-
-
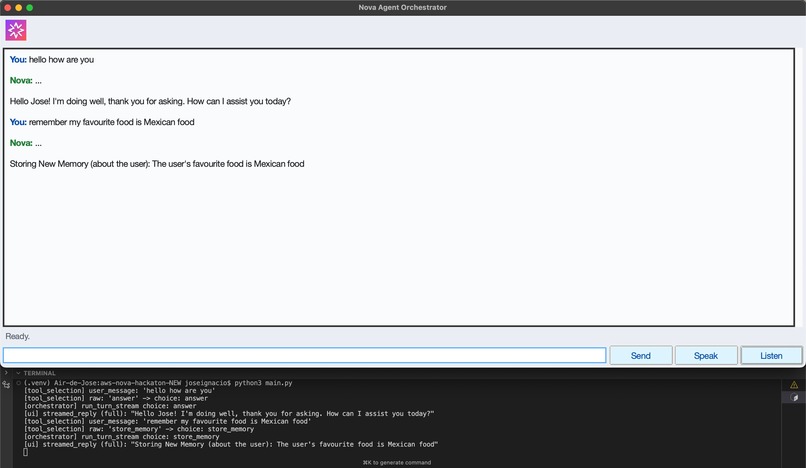
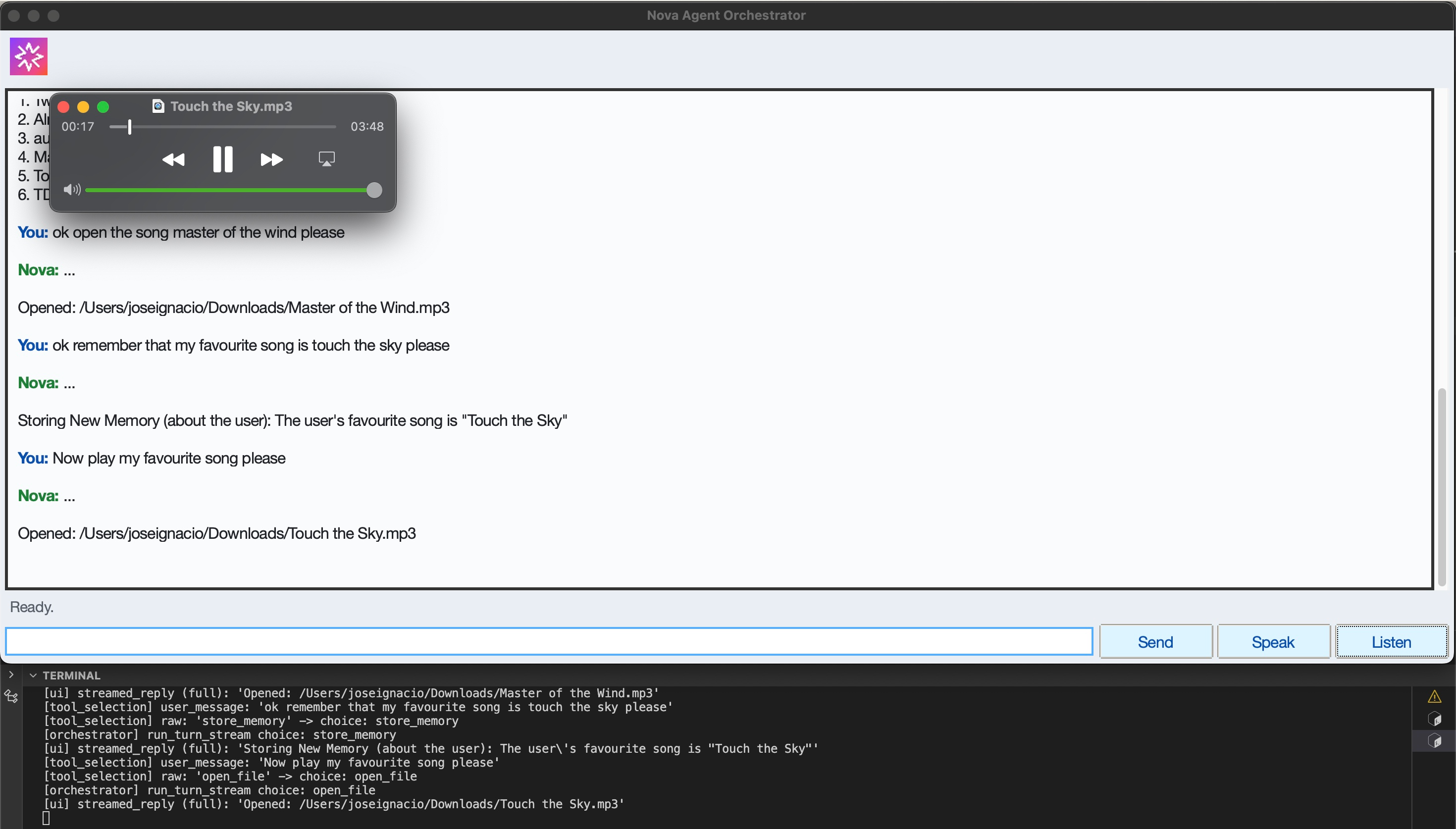
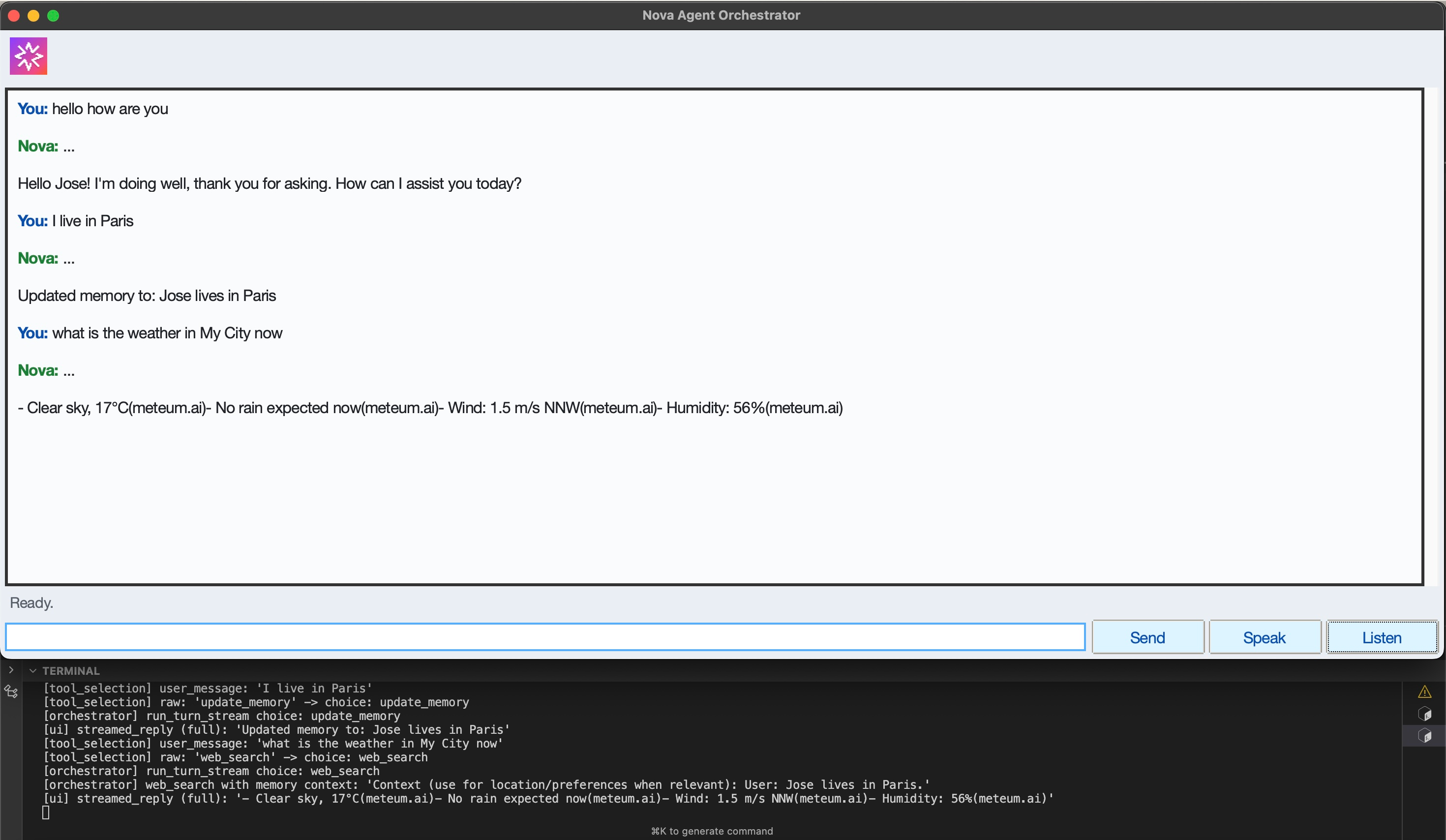
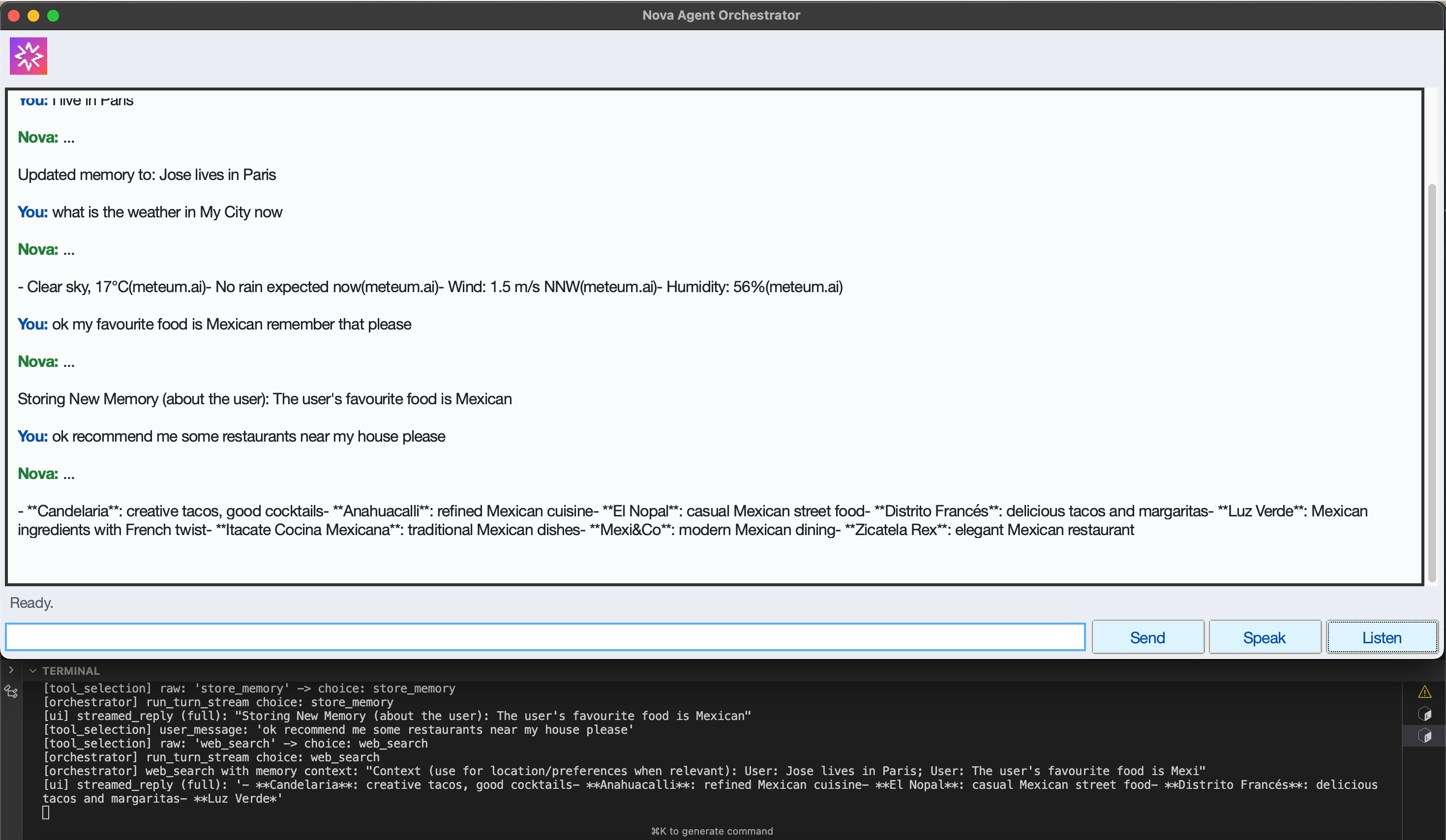
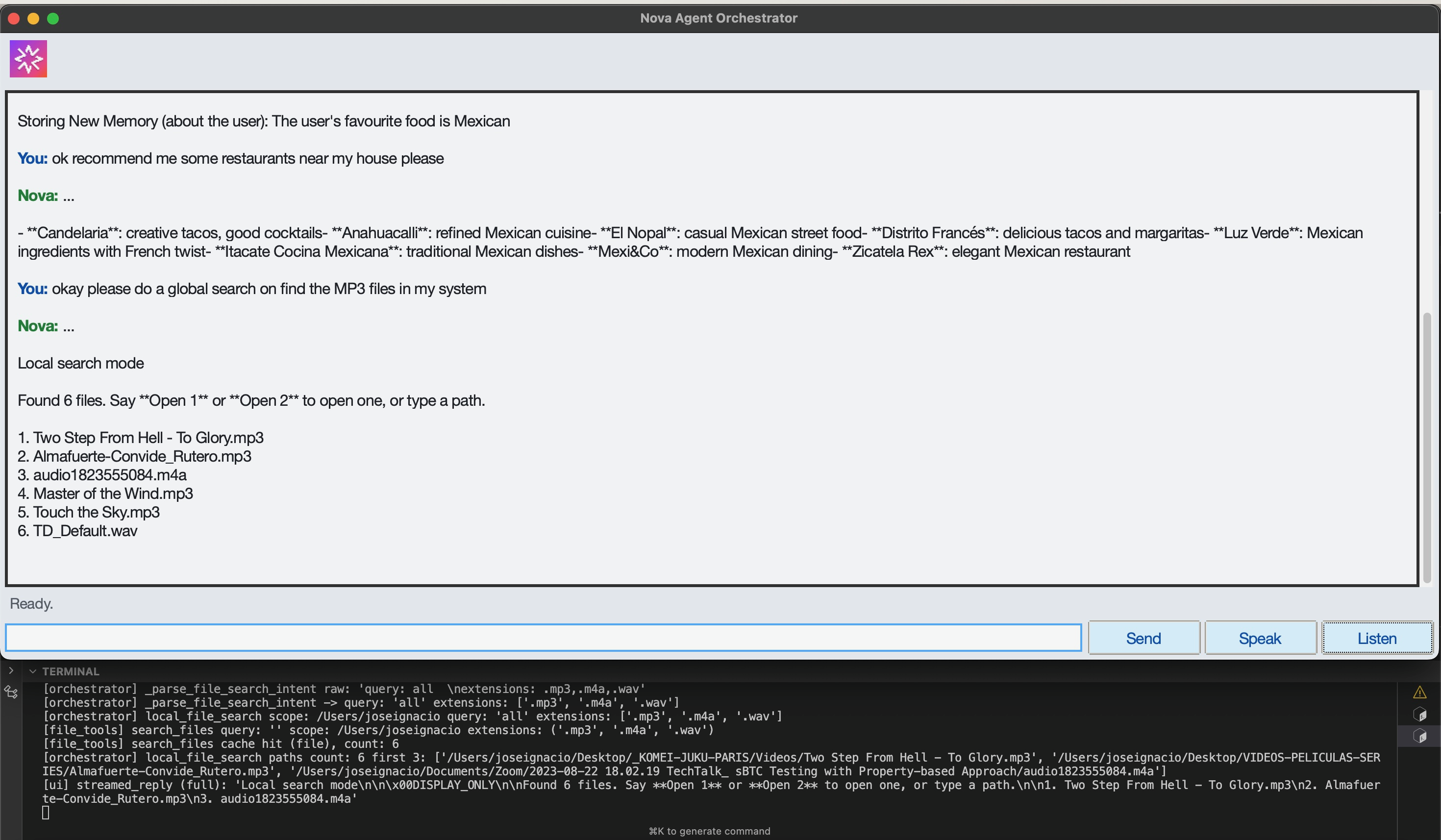
Persistent Memory Detection and Storage
-
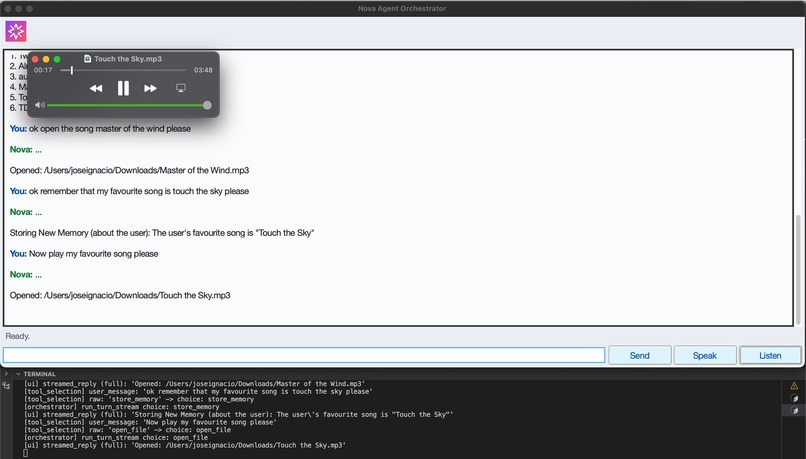
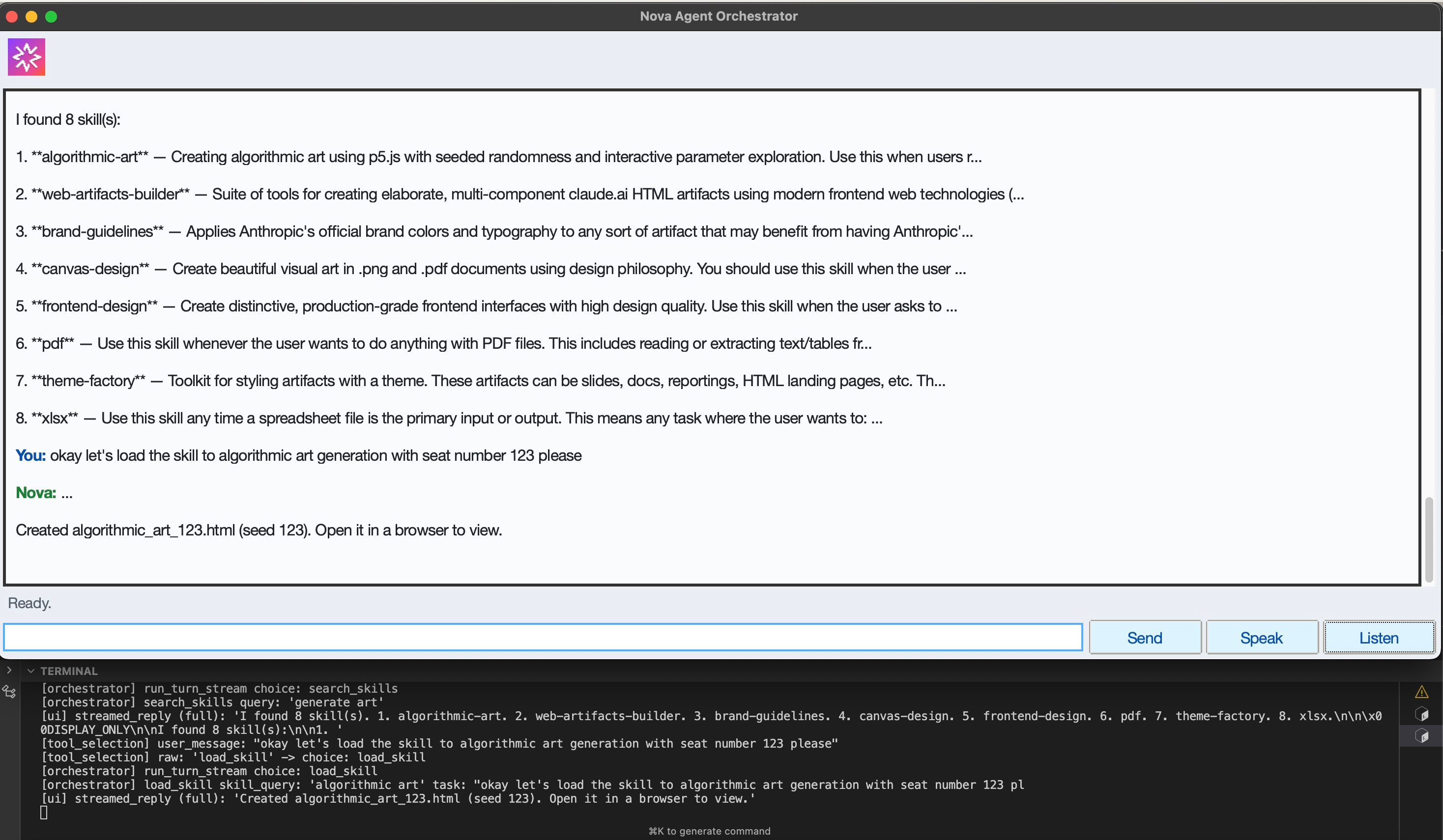
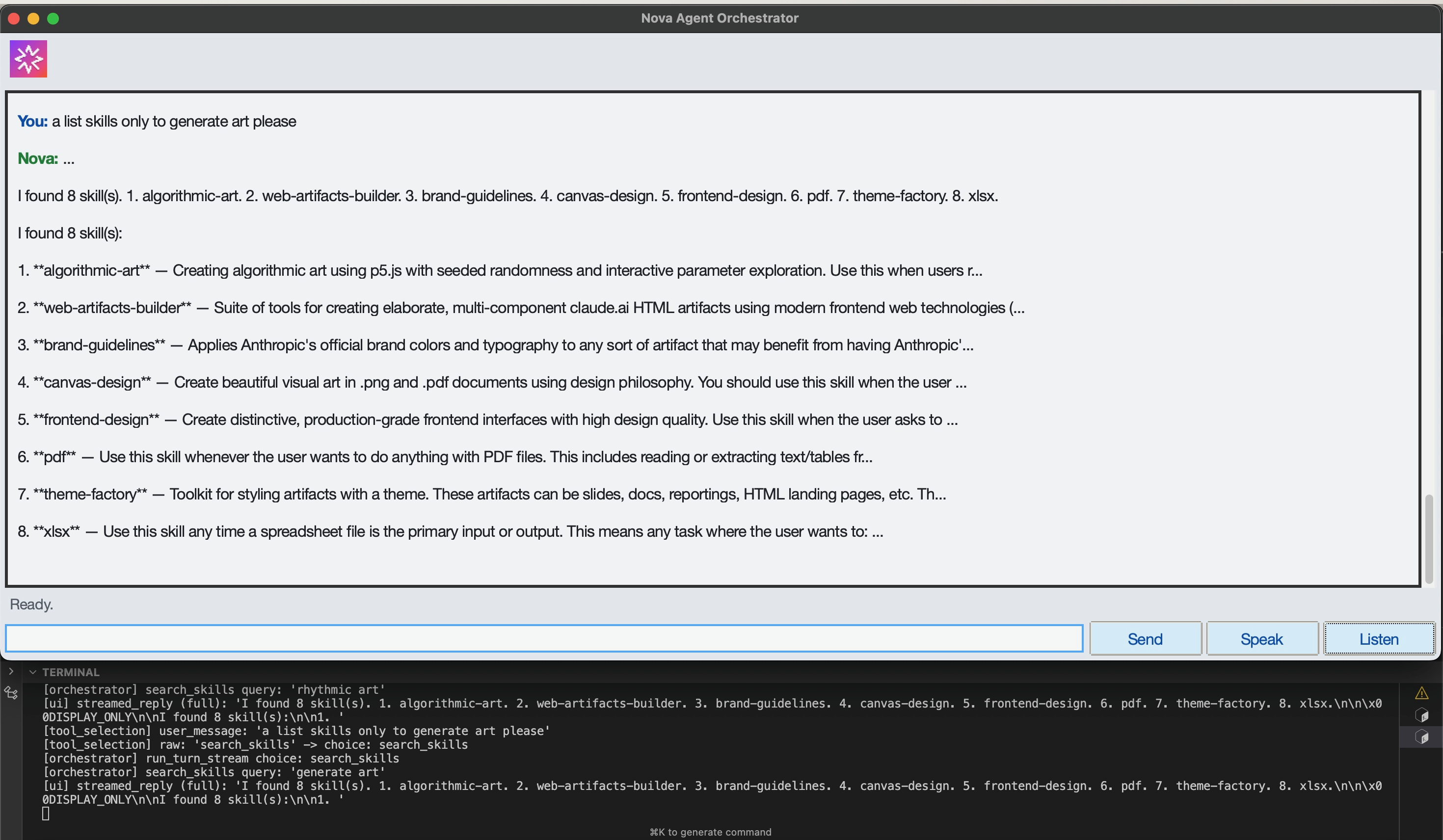
List Skills and Filter
-
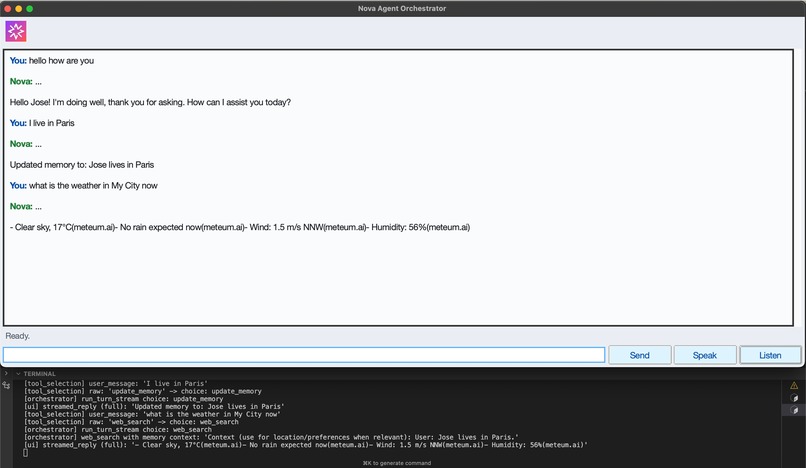
Web Search with Persistent Memory Context
-
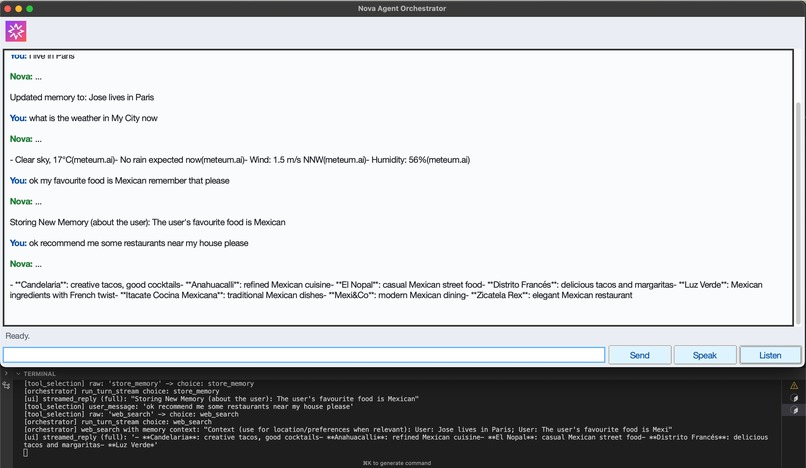
Web Search with Memory Context
-
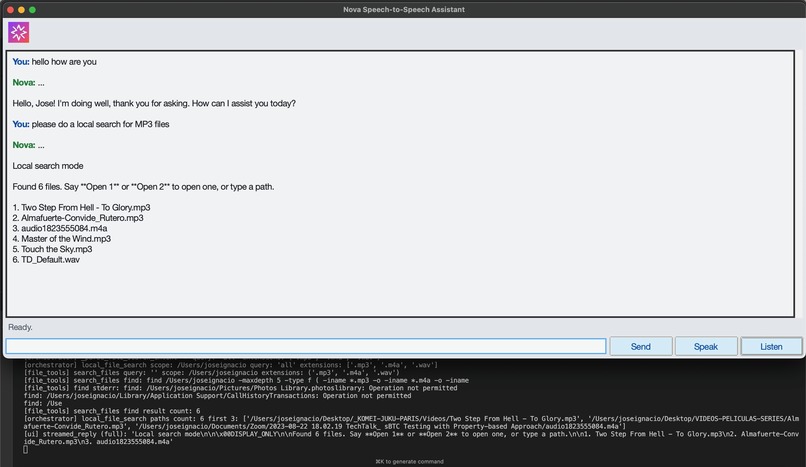
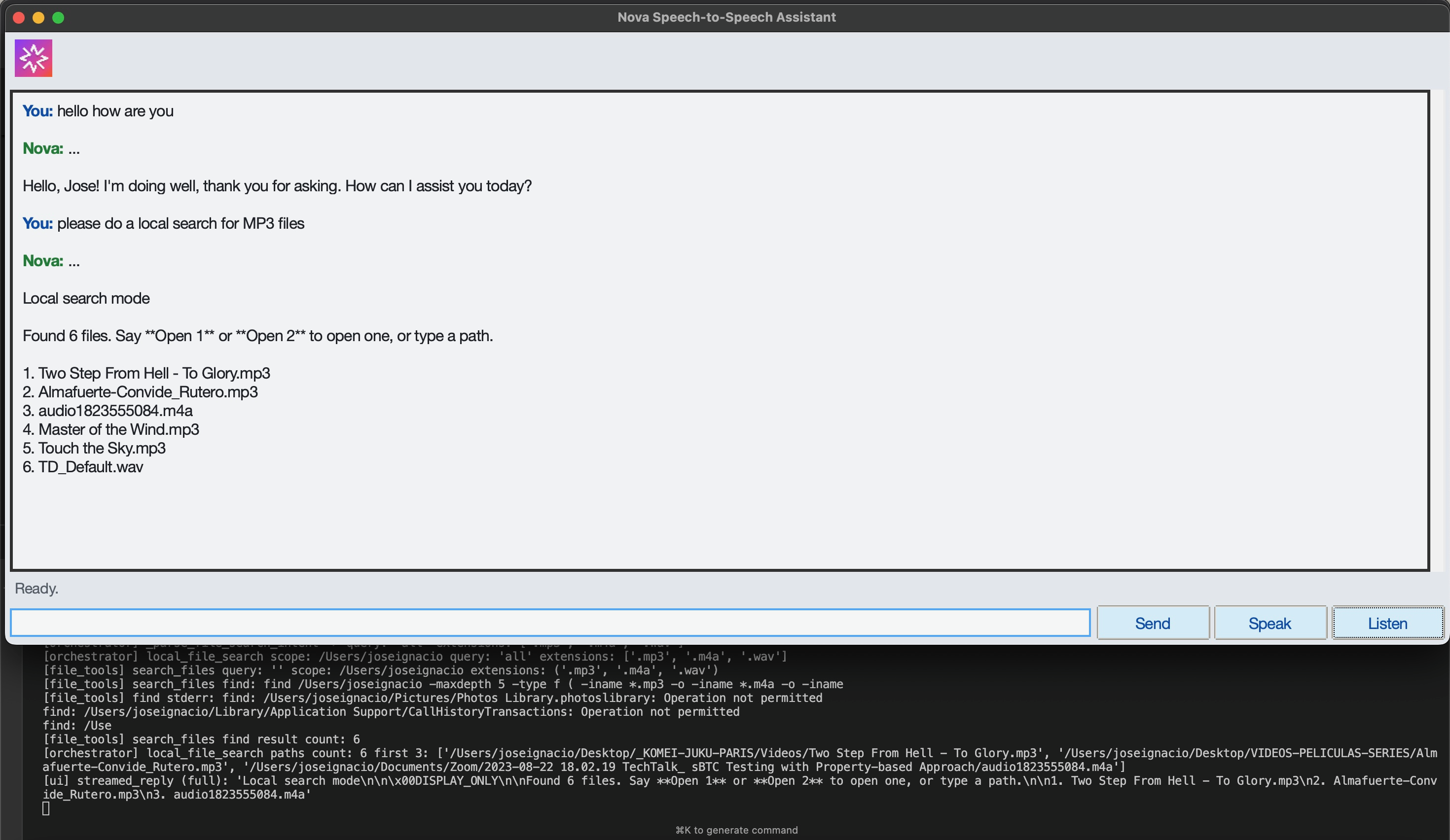
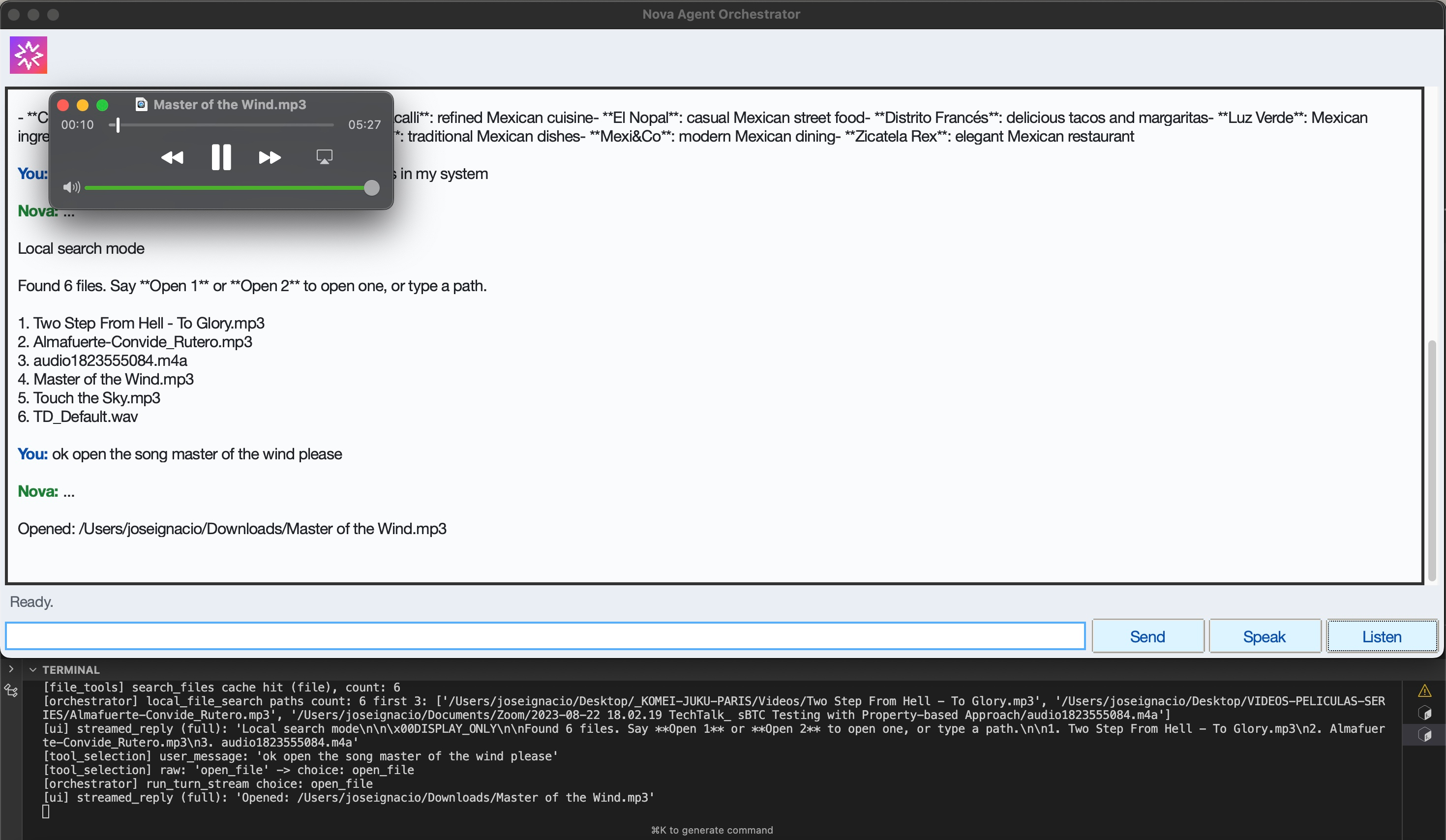
Local File Search
-
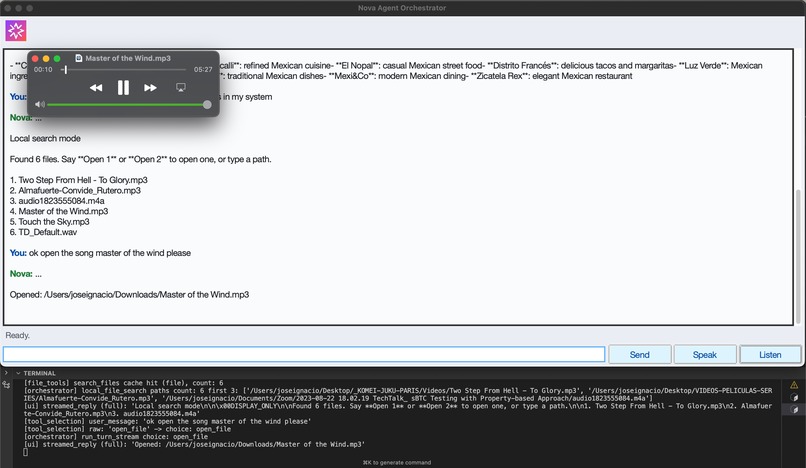
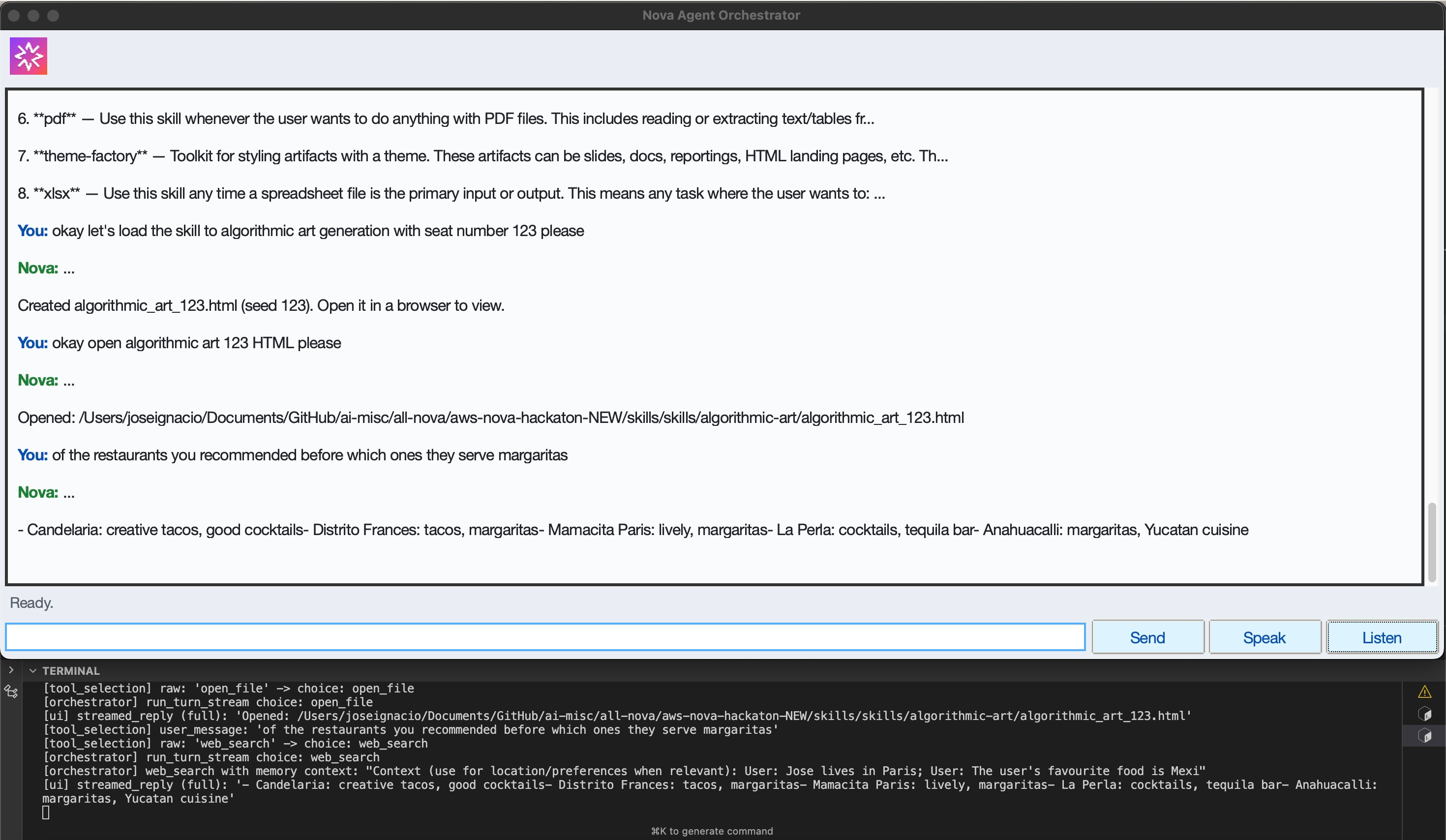
Memory Context + Open File Skill
-
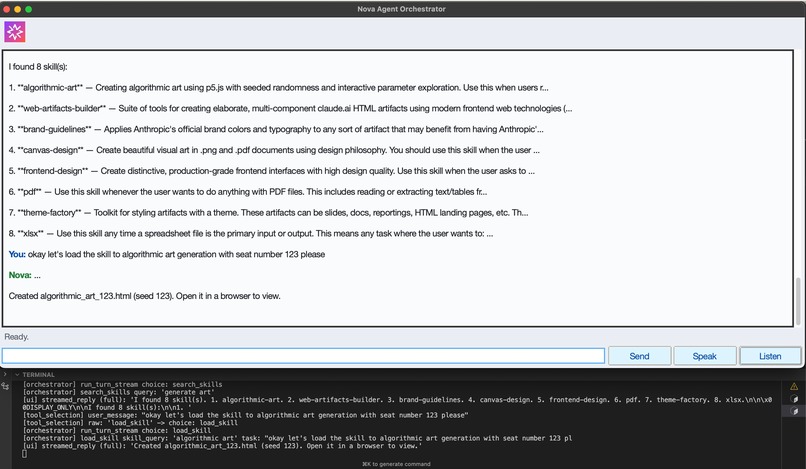
Open Generated File from Filepath Cache
