-
-
hree-step input form: ticker, optional earnings URL, and a full-width analyze button with real-time timing estimate
-
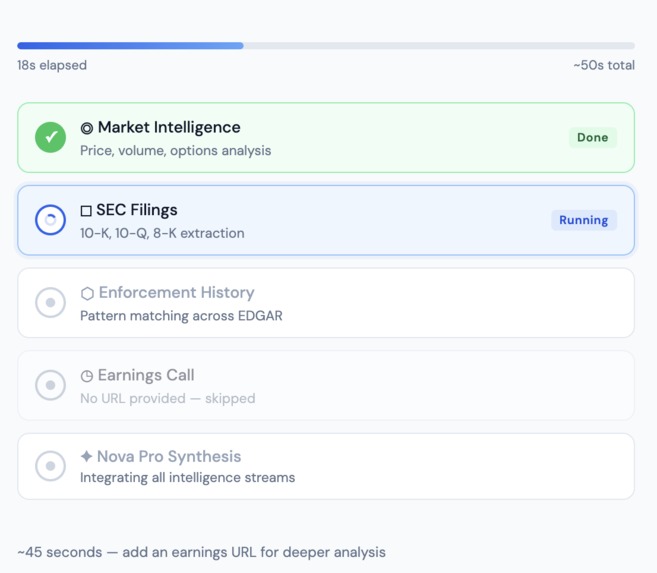
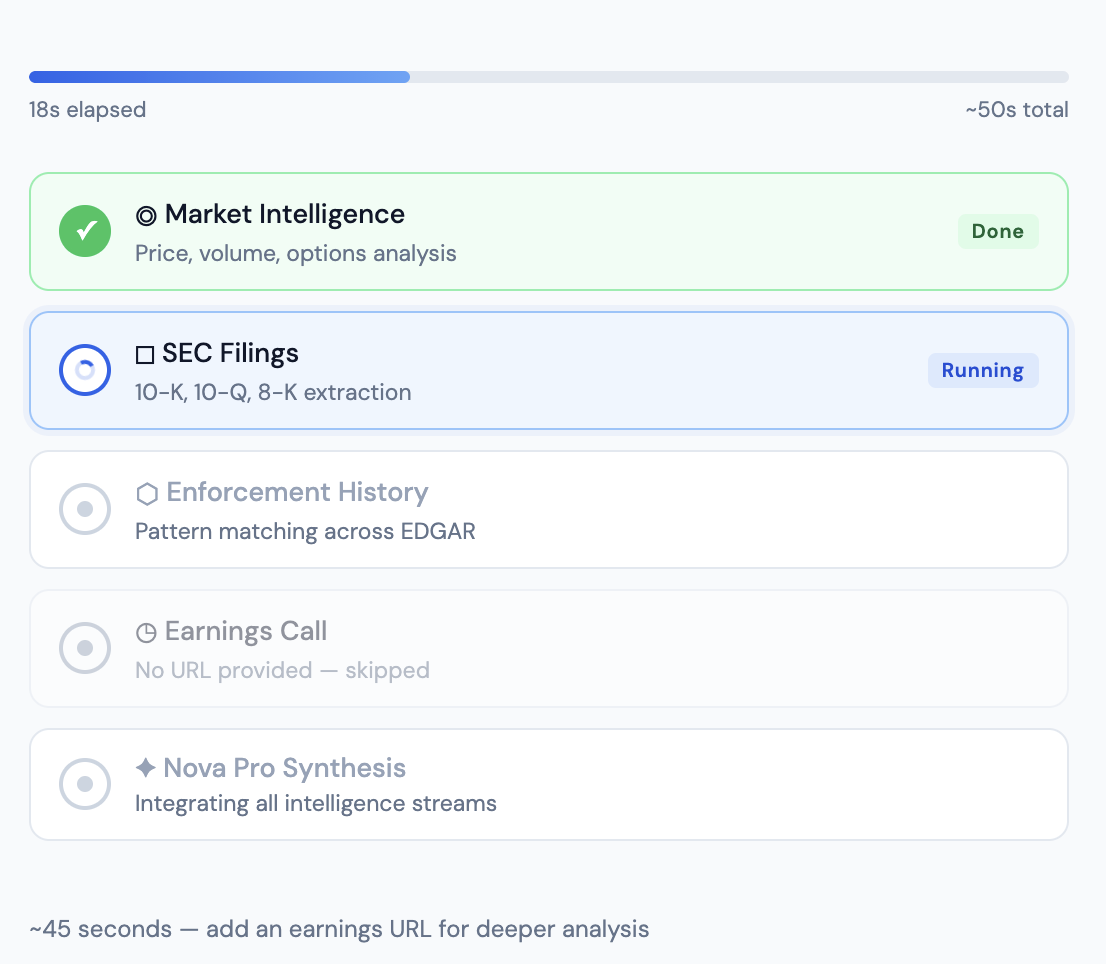
Real-time agent progress: Market done, SEC Filings running, downstream agents waiting. Stages check off as results arrive from Lambda
-
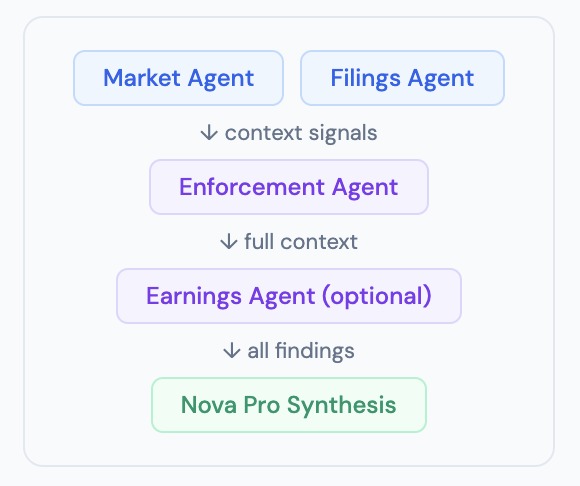
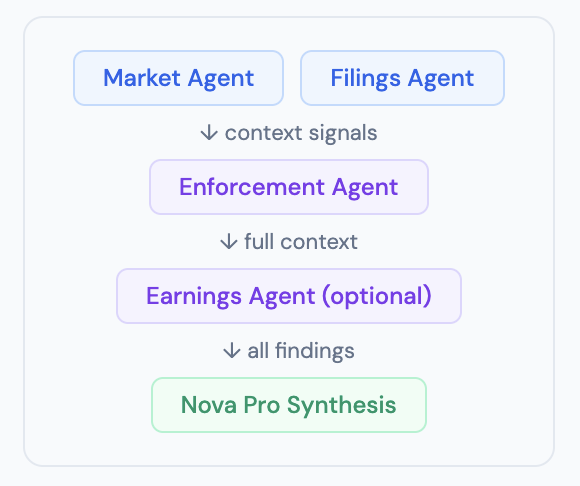
Four-stage pipeline: Market and Filings run in parallel, Enforcement uses their output to target its search, Nova Pro synthesizes everything
-
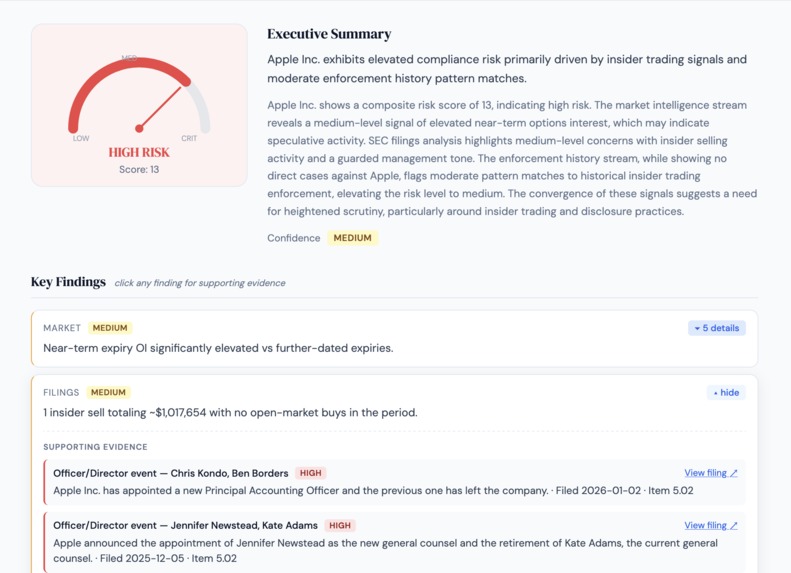
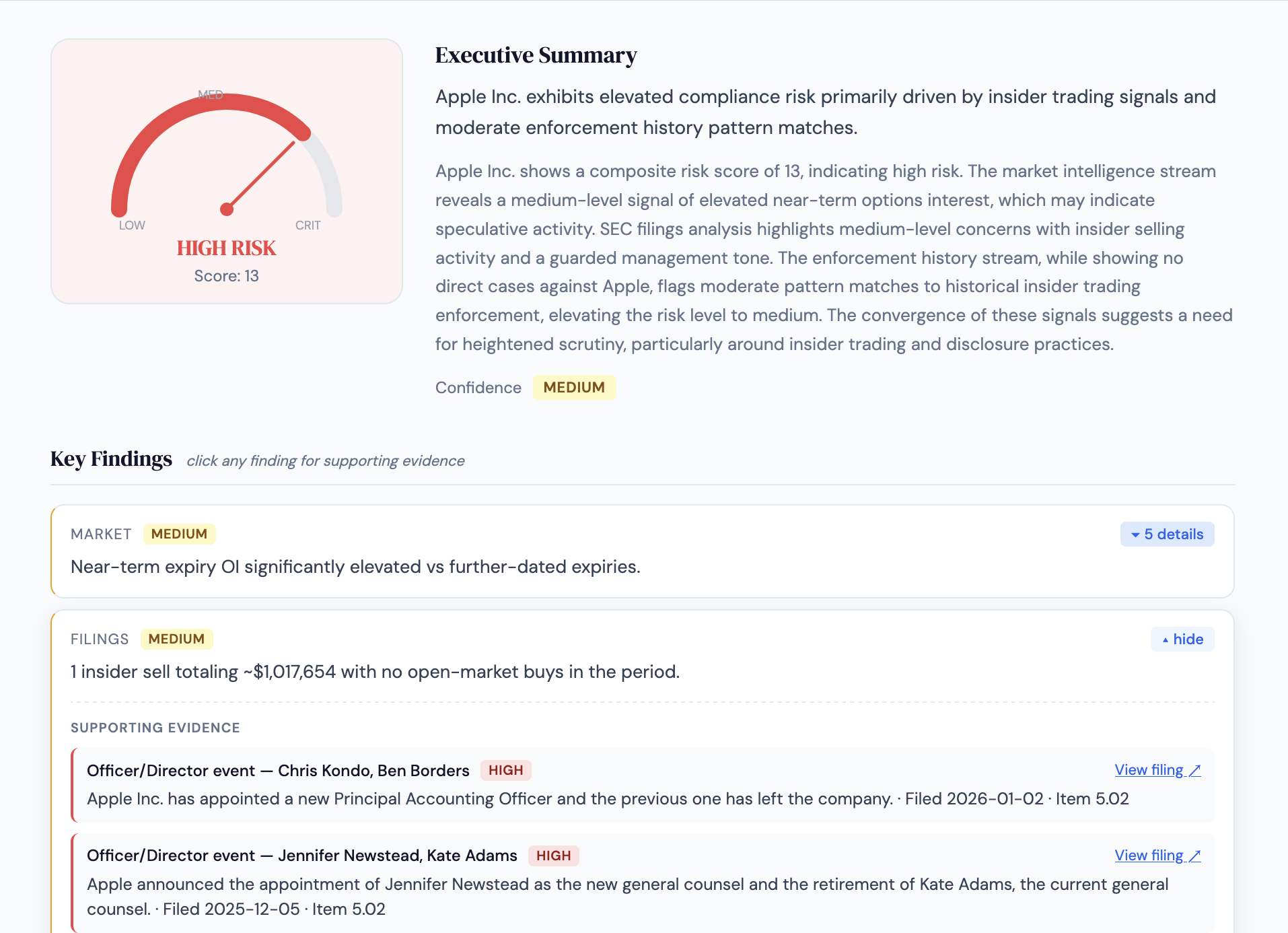
Full results page for Apple Inc. Risk gauge, executive summary synthesized across 4 data streams, and key findings with drill-down support
