-
-
Home page
-
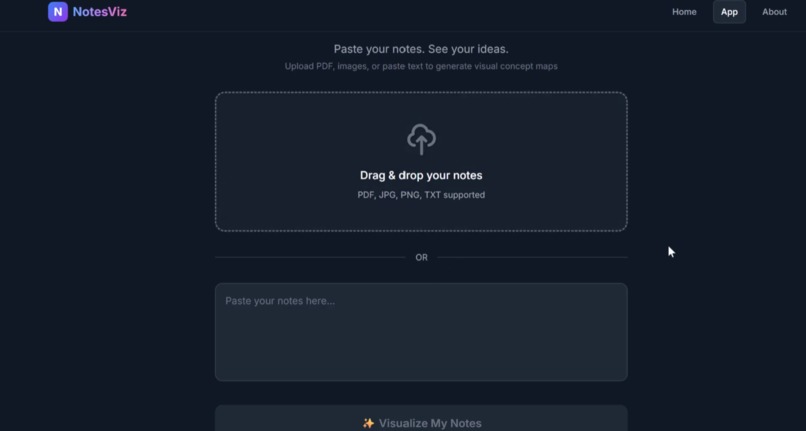
Document insertion / notes page
-
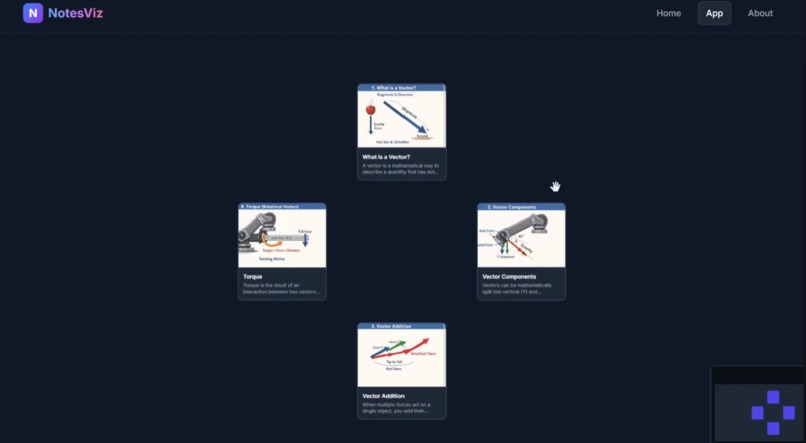
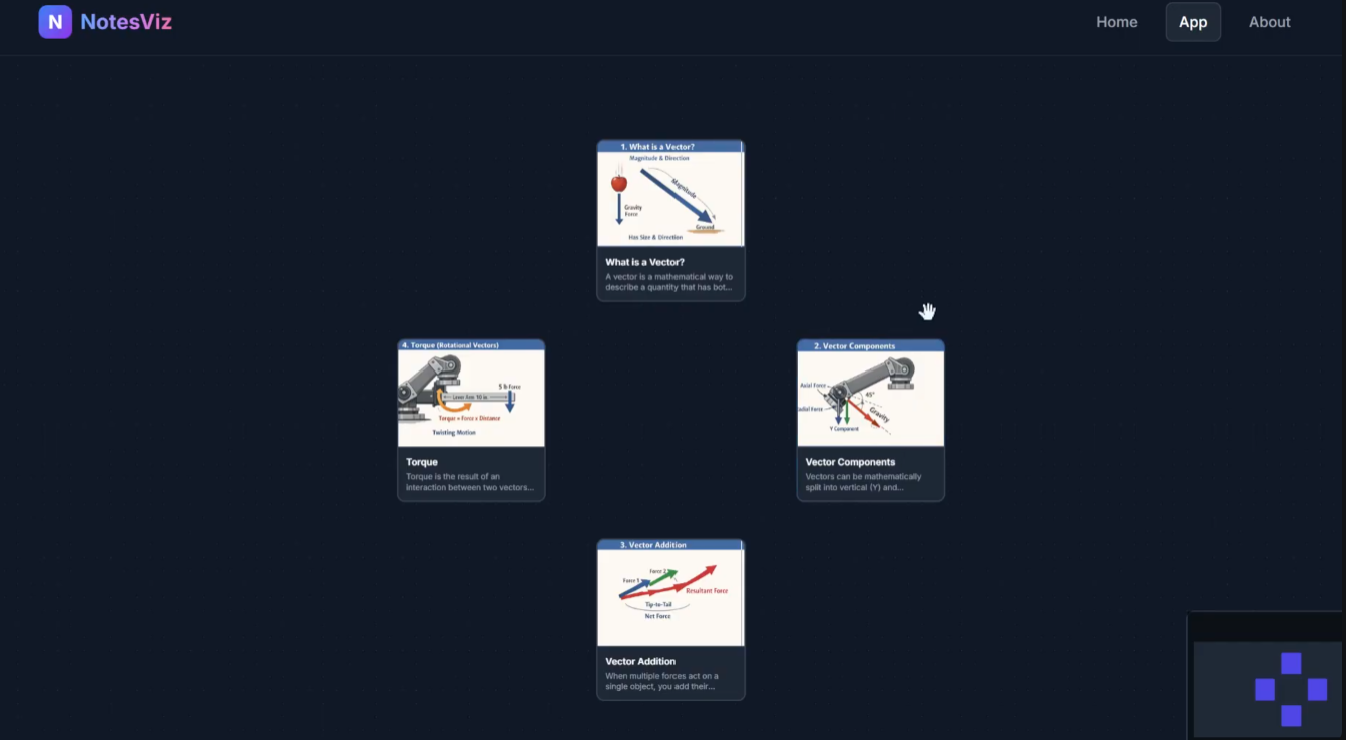
image generation
-
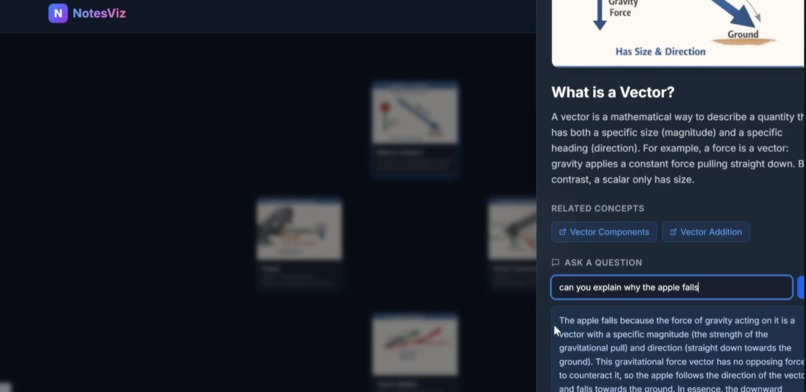
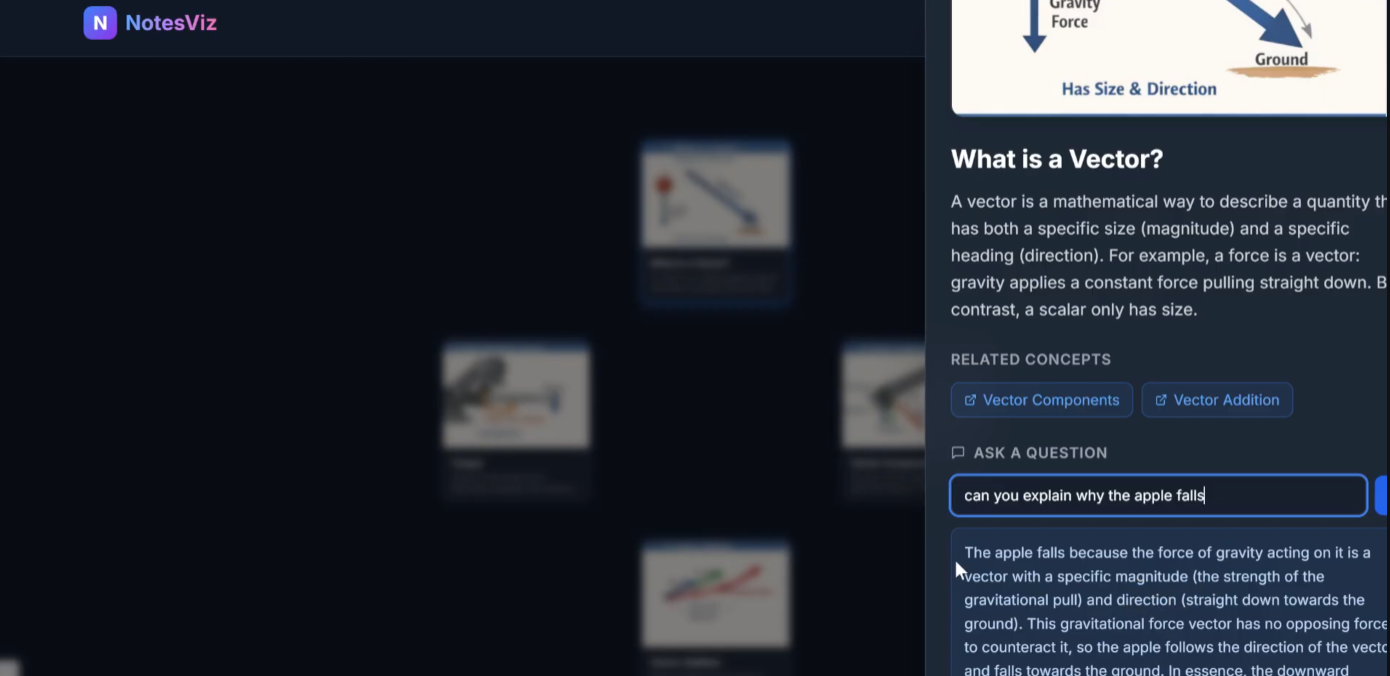
Explanations and live question answering
Inspiration
Reading through dense textbooks, endless text-heavy slides, and messy engineering notes can be overwhelming. Traditional studying forces you to consume information linearly, but human brains learn by association, linking new ideas to existing knowledge. We were inspired to bridge the gap between abstract academic concepts and intuitive visual understanding. We wanted to create a tool that could instantly turn a wall of text or a whiteboard photo into a beautiful, interconnected, and visually stimulating learning environment. We also wanted to include an ai assistant that would be able to teach based on the context of the notes and the drawings.
