-
-

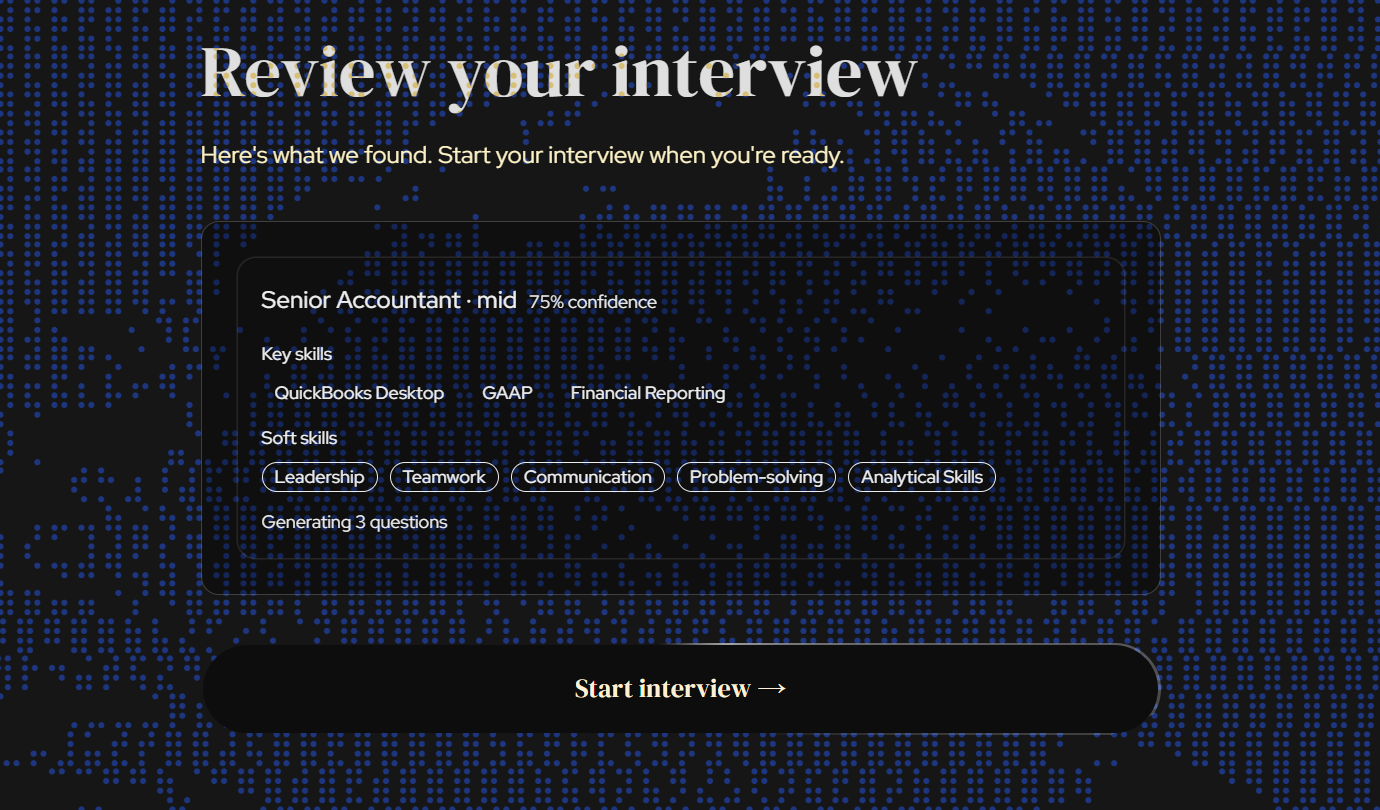
Landing Page
-
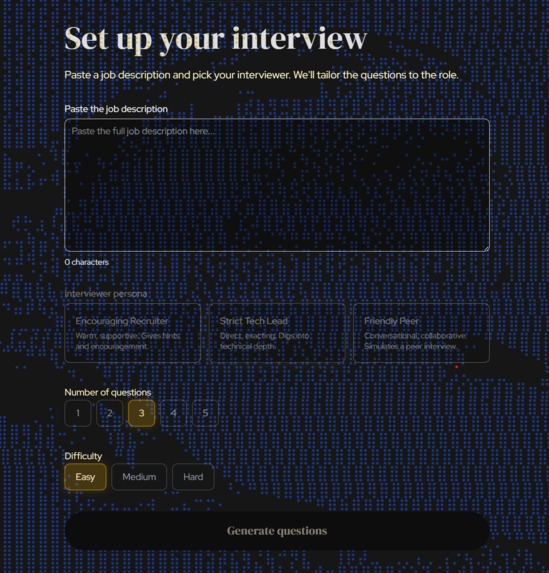
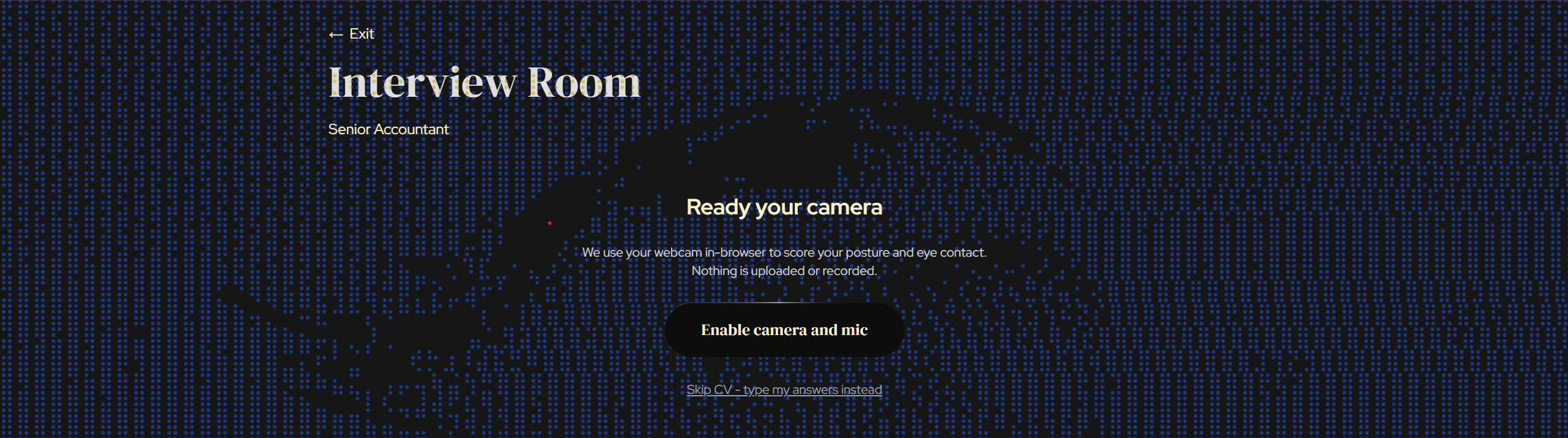
interview setup
-
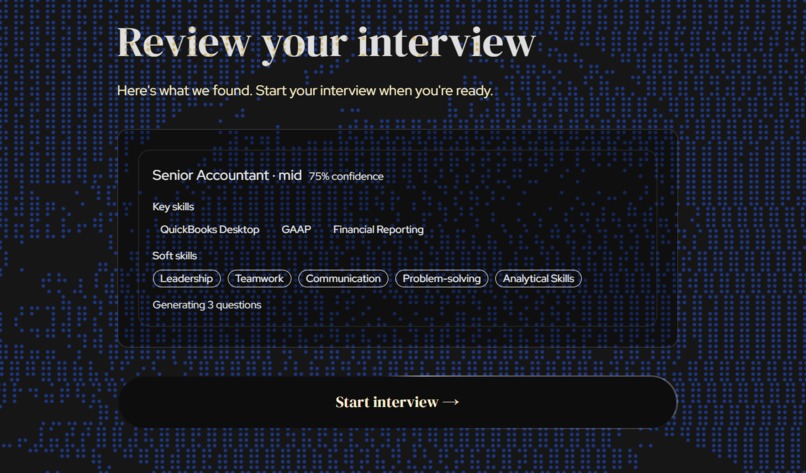
pre-interview overview
-

Permissions for camera and micorphone
-
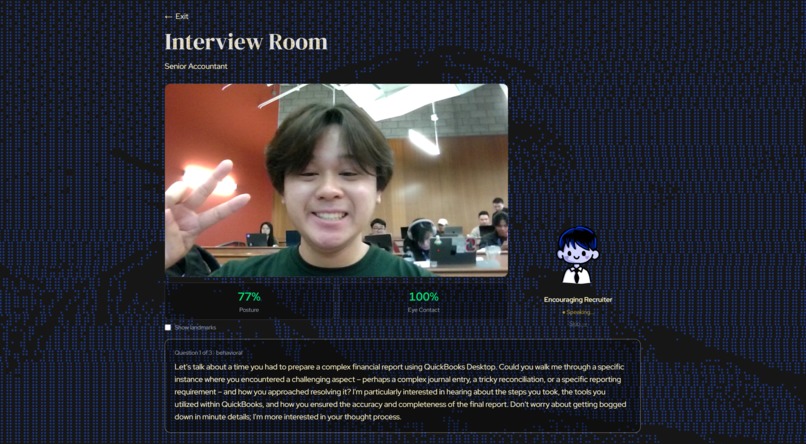
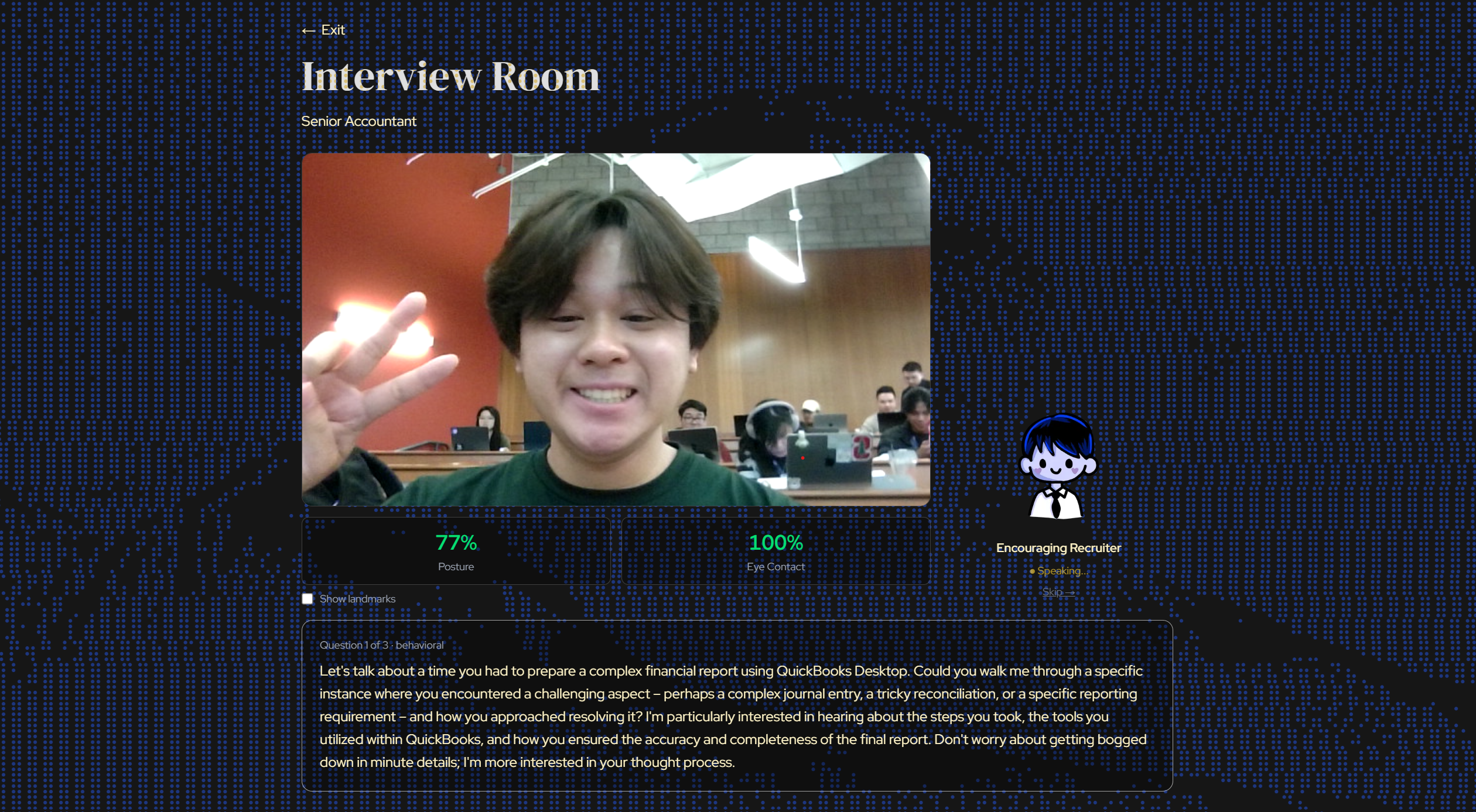