-
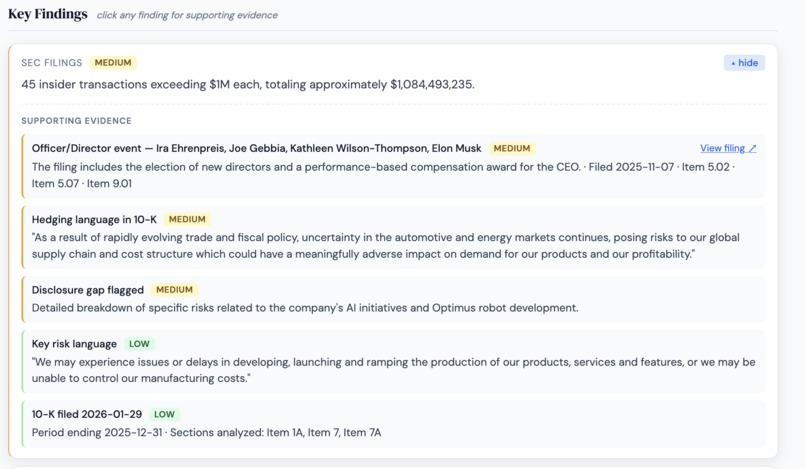
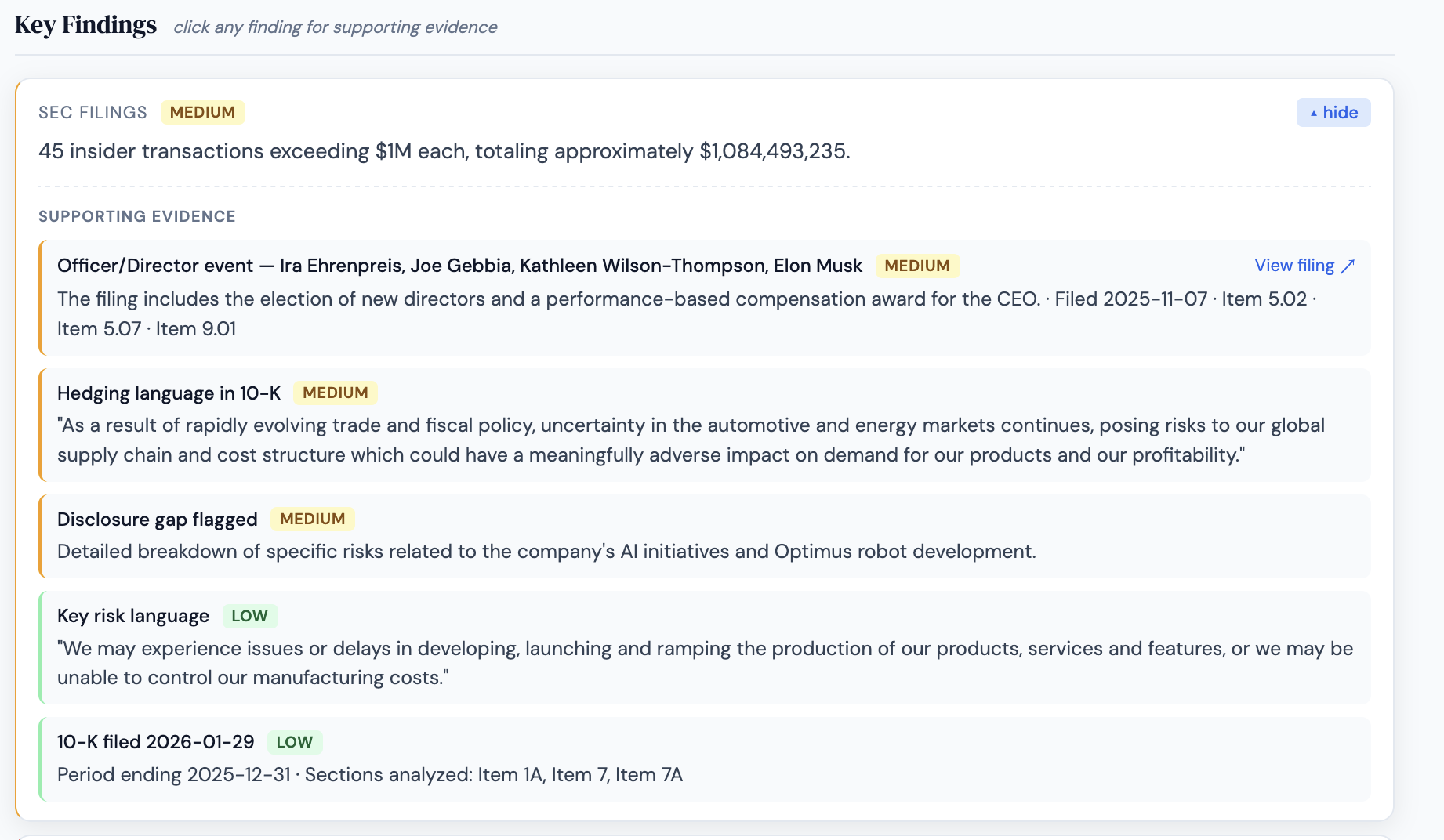
Filings drill-down showing officer events with named individuals extracted from SEC filing text, linked directly to EDGAR source filings
Inspiration
I've spent my career in financial services product and architecture, most recently at FINRA. One thing that never changes regardless of the firm or the role: compliance analysts spend a disproportionate amount of time on work that shouldn't require human judgment. Not because the work is unimportant (it's critical), but because gathering and organizing the raw material consumes hours before a single insight gets generated.
The specific trigger for NOVA was watching a compliance team prepare for a counterparty review. Four people. Three days. Most