-
-

Noema Logo
-
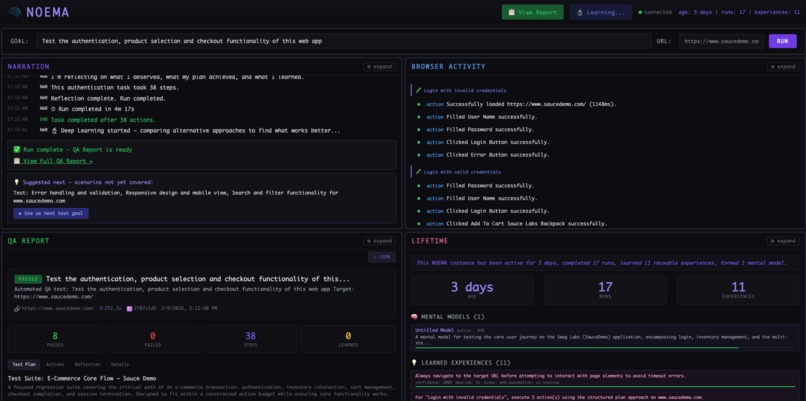
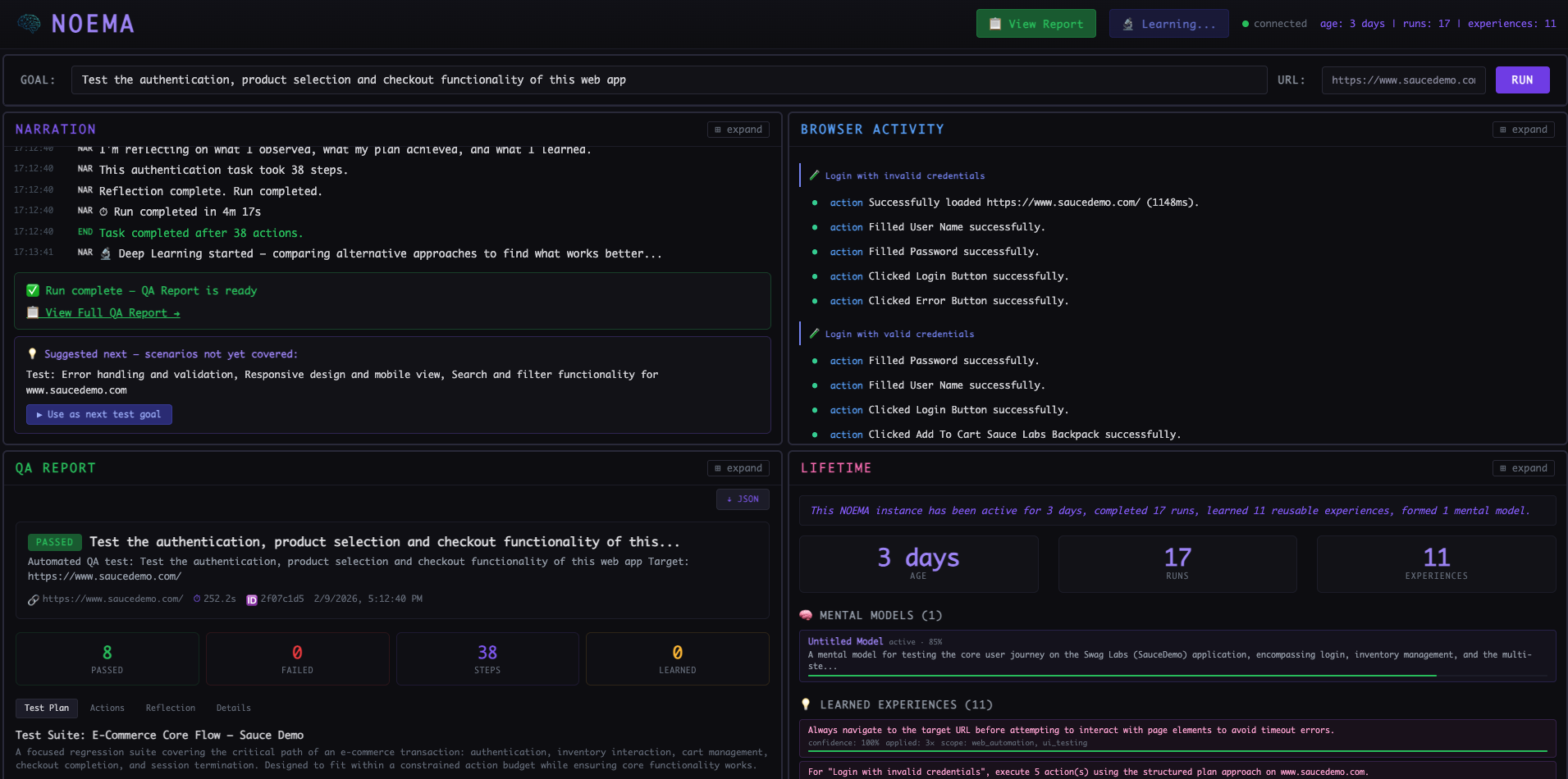
Noema Cockpit With QA report
-
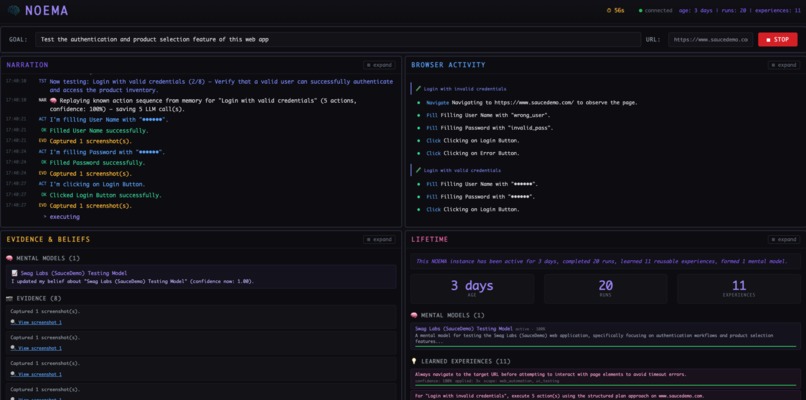
