Inspiration
As a computer science student specializing in AI, I realized that doing academic literature reviews takes way too much manual effort. I wanted to build an Agentic System that doesn't just search a static, outdated database via standard APIs, but actually automates the web UI workflow and reads the latest live papers for me just like a human researcher would.
What it does
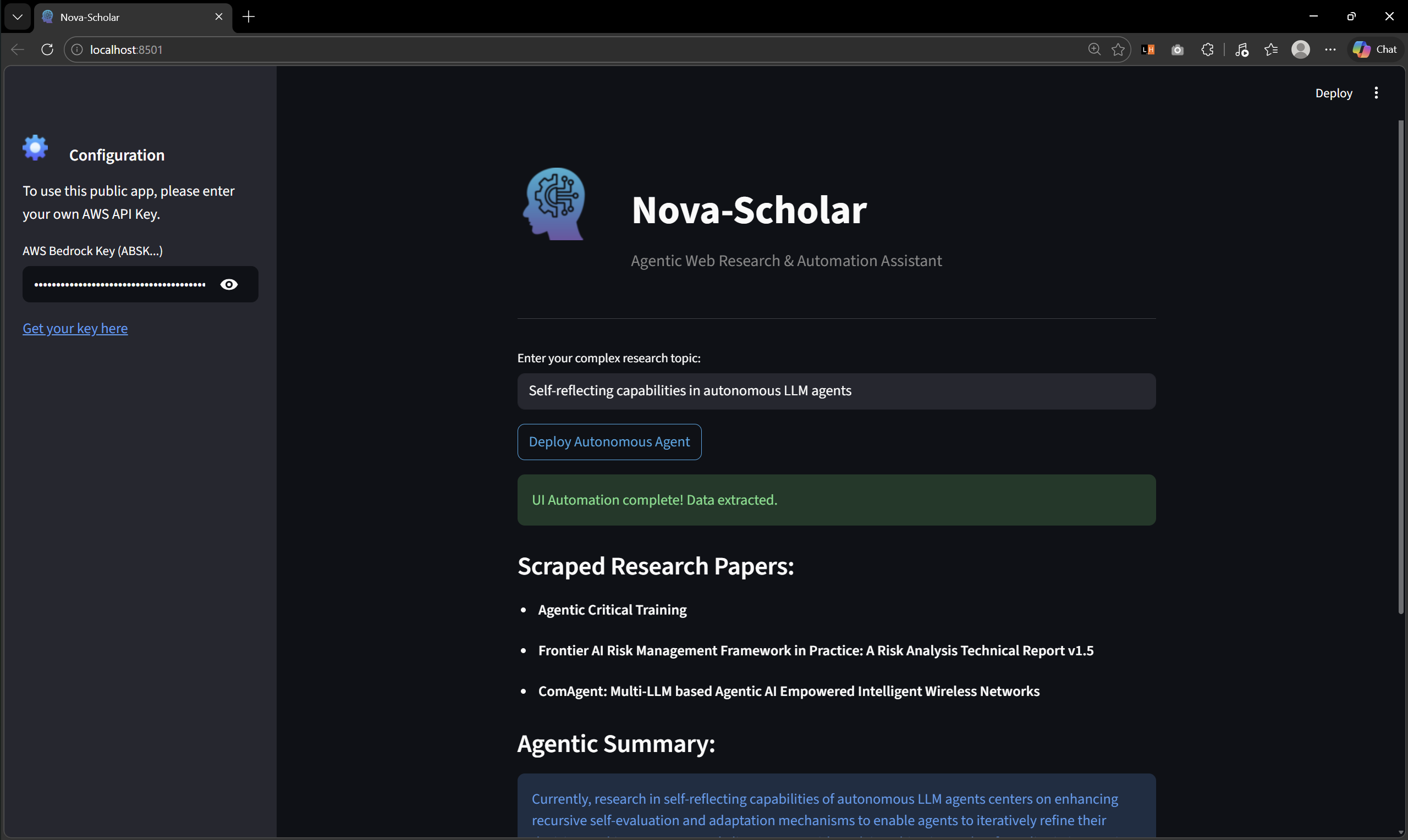
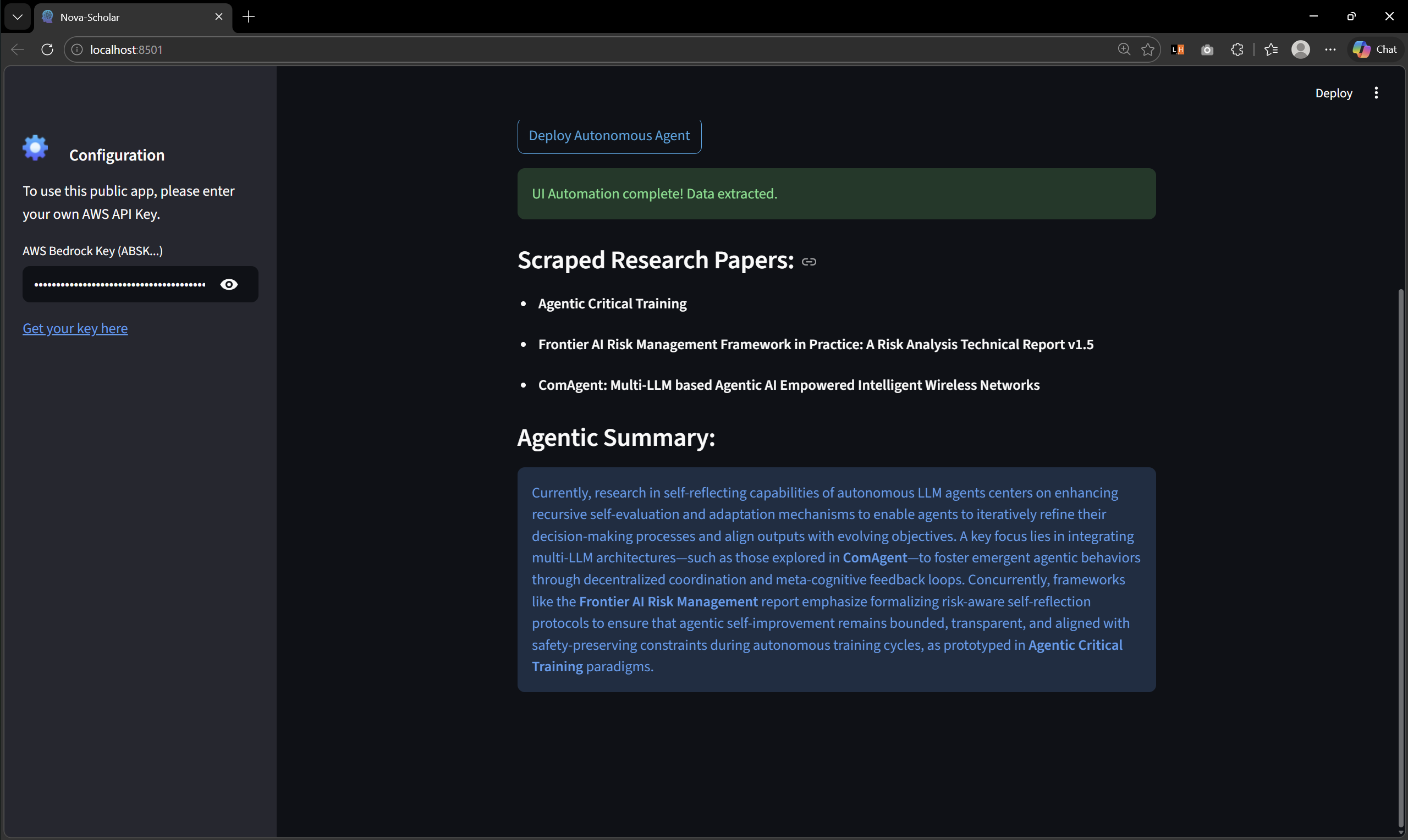
Nova-Scholar acts as an autonomous AI researcher. When given a complex technical topic, it launches a live browser, autonomously navigates to the ArXiv database, types in the query, bypasses basic bot restrictions, and scrapes the live DOM for the most up-to-date research titles. It then passes this extracted context directly to Amazon Nova 2 Lite to instantly synthesize a cohesive, highly technical summary of the field.
How I built it
I built a dual-engine Agentic System in pure Python:
The UI Automation Engine: I utilized Playwright to build the autonomous crawler that physically interacts with the web UI in real-time.
The Intelligence Engine: I integrated the AWS Bedrock Converse API, specifically targeting the us.amazon.nova-2-lite-v1:0 model. I chose Nova 2 Lite because it offers the lightning-fast inference speed required for a real-time web UI loop, while maintaining the high-level reasoning needed to synthesize complex academic data.
The Frontend: I wrapped the agent in a custom, dark-mode Streamlit UI that includes a secure configuration sidebar, allowing users to safely input their own AWS credentials without exposing developer keys.
Challenges I ran into
