-
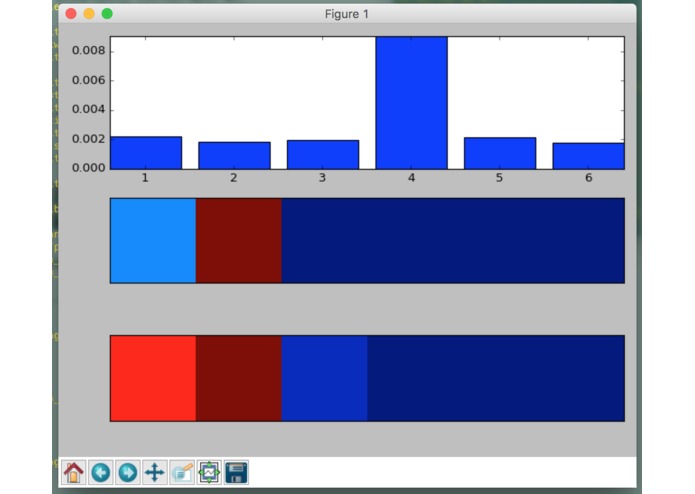
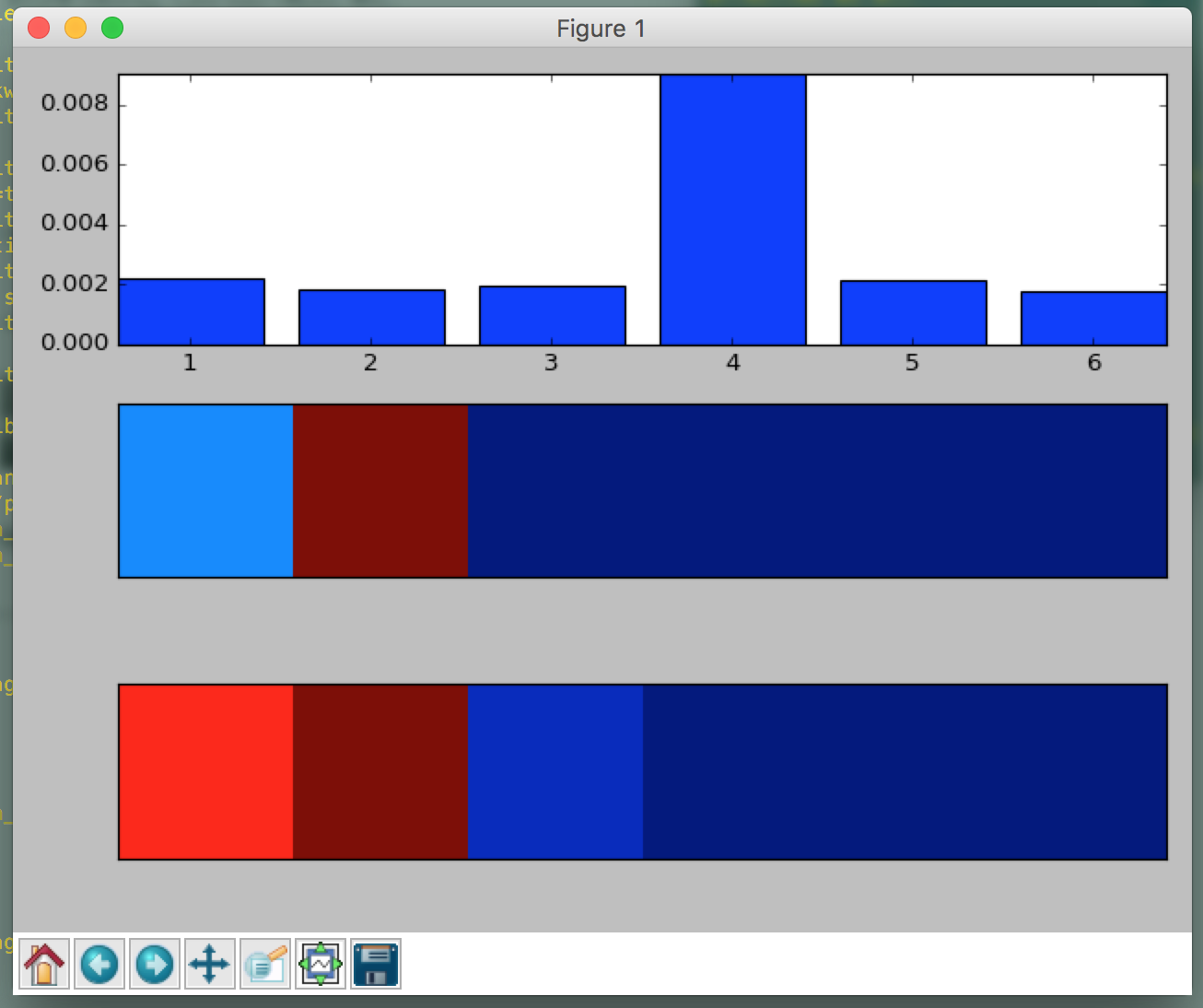
Properly classified entry! Yeay