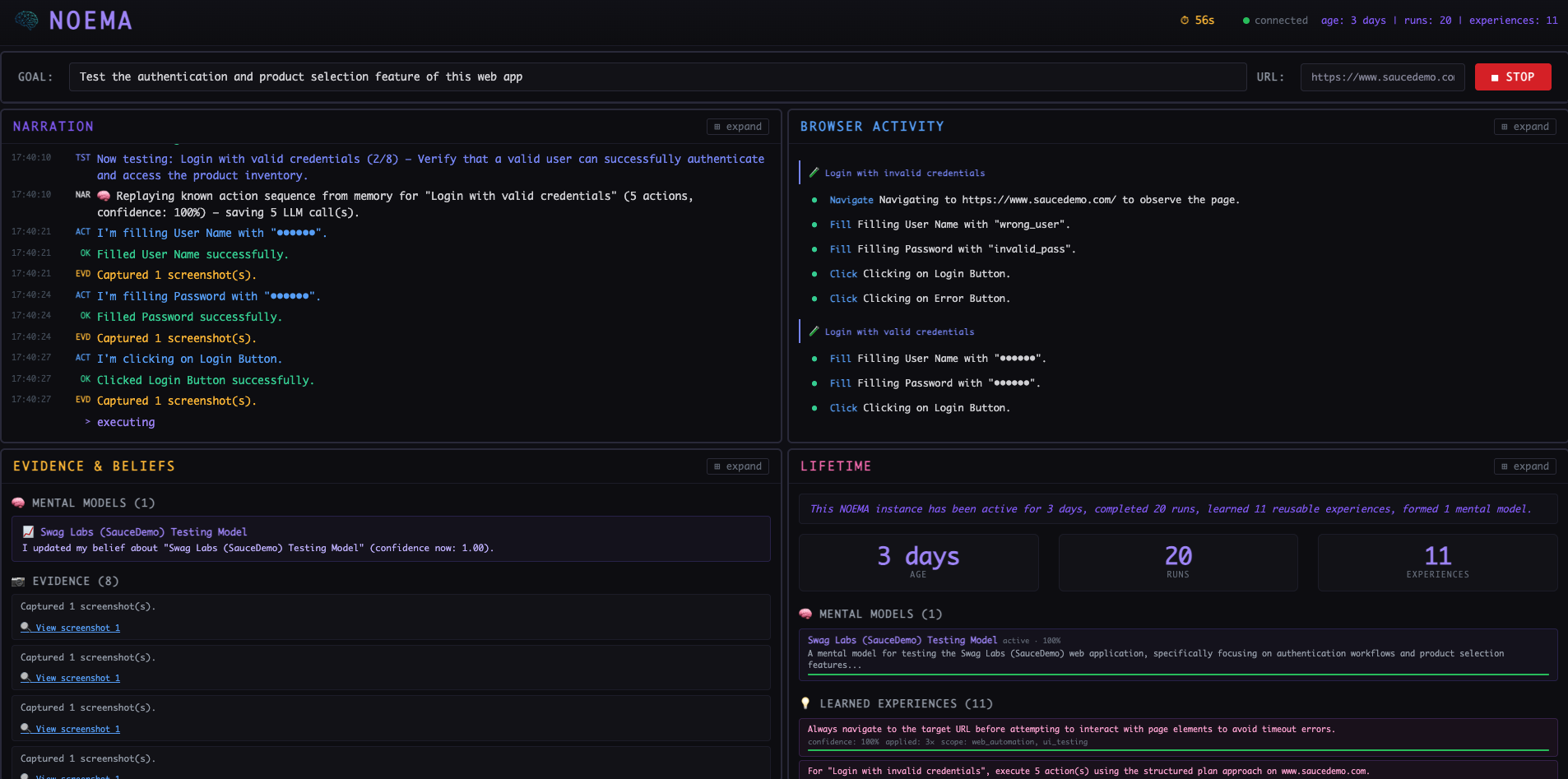
Noema Cockpit showing Thought Narration,Evidence and Belief formation, Browser Activity (For QA demo), and Lifetime.

