-
-
HomePage
-
Decide on Conversation
-
Voiced Interview w/ Transcript
-
Chat Interview
-
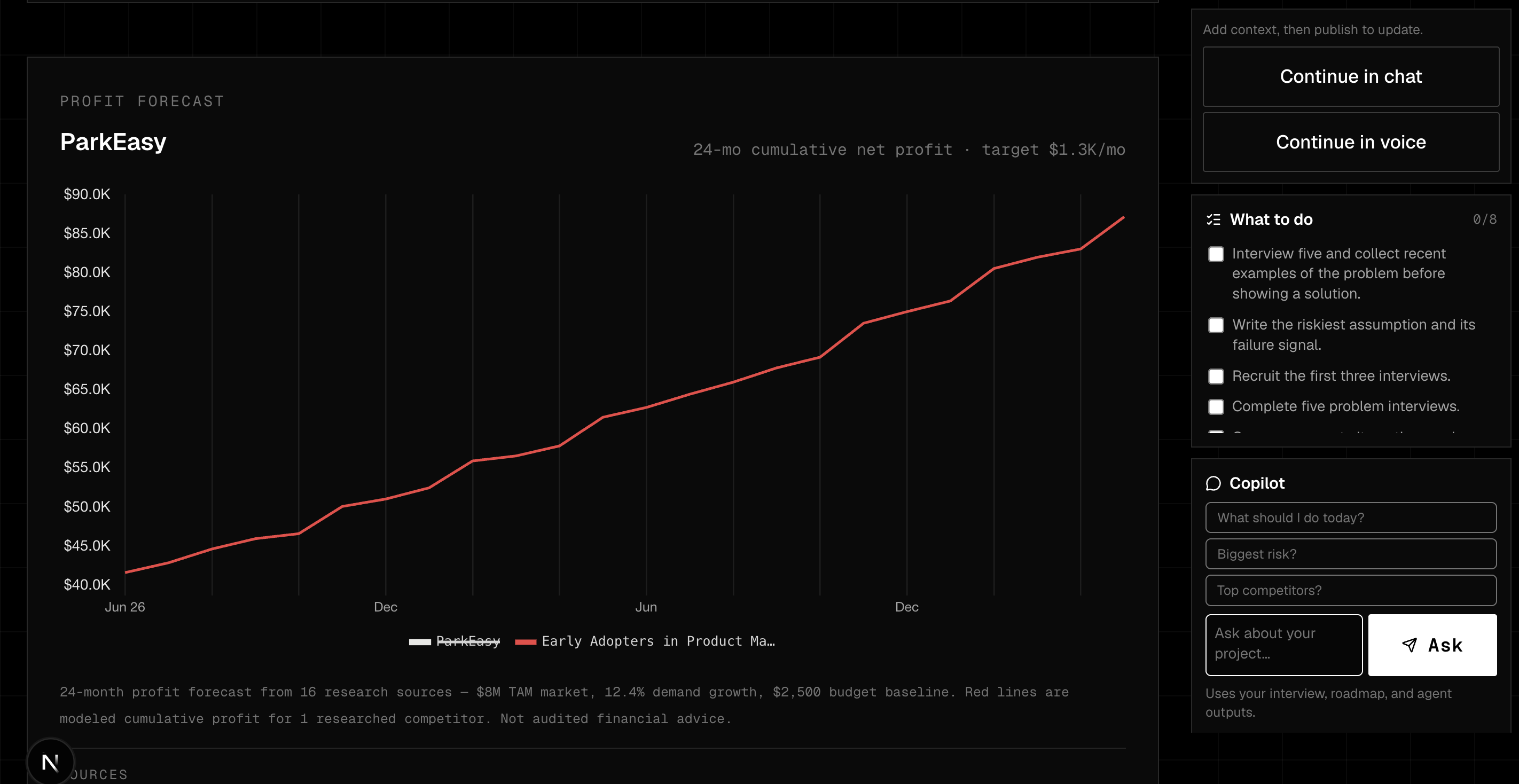
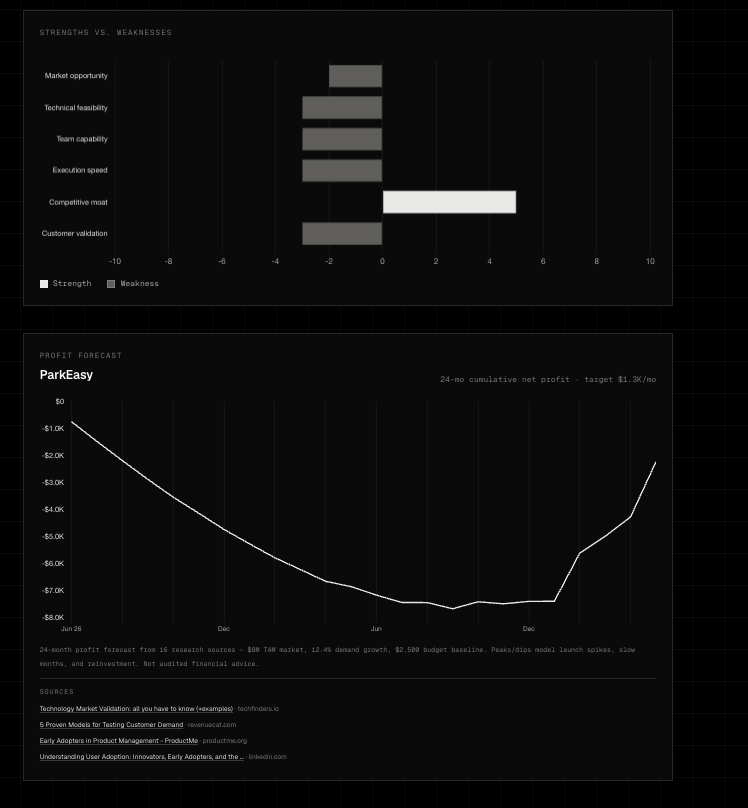
Post Interview - Stats summary, Step-by-step blueprint, Strengths vs. Weaknesses Chart
-
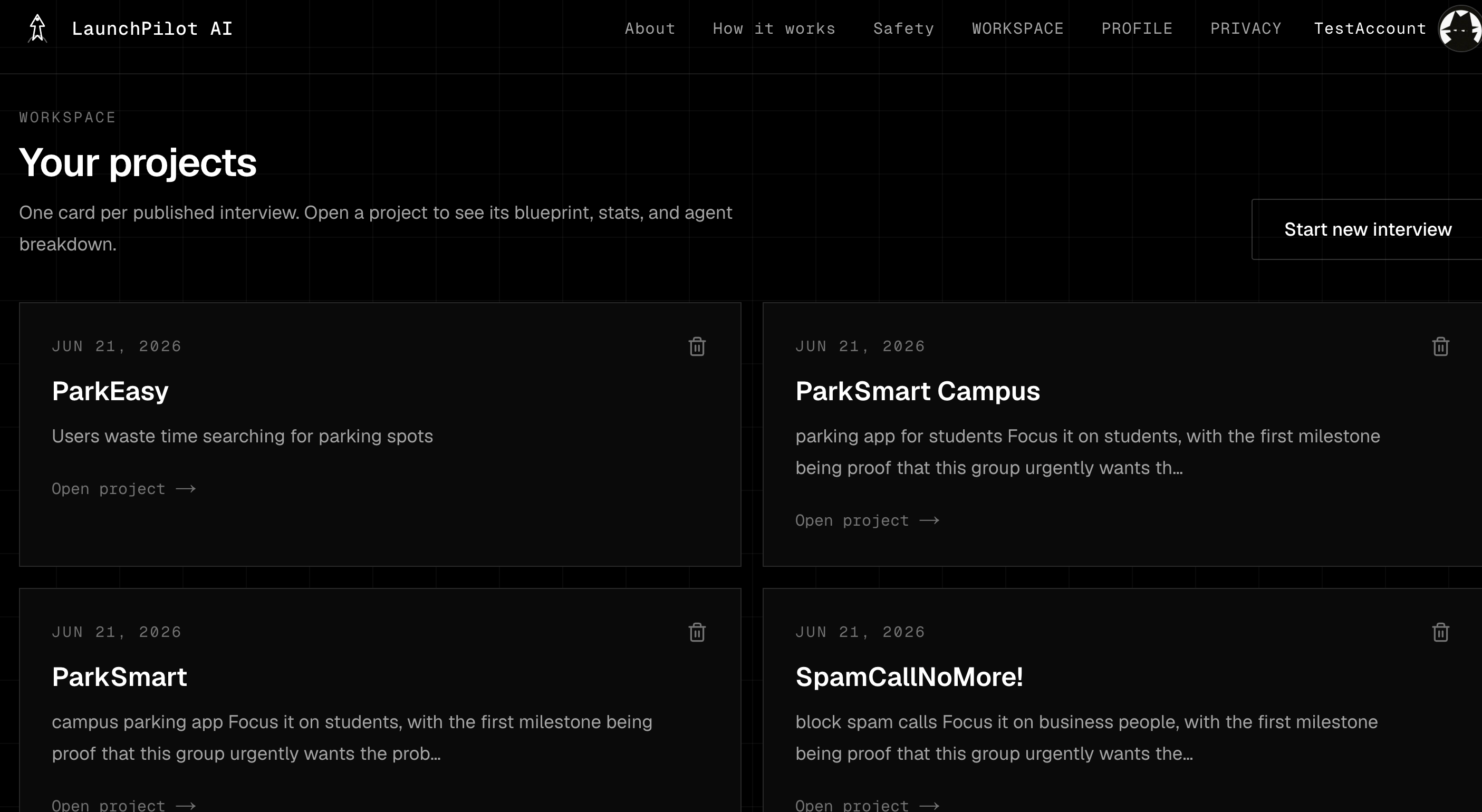
Workspaces - Past Projects!
-
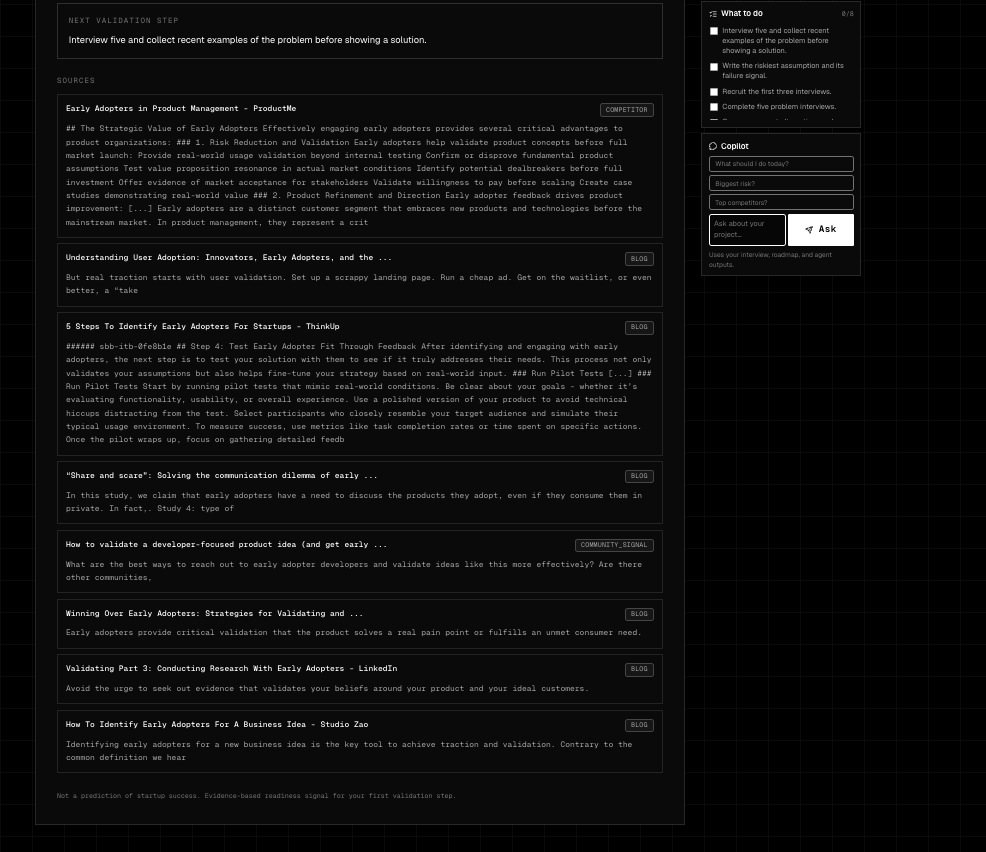
Evidence Based Research - Sites and Citations
-
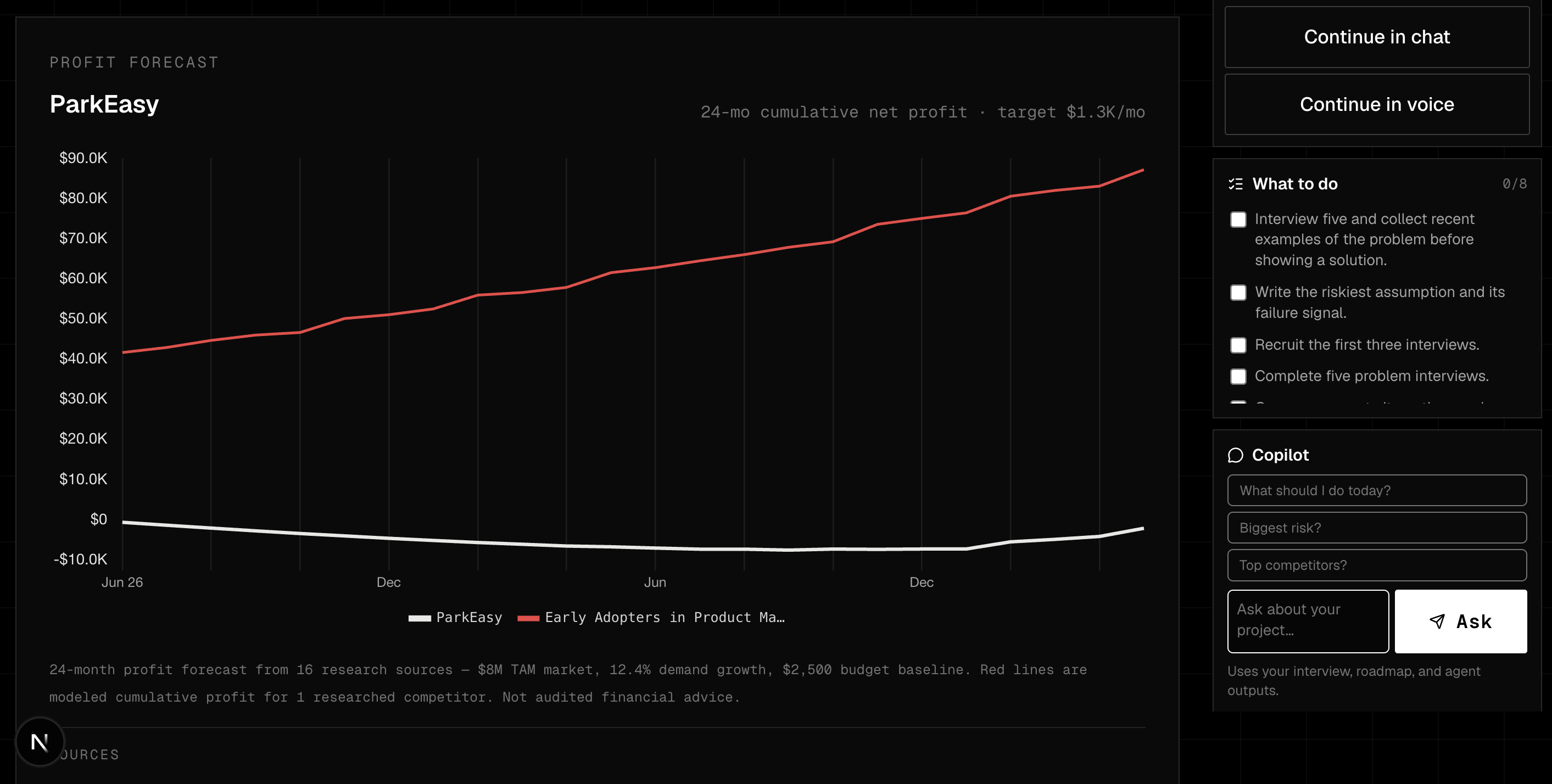
