Inspiration:
NOVA Lab began with something deeply personal. We lost our grandfather to ALS, a disease that slowly took away his ability to move, speak, and ultimately live independently. Watching that progression firsthand changed how we saw biology. Proteins were no longer abstract molecules in a textbook. They were the difference between function and failure, between life and loss. At the same time, we were also exploring environmental challenges, particularly plastic waste, and the role of enzymes like PETase in breaking it down. What stood out to us was that both problems came down to proteins, but they required completely different solutions. That realization became our inspiration. Protein engineering should not be one dimensional. It should adapt to the problem it is trying to solve.
What it does:
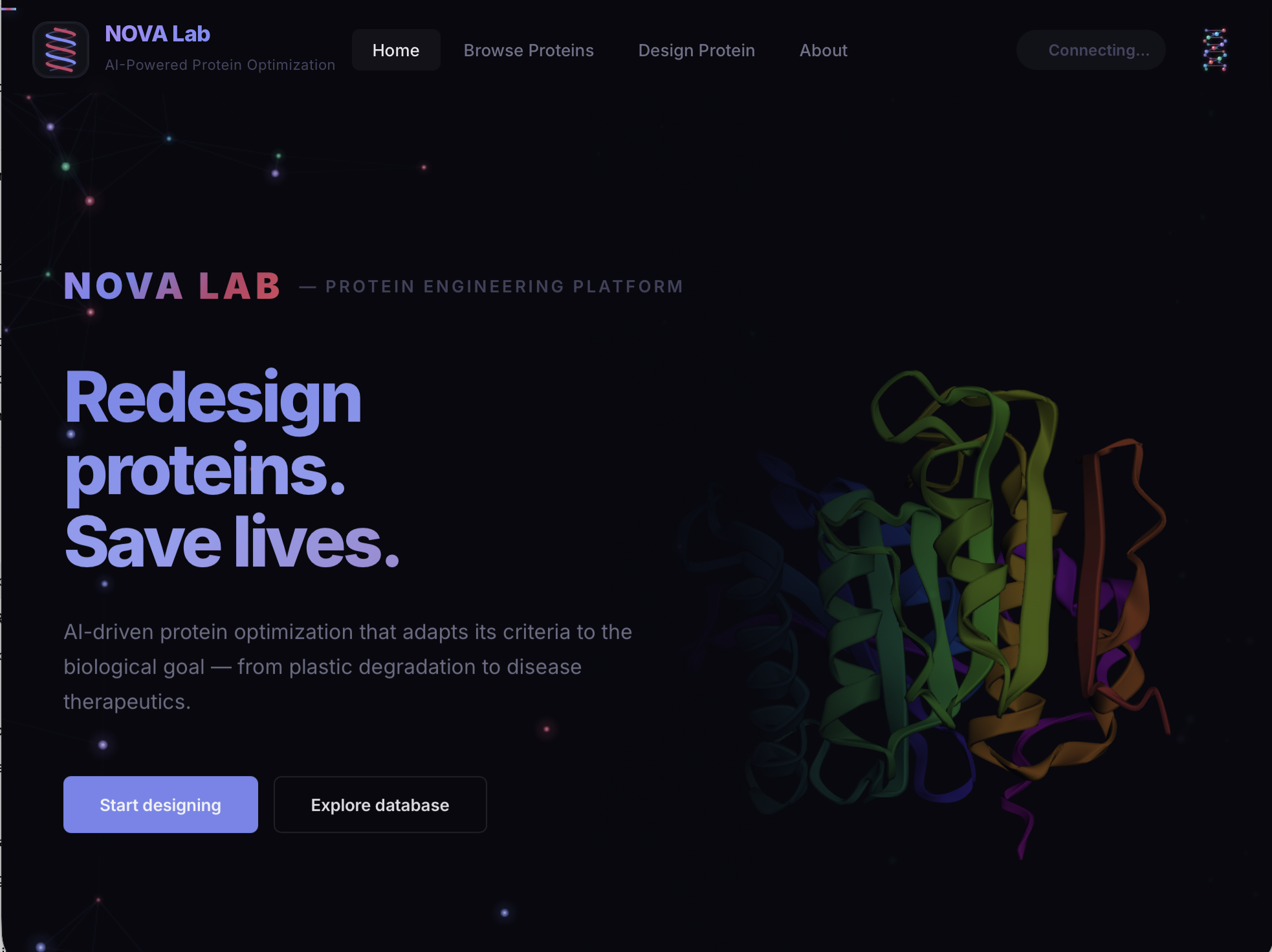
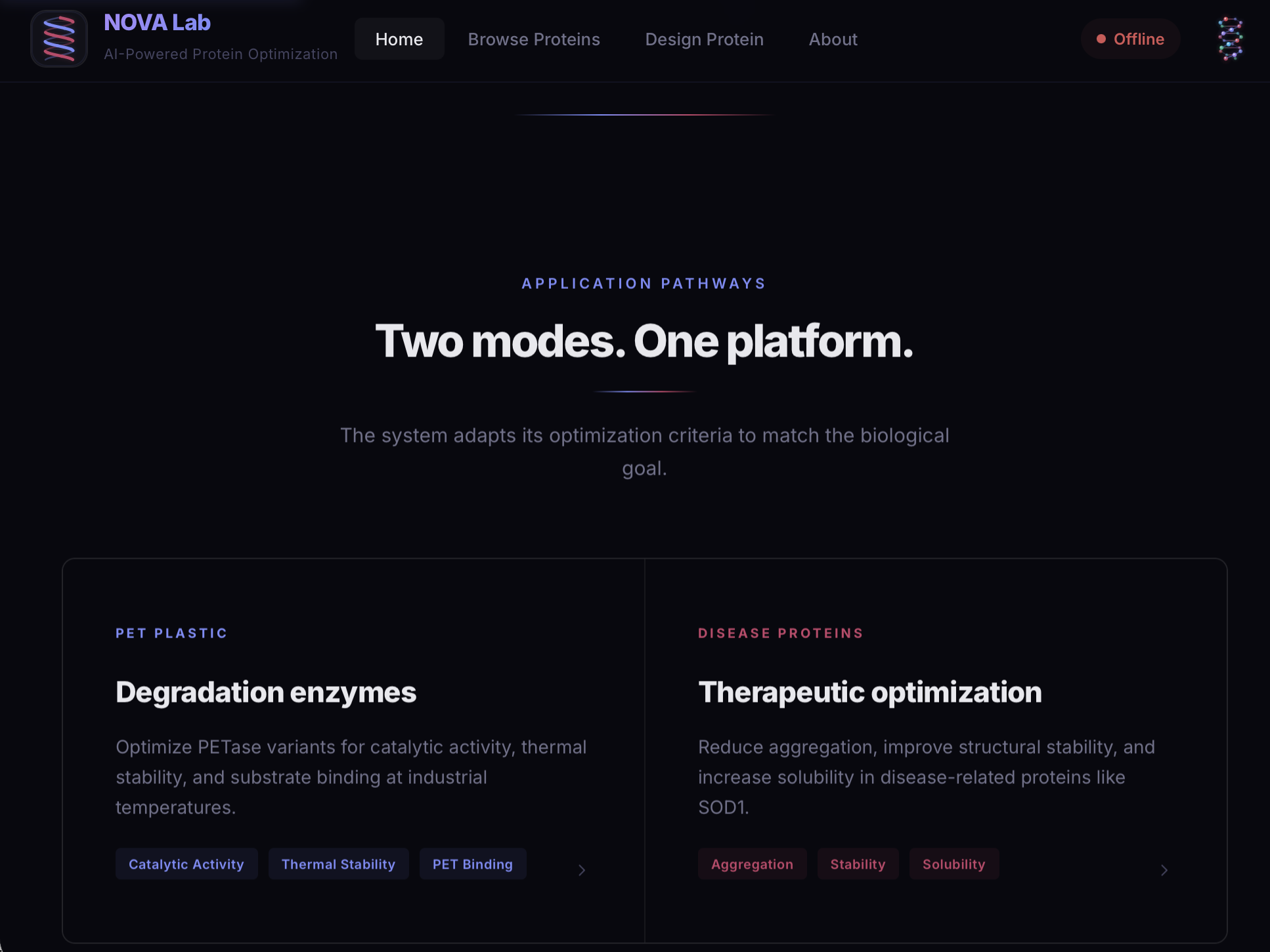
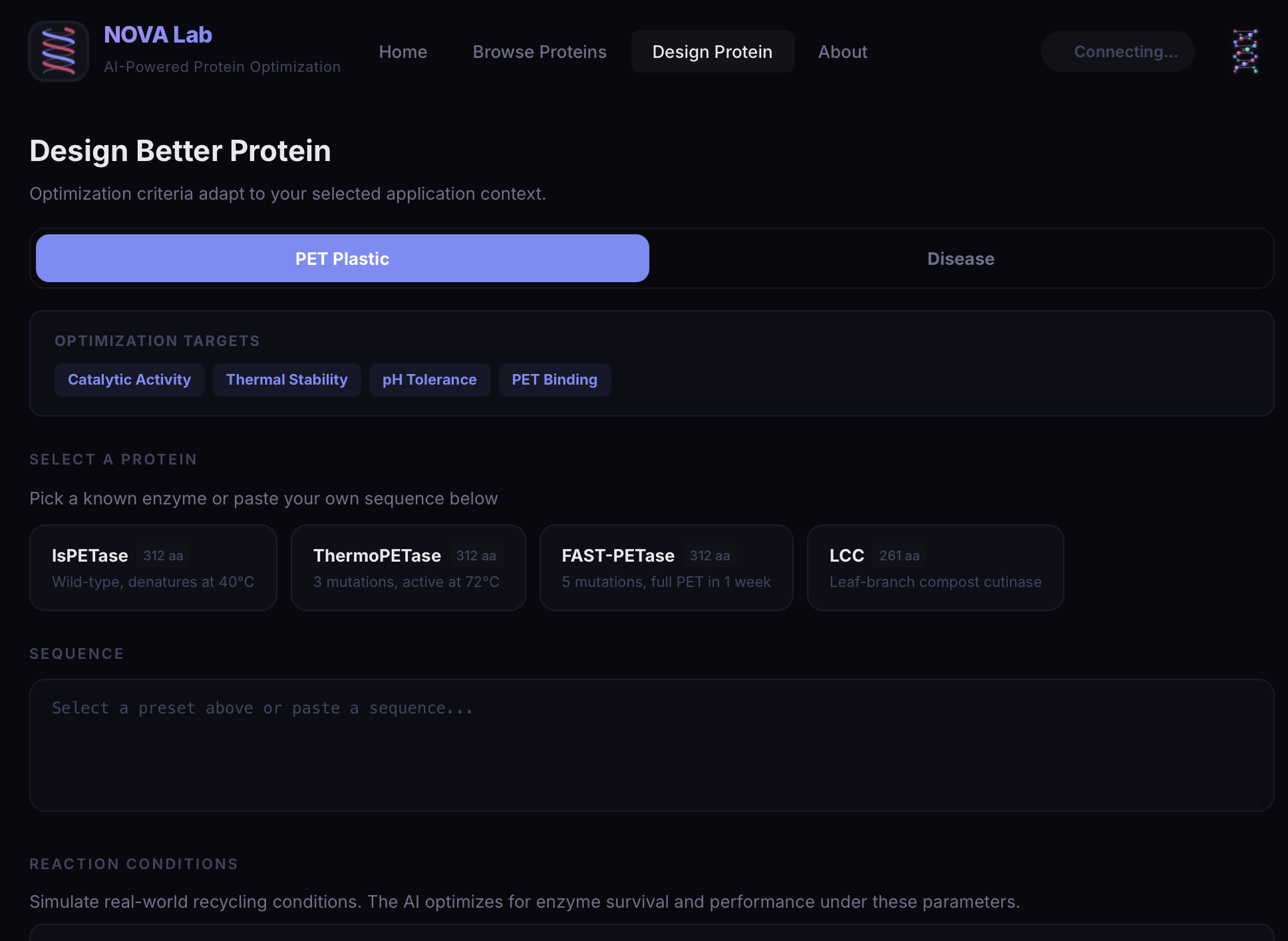
NOVA Lab is an AI-guided protein engineering platform designed for context-aware optimization. Instead of using a single objective, the platform allows users to optimize proteins based on application-specific goals. In industrial settings like PET plastic degradation, it focuses on improving activity, thermal stability, and environmental tolerance. In disease settings like ALS, it prioritizes reducing aggregation, increasing structural stability, improving solubility, and preserving function. Users can seamlessly switch between modes, such as plastic degradation and disease stabilization, and the entire system adapts accordingly, including the database and new enzyme design workflows. At its core, NOVA Lab balances multiple competing biological objectives to generate protein variants that are both functional and practical for real-world applications.