Inspiration
Current AI agents are stateless. Every invocation starts from scratch — they can't remember what worked, learn from failures, or demonstrate measurable improvement. Even sophisticated agents with tool use chain-of-thought and lack persistence. We asked: what if an AI agent could accumulate experience like a human — remembering, understanding, planning, learning, and getting better at its job over time, without any model retraining?
The name NOEMA comes from Husserl's phenomenology — it means "the object of thought as experienced by the mind." We wanted to build a system where AI cognition is transparent, persistent, and inspectable — not a black box.
What it does
NOEMA is a cognitive architecture built on Gemini 3 that gives AI agents:
- Persistent Memory — Every observation, belief, and experience survives restarts. NOEMA's identity (age, runs, knowledge) persists indefinitely. On repeat runs, existing experiences are reinforced (confidence increases), cached plans are reused, and proven action sequences are replayed — directly reducing LLM API calls.
- Belief Formation — Raw inputs (text, screenshots, DOM) are transformed into structured Mental Models with confidence scores, evidence links, and typed relationships (depends_on, explains, contradicts). Beliefs are updated every run — new models are created, existing models have their confidence adjusted based on new evidence.
- Plan-Driven Execution — Before acting, NOEMA generates a structured test plan using Gemini 3, informed by beliefs and past experiences. Each step has a title, priority, expected outcome, and failure indicator.
- Training-Free GRPO — Adapts Group Relative Policy Optimization to work without gradient updates: runs multiple approaches, scores them on 5 weighted criteria, extracts reusable heuristics, and injects them into future LLM prompts as "token priors."
- Gemini Vision Feedback Loop — After every browser action, screenshots are analyzed by
gemini-3-pro-image-preview, creating a visual understanding loop: Act → See → Decide → Act. Evidence (screenshots, DOM snapshots) is captured and streamed live to the cockpit. - Measurable Improvement — Each run records metrics. An Improvement Analyzer compares runs to detect fewer steps, fewer failures, and more experiences applied. Persistent memory (plan cache + action sequence store + experience reinforcement) directly reduces LLM API calls over time.
- Live Narration — NOEMA narrates its cognition in real-time — including belief formation, evidence capture, and experience learning as they happen. Unlike Chain-of-Thought (ephemeral tokens in one LLM call), every narrated belief is a real stored object, every action is persisted, and every experience influences future runs.
For the demo, NOEMA performs Software QA — navigating real websites via Playwright, testing login flows, form validation, and purchase flows — and produces detailed QA reports with per-step pass/fail results, screenshots, and video recordings.
How we built it
NOEMA is a full-stack system with 8 architectural layers:
Backend (Node.js + TypeScript):
- Persistent Storage — JSON file repositories with Zod schema validation (observations, mental models, experiences, graph edges, plan cache, action sequences)
- Sensing + Vision — Multimodal perception via text adapters, Playwright screenshot capture, and Gemini Vision (
gemini-3-pro-image-preview) for visual understanding - Cognition — Belief formation engine with confidence tracking, bounded deltas, evidence chains, and a typed belief graph. Models are created on first encounter and reinforced on subsequent runs.