User vs Competitor Comparisons
-
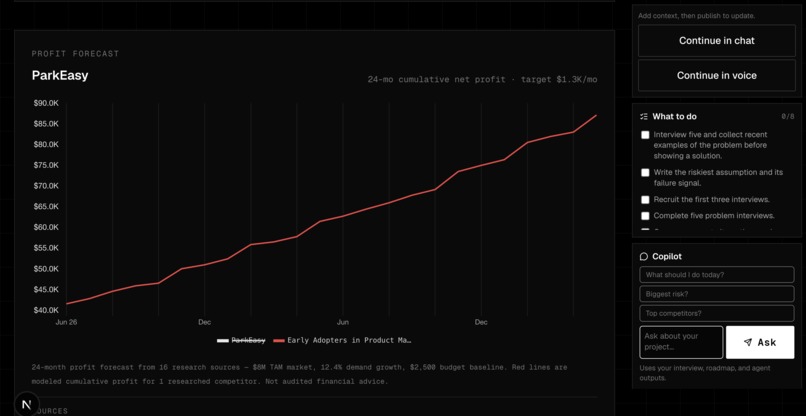
Competitor Charts
-
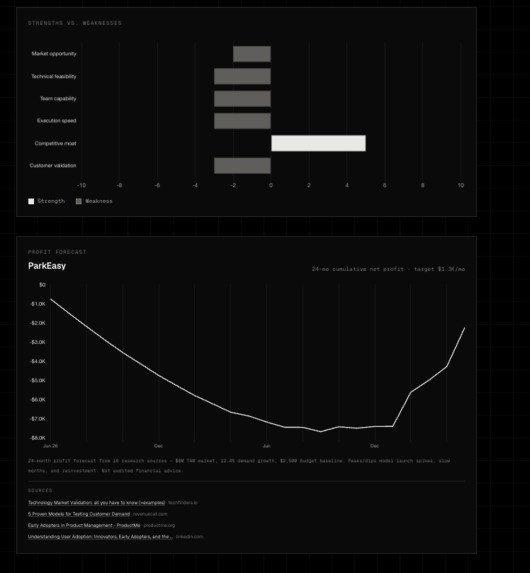
Project Charts
-
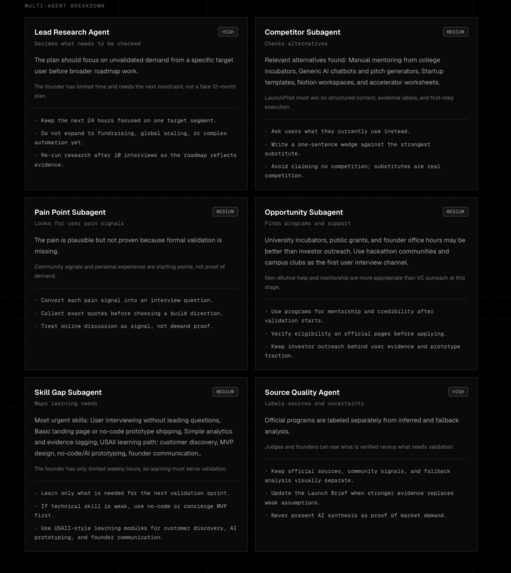
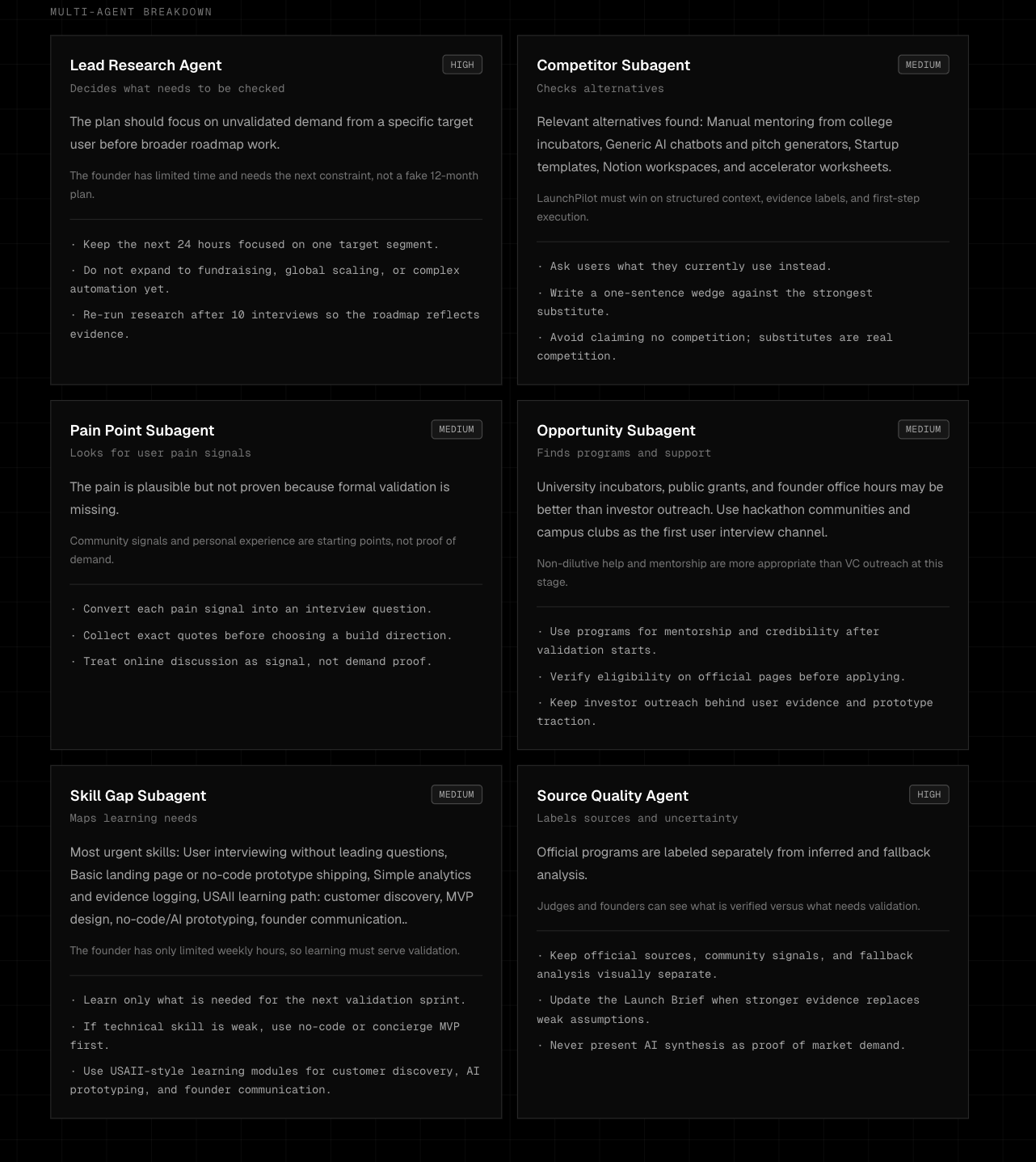
Multi-Agents Project Breakdown
-
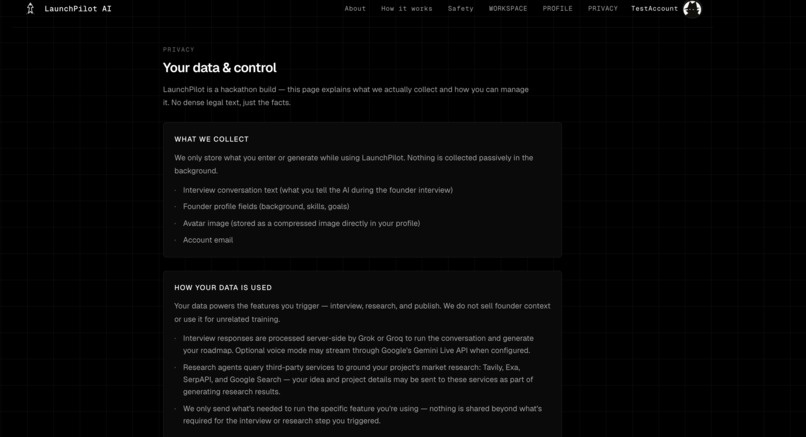
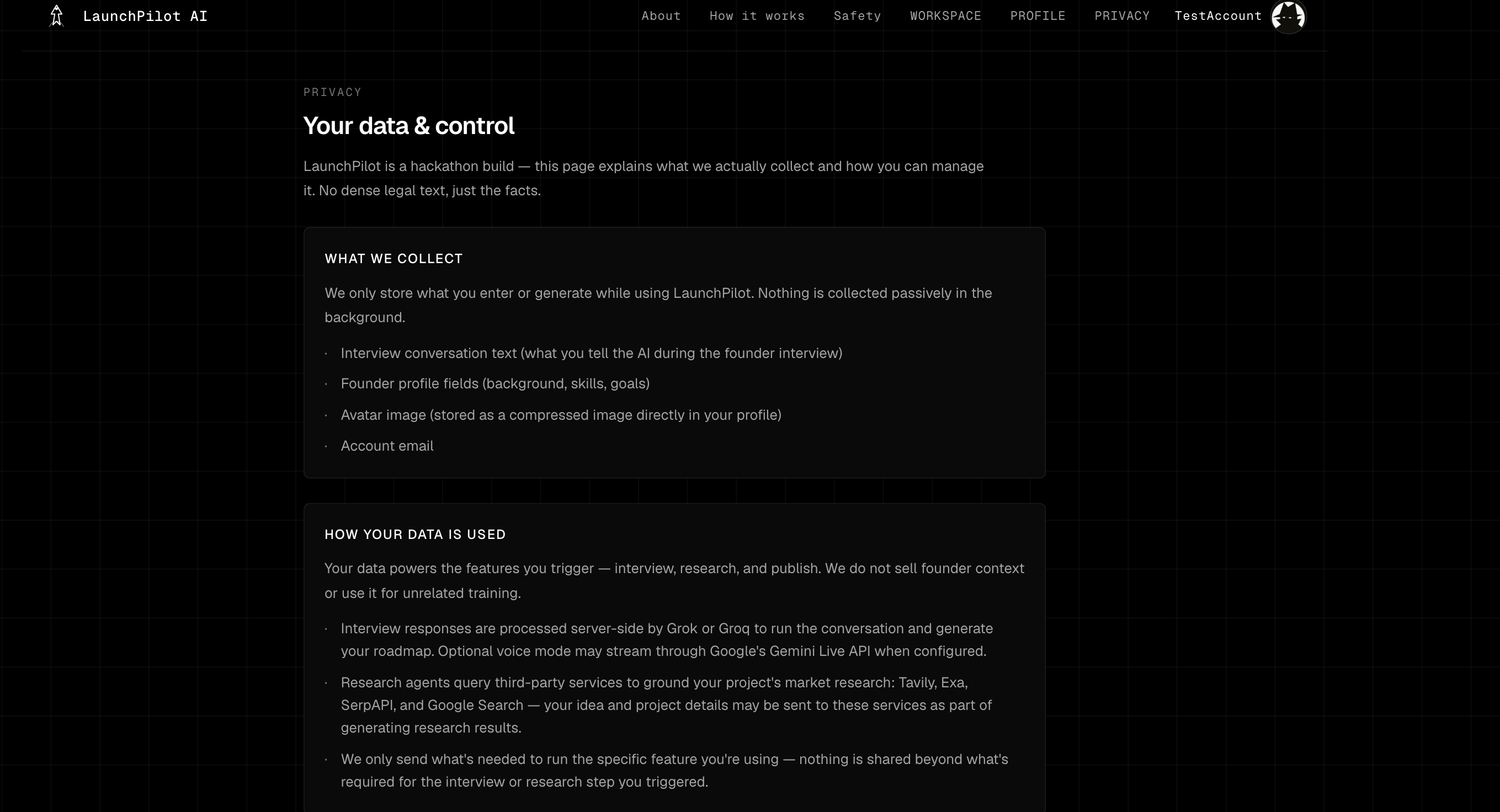
Responsible AI
-
Safety and Concerns

About LaunchPilot AI
