-
-
Landing page
-
-
-
-
NoShot (You're Still LeetCoding)
The Premise
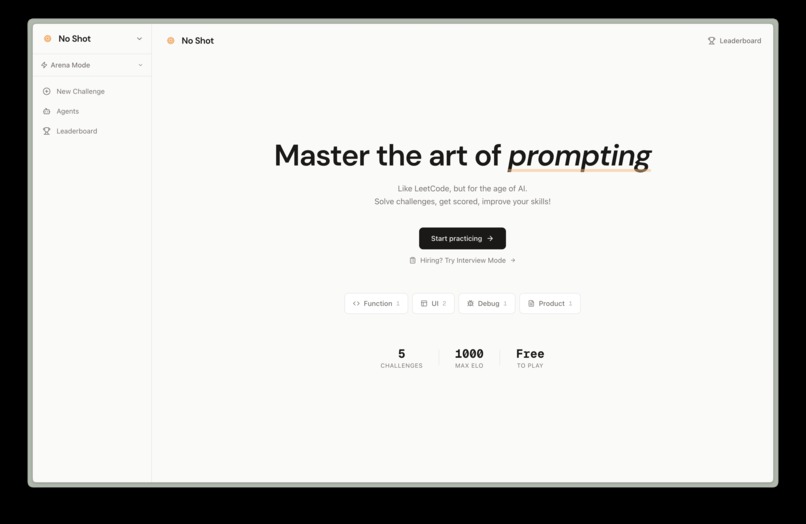
Every developer writes code by directing AI now; the new default is prompting. We want to build a standardized way to measure, compare, and certify that skill.
NoShot is Leetcode for the AI era. Just as Leetcode became the canonical benchmark and training ground for DSA, NoShot creates the canonical benchmark for prompting speed, efficiency, and accuracy. You sit down, you face a challenge and you prompt an LLM to do it. You're scored on how fast, how token-efficient, how few turns, and how accurate your output is. Your score goes on a global leaderboard. You share a result card on X. You hillclimb a leaderboard.