Interview room
-
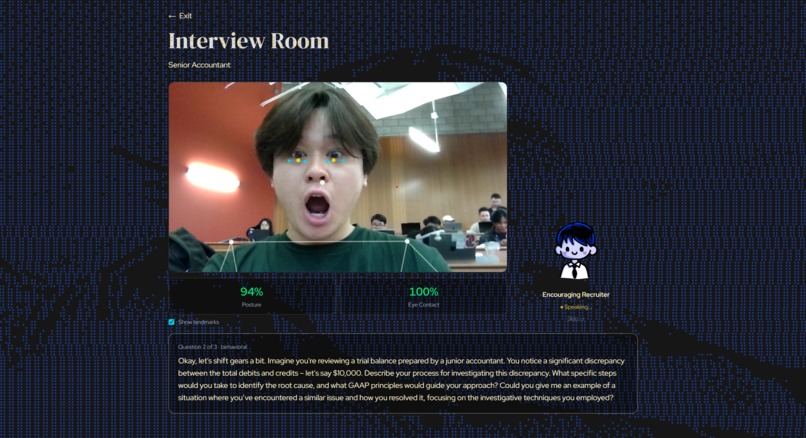
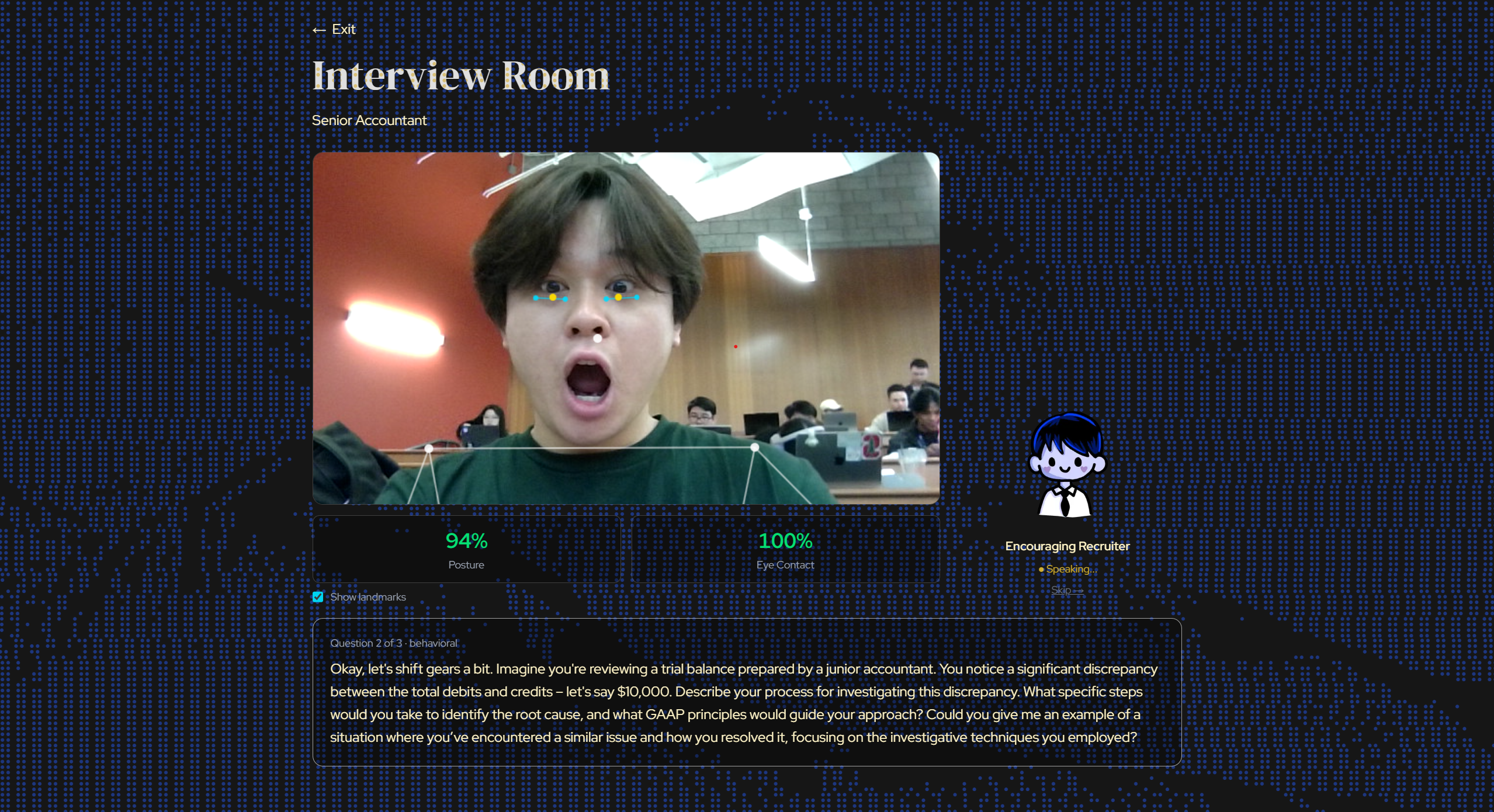
Interview room with landmarks
-
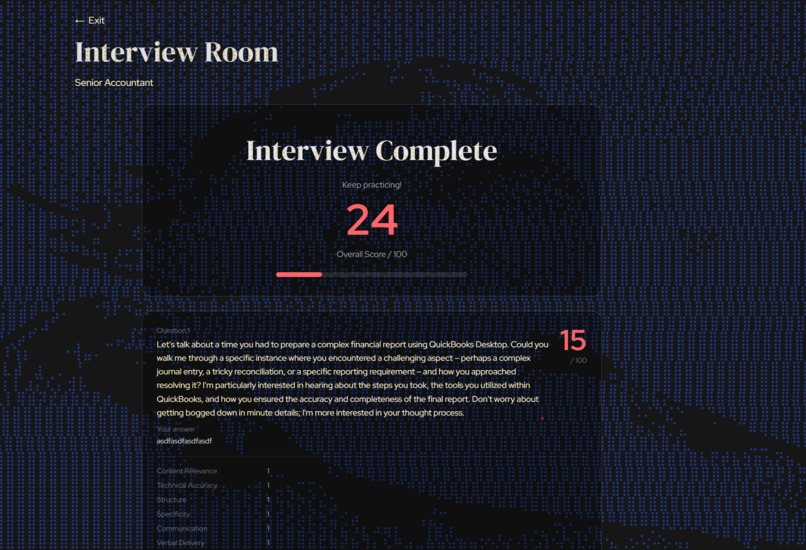
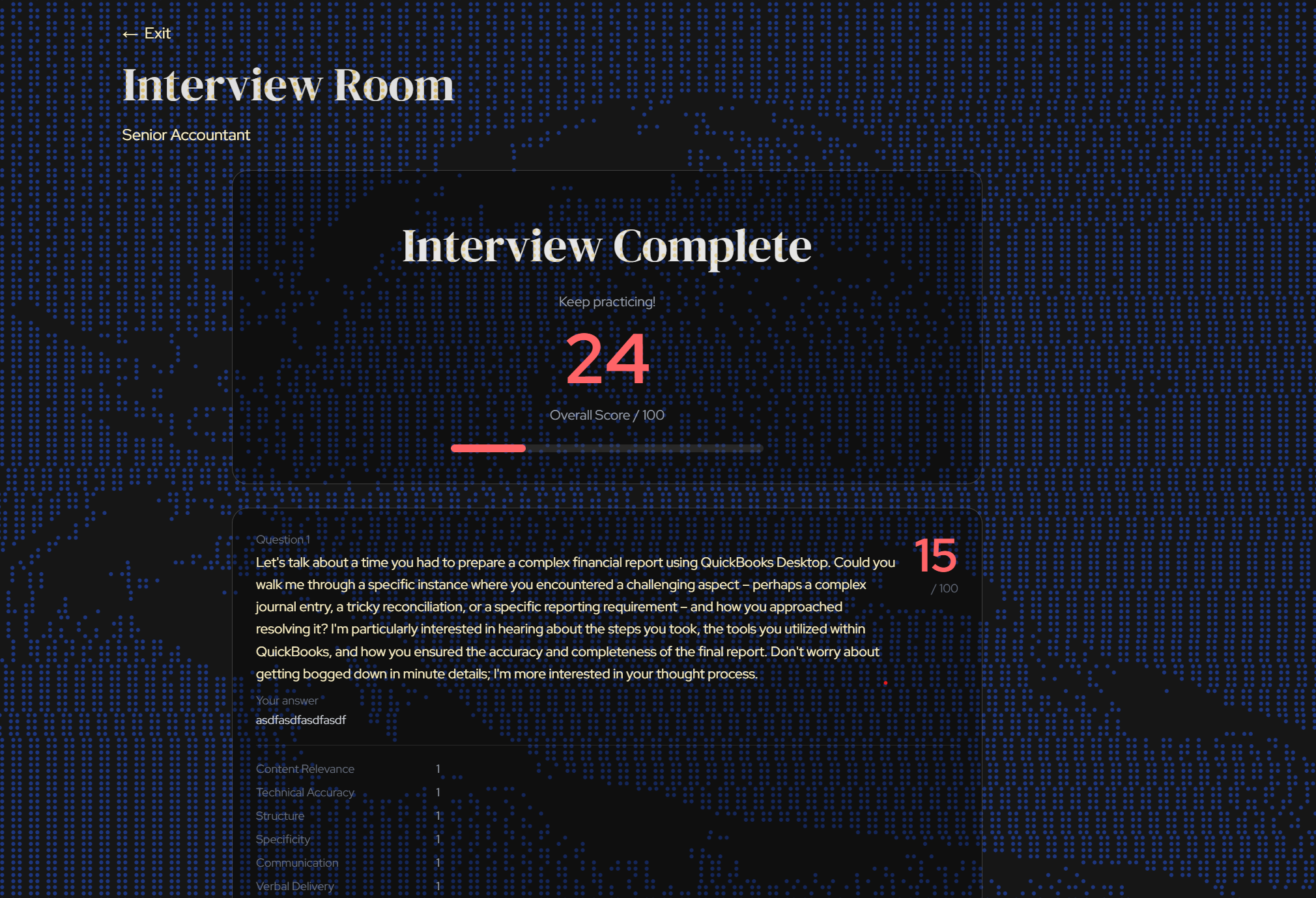
Interview Score
-
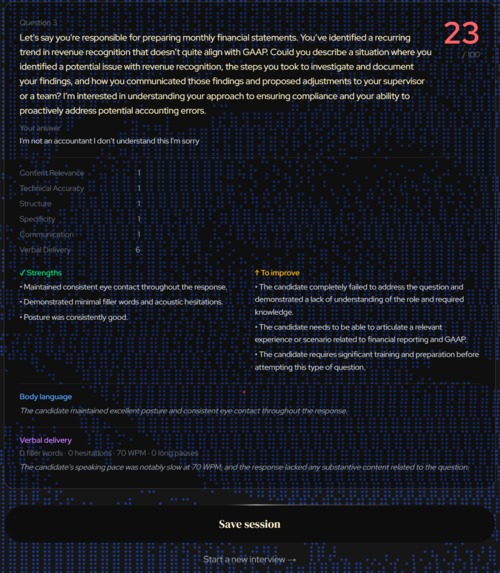
Question evaluation example 1
-

