become the orchestrator.
What it does
NovaFlow is an autonomous, end-to-end Business Intelligence pipeline that transforms raw tabular data into interactive dashboards and executive-ready audio briefings. It eliminates the 80% of time analysts spend on data cleaning and query debugging by acting as an agentic data engineer.
Here is the exact workflow of the system:
- Frictionless, Heavy-Payload Ingestion: Users upload raw CSVs which securely bypass standard API Gateway payload limits via S3 presigned URLs. An asynchronous interceptor tracks the analysis state without timing out the connection.
- Autonomous Data Profiling: Before the AI even sees a user prompt, NovaFlow scans the entire dataset, drops empty rows, normalizes column names, and builds a strict, mathematical Ontology Map. This forces the foundation model to operate within deterministic boundaries, completely preventing schema hallucinations.
- Self-Healing SQL Execution: Standard LLMs hallucinate syntax and crash databases. NovaFlow utilizes a closed-loop Critic Agent. If the generated SQL fails against the ephemeral database, the agent intercepts the literal Python traceback error, reads it, and autonomously rewrites the code to execute perfectly before the user ever sees a failure.
- "Breathing" Interactive Visualizations: Instead of generating lazy, static PNG images, NovaFlow executes complex extraction logic to mount dynamic, fully interactive Plotly environments natively in the React frontend. Users can zoom, pan, and hover over specific data points.
- The Executive Audio Brief: Executives don't read dashboards; they want to be briefed. NovaFlow takes the isolated target data and synthesizes a broadcast-quality strategy brief using Amazon Nova Sonic. Using a custom hybrid voice-edge integration, the React app bypasses standard downloading to stream the generated audio with virtually zero latency.
How I built it
I engineered NovaFlow from the ground up to be a 100% serverless, event-driven distributed system. The core philosophy was simple: if nobody is querying the pipeline, the AWS compute bill should be exactly $0.00.
The Edge & The Paywall I built the frontend using bleeding-edge React 19 and Vite 6, styled with Tailwind CSS v4, and deployed to the Vercel Edge Network. Because I wanted this to survive in the real world as an enterprise SaaS, I didn't fake the login. I integrated Clerk for authentication and wired it directly to a Product-Led Growth (PLG) quota system in the database.
Decoupling the Pipeline (Beating the Timeout) AWS API Gateway has a hard 29-second timeout. You cannot synchronously profile a 50,000-row CSV, run LLM inference, execute statistical SQL, and synthesize audio in under 29 seconds consistently. So, I completely decoupled the stack. The API Gateway acts purely as a bouncer—it validates the Clerk JWT, issues a pre-signed S3 URL for the client upload, and tosses the job payload into an Amazon SQS queue. It immediately returns a 202 Accepted, and the React UI switches to async polling against DynamoDB.
The Ephemeral Sandbox
When the SQS queue triggers the Python 3.10 Lambda Worker, it pulls the raw data from S3 and mounts it into an ephemeral, in-memory SQLite database (:memory:). I specifically chose not to use a persistent database for the analysis. The data exists only for the lifespan of the Lambda container. This guarantees complete data isolation and zero risk of a prompt-injected DROP TABLE command destroying anything permanently.
The Critic Agent Loop (Amazon Bedrock)
This is the heart of the engine. The Lambda worker prompts Amazon Nova Lite to write dynamic SQL based on the user's plain-English query. But LLMs hallucinate. If Nova Lite invents a column name or writes bad syntax, the Python sqlite3 engine throws a traceback. Instead of failing the pipeline and passing a 500 error to the UI, the Lambda catches the exact traceback, feeds it right back to Nova Lite as a "Critic" prompt, and forces the model to rewrite the broken code. It loops autonomously until the SQL executes perfectly.
Multimodal Synthesis & State Once the data is successfully queried, aggregated, and mapped to Plotly.js JSON structures, the Lambda makes a final pass through Amazon Nova Sonic. Nova Sonic synthesizes the neural audio strategy brief, the audio file is stored, and the final state payload is dumped into DynamoDB. The React frontend detects the state change, kills the loading terminal, and mounts the live dashboard to the DOM.