That's the consumer product. But, underneath it, we're building something much bigger.
The Vision: Three Layers
NoShot is a three-layer platform:
Layer 1: The Arena (Consumer)
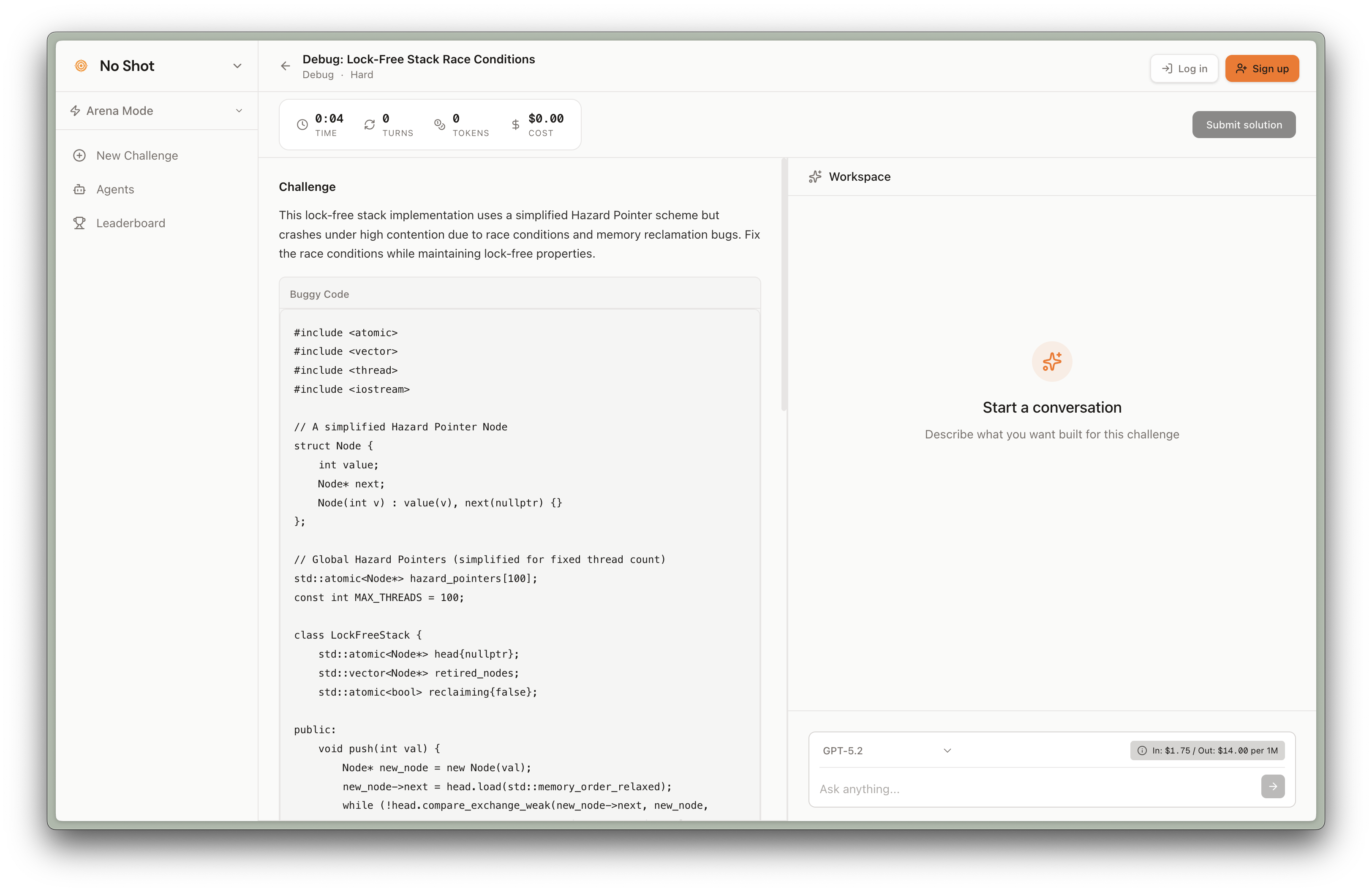
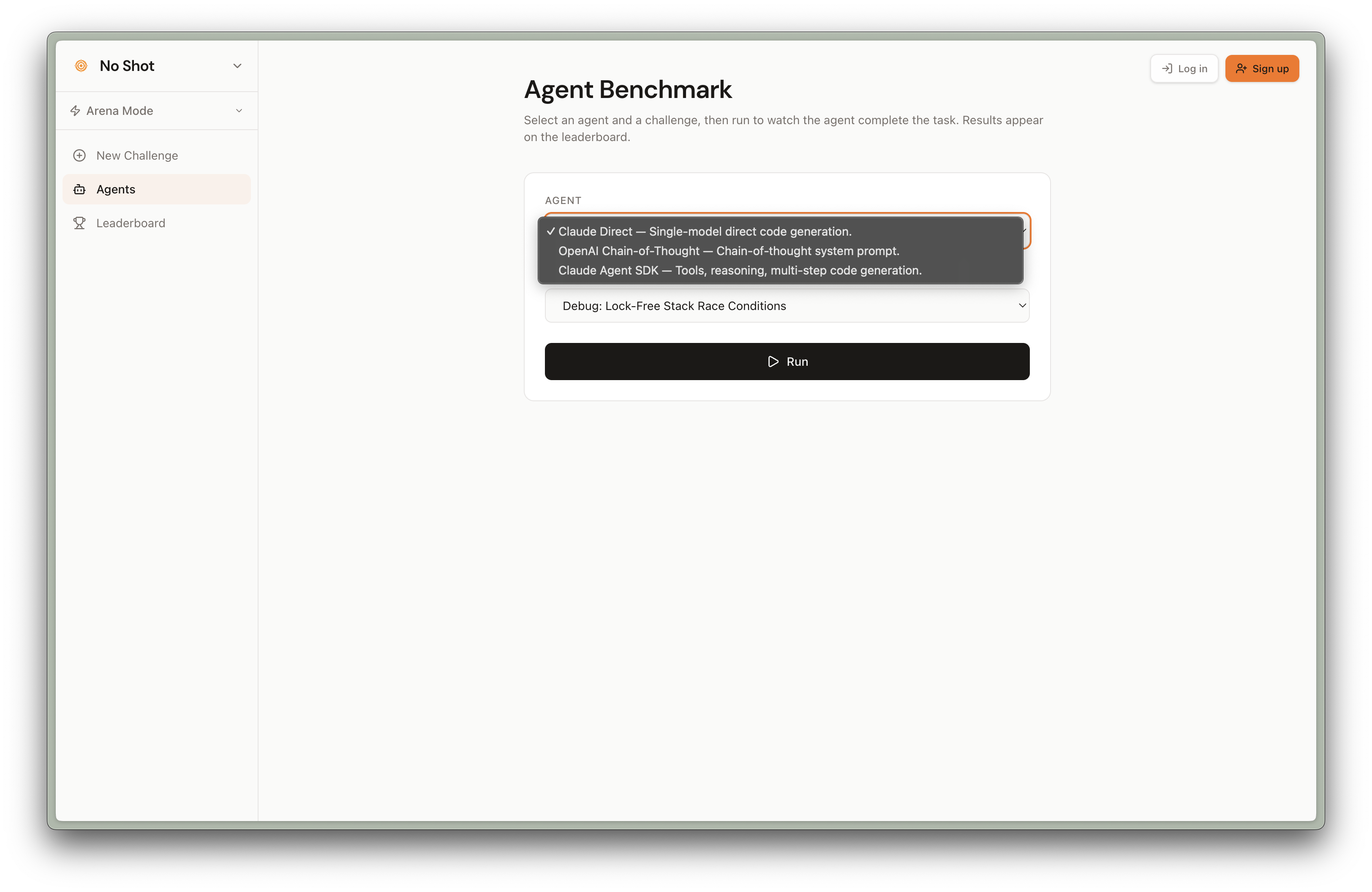
The default experience. Users land on a challenge, prompt an LLM, and get scored.
How it works:
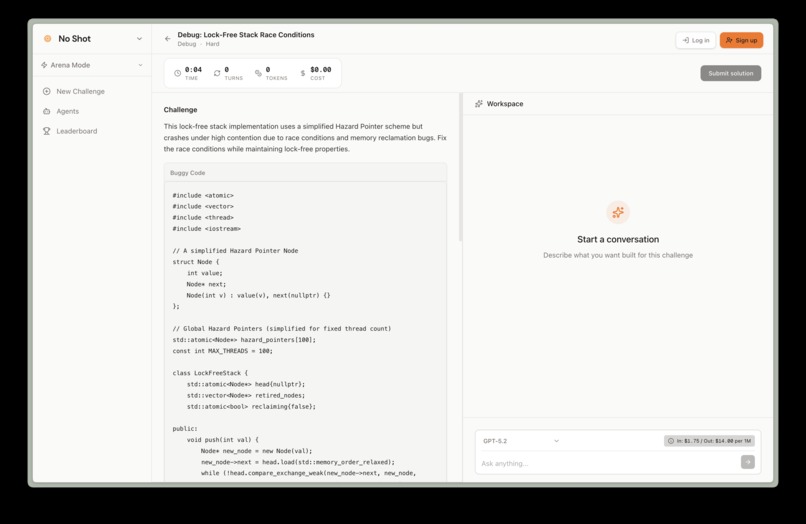
- You see a target — a rendered UI component, a function signature with test cases, or a data transformation spec
- You write prompts in a split-pane editor
- The LLM generates code, which executes in a sandboxed environment and renders live
- You iterate until your output matches the target
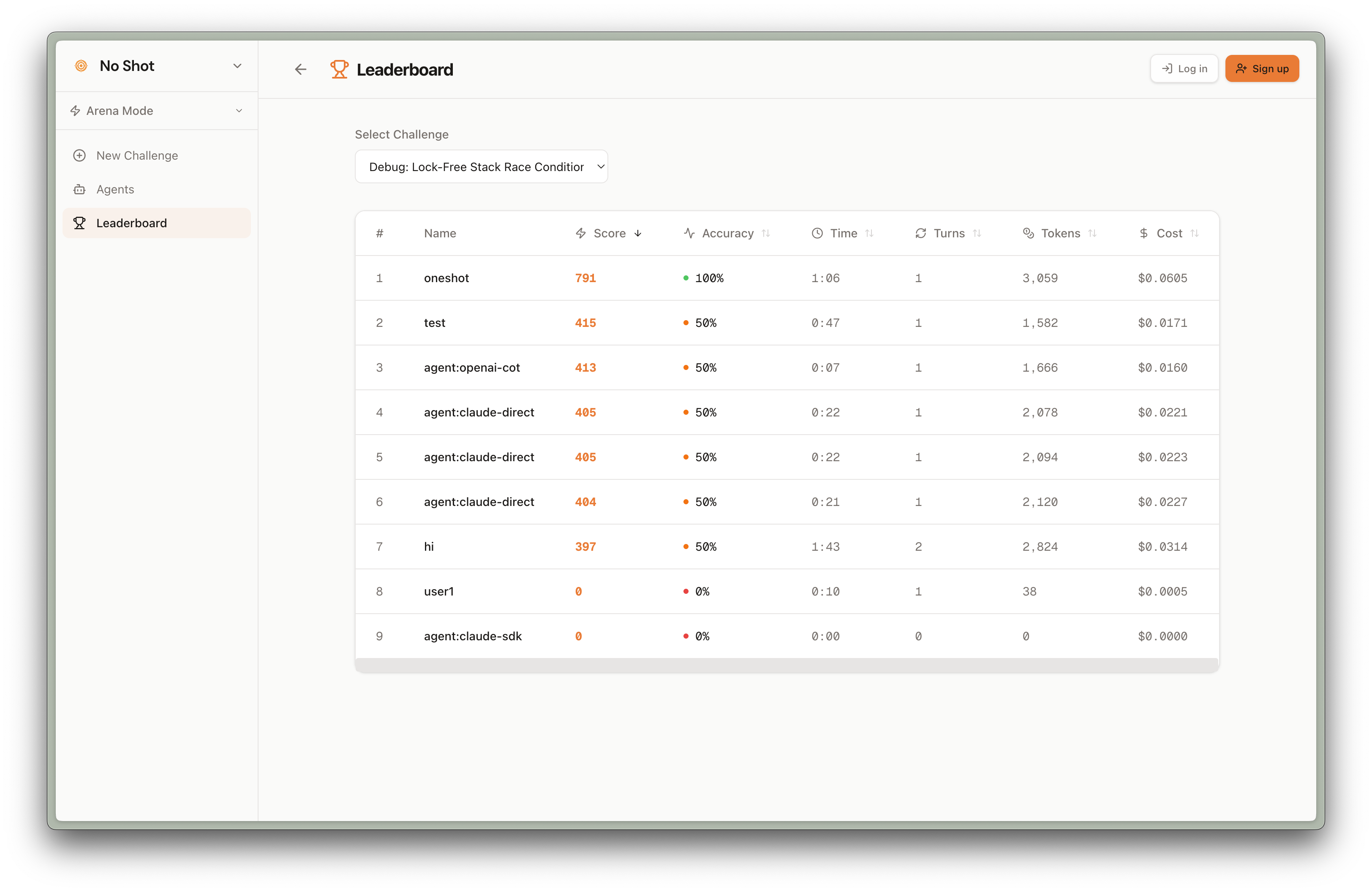