-
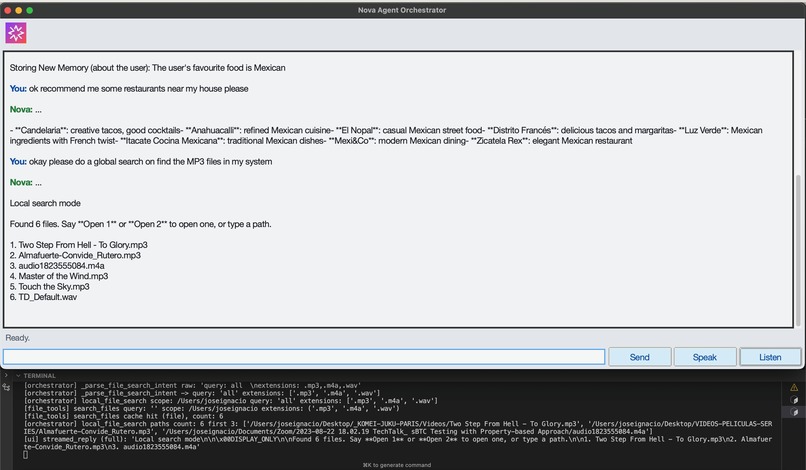
Open File Skill + Cache of Recent Files
-
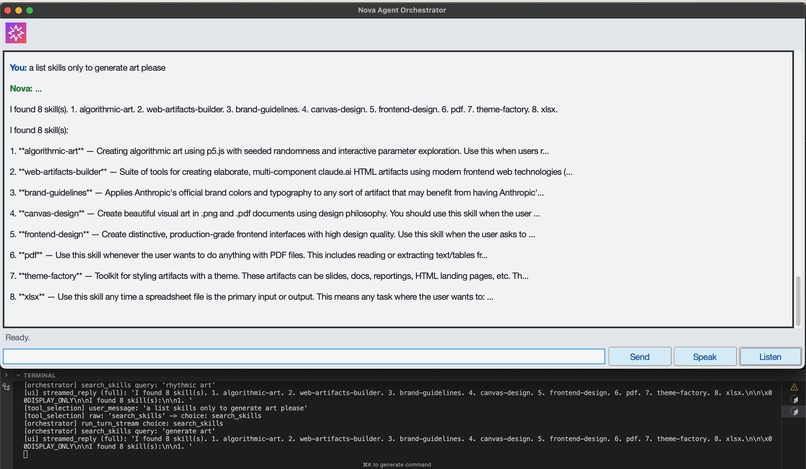
Load Skill with Custom Input
-
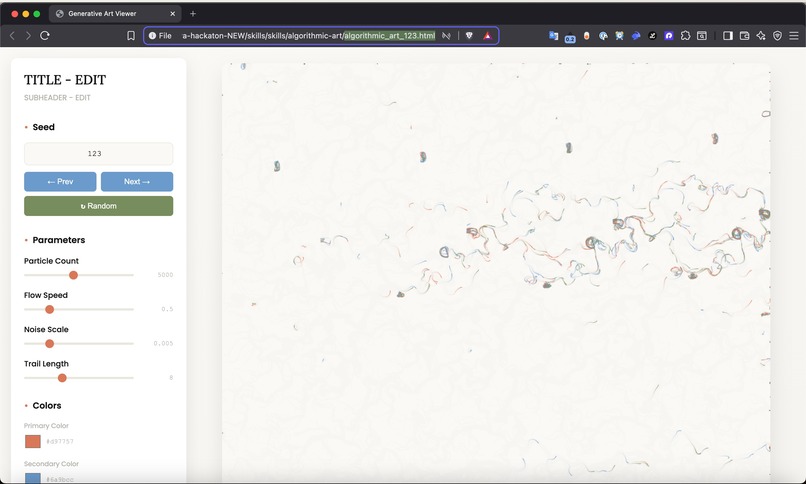
Example HTML Opened
-
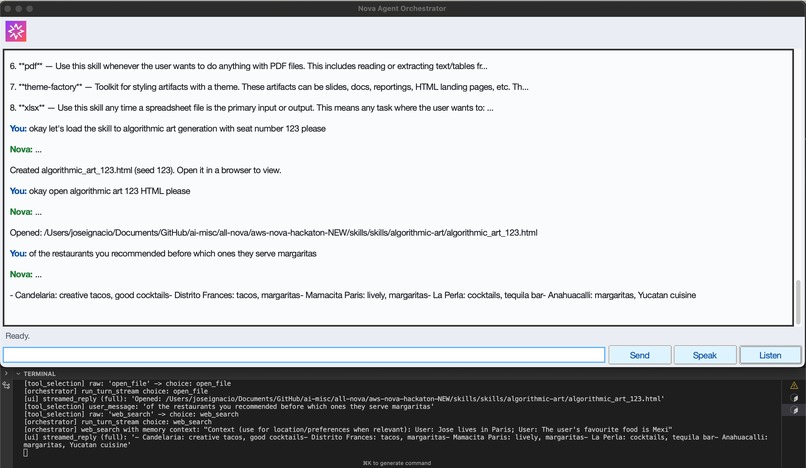
Session Short-term Memory
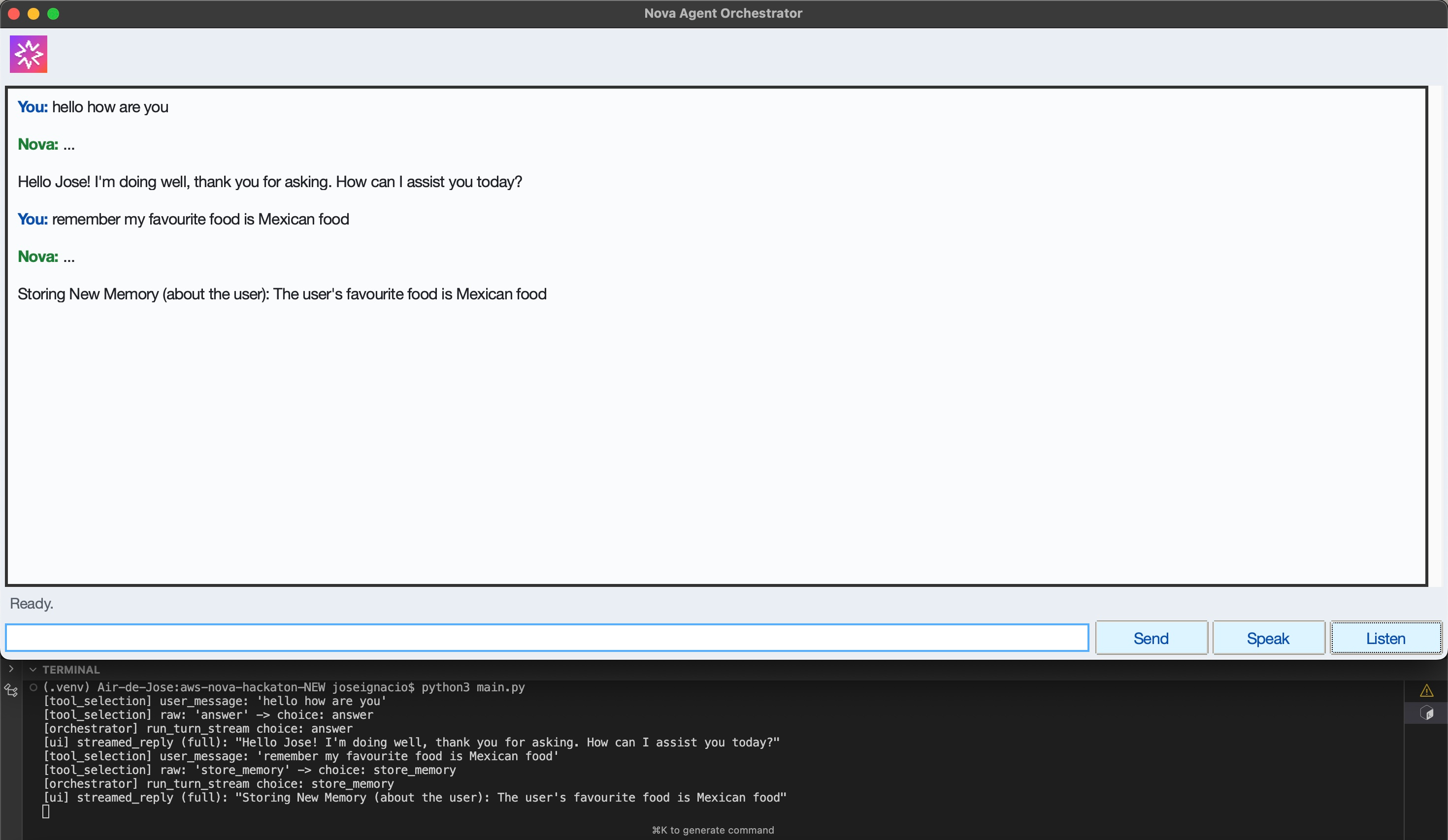
Inspiration
We wanted a local, privacy-preserving “AI OS” for developers that can actually operate on their machine: searching files, running scripts, applying skills, and remembering recent context without sending everything to the cloud. Cursor already gives deep code understanding; Nova Agent Orchestrator aims to add a robust orchestration layer on top of it: tools, skills, short‑term memory, and file awareness, all wired together in a way that feels like using a real assistant, not a chat bot.
What it does