How we built it:
We built NOVA Lab by combining machine learning with biologically informed optimization strategies.
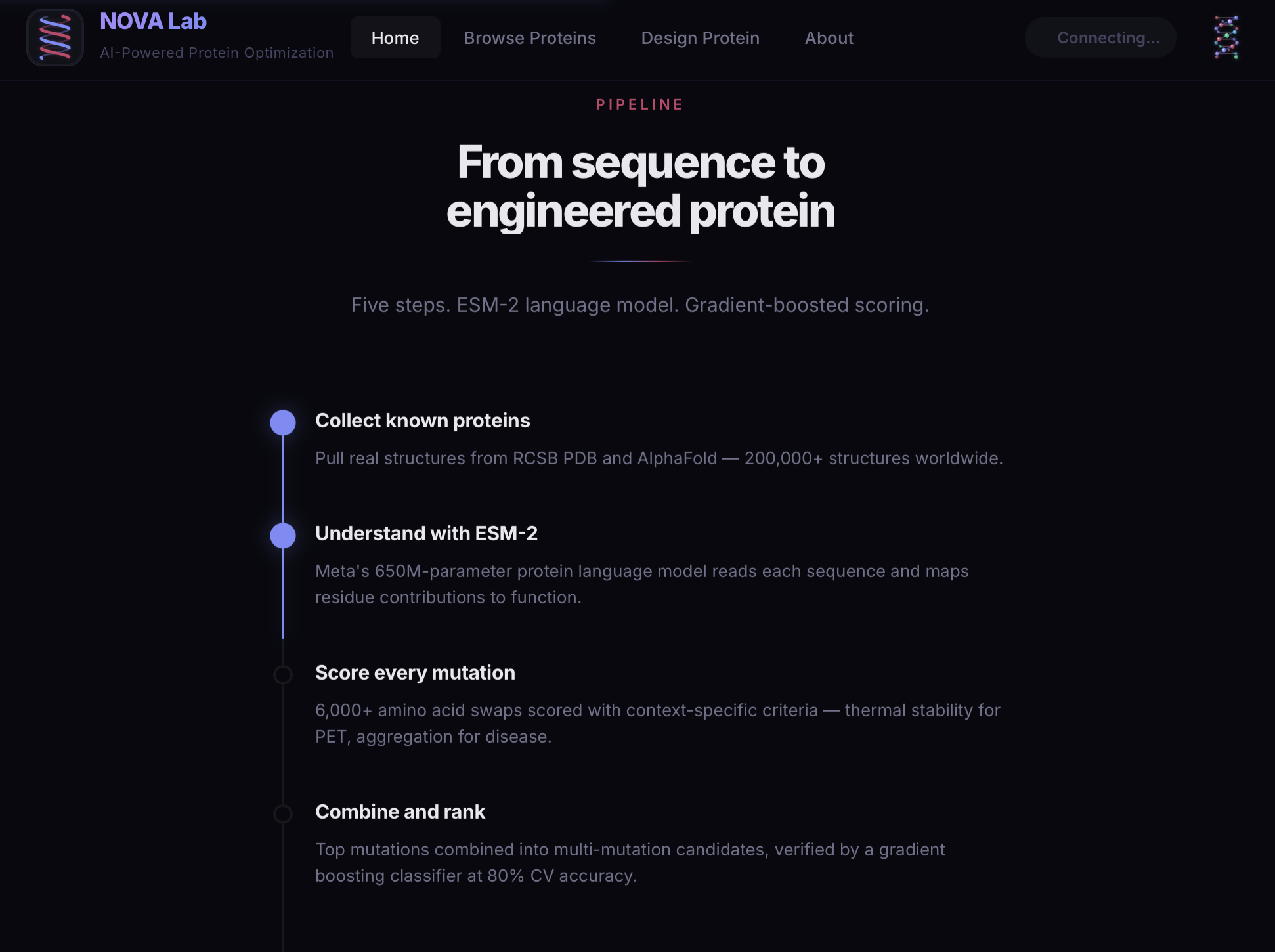
The platform evaluates protein sequences and predicts how mutations impact key properties such as stability, aggregation, solubility, and function. These predictions are integrated into a multi-objective optimization system that balances tradeoffs instead of optimizing a single metric. To enable this at scale, we leveraged AMD-based compute to train and run models such as ESM-2, allowing us to efficiently process large protein sequence datasets and generate high-quality mutation effect predictions.