- On completion, you receive a NoShot Score — a composite of speed, token efficiency, and accuracy
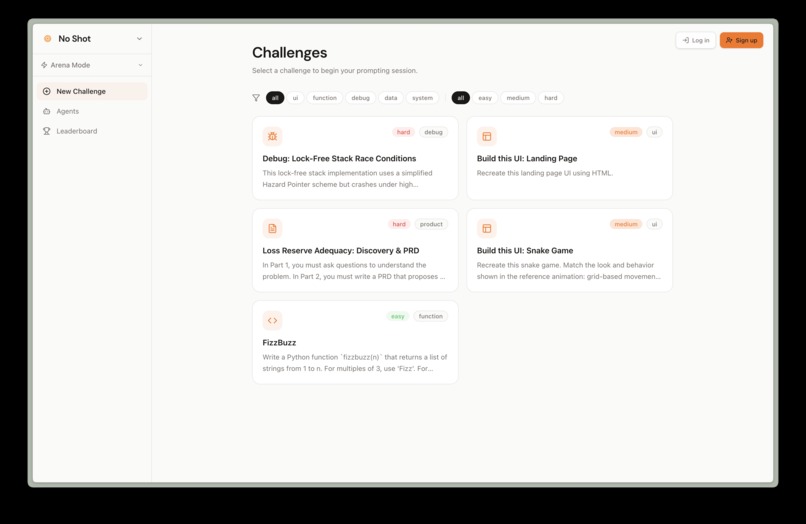
We support five challenge categories:
- UI Build — "Reproduce this component" (scored via LLM-graded HTML comparison)
- Function — "Write a function that passes these tests" (scored via sandboxed test execution)
- Debug — "This code has a bug, fix it via prompting" (scored via sandboxed test suite)
- Product — "Chat with a stakeholder, then write a PRD" (scored via LLM-graded rubric on feasibility, expertise, clarity, and alignment)
- Data — "Transform this dataset" (scored via exact output match)
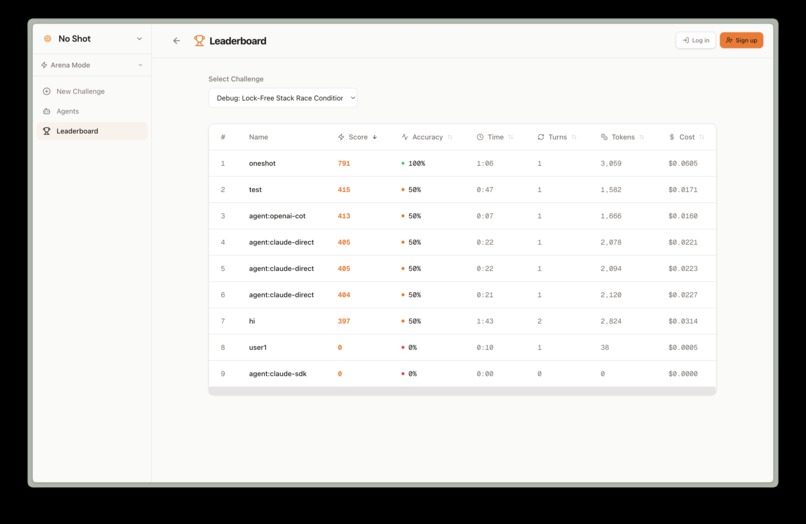
Each category has Easy / Medium / Hard difficulty tiers. A global ELO leaderboard ranks users by composite score. Result cards are designed for X — they show your ELO, score breakdown, performance metrics, and challenge name.
Layer 2: Interview Mode (B2B)
A CoderPad-like session where companies assess candidates on prompting ability.
This is where we think hiring is going. The question isn't "can this person write a binary search from memory?" anymore. The question is: can this person prompt effectively, read traces, iterate on AI output, and ship?
Interviewer flow:
- Create an interview room with a unique shareable link
- Add challenges — coding, frontend, or system design
- Configure constraints: time limit, allowed models, max token budget
- Share the invite link with a candidate
- Watch the session live — see prompts, AI responses, code output, and test results in real time
- After session: view an assessment report with detailed analytics
Candidate flow:
- Join via link — no account required
- See the challenge description
- Prompt and iterate in the standard editor
- Session auto-submits on time expiry or manual submission
Live observation dashboard:
- Real-time stream of the candidate's prompts and LLM responses
- Generated code updating live
- Test case pass/fail status
- Running metrics: elapsed time, tokens used, turns taken
- Full session replay for post-interview review
This is a direct monetization path: per-session or monthly subscription pricing for companies. We can also partner with startups and give interviews to the top candidates every week!