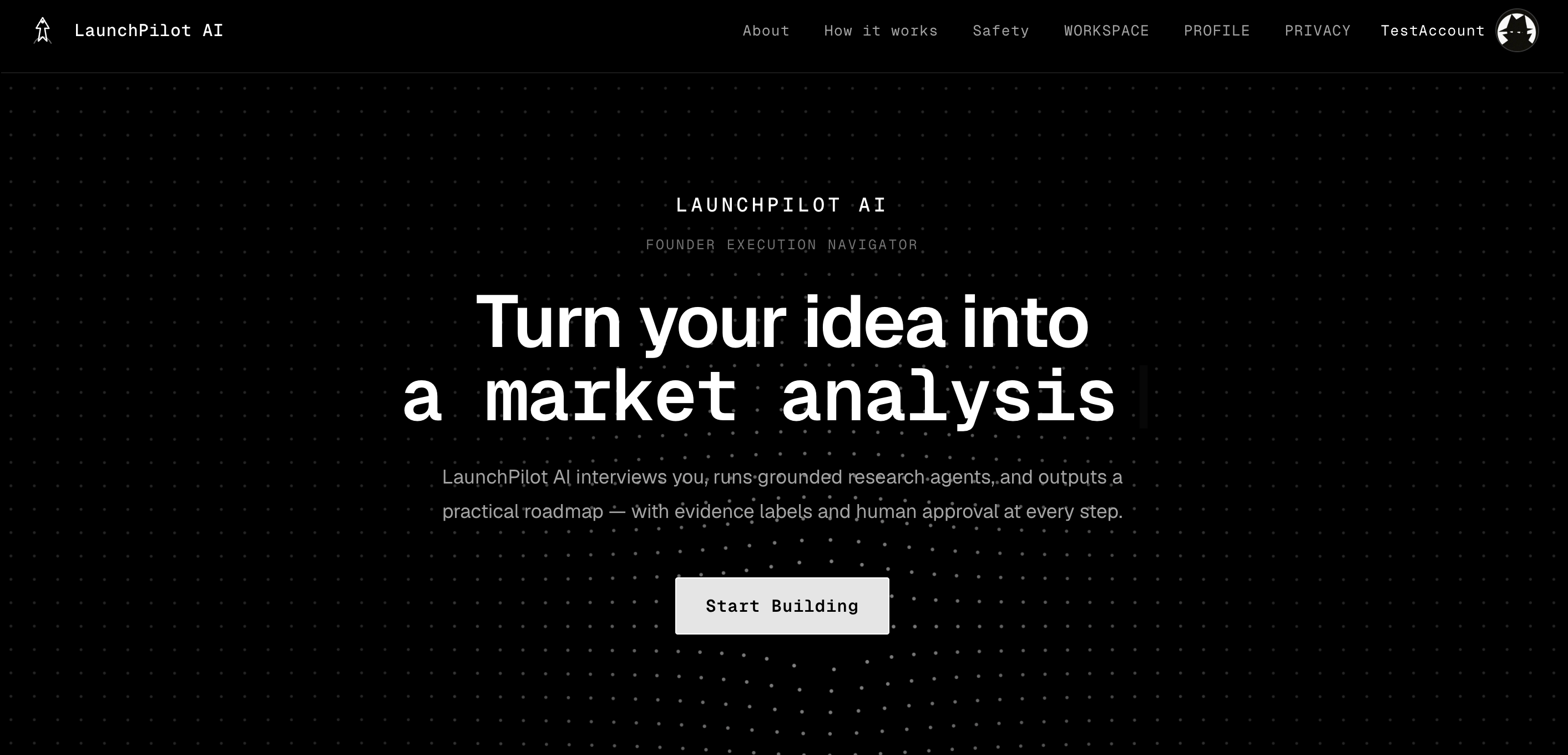
LaunchPilot AI is an evidence-grounded execution workspace for student and first-time founders. It turns a vague startup idea into a realistic first plan: who to validate with, what assumption could break the idea, what not to build yet, and what the founder should do in the next 24 hours, 7 days, 30 days, and 90 days.
Most founder tools generate more tasks. LaunchPilot does something harder: it helps a founder decide which task is worth doing first.
Early founders rarely fail because they lack ideas. They fail because they build too early, trust weak signals, copy competitor lists, or mistake polished AI output for proof. LaunchPilot was built to slow that moment down just enough to ask:
What do we actually know? What is still unproven? What is the smallest test that creates real learning?
What it does
At a glance
Input: A founder’s messy idea, target user, problem, constraints, evidence, budget, skills, and goals.
AI process: Conversational intake, live retrieval, source classification, evidence scoring, multi-agent reasoning, and LLM synthesis.
Output: A Launch Brief with risks, MVP scope, roadmap, source ledger, Copilot, exports, and the first real validation step.
Human role: The founder approves the direction. LaunchPilot advises, but never decides whether the idea should be pursued.
