-
-

Stage 5
-
Our solution part 1
-

The actual problem
-
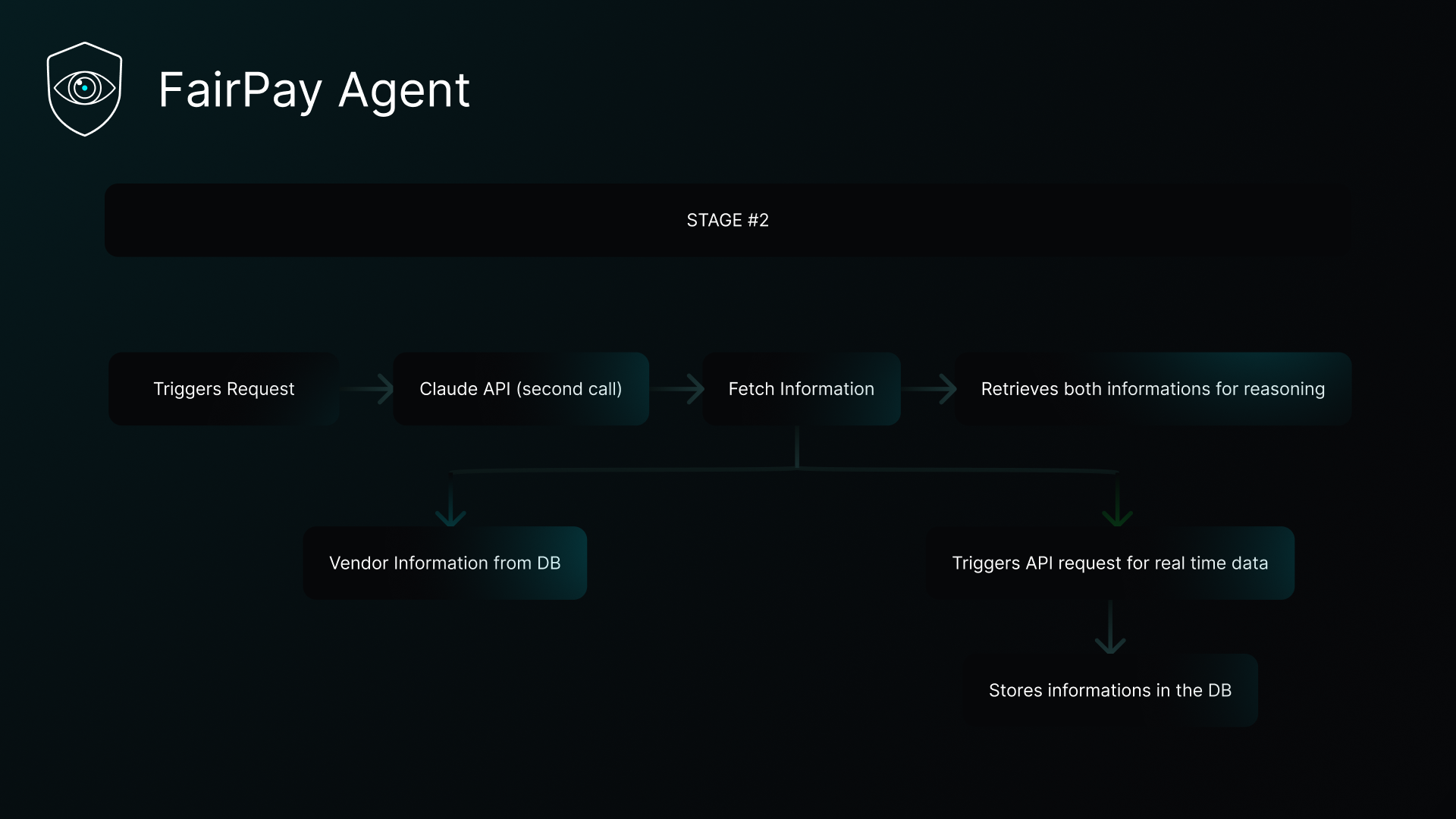
Stage 2
-

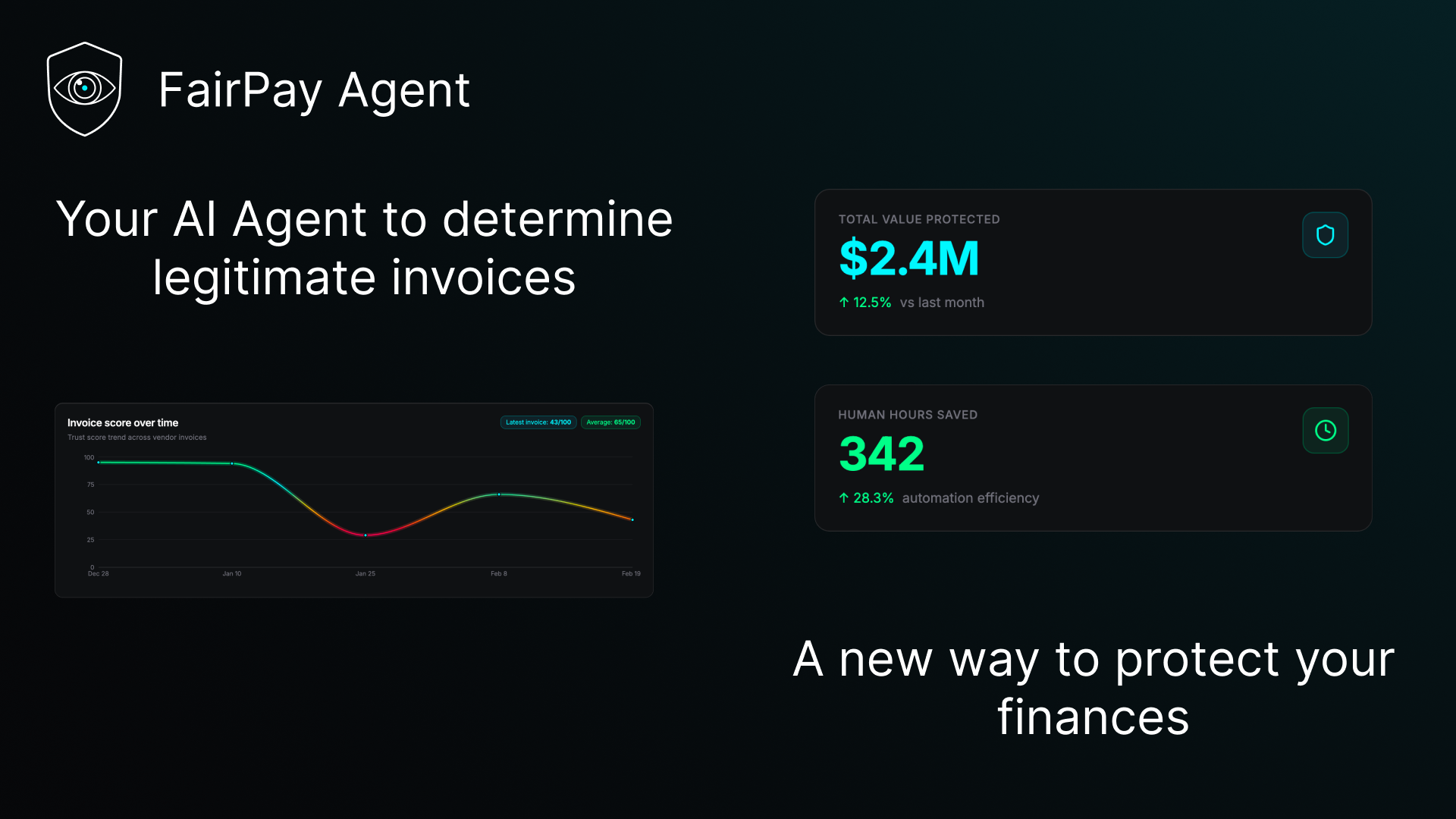
Catch slide
-
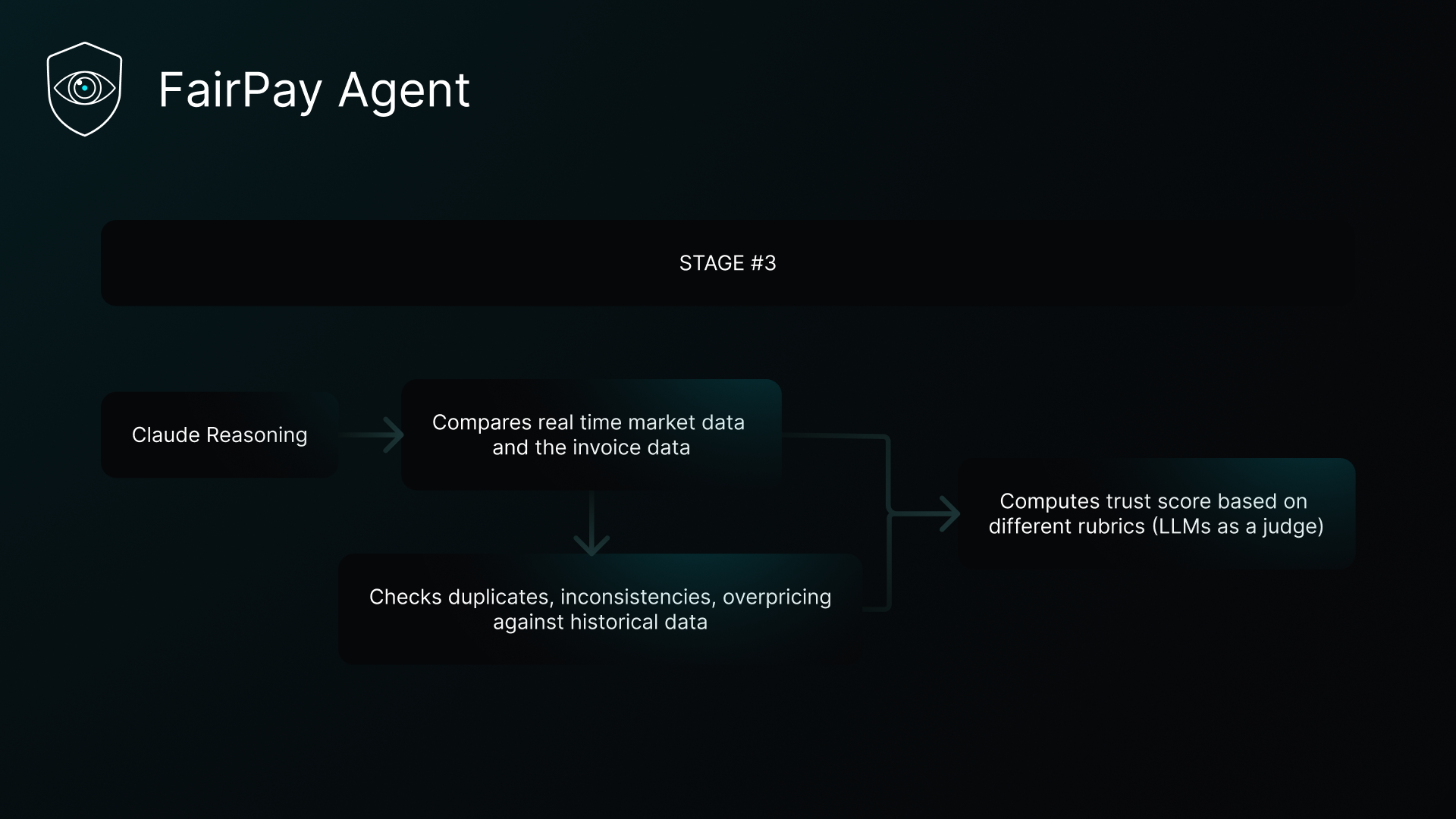