Layer 3: Foundational Model Data (The Long Game)
This is the part we're most excited about, and the part that makes the other two layers worth 10x more.
Every session on NoShot generates structured, high-signal training data that foundational AI labs desperately need.
Here's what we collect from every session:
| Data Point | Description | Signal |
|---|---|---|
| Prompt text | Raw user prompt per turn | Intent → code mapping |
| Generated code | LLM output per turn | Prompt → completion pair |
| Acceptance signal | Did the user iterate or accept? | Implicit preference / RLHF |
| Edit patterns | What changed between consecutive prompts? | Correction signal |
| Final code | The accepted output | Ground truth for quality |
| Token count | Tokens used per prompt | Efficiency benchmark |
| Turn count | Iterations to correct output | Prompt quality signal |
| Challenge metadata | Category, difficulty, target spec | Task complexity context |
| Time per turn | How long the user spent crafting each prompt | Deliberation signal |
Why labs would buy this data:
Multi-turn RLHF sequences. The most valuable training signal for frontier models is multi-turn human-AI interaction where the human is correcting, refining, and steering. That's literally every NoShot session. Labs like OpenAI, Anthropic, and Google currently pay human contractors to generate this data synthetically. We generate it organically at scale, from real users with genuine intent.
Implicit preference data. When a user accepts an output on turn 3 instead of iterating further, that's a preference signal. When they reject turn 1's output and rephrase, the pair (prompt₁ → output₁, prompt₂ → output₂) tells you which style of instruction the model should learn to respond to better. This is the exact format needed for DPO (Direct Preference Optimization) and RLHF pipelines.
Prompt efficiency pairs. Two users solve the same challenge — one in 2 turns with 150 tokens, another in 8 turns with 2,000 tokens. The terse prompts that produce equivalent output to verbose prompts are gold for training models to understand concise instructions. Labs are actively looking for data that helps models do more with less context.
The flywheel: More arena users → more sessions → richer data → better data licensing revenue → funding for better challenges → more users. The consumer product is the data engine.
How We Built It
Architecture
┌─────────────────────────────────────────────────────────────┐
│ Frontend (Next.js on Vercel) │
│ ┌──────────┐ ┌──────────┐ ┌───────────┐ ┌──────────────┐ │
│ │ Arena │ │Interview │ │ Practice │ │ Leaderboard │ │
│ │ Mode │ │ Mode │ │ Mode │ │ & Profiles │ │
│ └────┬─────┘ └────┬─────┘ └─────┬─────┘ └──────┬───────┘ │
│ └────────────┴─────────────┴──────────────┘ │
│ │ │
│ WebSocket ◄──┼──► REST API + SSE │
└───────────────────────────┼─────────────────────────────────┘
│
┌────────┴────────┐
│ FastAPI on │
│ Render │
└────────┬────────┘
│
┌───────────────┬───────┴───────┬───────────────┐
│ │ │ │
┌───┴───────┐ ┌─────┴─────┐ ┌───────┴───────┐ ┌─────┴─────────┐
│ Supabase │ │ Multi-LLM │ │Modal / Vercel │ │ Claude Agent │
│(PostgreSQL│ │ Router │ │ Sandboxes │ │ SDK │
│ │ │ (OpenAI, │ │ (code exec) │ │ │ │
│ │ │ Claude, │ │ │ │ ▼ │
│ │ │ Grok, │ │ │ │ ┌───────────┐ │
│ │ │Perplexity)│ │ │ │ │Browserbase│ │
│ │ │ │ │ │ │ │ Stagehand │ │
└───────────┘ └───────────┘ └───────────────┘ └─┴───────────┴─┘
Tech Stack
| Component | Technology | Why |
|---|---|---|
| Frontend | Next.js 15 (App Router), TypeScript, Tailwind CSS | Server components, fast navigation, Vercel-native |
| Backend | FastAPI (Python) + Bun (Javascript) | Async-native, WebSocket support, clean API design |
| Database | Supabase (PostgreSQL) | Managed Postgres, instant REST API, auth primitives |
| Auth | Auth0 | OAuth with GitHub/Google, JWT tokens, zero-config |
| Code Execution | Modal Sandboxes | Ephemeral containers, isolated execution, auto-scaling |
| LLM Providers | OpenAI (GPT-5.2, GPT-5 Mini/Nano), Anthropic (Claude Opus/Sonnet/Haiku), xAI (Grok) | Perplexity Sonar API |
| Real-time | Server-Sent Events (SSE) + WebSocket | Low-latency streaming for chat, observation, and live metrics |
| Deployment | Vercel (frontend) + Render (backend) | CI/CD, preview deploys, managed infrastructure |
Key Technical Decisions
1. Composite (ELO) scoring system. Every session produces a -1 to +1 Elo delta:
Delta = 0.70 × Accuracy^2 + 0.15 × Time_penalty + 0.15 × Cost_penalty
Each sub-score is normalized against difficulty-based baselines. This might be adjusted based on user-data. An easy challenge expects 30 seconds and 200 tokens; a hard one expects 300 seconds and 1,000 tokens. The scoring rewards both raw skill and efficiency — you can be accurate but inefficient, or fast but sloppy, and the score captures the tradeoff.