of that time was spent pulling 10-Ks, checking EDGAR for enforcement history, downloading earnings transcripts, and cross-referencing everything in a spreadsheet. The actual analysis, the part that required their expertise, took maybe four hours total.
That ratio bothered me. This hackathon gave me a reason to do something about it.
What it does
NOVA analyzes any publicly traded company for compliance risk by running four specialized agents in a staged pipeline, then synthesizing their findings through Amazon Nova Pro.
The pipeline looks like this:
Stage 1 (parallel): Market Agent + Filings Agent | context signals | Stage 2: Enforcement Agent | full context | Stage 3 (optional): Earnings Agent | all findings | Stage 4: Nova Pro Synthesis
Each agent owns a distinct data stream:
Market Intelligence: six months of price/volume data, options activity, and anomaly detection
SEC Filings: 10-K, 10-Q, and 8-K analysis via EDGAR, including Nova Lite-powered semantic classification of Item 5.02 officer events and Form 4 insider transaction parsing direct from SEC XML
Enforcement History: direct enforcement disclosures from company filings plus pattern matching against analogous historical cases
Earnings Call: optional behavioral analysis of transcript tone, hedging language, and filing inconsistencies
The result is a Compliance Readiness Dossier, not a decision, but a complete starting point that takes under a minute rather than days.
How we built it
Intelligent model routing was the key architectural decision. Not every task needs the same model. Nova Lite handles per-agent structured extraction and classification. Nova Pro handles the final cross-stream synthesis. This distinction matters for production workloads. The latency and cost difference between the two models is significant enough to justify application-level routing logic.
The back-end runs on AWS Lambda (Docker container, 2048MB), with API Gateway handling an async job pattern: POST to /analyze returns a job_id immediately and the front-end polls /status/{job_id} while showing real-time agent progress. DynamoDB stores job state with incremental stage checkpoints written after each agent completes, which is what drives the live progress visualization in the UI. All infrastructure is defined in CDK. The front-end is React with Vite, served via S3 and CloudFront.