Stage 3
-
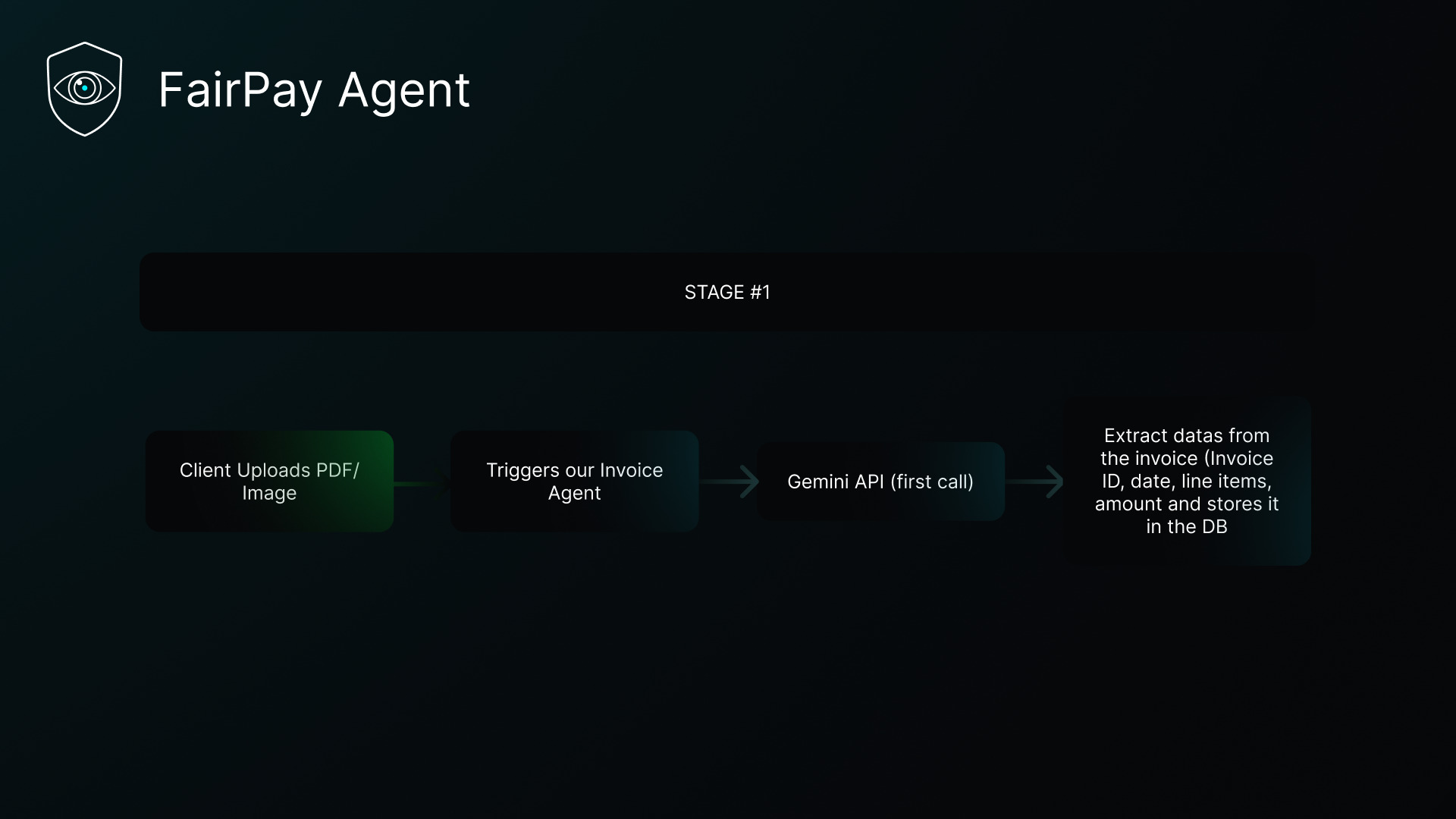
Stage 1
-
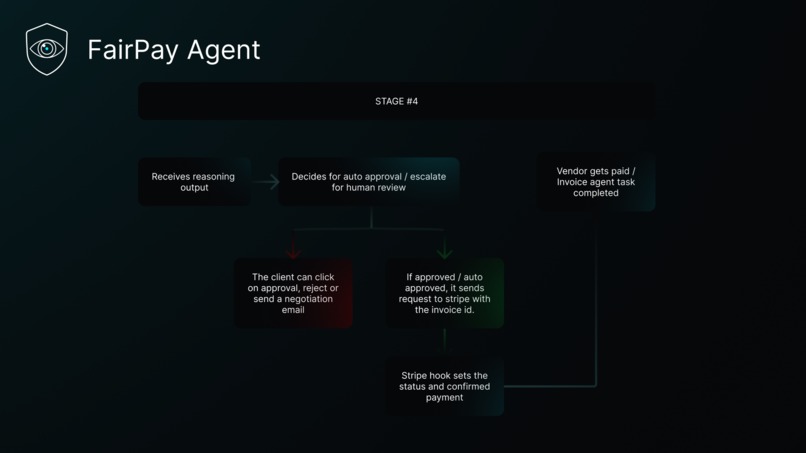
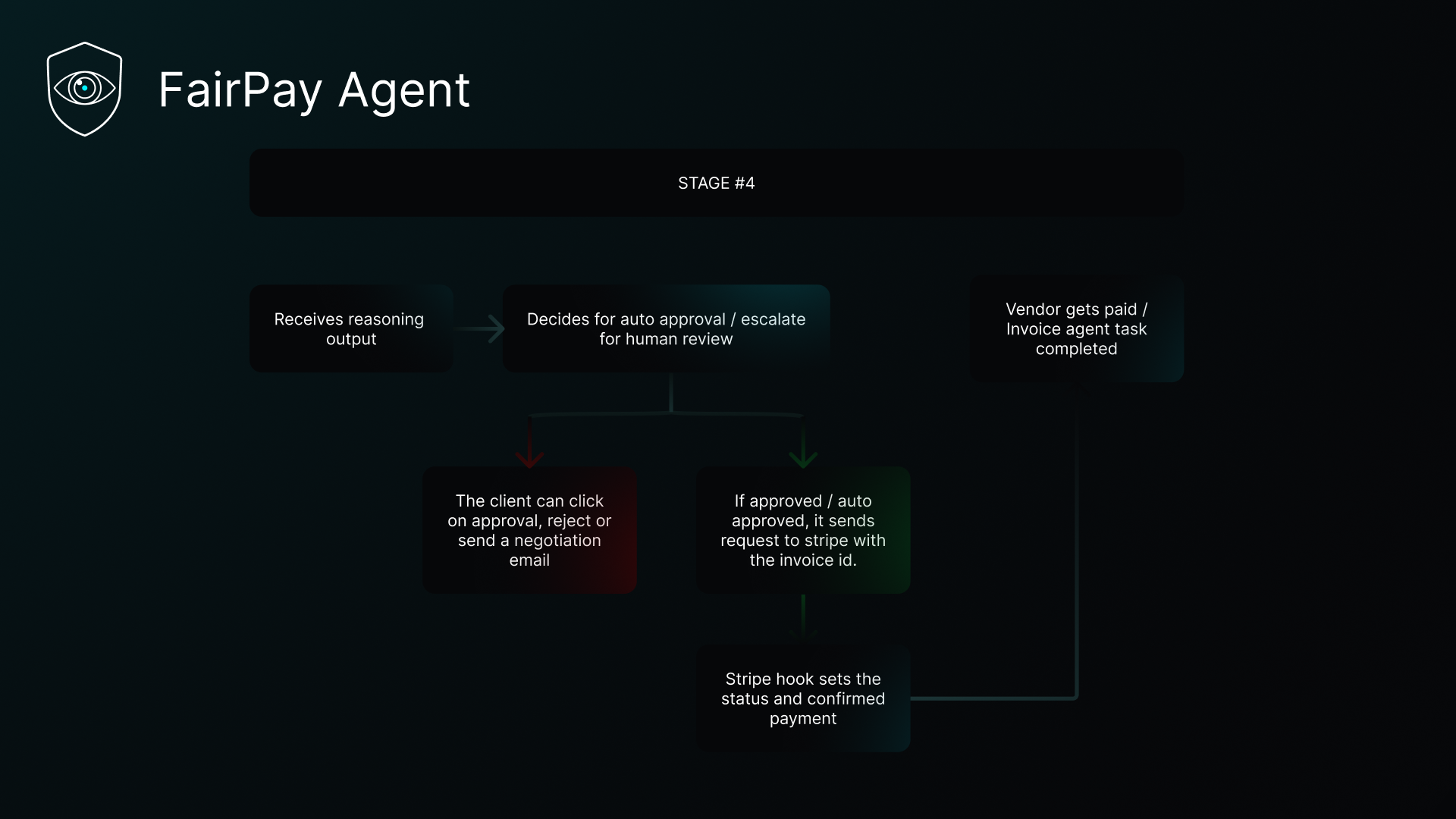
Stage 4
-

Data usage and collection
-

Our track and challenges
-

Our solution part 2






Inspiration
Finance teams at B2B companies process hundreds of vendor invoices every month — and a disproportionate share of them are wrong. Cloud infrastructure bills from AWS, Azure, and GCP are some of the worst offenders: line items referencing opaque SKUs, prices that quietly drift upward between billing cycles, and occasionally an invoice submitted twice with a different date. Most accounts-payable teams catch these errors through experience and gut feeling, not systematic verification.