- Understands intent and routes to tools: Classifies user requests (code help, local file search, skill invocation, research, etc.) and calls the right tool chain.
- Runs “skills” as real programs: Converts Markdown skills into runnable Python scripts (or uses existing
run.py) and executes them with structured input. - Caches and reuses file paths: Maintains a shared recent-file cache (search hits, opened files, skill outputs) so the user can say “Open 2” or refer back to generated artifacts.
- Keeps short‑term memory: Stores recent conversational and tool context to improve resolution (e.g. resolving vague file references from prior turns).
- Local-first developer workflows: Uses the local filesystem, local virtualenv, and tools like
find, so the assistant can actually manipulate and open the user’s files.
How we built it
- Core orchestrator: Implemented in Python, with a main
run_turn_streamloop that:- Interprets user messages.
- Chooses an action (skill, search, open file, normal chat).
- Streams model responses and tool output back to the UI.
- Skills pipeline:
- Skill discovery via
SKILL.mdfrontmatter (skills_tools.py). - Optional conversion of skills to Python using Nova, with heuristics to decide if a single-script implementation is safe.
- Execution via a project
.venv, with lightweight dependency inference and installation from comments/imports.
- Skill discovery via
- File tooling (
file_tools.py):- File search backed by
find+ on-disk and in‑memory cache. - A unified recent-path cache (
.recent_file_paths.json) shared by all tools and the orchestrator. - “Open N” and fuzzy path resolution that use both cached search results and recent paths.
- File search backed by
- Memory integration:
- Simple, bounded short‑term memory store wired into intent parsing and file resolution so ambiguous prompts can be grounded in recent history.
Challenges we ran into
- Skill execution robustness: Many skills come from Markdown descriptions, not clean scripts. We had to:
- Decide when not to auto-generate a script (interactive / multi‑step skills).
- Enforce strict script input/output conventions so orchestration stays predictable.
- Path handling and UX:
- Ensuring everything uses absolute paths, works across platforms, and avoids cluttering caches with irrelevant paths (e.g.
.venv,site-packages). - Making “Open 1/2” resolution feel reliable even as the user runs searches, opens files, and runs skills in parallel.
- Ensuring everything uses absolute paths, works across platforms, and avoids cluttering caches with irrelevant paths (e.g.
- Tool / model boundaries:
- Keeping the orchestration logic deterministic while still leveraging an LLM for flexible parts (e.g. task formatting for scripts, skill suitability checks).
- Performance and safety:
- Avoiding expensive recursive searches of the entire home directory.
- Bounding generated scripts (length, dependencies, timeouts) so a bad skill definition can’t hang the system.
Accomplishments that we’re proud of
- Unified file-path memory across modalities: Search results, opened files, and now skill output files all flow into a single recent-path cache that downstream UX features consume.
- Real, runnable skills: We can take a high‑level skill description and turn it into a concrete Python program, install its deps, and run it end‑to‑end against a user task.
- Short‑term memory that actually helps: Instead of generic “context windows”, we implemented a targeted, structured short-term memory that directly feeds into intent parsing and path resolution.