Challenges I ran into
Building a distributed, autonomous agent in a weekend is a recipe for pain. I didn't just string together some API endpoints; I hit massive architectural walls and lost a lot of sleep over them:
1. The 29-Second Execution Wall I spent hours building a beautiful, synchronous backend pipeline, only to remember that AWS API Gateway murders any request that takes longer than 29 seconds. You cannot ingest a CSV, run a Pandas profile, prompt Nova Lite to write SQL, execute it, and wait for a neural audio TTS generation in that timeframe. Halfway through the hackathon, I had to completely tear down my backend and re-architect it into an asynchronous, event-driven SQS polling pipeline.
2. The Python-to-JavaScript Translation Nightmare Python and JavaScript do not speak the same language. I naively thought I could just pass a Pandas DataFrame to the React frontend and let Plotly.js figure it out. Nope. Plotly expects highly rigid JSON structures (specific arrays for x/y traces, nested layout dictionaries). I had to engineer a dedicated serialization layer inside the Worker Lambda so the AI wouldn't just write SQL, but perfectly formatted Plotly-compliant JSON payloads.
3. The Birth of the Critic Agent (SQL Hallucinations)
Wiring an LLM directly to a database is terrifying. Early on, Nova Lite would occasionally hallucinate a JOIN, invent a column name, or return mangled JSON that completely crashed my React UI. Instead of passing 500 errors to the user, this friction birthed the Critic Agent. I built a deterministic loop where the Lambda runs the code in an isolated memory space. If it throws a Python traceback, the Lambda catches it, feeds it back to Nova Lite as a harsh prompt, and forces the AI to debug its own code until it works.
4. The Serverless Amnesia (Context Management) Because my backend is 100% serverless and decoupled via Amazon SQS, it is inherently stateless. Every time the Lambda spins up, the bot has complete short-term memory loss. Maintaining conversational memory so a user could ask follow-up questions ("Now isolate just the high-risk patients from that last chart") was brutally difficult. I had to build a contextual memory compressor that dynamically pulls the user's prior chat history from DynamoDB and injects it into the Bedrock system prompt on every single loop.
5. Lambda OOM Kills & Dependency Hell
The environment fought me constantly. My Worker Lambda kept silently failing because the default 128MB of RAM is nowhere near enough to load a Pandas DataFrame and an SQLite database simultaneously (instant Out-Of-Memory crashes). Meanwhile, on the frontend, I used bleeding-edge React 19 and Vite 6, which caused a massive upstream peer-dependency conflict with the Clerk Auth SDK. I spent way too much time at 3 AM fighting npm install --legacy-peer-deps just to get the dev server to boot.
6. The "Judge Login" Trap At the 11th hour, I realized my enterprise-grade authentication was actually too secure. I had set up Clerk to use Email OTPs, but the dummy email I provided for the hackathon judges didn't actually have a real inbox to receive the 6-digit code! I had a mild panic attack realizing you guys might be locked out of my app entirely and had to scramble into the Clerk developer settings to hardcode a mock OTP bypass just so you could log in and grade my work.
Accomplishments that I am proud of
- Designing a "Bloomberg Terminal Meets The Matrix" UI: Most hackathon projects look like standard component libraries slapped together at the last minute. I am incredibly proud of hand-crafting a deeply immersive, dark-mode interface using React 19 and Tailwind CSS v4. It doesn't just function well; it feels like a premium, high-stakes enterprise tool that an executive would actually want to log into.
- The Fastest, Cheapest, and Most Logical Execution Pipeline: By combining the sheer inference speed of Amazon Nova Lite with an ephemeral AWS Lambda/SQLite architecture, I built an engine that is brutally efficient. It costs fractions of a cent per execution, runs completely serverless with zero idle overhead, and follows a hyper-logical, decoupled path from raw CSV to SQS queue to self-healing SQL execution. It might be the leanest data pipeline you'll ever see.
- The Self-Healing Critic Agent: I am incredibly proud of getting the AI to seamlessly debug its own Python tracebacks. Watching the AWS CloudWatch logs show a failed SQL query, catch the error, feed it back to Nova Lite, and then output a perfect Plotly JSON on the second try, all while the user's UI just shows a calm "processing" spinner was my biggest "YAY!" moment of the entire weekend.
- A Truly Zero-Idle Architecture: I didn't take the easy way out by spinning up a persistent EC2 instance, an always-on backend server, or a managed database. I successfully engineered a decoupled, event-driven SQS/Lambda pipeline that costs exactly $0.00 when nobody is using it. It is secure, ephemeral, and built for actual enterprise scale.