We wanted to build the tool that should already exist: a system that reads every invoice the moment it arrives, benchmarks every line item against live market prices, checks it against the vendor's own billing history, and produces a verifiable trust score — before a human ever looks at it. Not a vibe check from an LLM. An auditable, criterion-by-criterion verdict.
What We Built
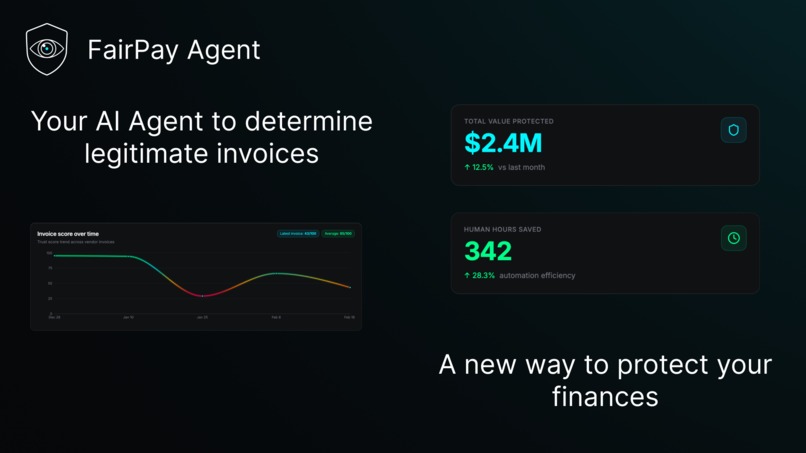
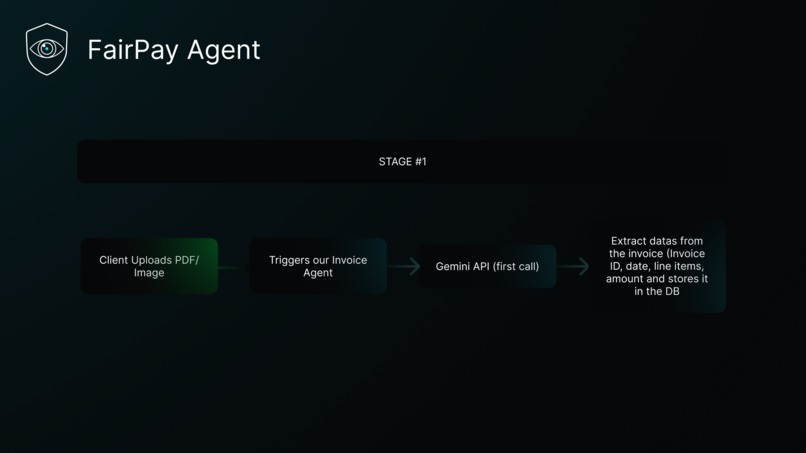
FairPay Agent is an autonomous invoice anomaly detection platform. You upload a PDF or image invoice; within seconds you get:
- Structured extraction of every field and line item
- A 0–100 confidence score computed from four weighted criteria
- A routed decision: APPROVED, HUMAN_REVIEW, or ESCALATE_NEGOTIATION
- A forensic narrative written by Claude explaining exactly what it found
- If escalated: a ready-to-send vendor renegotiation email drafted by Claude
Approved invoices trigger a Stripe payment automatically. Suspicious ones land in a review queue. The entire pipeline is observable via a Paid.ai wrapper that tracks per-invoice AI cost and estimated savings.
