-
-
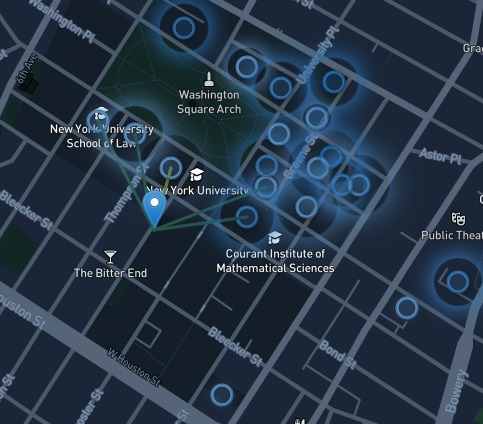
Sensor Map
-
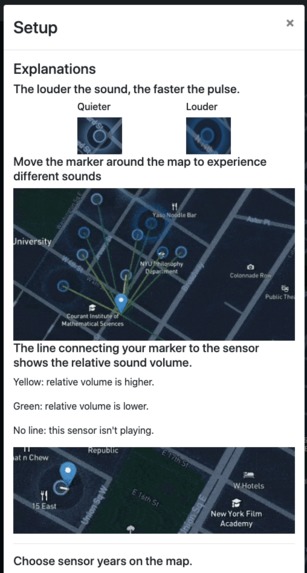
Introduction for Sensor
-
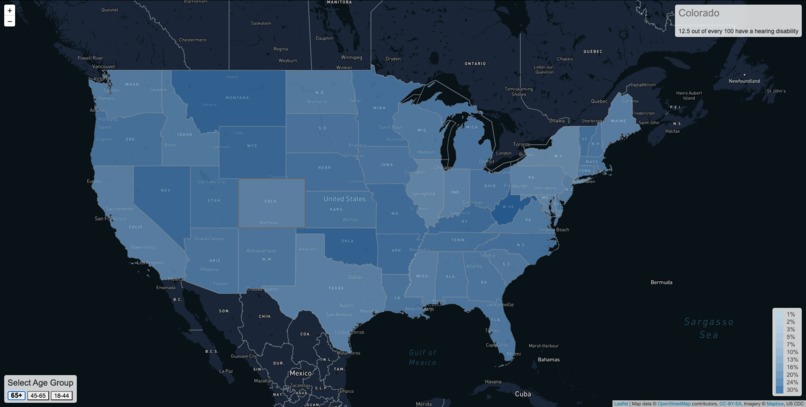
Map of Hearing Disability Across the US
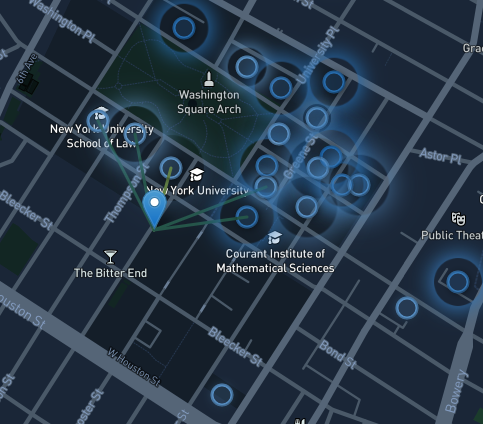


Inspiration
When the world went into lockdown, one interesting effect was the drastic reduction in sound in places like New York. That change in sound got us wondering how noise pollution has been effecting us. We grounded our look in how hearing loss could be measured. Using AWS Data Exchange, we found CDC data showing the prevalence of hearing disability by state and age group. We were expecting there to be a clear pattern between those states that have large cities and industry and hearing loss. However, we were shocked to see that for the most part, hearing loss effected every state significantly. With this discovery, we began wondering how the world should prepare for a good portion of its population to eventually become hard of hearing.
Having family members who suffer from hearing loss, we knew first hand that hearing aids can be improved significantly and have a real impact on quality of life. With this in mind, we began researching how to improve hearing aids. While we saw implementations on the market that would allow for the hearing aid to automatically adjust the volume, the flaw we saw in this was that not all sounds should be treated equally. While dampening construction noises would likely be fine, reducing the sound of a siren or a car horn could be dangerous for the person. This was when we began creating our machine learning model.
