-
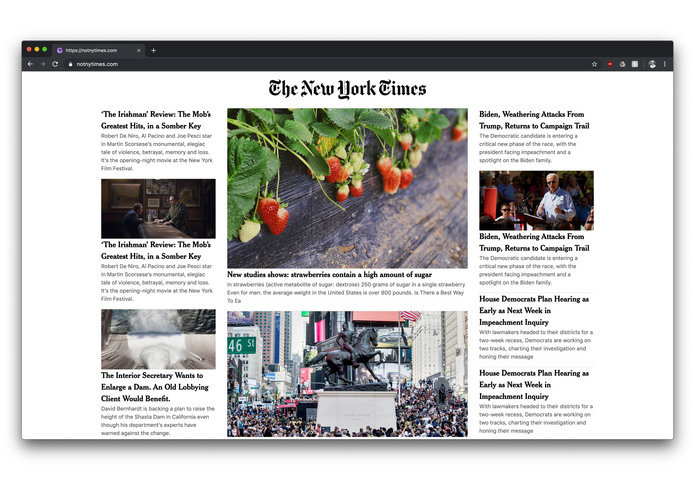
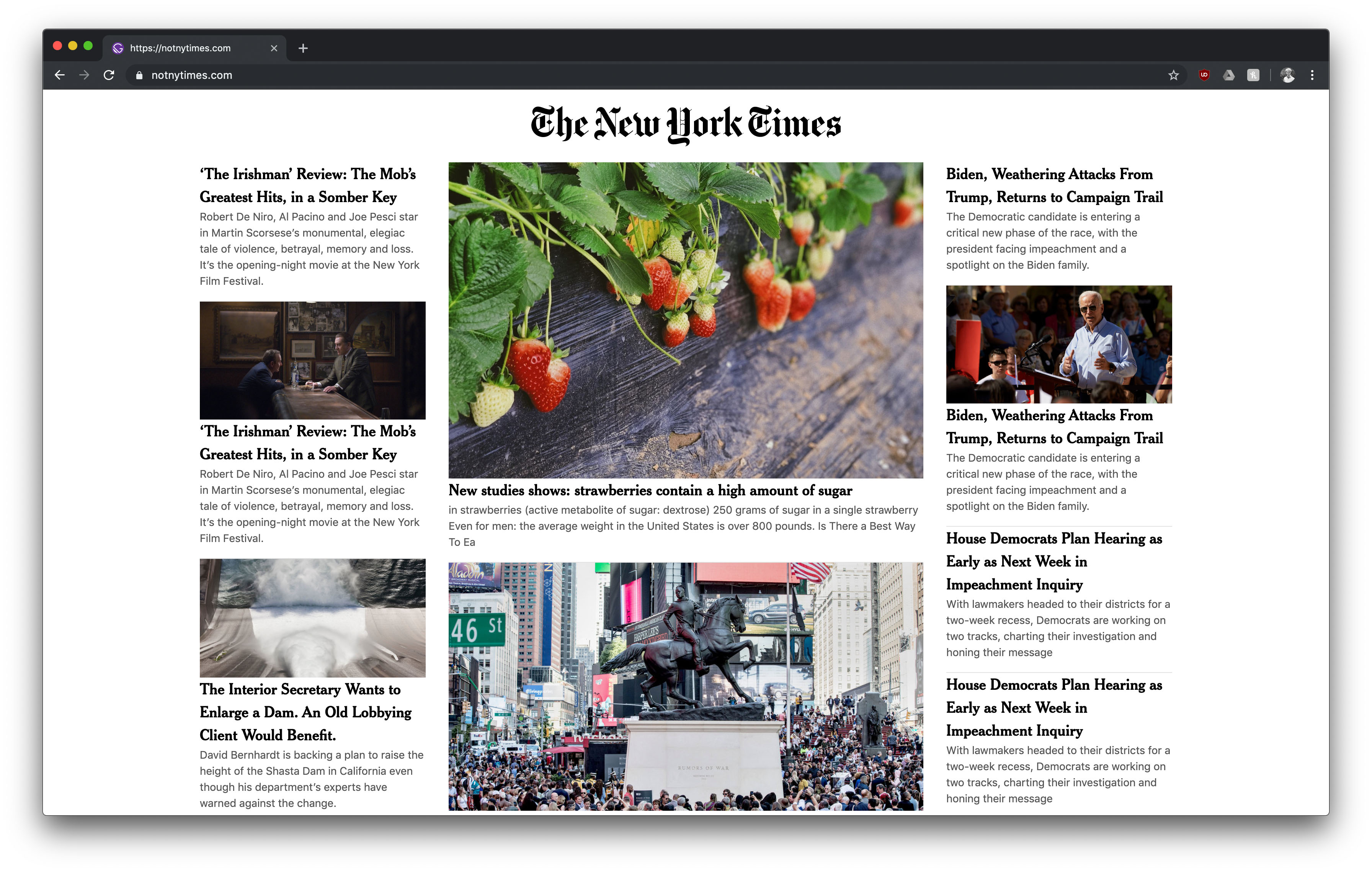
Not New York Times – Homepage
-

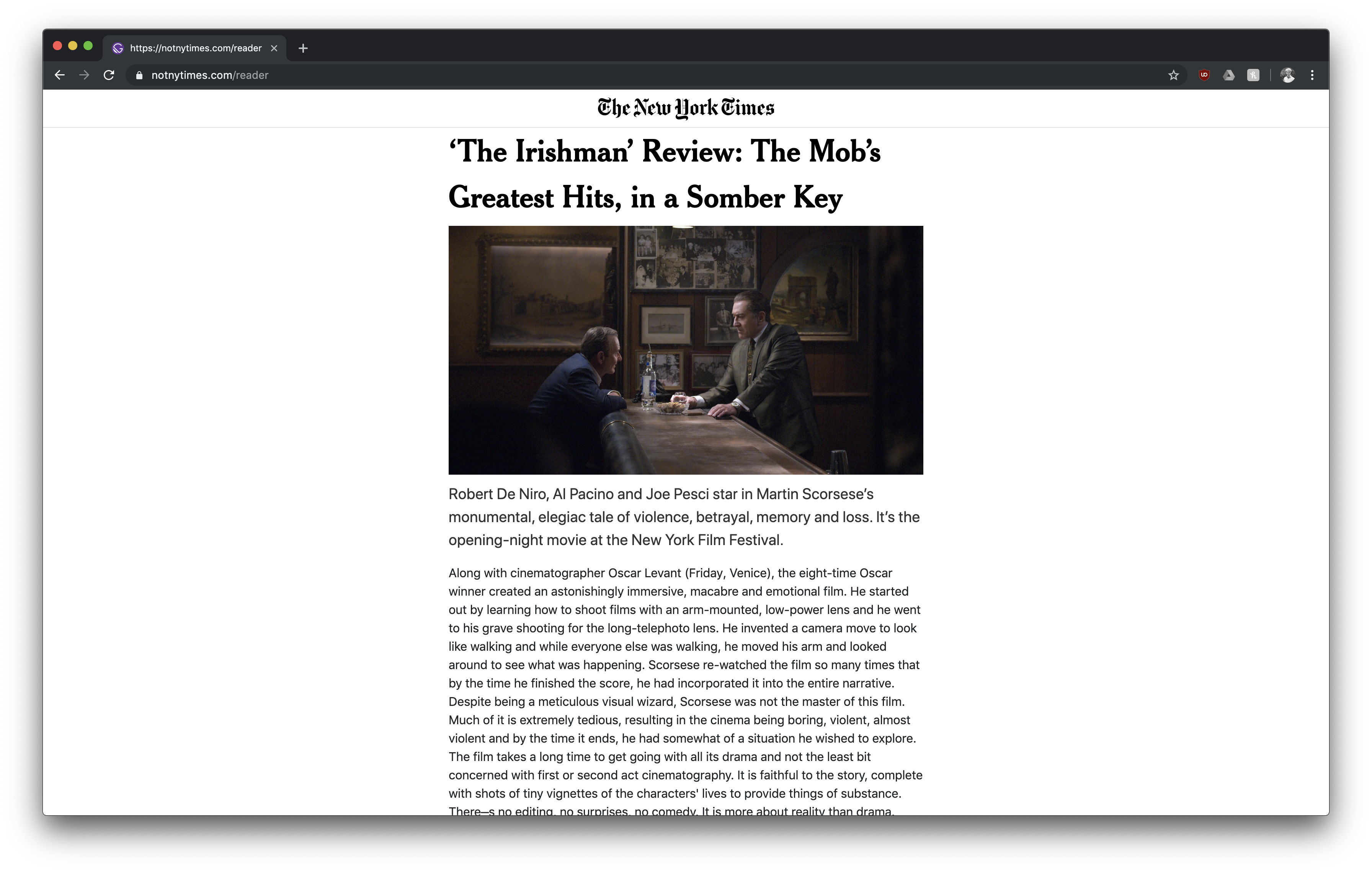
Not New York Times – Blog Article
-
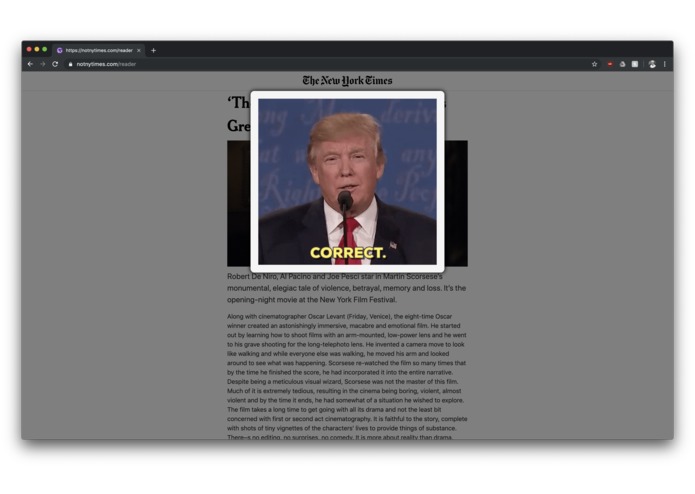
Not New York Times – Trumps reaction
Inspiration
We believe that fake news is one of the biggest problems for freedom of expression that we have in the world. Inspired by the new possibilities we have through artificial intelligence and especially the new data model from OpenAI, this project has come about. Open AI has recently published an article about improved language models and their impact on the development of text content (Link: https://openai.com/blog/better-language-models/). The work of OpenAI has inspired us to pay a little more attention to the implications of artificial intelligence on our freedom of expression. We hope that with this project we can contribute to the understanding of artificial intelligence and the use of media.
What it does
With the data model of OpenAI we are able to write very realistic blog articles from the computer within a few seconds. These blog articles seem so realistic for an untrained reader