-
pythonscript
Normalize Your Data, pls
Remembering CS202 Database systems course DANIEL An (team Five) Failed attempt Use SARIMA, PCA, and Naïve Bayesian to predict the daily congestion at a port using AIS data. Adjust ship’s speed accordingly to save fuel
The AIS data was around NY/NJ, and contained mostly ferries and tugboats Data downloaded from https://marinecadastre.gov/ais/ AIS collected in 18 zones from year 2009-2017. 2017 data alone is 82GB in 200+ zip files. Download time: 4 hours Time required to unzip all the files : 3 hours Size of 2017 data after unzip: 400+ GB
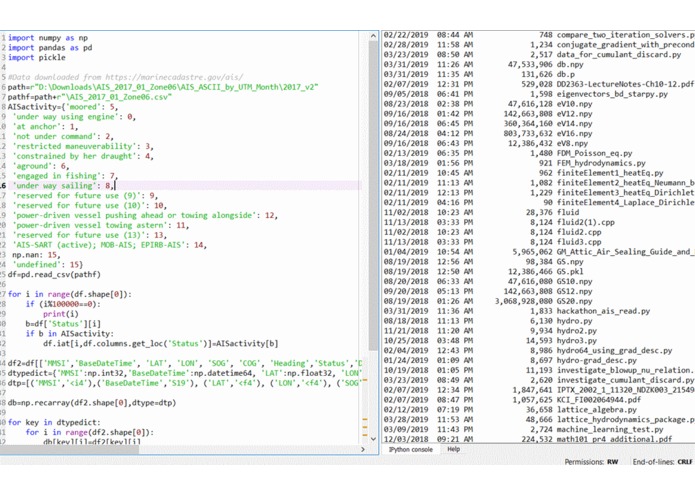
Lack of explanation of data One pdf file says VesselType is a two digit number. The data has VesselType as 4 digit number ??? How can I find out if the ship is a container, bulk carrier, RoRo, Tanker etc.? AIS data has lot’s of redundancies 1NF --> 2NF normalization and more. Make a separate table for IMO number, Call sign and MMSI number --> make it possible to convert between the numbers Make a separate table for ship information: name, type, length, width. Less redundancy --> less memory. Also use data types that require less memory. Int2 over int8. AIS activity is changed back to AIS activity code
To do next: Conclusion Problem: Fractured, scattered data. Hard to find definitions, and packages. Having to rely on paid websites for public information Solution: Let data be handled by those who know data and has been thinking about data. Excel spreadsheets and csv files are not data. We can start working on publicly available data.



Log in or sign up for Devpost to join the conversation.