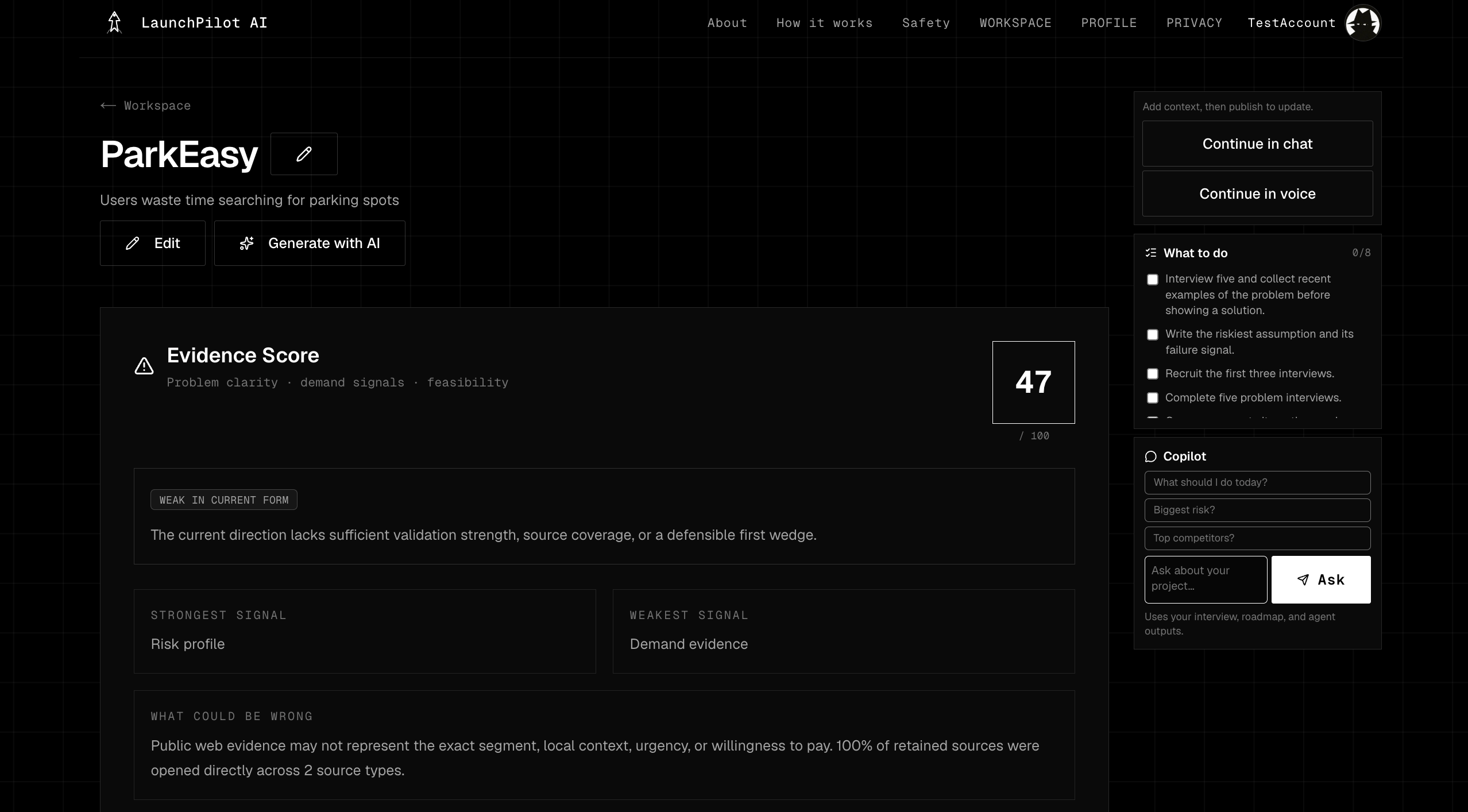
LaunchPilot guides a founder through a structured interview and converts messy answers into an evidence-labeled Launch Brief.
Workflow: Interview → Validation → Live Research → Six-Agent Analysis → Launch Brief → Copilot → Export
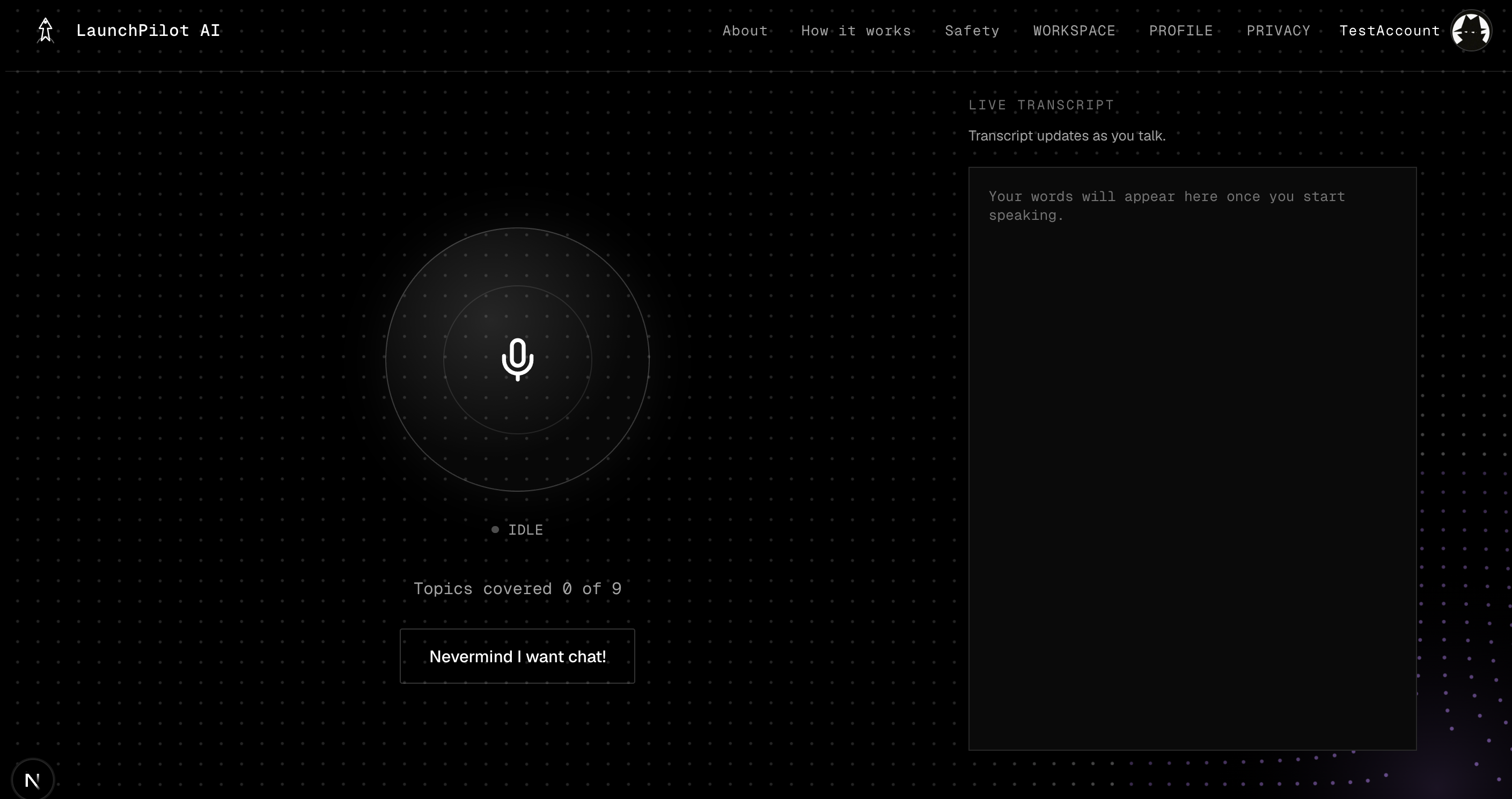
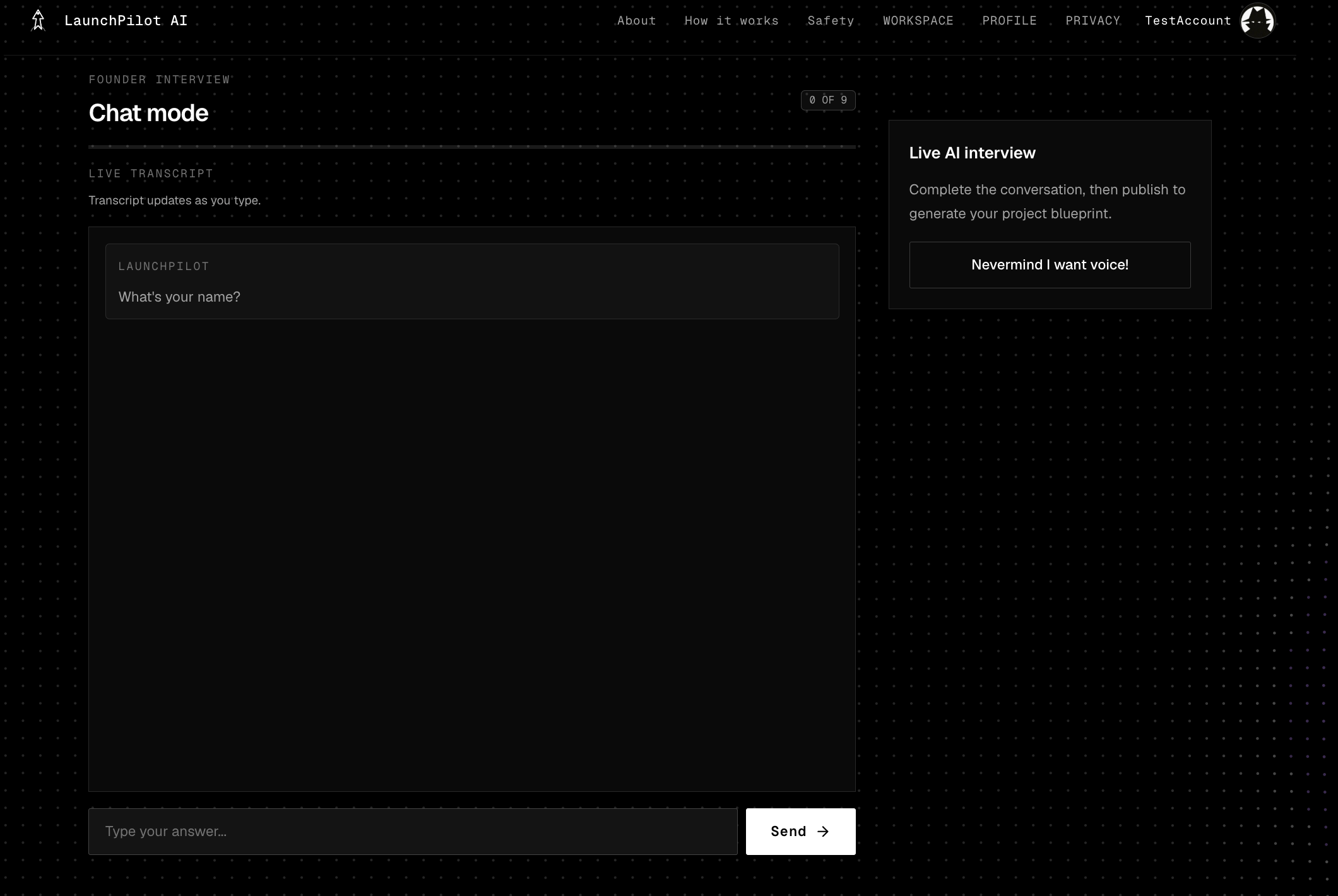
The founder provides their idea, target user, problem, constraints, skills, budget, current evidence, and willingness to pivot. LaunchPilot then:
- cleans the idea into a focused venture brief,
- scores evidence readiness across key dimensions,
- identifies the riskiest assumptions,
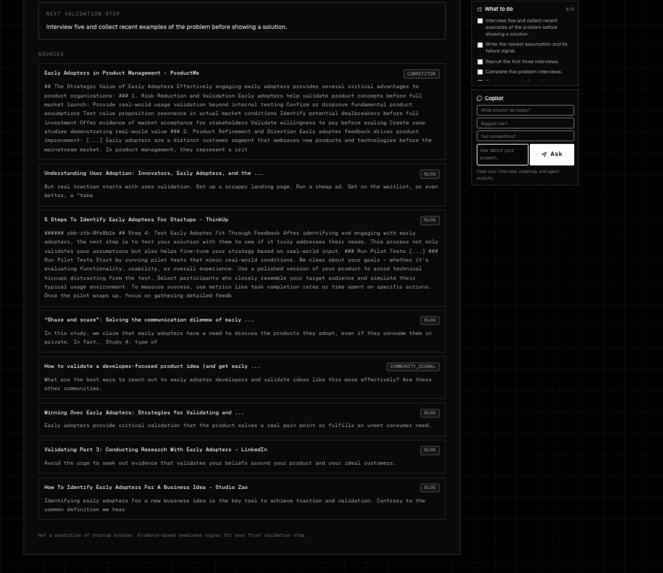
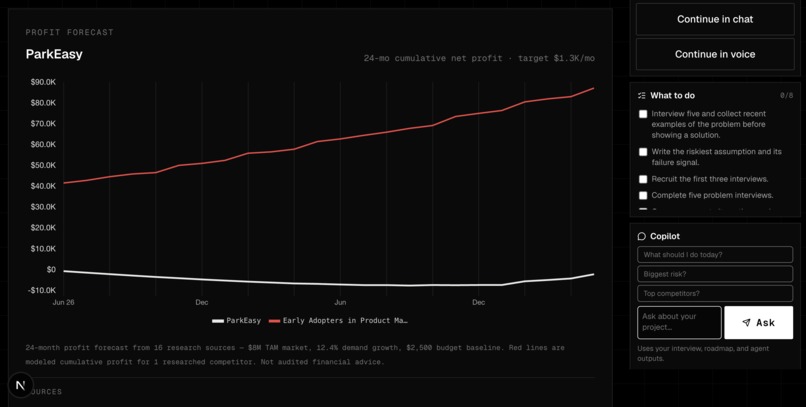
- runs live market research,
- separates direct competitors from adjacent alternatives,
- labels sources with confidence and limitations,
- recommends the smallest credible MVP or manual pilot,
- creates a bottleneck-first execution roadmap,
- and gives the founder a contextual Copilot for follow-up decisions.
The output is not a generic business plan. It is a practical execution brief that tells the founder what to test, what to avoid building yet, and what evidence would change the decision.
The AI system
LaunchPilot combines multiple AI capabilities instead of relying on one generic chatbot response.
Conversational intake captures founder context through chat and optional voice. Retrieval-augmented research gathers public evidence from live web providers. Source classification separates competitors, communities, product pages, reports, and weak signals. Evidence scoring measures readiness to test, not probability of success. Multi-agent reasoning turns research into founder decisions. LLM synthesis produces the final Launch Brief and contextual Copilot answers.
The six agents each answer a different founder-critical question:
- Market Reality Agent — what are users already doing?
- Assumption & Risk Agent — what could invalidate this?
- MVP Scope Agent — what is the smallest testable workflow?
- Roadmap Agent — what should happen first?
- Opportunity Agent — what support paths are relevant without overstating eligibility?
- Pitch & Communication Agent — how can the founder explain the idea without claiming fake traction?
This makes LaunchPilot more than a planner. It is a structured reasoning system for early-stage execution.