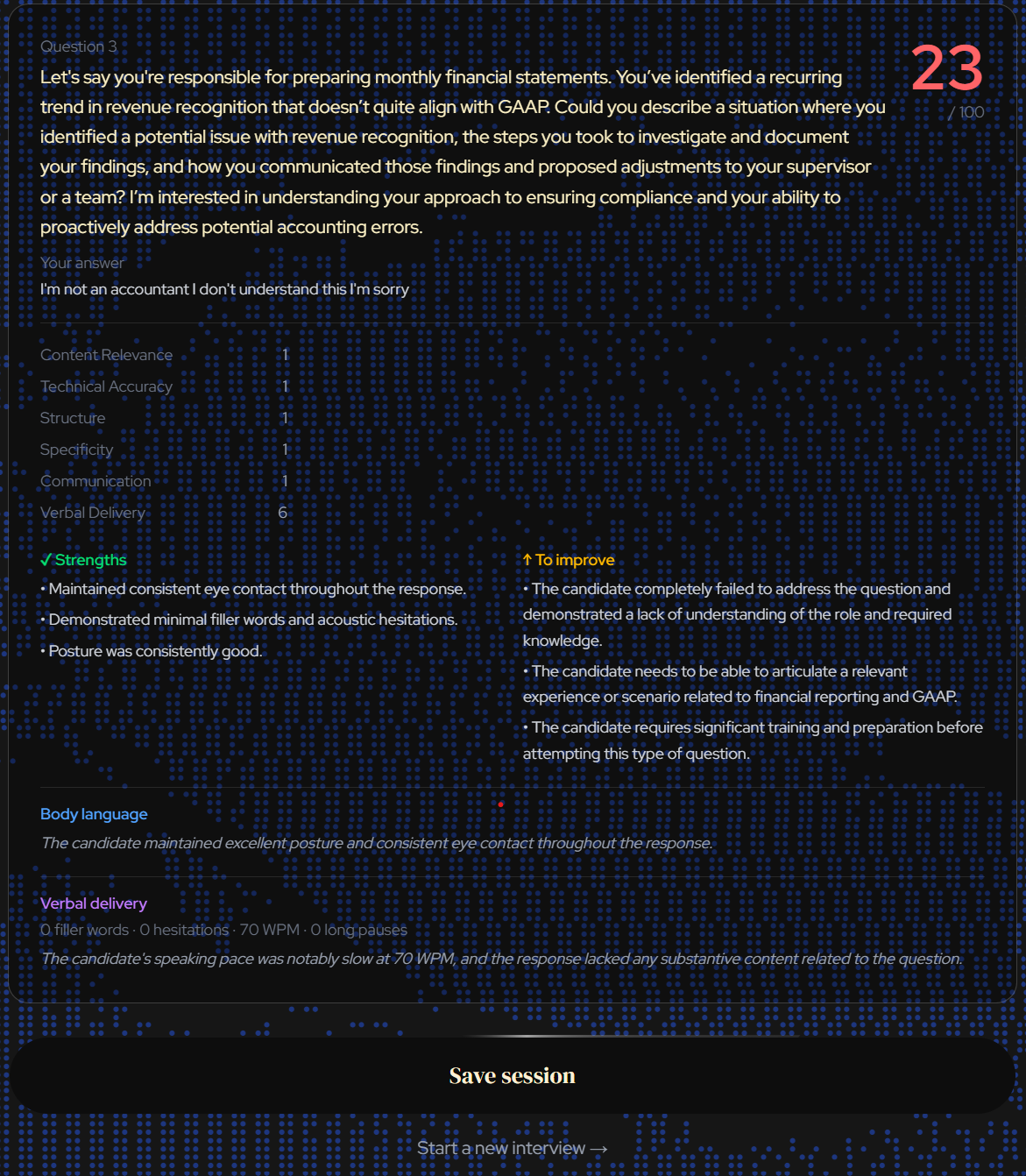
Question evaluation example 2
-
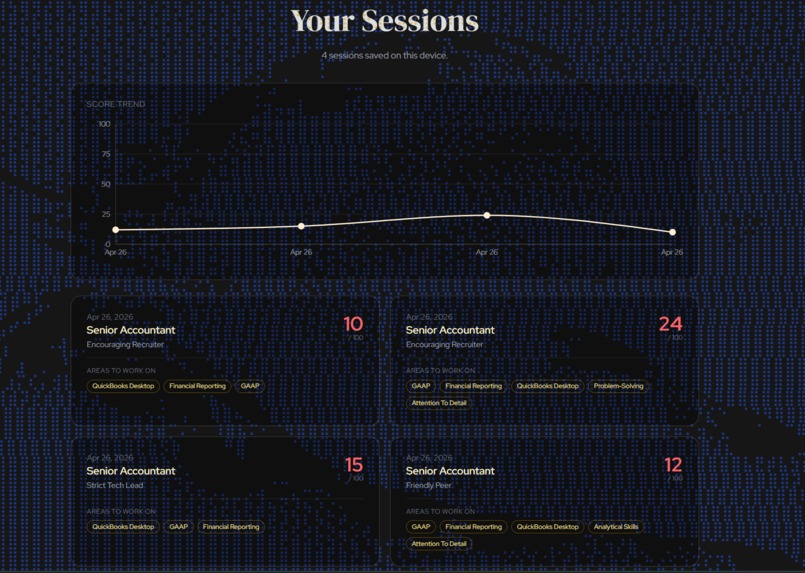
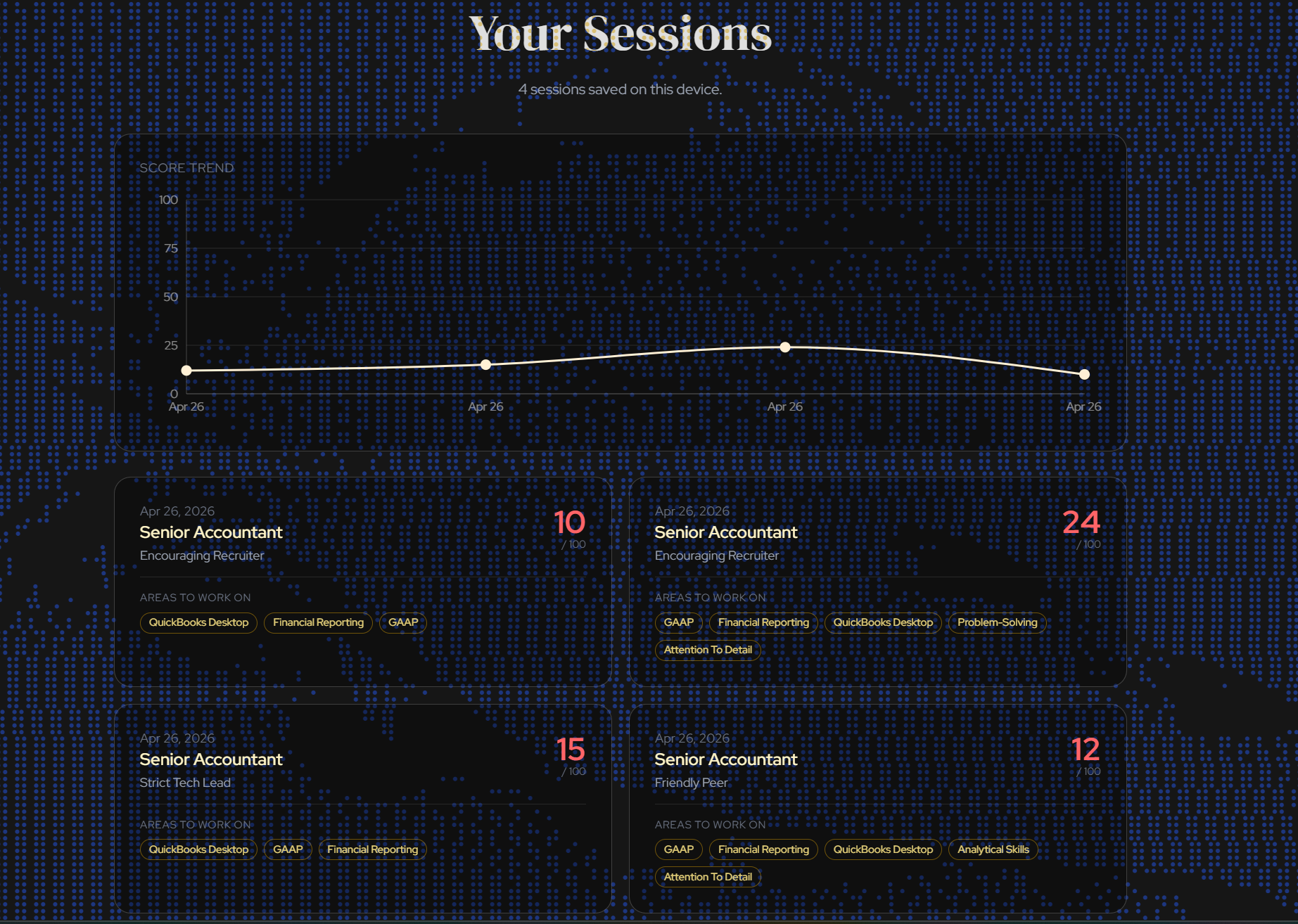
Session history

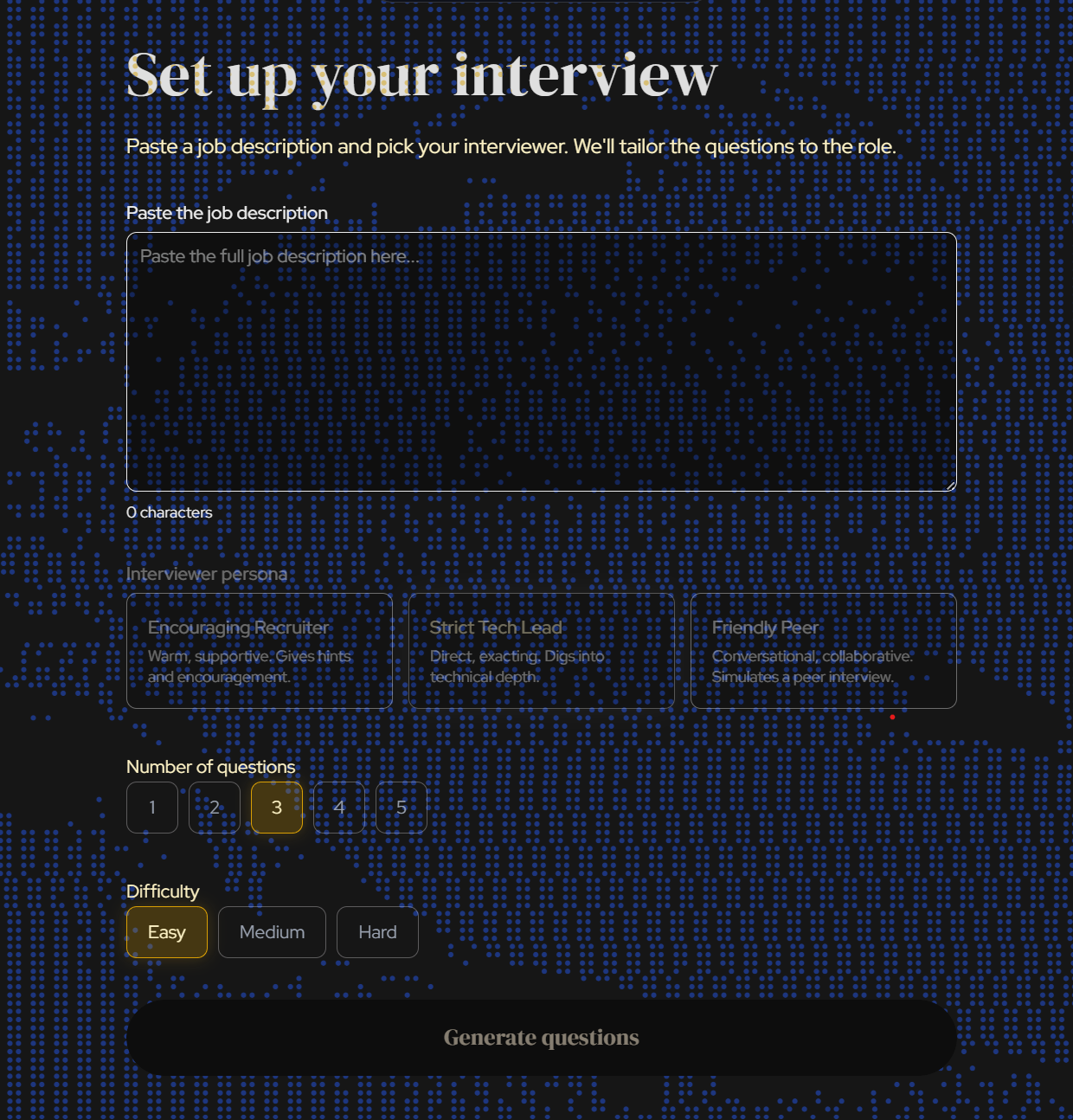

Inspiration
Mock interviews are expensive or awkward — career coaches cost money, and asking a friend feels uncomfortable. We wanted to build