How We Built It
Dual-LLM Architecture
We separated the two jobs an LLM needs to do here and assigned each to the model best suited for it:
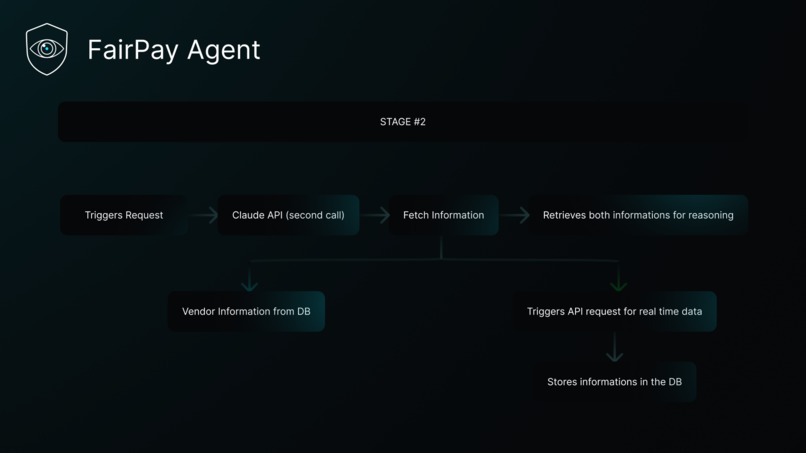
- Gemini handles extraction — it ingests the raw PDF or image with response_json_schema forcing a typed InvoiceExtraction output. Multimodal, fast, structured.
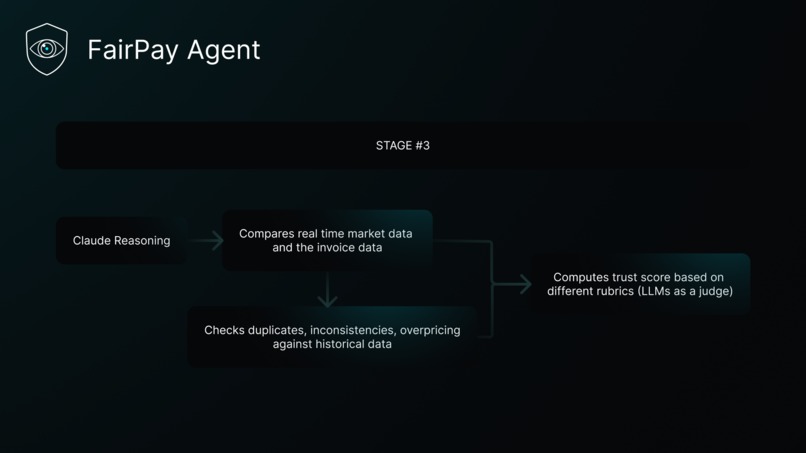
- Claude Sonnet 4.6 handles reasoning — it receives pre-computed signals (not raw numbers) and writes a forensic analysis, then drafts negotiation emails when needed.
This separation is deliberate. LLMs are poor calculators. Every percentage deviation, every drift metric, every duplicate check is computed in Python before Claude sees it. Claude reasons over facts, not raw data.
The Signals Layer
After extraction, a pure-Python signals engine computes four signal types from the invoice and database context:
- DUPLICATE_INVOICE — hash-based check against prior invoice IDs and amounts
- CONSISTENCY_CHECK — plausibility check of every extracted information
- MARKET_DEVIATION — per-line-item comparison against the live CloudPricing catalogue (AWS/Azure/GCP)
- HISTORICAL_DEVIATION — per-line-item comparison against the same vendor's past invoices
- VENDOR_TOTAL_DRIFT — invoice-level drift of the vendor's total billing over time
Each signal produces a human-readable statement string that is passed verbatim to Claude.
Rubric-Based Confidence Scoring
Rather than asking an LLM "how suspicious is this invoice?", we implement a structured rubric — inspired by recent research on https://arxiv.org/abs/2501.00274. Four criteria with fixed weights summing to 100:
┌──────────────────────────────┬────────┐ │ Criterion │ Weight │ ├──────────────────────────────┼────────┤ │ Formal Validity │ 20 pts │ ├──────────────────────────────┼────────┤ │ Market Price Alignment │ 27 pts │ ├──────────────────────────────┼────────┤ │ Historical Price Consistency │ 27 pts │ ├──────────────────────────────┼────────┤ │ Vendor Total Drift │ 26 pts │ └──────────────────────────────┴────────┘
The score formula adjusts for missing data. When no prior invoices or no market price match exist for a criterion, that criterion is excluded from the denominator:
$$\text{score} = \frac{\displaystyle\sum_{c ,\in, \mathcal{C}{\text{avail}}} w_c \cdot v_c}{\displaystyle\sum{c ,\in, \mathcal{C}_{\text{avail}}} w_c} \times 100$$
where $\mathcal{C}_{\text{avail}}$ is the subset of criteria with available data, $w_c$ the criterion weight, and $v_c \in [0, 1]$ the normalized verdict.