2. Interview mode with live observation. The interview system uses SSE to broadcast every candidate action to the interviewer's observation dashboard. When a candidate submits a prompt, the interviewer sees it in real-time. When the LLM responds, both the candidate and the interviewer see the same token stream. Turn metrics, code output, and test results update live. After the session, a full assessment report is generated with turn-by-turn replay.
3. Prompt feedback engine. After every session, users can request AI-powered feedback on their prompting strategy. The feedback engine analyzes the full conversation — user prompts, LLM responses, iteration patterns — and produces a concise evaluation: what worked, what didn't, one improvement suggestion, and one prompt template to try next time. For product challenges, the feedback evaluates the PRD on feasibility, expertise, clarity, and alignment with the discovery conversation.
The Prompting-First Philosophy
We built NoShot because we believe the future of software development is prompting, not manual coding.
The traditional hiring pipeline tests whether a candidate can recall syntax, manipulate data structures, and write code from scratch. These are valid skills, but they're increasingly commoditized by AI. The scarce skill now is the ability to direct AI effectively: to decompose a problem into promptable sub-tasks, to read LLM output critically, to iterate on failures, and to ship a working product through human-AI collaboration.
This is what NoShot measures. When a candidate sits down in Interview Mode, we're not testing whether they can write a sorting algorithm. We're testing:
- Problem decomposition — Can they break a complex target into a sequence of prompts that build on each other?
- Context management — Do they provide the right amount of context? Too little and the LLM guesses wrong. Too much and they waste tokens (and time).
- Trace reading — When the output is wrong, can they diagnose why? Do they read the generated code, or do they blindly re-prompt?
- Iteration strategy — Do they refine incrementally, or do they start over? Do they get stuck in a loop, or do they change approach?
- Model awareness — Do they choose the right model for the task? A UI challenge might benefit from a vision-capable model. A simple function might only need a fast, cheap model.
These are the skills that separate a productive AI-native developer from someone who just copies ChatGPT output. And right now, no hiring platform measures them.
What's Next
What's next:
- Head-to-head mode — Live competitive racing: two users compete on the same challenge simultaneously via WebSocket
- Data pipeline — Automated anonymization, aggregation, and export of prompt-completion datasets
- Expanded question bank — Practice with agentic tooling or domain-specific settings where AI automation is replacing traditional workflows
- Enterprise dashboard — Analytics for hiring teams: candidate comparison, team benchmarks, skill gap analysis
- Persistent interview mode — Move interview rooms from in-memory storage to Supabase for production-grade reliability
- AI coach agent — A multi-turn agent that watches your session and provides real-time coaching on your prompting strategy
Built With
- auth0
- browserbase-stagehand
- claude-agent-sdk
- fastapi
- modal-sandboxes
- perplexity-sonar-api
- supabase
- typescript
- vercel-sandboxes



Log in or sign up for Devpost to join the conversation.