We sourced structural and sequence data from the RCSB Protein Data Bank and AlphaFold, which provided high-quality protein structures and predicted models to inform our analysis and optimization pipeline.
We designed the system to be modular, allowing different optimization criteria to be applied depending on the selected mode. This enables seamless switching between industrial and disease-focused workflows.
To manage the complexity of the data generated, we implemented a centralized data workflow through Palantir. Protein variants, mutation effects, and predicted properties are structured into a unified data layer, enabling us to compare thousands of variants across multiple dimensions. This system allows us to analyze tradeoffs, track optimization outcomes, and support context-aware decision making across different biological applications.
On the frontend, we focused on creating an intuitive interface where users can adjust optimization parameters dynamically and immediately understand the impact of their choices. The system maintains consistency across all features, including database exploration and enzyme creation, with seamless mode switching between disease and industrial contexts.
Challenges we ran into:
One of the biggest challenges was balancing competing objectives. Improving one property, such as stability, can negatively impact another, such as function. Designing a system that could intelligently navigate these tradeoffs without oversimplifying the biology required careful modeling and iteration. Another challenge was building a platform that could handle fundamentally different problem domains. Industrial enzyme optimization and disease-related protein stabilization require different priorities, constraints, and evaluation strategies. We also faced challenges in translating complex biological concepts into an interface that is both intuitive and flexible, especially when allowing users to dynamically control optimization parameters. Accomplishments that we're proud of We are most proud of creating a platform that goes beyond single-objective optimization and introduces true context awareness into protein engineering. We successfully demonstrated this by applying the same system to two very different use cases: PETase for plastic degradation and SOD1 for ALS-related stabilization. We also built a cohesive user experience where mode switching is seamless and consistent across the platform, making complex biological optimization accessible and interactive. Most importantly, we were able to connect a deeply personal motivation with a technical solution that has potential impact across both environmental and biomedical fields.
What we learned:
Through this project, we learned that protein engineering is fundamentally about tradeoffs. There is no single “best” mutation. Every decision depends on context, and understanding that context is just as important as the underlying model. We also learned how to bridge disciplines, combining machine learning, biology, and system design into a unified platform. Finally, we learned the importance of designing tools that are not only technically sound but also intuitive for users, especially when dealing with complex scientific concepts.
What's next for NOVA Lab:
Next, we plan to improve both the depth and breadth of the platform. On the technical side, we aim to integrate more advanced predictive models and expand the range of protein properties that can be optimized. We also want to incorporate real experimental datasets to further validate and refine our predictions. On the application side, we plan to extend NOVA Lab to a wider range of human diseases and explore more industrial enzymes beyond PETase. We also want to enhance the user experience by adding more visualization tools, deeper insights into model predictions, and collaborative features for researchers. Ultimately, our goal is to build a platform that can meaningfully contribute to both solving environmental challenges and advancing the understanding of protein-related diseases.
Built With
- 3dmol.js
- alphafold-api
- amd
- amd-instinct-mi300x
- esm-2-(meta-protein-language-model)
- fastapi
- html/css
- javascript
- palantier
- python
- pytorch
- railway
- rcsb-pdb-api
- rocm
- scikit-learn
- xgboost

Log in or sign up for Devpost to join the conversation.