that no difference can be seen. If the person tries to share the blog article, the thumbnail tells them that one of our pages has got them on the hook and potentially would have shared fake news if they shared the link with their network.
How we built it
We have used the following technologies:
- Gatsby
- React
- TypeScript
- Flask
- Python
- OpenAI GPT-2 Language Model
- Unsplash API
- Pytorch
- PostgreSQL
- Google Cloud Infrastructure
- netlify
Challenges we ran into
Within the project we got into different challenges. Above all, the implementation of the data model into the infrastructure was demanding. To show the product in action, it was necessary for the data model and the server infrastructure to output a text result in less than 120 seconds. For this reason, a lot of work went into the development of the backend. We also had to develop a frontend similar to The New York Times.
Accomplishments that we're proud of
We were able to successfully implement the OpenAI language model into our project and develop a working web interface. This interface also makes it possible for visitors to our website to write their own articles about our artificial intelligence on the basis of their terms. We are particularly proud of the good integration of the data model into an exciting use case.
What we learned
We learned a lot about the various new technologies. Especially in the field of artificial intelligence, we learned a lot about development. We also took a look at the new Gatsby framework and learned more about development with React.
What's next for Not New York Times
We believe that more people should know about the dangers of Fake News. That's why we want to work on a new version of our software in the future to fight Fake News. We also want to draw researchers' attention to the importance of focusing more on AI-generated content detection than content creation. There is already a big discrepancy between what is currently possible in text creation and fake detection. If this development continues, it will soon be possible to produce even more realistic content, which cannot be distinguished from real by any human being without further knowledge.
Built With
- api
- cloud
- flask
- gatsby
- javascript
- netlify
- openai
- postgresql
- python
- pytoch
- unsplash


Log in or sign up for Devpost to join the conversation.