-
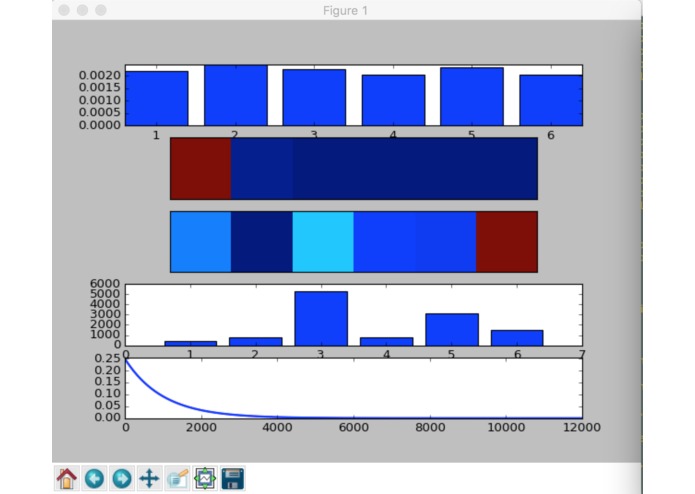
A bit confused???
-
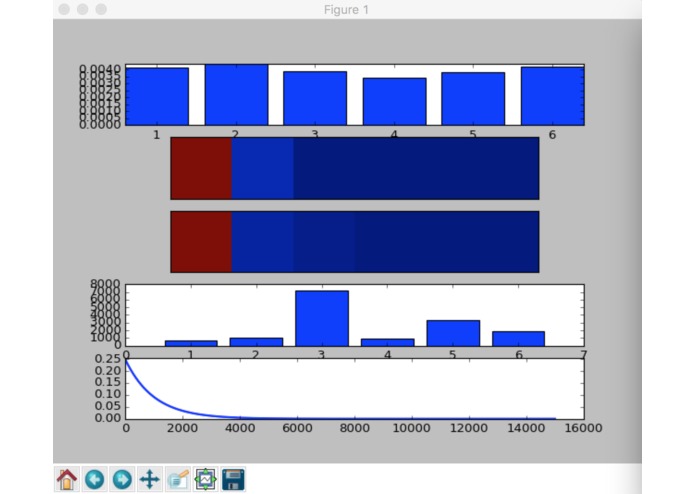
Learning!!