What it does
NotesViz is an intelligent study platform that automatically transforms unformatted notes, PDFs, or images into fully interactive, AI-generated concept maps. It uses large language models to ingest raw material, pinpoint the core concepts, and determine how they logically relate to one another. Then, instead of just displaying text bubbles, NotesViz prompts a generative AI model to synthesize highly concrete, educational illustrations for every single concept. The result is a dynamic mind map where users can freely drag nodes, explore connections between topics, and use a built-in AI tutor to drill down on confusing material. We implemented a smart follow-up tutoring system using the Groq API. When a student drills down into a specific map node, the backend instantly queries Llama-3.3-70b-versatile using the original parsed notes as strict context. This guarantees hyper-relevant answers that help students grasp confusing topics on the fly without hallucinating outside information.
How we built it
- Frontend: We built the user interface with React and Vite. Using Tailwind CSS and Framer Motion, we made a dark, distraction-free experience. The core interactive mind-map relies heavily on React Flow to render custom image-based nodes, map out edges, and manage complex dragging interactions.
- Backend & AI: Our backend is driven by FastAPI (Python), prioritizing speed and concurrency. We integrated Groq to harness the fast inference of open-weights models (
llama-3.3-70b-versatileand Llama Vision). The backend pipelines the raw text, coerces the LLM into returning strict, structured relationship JSONs, and dynamically generates the visual prompts. - Image Generation: To keep generation near-instant and bypass long queues, we proxy our image prompts directly to Pollinations.ai (using the
fluxmodel) which rapidly renders contextual illustrations on the fly.
Challenges we ran into
- JSON Structure Enforcement: Getting Llama models to perfectly output structured data, without hallucinating markdown blocks, conversational text, or malformed edges, required heavy prompt engineering and backend regex validation.
- Abstract Metaphors vs. Concrete Graphics: Initially, our gen-AI prompts were resulting in confusing, overly-artistic metaphors. We had to heavily refine the prompt injection pipeline to instruct the image model to prioritize "concrete, textbook-like visualizations"
- Asynchronous Workloads & APIs: Designing the backend to smoothly request 10+ image generations and concept extractions at the exact same time without hitting strict rate limits required careful async concurrency management.
Accomplishments that we're proud of
- Achieving start-to-finish generation where a user can drop a messy image of handwritten notes into the system and, within seconds, get a sprawling, fully-interactive graph of beautifully illustrated ideas.
- Eliminating all API latency bottlenecks. By tapping into Groq's high-speed inference and Pollinations' rapid-generation endpoints, the time-to-value for the user is remarkably low.
- Designing a polished, premium aesthetic that rivals enterprise software using only a team of four over the course of a single hackathon.
What we learned
- The power (and sheer complexity) of multimodal AI pipelining. Chaining OCR-vision transcriptions into text summarization, into JSON structured extraction, into generative visual prompts showed us just how powerful modern LLMs are when strung together cleanly.
- Managing sprawling interactive graph states with React Flow and mapping dynamically generated nodes and edges on the fly.
- Crafting system prompts that reliably bypass verbose explanations in favor of pure, machine-readable data structures.
What's next for NotesViz
- Multiplayer Collaboration: Allowing students to join the same canvas, share notes, and build upon a shared class "mind-map" in real-time.
- Export & Integrations: Implementing workflows to easily export the generated React Flow canvas directly to PDF, Notion, or interactive Anki flashcards.
- Customization and Iteration: Providing users the ability to regenerate a specific node's image or prompt until it perfectly clicks for their unique learning style.
Built With
- fastapi
- framermotion
- groqapi
- lucidereact
- metallama3
- pollinations.ai
- pymupdf
- python
- react.js
- reactflow
- reactrouter
- tailwind
- uvicorn
- vite

Log in or sign up for Devpost to join the conversation.