Challenges we ran into
Processing time with large documents. Nova Pro's PDF analysis of a 200-page earnings release takes 60-90 seconds. Model inference time is what it is, but the 2048MB Lambda memory allocation (up from 1024MB) made a noticeable difference on everything else, and the async polling pattern means the user sees real progress rather than a frozen screen.
EDGAR rate limiting and access patterns. SEC EDGAR has strict rate limits and some filing formats don't parse cleanly through library abstractions. Building reliable fall-backs: fetch the HTML directly, strip tags, search for specific section markers all added complexity but was necessary for production-grade reliability across a diverse set of companies and filing types.
Structured output consistency. Nova Lite intermittently wraps JSON responses in markdown code fences despite explicit instructions to return raw JSON. This required defensive stripping on every response. This kind of non-deterministic behavior is easy to miss in development and painful in production. Boilerplate vs signal. Teaching the model to distinguish between legally required forward-looking language (which appears in every 10-K and means nothing) and genuine operational hedging (which is rare and meaningful) required more iteration than expected. What eventually worked: concrete positive and negative examples plus a structural rule about which document sections to exclude. The path to get there was empirical rather than documented.
Accomplishments that we're proud of
Getting the Item 5.02 semantic extraction right was the result I'm most satisfied with. The jump from regex name extraction to Nova Lite reading the full filing section and returning all named individuals with correctly classified event types: departure vs appointment vs compensation change vs board change - is the kind of qualitative improvement that's hard to spec in advance and obvious once you see it. Tesla's Annual Meeting filing returning four named individuals with individual risk assessments, from a single 8-K, is a result a compliance analyst would actually use.
The progress visualization was a smaller technical win that made a real UX difference. Writing incremental stage checkpoints to DynamoDB after each agent completes, then polling from the front-end every two seconds, means the user watches Market and Filings check off in parallel and sees Enforcement light up when they finish. For a 45-second analysis it gives the user confidence that something real is happening and tells them which stage is taking longest.
The intelligent model routing also came together cleanly. Nova Lite for per-agent classification, Nova Pro for final synthesis, with each prompt tuned specifically for its task. The cost and latency profile of the resulting system is something you could run at production scale for a real compliance team.
What we learned
Nova Lite handled more than I expected. I'd assumed the heavier model would be needed for most tasks. The Item 5.02 semantic analysis is a good example - early versions used regex to extract officer names from 8-K filings. Regex works sometimes. It completely missed Tesla's Annual Meeting 8-K, which contained both director elections and Elon Musk's CEO performance award approval in the same filing because it stopped at the first match. Nova Lite read the entire section and returned all four named individuals with their roles, event types, and individual risk scores. The difference in output quality was immediate.
Prompt precision matters more than prompt length. The hedging language detection took four iterations to stabilize. The model kept including standard Risk Factors boilerplate even when told not to. The fix wasn't a longer prompt. The fix was a more precise rule: Risk Factors section language is always excluded, regardless of how company-specific it sounds, because it is required forward-looking disclosure. Structural rules work better than judgment-based instructions when the boundary needs to hold consistently.
The silent filing.obj() failure. The edgartools library's filing.obj() method fails silently on a significant percentage of real EDGAR filings. The outer except Exception: continue pattern swallows the error and keeps counting the filing, so totals look right but content is missing. The fix was fetching filing HTML directly via EDGAR URLs and parsing it independently. This class of silent failure, where error handling makes a bug invisible, took longer to diagnose than any of the model-related challenges.
What's next for NOVA — Multi-Agent Compliance Intelligence on AWS Nova
Watchlist monitoring is the obvious next step - scheduled analysis with alerts when risk scores change materially between periods. Longitudinal earnings call analysis across multiple quarters would surface behavioral drift that no single call reveals. And the agent architecture is deliberately modular: each agent implements a standard interface, so new data streams plug directly into the existing pipeline without touching the orchestrator.
The deadline was a useful forcing function.
Built With
- amazon-cloudfront-cdn
- amazon-dynamodb
- amazon-nova
- amazon-transcribe
- api
- bedrock
- cdk
- docker
- edgartools
- javascript
- lambda
- nova
- python
- react
- s3
- sec-edgar
- vite
- yfinance

Log in or sign up for Devpost to join the conversation.