- Plan Generator — LLM-driven structured test plan generation from goals, beliefs, and experiences
- Decision Engine — Gemini 3-powered action selection from 8 typed browser actions, with stuck-loop detection, action history tracking, and cached sequence replay from persistent memory
- Experience System — Training-free GRPO for deep learning (rollout comparison → multi-criteria evaluation → heuristic extraction), plus lightweight per-step extraction that creates new experiences or reinforces existing ones with confidence boosts
- Narration System — Event-based first-person narration streamed via SSE, covering actions, evidence capture, belief formation, and experience learning
Frontend (React + Vite):
- Single-page cockpit with 6 live panels: Task Input, Narration, Browser Activity, Evidence & Beliefs, QA Report (with Plan/Actions/Reflection/Recording tabs), and Lifetime
- SSE streaming for real-time updates, expandable panels, screenshot lightbox with arrow-key navigation
External Integration:
- Cognee (optional Python microservice) for semantic memory — similarity retrieval + auto-extracted graph context via LanceDB and Kuzu
- Playwright for real browser automation with video recording
All Gemini 3 calls use the REST API directly (no SDK dependency) through 5 dedicated JSON-in/JSON-out prompt pipelines: planning, belief formation, decision making, experience extraction, and reflection.
Challenges we ran into
- LLM response reliability — Gemini sometimes returns thinking text before JSON, truncates long responses, or hits rate limits. We built a shared utility with exponential backoff retry logic and robust JSON extraction that handles markdown-wrapped or truncated outputs.
- Action loop detection — The decision LLM would sometimes repeat the same action indefinitely (e.g., clicking a button that doesn't exist). We implemented stuck-loop detection that identifies repeated action patterns and forces the agent to move on.
- Performance optimization — Vision analysis (3-15s per screenshot) and belief updates were blocking the main execution loop. We made vision calls non-blocking (fire-and-forget) and moved belief updates to per-step instead of per-action, reducing total run time significantly.
- Persistent memory across execution paths — Cached sequence replays (from memory) needed to emit the same evidence and belief events as LLM-driven execution, so the UI stays consistent regardless of whether NOEMA is reasoning fresh or drawing from experience. Getting this event parity right required careful alignment of both code paths.
- Credential security — Test credentials needed to be available to the LLM for form filling but never visible in narration, the UI, or network traffic. We implemented environment variable injection with automatic masking.
Accomplishments that we're proud of
- Training-Free GRPO actually works — Experiences extracted from rollout comparisons measurably improve subsequent runs. The system learns without any parameter changes to the model.
- Persistent memory reduces LLM costs — Plan caching, action sequence replay, and experience reinforcement mean that repeated runs against the same target require progressively fewer Gemini API calls. On repeat runs, NOEMA replays proven action sequences from memory instead of calling the LLM — and reinforces the experiences that guided those sequences, increasing their confidence for future use.
- Genuine visual understanding — The Gemini Vision feedback loop gives NOEMA real visual awareness of what it's interacting with, not just DOM inspection.
- Transparent cognition — Every belief, experience, and action is a real, inspectable data object. When NOEMA says "I formed a belief," you can find that belief in storage, check its evidence, and trace how it influenced decisions. The Evidence & Beliefs panel streams these events live — including belief confidence changes and experience reinforcement.
- The narration is not Chain-of-Thought — We built an architectural distinction that judges can verify: CoT tokens vanish after an LLM call; NOEMA's narrated state persists, accumulates, and drives improvement.
What we learned
- You don't need gradient descent to improve. Persistent storage + structured extraction + context injection is sufficient for measurable learning. Even simple reinforcement (boosting confidence when an experience is confirmed) compounds across runs.
- Planning before acting transforms agent quality. Without a plan, the agent explores randomly. With a plan, it executes strategically and can evaluate step-level outcomes.
- Two-model architectures are powerful. Using Gemini 3 Flash for reasoning and Gemini 3 Pro for vision creates a complementary system where each model does what it's best at.
- Persistence changes everything. The moment an agent can remember across sessions, entirely new capabilities emerge: improvement tracking, experience reuse, cost reduction over time, and genuine identity.
What's next for Noema
- Multi-domain support — The cognitive core is domain-agnostic. Adding action adapters for code review, security auditing, data pipeline QA, and compliance checking.
- Collaborative agents — Multiple NOEMA instances sharing experiences and beliefs through a shared memory layer.
- Real-time learning — Streaming experience extraction during execution, not just after completion.
- Richer graph reasoning — Expanding the belief graph with causal inference and temporal reasoning.
- Production deployment — Migrating from JSON persistence to a production database while preserving the same cognitive architecture.
Built With
- cognee
- gemini-3
- gemini-3-flash-preview
- gemini-3-pro-image-preview
- kuzu
- lancedb
- node.js
- playwright
- react
- server-sent
- typescript
- vite
- zod

Log in or sign up for Devpost to join the conversation.