Deterministic Routing
No LLM touches the routing decision. Pure Python:
$$\text{decision} = \begin{cases} \texttt{ESCALATE} & \text{if } is_duplicate \ \texttt{HUMAN_REVIEW} & \text{if } formal_failed \ \texttt{APPROVED} & \text{if } score \geq 80 \ \texttt{ESCALATE} & \text{if } score < 40 \ \texttt{HUMAN_REVIEW} & \text{otherwise} \end{cases}$$
The Full Stack
The backend is a clean layered FastAPI app (Routers → Services → Repositories → SQLAlchemy models) with a 12-step inline pipeline wired to a PostgreSQL 15 database. The frontend is React 18 + TypeScript + Tailwind. Cloud pricing data is scraped from AWS, Azure, and GCP APIs via Playwright and normalised into a unified cloud_pricing catalogue with upsert-on-conflict deduplication. Payments flow through Stripe webhooks that close the loop by marking the invoice as paid. AI cost and value attribution are tracked in real time via the Paid.ai wrapper.
Challenges
Keeping math out of the LLM. Our first instinct was to hand Claude the raw numbers and let it reason. The outputs were inconsistent and sometimes factually wrong on basic arithmetic. The breakthrough was computing every signal deterministically in Python first, then giving Claude only human-readable statements like "EC2 t3.medium billed at $0.052/hr — 34% above the current AWS list price of $0.038/hr." Claude's analysis quality improved dramatically, and the score became fully auditable.
Rubric design. Deciding which criteria to include, how to weight them, and how to handle missing data (no historical invoices for a new vendor, no CloudPricing match for a niche SKU) required several iterations. The "scale to available evidence" approach — excluding missing-data criteria from the denominator — prevents the score from collapsing to zero just because a vendor is new.
Real-time pricing normalisation. AWS, Azure, and GCP each expose pricing in completely different schemas. Building a unified CloudPricing model that could hold records from all three, deduplicate on upsert, and be queried efficiently against arbitrary line-item descriptions was non-trivial. We ended up with a keyword-matching approach against the SKU description field.
Structured LLM output. Getting both models to reliably return typed, validated objects — especially Claude with nested AnomalyFlag lists inside InvoiceAnalysis — required careful prompt engineering and using tool-use JSON schema constraints rather than free-form text generation.
Building end-to-end in a hackathon. Five independent moving parts (backend, frontend, processing layer, data sourcing, payments) that all need to work together, under time pressure, meant constant interface negotiation. We enforced strict Pydantic schemas at every boundary so components could be developed in parallel without breaking each other.
What We Learned
- Rubric-as-a-judge is genuinely powerful. Replacing a single "score this 1–10" prompt with a structured, criterion-by-criterion evaluation produces far more consistent and explainable results — and makes it trivial to identify why an invoice scored badly.
- The right LLM for the right job matters. Gemini's native multimodal document understanding made extraction reliable in a way that prompt-engineering a text-only model would not. Claude's reasoning quality on signal-based forensic analysis is where it earns its place.
- Determinism is a feature. Every stakeholder we described this to asked the same question: "But can you explain why it flagged this invoice?" Because routing is pure Python and scoring is formula-based, the answer is always yes. That explainability is what makes automation trustworthy in a financial context.
- Paid.ai gives you a completely different relationship with AI cost. Seeing per-invoice LLM cost next to estimated overcharge savings makes the ROI of the pipeline immediate and concrete.
Built With
- css3
- fastapi
- gemini
- google-cloud
- google-generativeai
- next.js
- postgresql
- python
- react
- requests
- sqlalchemy
- tailwind
- typescript
- vite

Log in or sign up for Devpost to join the conversation.