- Local‑first design: The system uses the user’s own filesystem and environment and can be inspected, tested, and extended like any other codebase.
What we learned
- Strict interfaces make LLM orchestration tractable: Clear contracts (what a skill script expects as input, what it prints, how it reports paths) are crucial; without them, it’s impossible to reliably compose tools.
- Caching is a UX feature, not just an optimization: Remembering recent paths and search results makes “fuzzy” commands like “Open 1” or “use the last HTML” feel natural.
- Hybrid automation works best: Let deterministic Python handle filesystem, processes, and caching; use the model for judgment calls (skill suitability, format inference, filling in edge cases).
- Small, composable tools beat monoliths: Separating
skills_tools,file_tools,skill_to_python, and the orchestrator made it much easier to iterate on individual behaviors like path caching or skill running.
What’s next for Nova Agent Orchestrator
- Richer skill I/O contracts: Standardized metadata so skills can declare their outputs (types and paths) explicitly, not just via stdout parsing.
- Multi-step, long-running skill workflows: Orchestrating sequences of skills with checkpoints, retries, and user decision points.
- Deeper IDE integration: Tighter hooks into Cursor (or other editors) for things like inline edits, diagnostics, and auto‑generated tests driven by the orchestrator.
- Improved observability: A diagnostic panel/log showing which tools were called, what paths were cached, and how a given answer was produced, to make debugging and trust easier.
Built With
- amazon
- amazon-web-services
- json
- nova
- python
- python-doc
- skills
- tkinter


Log in or sign up for Devpost to join the conversation.