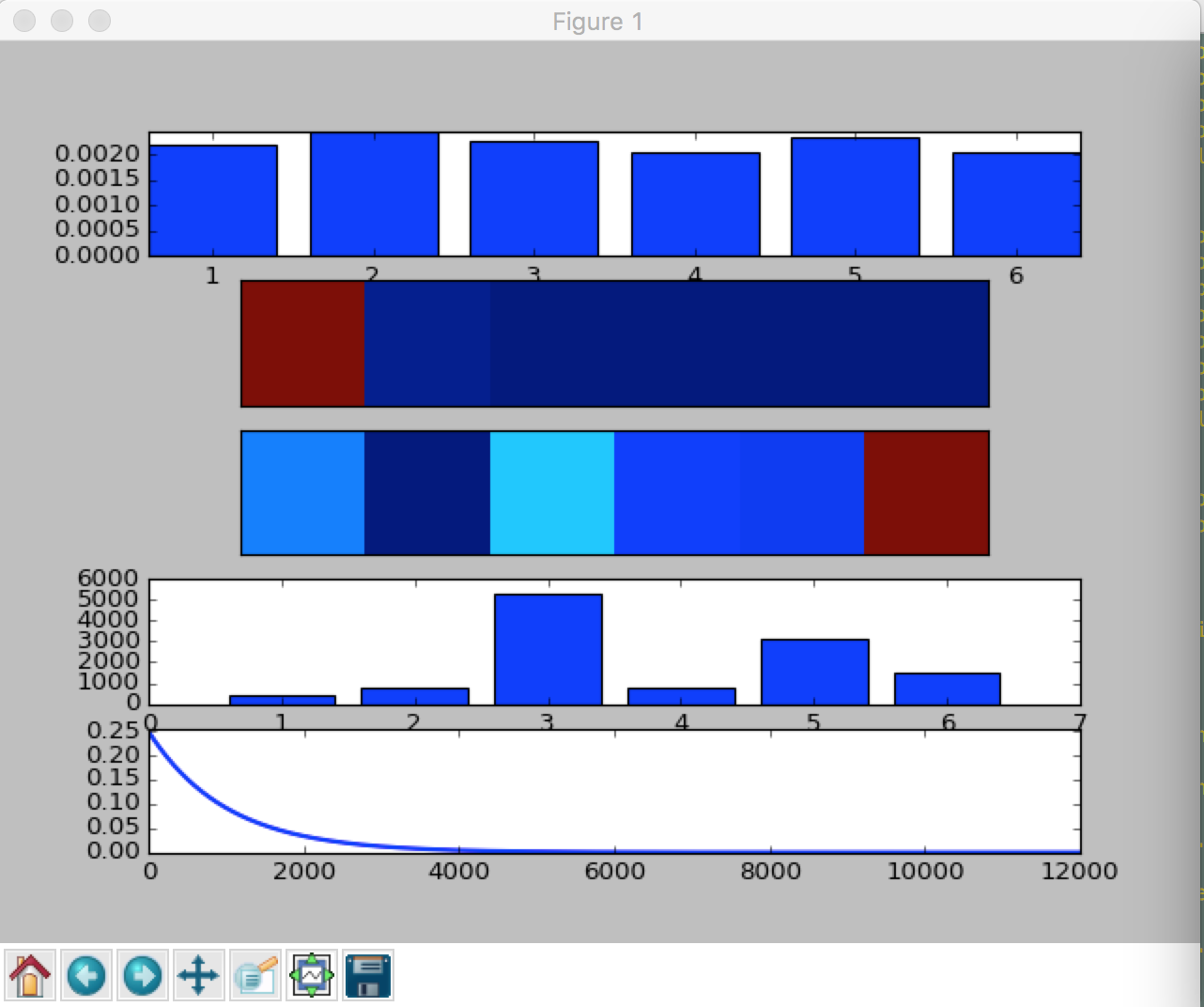
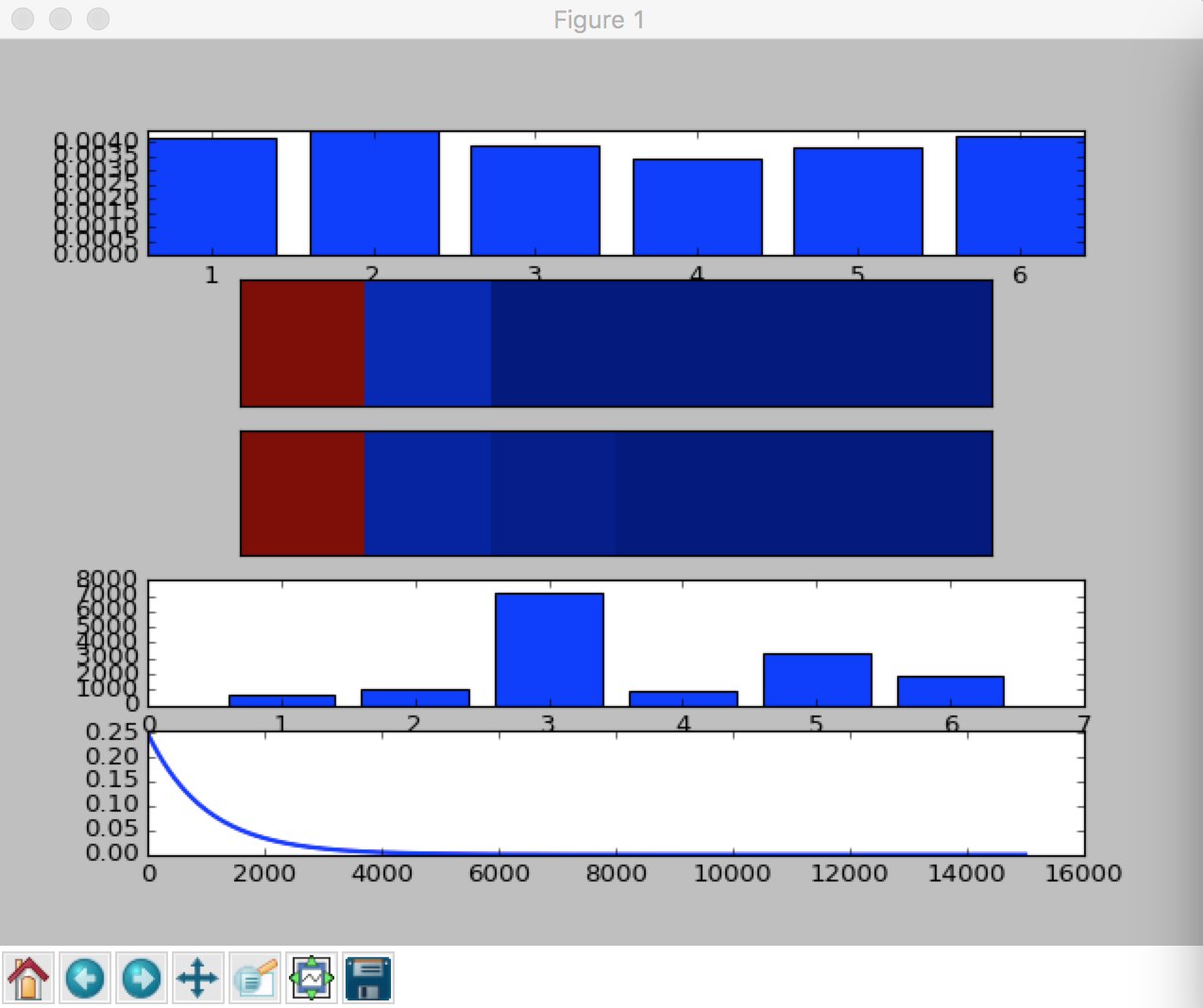
Inspiration
Sensor data from real world can be extremely noisy. Trying to make sense of tens of thousands of entries manually is NOT an option. Our approach uses different techniques to map the entries to the proper activities.
What it does
Initial dataset has many instances that are mislabeled. We use a rule-based pre-processing routine to filter the meaningless data points. A simple neural network is then trained to classify the entries into 6 categories: IN_VEHICLE, ON_BICYCLE, STILL, UNKNOWN, TILTING, WALKING The final goal is to visualise this new, improved information on a front-end.
How we built it
The data is in CSV format, the pre-processing is done using simple python scripts and subroutines. The neural-net is written in python and is an input layer directly fed into an output layer. Activation function is a simple max function. Noise was introduced to try to reduce the effect of the skew in the classes composing the dataset.
Challenges we ran into
The dataset, being real-world sensor data, was skewed towards certain activities. This means that some classes were overrepresented during the learning process and dominated the network.
Accomplishments that we're proud of
There is [a certain degree of] learning from the network and the visualisation shows that pre-processing is useful to a certain extent.
What we learned
Expect some serious noise in real world-data, sensors are cool but take them with a pinch of salt. Unsupervised learning is hard but super-cool.
What's next for NoisyWorld
Introducing techniques to reduce the effect of skew in the data.




Log in or sign up for Devpost to join the conversation.