- Giving Data a Voice (Nova Sonic): Integrating Amazon Nova Sonic wasn't just a cool hackathon gimmick; it fundamentally changes the UX. I am proud that I successfully bypassed the traditional React virtual DOM to stream a natively generated, broadcast-quality executive audio brief directly to the client. You don't have to look at the screen to understand your data anymore.
- Building a Real SaaS, Not Just a Hack: I didn't just wire up a simple text-in, text-out chatbot. I implemented a Clerk authentication wall, a DynamoDB-backed compute quota system (proving real Product-Led Growth viability!), and dynamic 1-click PDF executive report generation. It doesn't feel like a weekend project; it feels like a deployable product.
What I learned
First of all I learnt building a SaaS from scratch is the most biggest hurdle I have ever come across in my life.. that too without a team, being a lonewolf is tough but without a team one can breakdown easily, novaflow taught me that just going on without a team can be very painstalking but it didnt stall me to stop building it. I built what I dreamt of...
I learned that building a resilient AI product is actually less about the LLM prompt and entirely about the infrastructure surrounding it. I had to learn how to properly decouple a system using Amazon SQS, realizing the hard way that synchronous API Gateway endpoints will ruthlessly timeout when doing heavy data lifting. I had to dive deep into AWS Lambda's Linux execution environments, figuring out how to manage ephemeral memory limits so the container wouldn't crash when profiling a heavy CSV.
On the frontend, I learned that utilizing bleeding-edge technology like React 19 and Vite 6 brings bleeding-edge package conflicts. It forced me to actually understand strict peer-dependency trees instead of just blindly running npm install. I also learned a golden rule of solo development: never build authentication from scratch. Integrating Clerk saved my sanity and instantly gave the app a legitimate enterprise feel.
Finally, diving deep into the Amazon Nova documentation was a massive learning curve. I had to learn how to strictly format multimodal payloads, route deterministic reasoning tasks to Nova Lite, and handle the binary audio streams from Nova Sonic directly into the React UI without relying on intermediary cloud storage.
I walked into this project as a data science student tired of manual pipelines, and I'm walking out as a full-stack systems architect.
What's next for NovaFlow: The Autonomous BI Pipeline
I didn't lose three days of sleep just to build a weekend hackathon toy. NovaFlow is the MVP for a real company, and the architecture was built from day one to scale into a serious B2B SaaS.
Here is the actual roadmap:
- Plugging straight into Big Data: Let's be real, C-suite executives aren't manually dragging and dropping CSV files. The immediate next step is building secure, read-only connectors into live data warehouses like Snowflake, AWS Redshift, and Databricks. NovaFlow needs to sit directly on top of live production tables so the boardroom can query terabytes of data and get a strategy brief instantly.
- Upgrading to a Multi-Agent Swarm: Right now, a single Nova Lite agent is basically carrying the entire pipeline on its back. I am going to rip that out and split the workload. I want Amazon Nova Pro handling the heavy predictive modeling, Nova Lite executing the rapid SQL, and a separate third agent acting purely as a strict data governance auditor to catch errors before Plotly even sees them.
- Bi-directional Voice BI: Nova Sonic already reads the strategy brief to the user, but I want executives to be able to talk back to it. Imagine a CEO just saying out loud, "Nova, isolate those high-risk patients and forecast the Q3 impact," and the entire dashboard just re-renders on the fly.
- Y Combinator. That's the end goal. I integrated a PLG paywall, real enterprise authentication, and a zero-idle AWS backend because I want to take this to market. The plan is to get early corporate adoption, prove the unit economics, and apply to YC. I want NovaFlow to be the default AI analyst for modern enterprises.
- Expanding the Visual Engine: Right now the translation layer handles a few core charts, but I want to map out entirely dynamic 3D rendering for complex clustering so the data literally pops off the screen.
Started this project wanting to kill the Jira-ticket data pipeline. I proved it works. Now, I'm going to build the company.
Built With
- amazon-api-gateway
- amazon-bedrock
- amazon-dynamodb
- amazon-sqs
- amazon-web-services
- aws-lambda
- clerk
- css
- nova
- nova-lite
- nova-sonic
- plotly.js
- react
- tailwind
- vite

Log in or sign up for Devpost to join the conversation.