How we built it
LaunchPilot is a full-stack web app built with Next.js, React, TypeScript, Tailwind CSS, Firebase Authentication, Prisma, SQLite, Vercel Blob, and Vercel.
The production system supports authenticated multi-project workspaces, refresh-safe dashboards, saved research runs, Markdown/JSON exports, and a project-aware Copilot. Firebase Authentication handles Google and email/password sign-in. Local development uses Prisma with SQLite, while production persistence uses Vercel Blob for serverless project state, validated briefs, research outputs, dashboards, and exports.
The AI and research layer uses Google Gemini API, Gemini Live API, Google Search Grounding, Tavily, Exa, SerpAPI, xAI Grok, Groq Llama, and evidence-aware deterministic fallbacks where configured. This provider-aware design keeps the workflow usable even when an external model or search provider fails.
The UI is intentionally dark, structured, and workspace-like. It is designed to feel less like a form and more like a founder cockpit: evidence score, bottleneck, roadmap, risks, source ledger, agents, Copilot, and exports all in one place.
What makes it different
LaunchPilot does not say, “Your idea will succeed.”
It says:
- here is your strongest signal,
- here is your weakest evidence,
- here is the assumption most likely to break the idea,
- here is what not to build yet,
- here is the smallest pilot worth running,
- and here is the first real action you should take.
That distinction matters. A confident AI-generated plan can be dangerous if the evidence is weak. LaunchPilot is built around uncertainty, not around hiding it.
Responsible AI by design
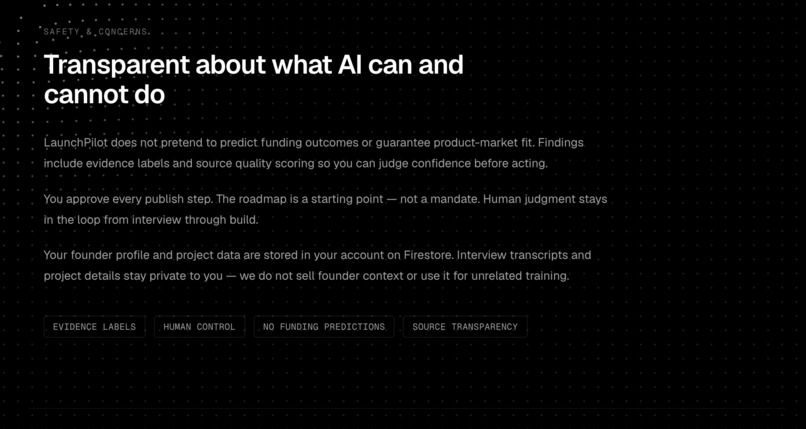
The main risk is false confidence: a founder treating polished AI output as proof that an idea will work.
LaunchPilot reduces that risk through product design:
- no “success probability,”
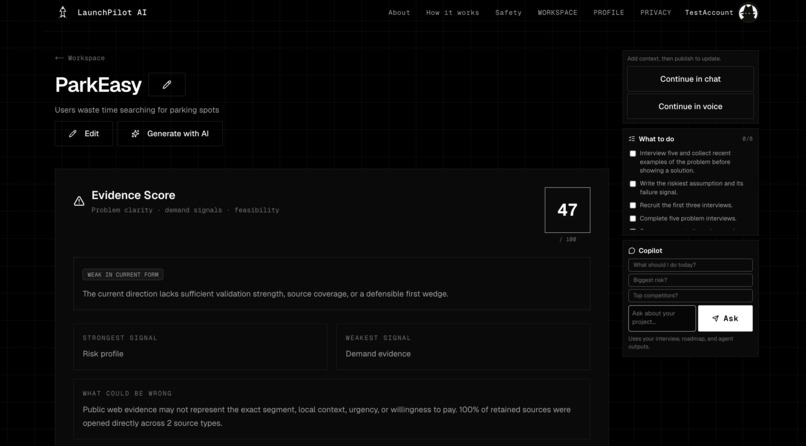
- Evidence Score framed as readiness to test,
- source ledger for retained evidence,
- confidence labels and limitation notes,
- separation of direct competitors from adjacent alternatives,
- “Needs validation” and fallback states,
- unsupported traction, funding, market-size, and eligibility claims blocked,
- human approval before continuing.
The founder stays in control. LaunchPilot advises; the founder decides.
Challenges we faced
The hardest challenge was making AI useful without making it overconfident.
Public web evidence can show that a market exists, but it cannot prove that a specific customer will switch, pay, or trust a new product. We had to design the system so it surfaced uncertainty instead of smoothing it away.
We also solved several production challenges:
- Firebase sign-in and app-session bridging,
- multi-project user isolation,
- Vercel Blob persistence and stale-read handling,
- fast interview startup,
- validation continuation without trapping users in refinement loops,
- Copilot answers based on persisted project context,
- refresh-safe dashboards and exports,
- stable production deployment under real provider failures.
What we learned
The best AI founder assistant is not an oracle. It is a system that helps founders think clearly under uncertainty.
A weak tool gives a founder more tasks. A better tool shows which assumption matters most. LaunchPilot is built for that second outcome.
Why it matters
For a student founder, one wrong month of building is expensive. LaunchPilot helps them move from enthusiasm to evidence, from vague ambition to a testable plan, and from “I should build this” to “I know what I need to prove first.”
That is the core idea:
Responsible AI should not replace founder judgment. It should make founder judgment sharper.
Built With
- answerqualitygate
- apikeypooling
- assumption-risk-agent
- assumptionriskagent
- auth.js
- browser-speech
- browserspeech
- chart.js
- confidence-labels
- contextual-copilot
- contextualcopilot
- email-auth
- evidence-based-ai
- evidence-scoring
- evidencebasedai
- evidencescoring
- exa
- firebase
- firebase-authentication
- founder-copilot
- founder-interview
- foundercopilot
- founderintake
- framer-motion
- framermotion
- gemini-live-api
- geminiapi
- geminilive
- geminisearchgrounding
- github-api
- google-gemini-api
- google-search-grounding
- google-sign-in
- groq
- gsap
- hacker-news-api
- human-in-the-loop
- humanintheloop
- json-export
- jsonexport
- launch-brief
- launchbriefworkspace
- live-web-research
- livewebresearch
- llama
- markdown-export
- markdownexport
- market-reality-agent
- marketrealityagent
- marketresearch
- multi-agent-workflow
- multiagentworkflow
- mvp-scope-agent
- mvpscopeagent
- next.js
- nextauth
- opportunity-agent
- opportunityagent
- pitch-agent
- pitchagent
- playwright
- postgresql-ready
- prisma
- providerfallback
- rag
- react
- responsible-ai
- responsibleai
- retrieval-augmented-generation
- retrievalaugmentedgeneration
- roadmap-agent
- roadmapagent
- serpapi
- shadcn-ui
- source-classification
- sourceclassification
- sqlite
- startup-validation
- startupvalidation
- tailwindcss
- tavily
- testing-library
- typescript
- vercel
- vercel-blob
- vitest
- voice-interview
- voiceinterview
- world-bank-api
- xai-grok
- zod

Log in or sign up for Devpost to join the conversation.