Handling dynamic UI elements and bot-detection timeouts during the web scraping phase was a major hurdle. I also had to figure out how to implement asyncio loop policies specifically to prevent Windows subsystem crashes when Playwright tried to spawn new browser processes inside the Streamlit event loop. Furthermore, building a secure way to pass AWS API keys dynamically through the Streamlit UI without exposing my own .env variables required careful regex string cleaning and environment management.
Accomplishments that I'm proud of
I am incredibly proud of successfully bypassing standard web scraping limitations by building a true UI automation loop that runs visibly in a browser. I'm also proud of securely integrating the brand-new AWS Bedrock Converse API for the Nova models and wrapping the entire complex architecture into a sleek, user-friendly, enterprise-grade web interface under a strict time limit.
What I learned
I deepened my understanding of asynchronous Python programming, headless vs. non-headless browser automation with Playwright, and how to format message arrays for the new Amazon Bedrock Converse API. I also learned a massive amount about rapid prototyping and securing API keys in public-facing web applications.
What's next for Nova-Scholar
I plan to upgrade the Playwright engine to click directly into the research papers, extract the full PDF text, and utilize Amazon Nova Pro to generate massive, comprehensive literature review documents with automatic citations. I also plan to add a feature for "iterative search," where the agent reads the first summary and autonomously decides to do a second, deeper search based on its findings.
Built With
- amazon-bedrock
- amazon-nova
- amazon-web-services
- playwright
- python
- streamlit

Log in or sign up for Devpost to join the conversation.