What it does
Our project has three deliverables.
The first one showcases how many people across the country suffer from a hearing disability. Showing you the data by state and age group, you can see that the problem effects people nationwide, and across all age groups. It is truly a problem of societal scale.
The second one showcases the danger that comes with city living and hearing loss. Using SONYC data from the past 4 years, we illustrated via map how walking through the city can impact your ears. We illustrate this concept visually with pulsations on map markers to show how loud the sound is. We draw lines between the map makers and the person icon to show what is a safe distance to be from the noise. Finally, we allow the listener to hear what the sound is like. All in all, the point is to visualize how the noises can impact you without your consciously realizing it.
The final one is a testing script. Using the sound classification convolutional neural network devised by Justin Salamon and Juan Pablo Bello (https://arxiv.org/pdf/1608.04363.pdf) and implemented by CodeImporium (https://www.youtube.com/watch?v=GNza2ncnMfA), we trained the model on UrbanSound8K data. Then to see how well it responded to a real world scenario (where multiple different sound classes were present), we tested it against data from SONYC. Overall the model did not perform well, suggesting that when building tech to help hearing aids distinguish multiple different sounds, CNNs will have to be more focused on the probabilities being correct for the different sounds than the one classification they think it is most likely to be.
How we built it
Hearing loss data was accessed using AWS Data Exchange, which contained the CDC DHDS - Prevalence of Disability Status & Types by Demographics dataset. We then used an Amazon EC2 instance, S3, and an auxiliary EBS disk, along with JupyterLab to clean and explore this dataset. Once we had sufficiently cleaned the data, we merged it with a GeoJSON of the 50 US States and Puerto Rico, which was displayed in a LeafletJS chloropleth map. This map provides the user the ability to toggle between different CDC defined age groups and view the estimated prevalence of hearing loss. Once we noticed that hearing loss was more common than our initial expectation, we explored other datasets. This brought us to NYU SONYC (Sounds of New York City), who maintain a Creative Commons licensed dataset of audio files from numerous microphones placed around New York City. For our purposes, we used version 2.2 of this dataset, which had a temporal range of 2016 - 2019. This dataset contained 10k+ short recorings of sounds, in the WAV file format, along with location metadata. We decided to visualize a unqiue subset of these recordings using a LeafletJS map. In order to be able to visualize identify louder sounds easily, we make use of icons which pulse based on how "loud" a specific sound should be. Additionally, when a marker is in range of one of SONYC's sensors, the specific audio clip from that time will be played. This allows users to move an icon around the map and experience different sounds and their relative "loudness". Each icon placed on the map also has an independent play/pause button, allowing for an inquisitive user to play each sound individually. Additionally, every marker on click will display metadata about its year, relative volume, and estimated decibels. The map lazy loads audio files only when a marker comes with a close distance in order to minimize bandwidth usage for the client and our EC2 instance.
Challenges we ran into
*It was taking an inordinate amount of time to clean the data *finding the best data for the project *Installing Librosa was painful as a llvmlite installation failed, requiring us to dive deep into the underlying code of that dependency.
Accomplishments that we're proud of
We think we found a great way to visually represent the power of sound in our sensor map. People often need to see things to believe it, and we feel the way we chose to represent it does a good job intuitively illustrating the potential danger that exists with noise pollution. While we didn't have enough time to test the model on all the data we found, being able to understand how the model worked on the surface level let us experiment and think about how best to move the project forward had we been given more time.
What we learned
With audio classification, the most challenging part is dealing with multiple true cases. While CNNs are well set up to account for this nuance, as they end with multiple different probabilities for each end neuron, the difficulty will be ensuring there is enough test data for the CNN to detect multiple true cases with a big enough differential for the false ones that there are limited false positives.
Built With
- amazon-data-exchange
- amazon-ec2
- jupyter
- leaflet.js
- librosa
- python
- sonyc
- tensor
- urbansound8k


Log in or sign up for Devpost to join the conversation.