something that gives every student honest, private feedback on both what they say and how they present themselves, available anytime from a browser.
What it does
NodeBud AI conducts full AI mock interviews tailored to a job description you paste in. It listens to your answers, watches your body language through your webcam, and scores you across six dimensions: content, structure, technical accuracy, communication, verbal delivery, and non-verbal presence. After each interview you get a detailed score report with strengths, improvement notes, and a session dashboard that tracks your progress over time.
How we built it
We built on Next.js 16 with Tailwind v4 and shadcn/ui. All AI scoring runs through Gemma 4 via the Google Gemini API. We initially got Gemma 4 working end-to-end, but response times were too slow for a real-time interview experience, so we dropped down to Gemma 3 for production. ElevenLabs voices the interviewer in real time, with three distinct personas. Webcam analysis runs entirely in the browser using MediaPipe, where pose and face landmarks feed a custom heuristics pipeline that scores posture, eye contact, and stability without ever sending video frames to a server. Verbal delivery metrics (filler words, speaking pace, pauses) are collected via the Web Speech API and Web Audio API.
Challenges we ran into
Our biggest unexpected challenge was the Gemini API itself. We initially built around Gemma 4 and got it working, but response latency was too high for a conversational interview flow, with questions taking uncomfortably long to score and generate. We dropped down to gemma-3-4b-it, but then hit a new wall: the model rejected JSON response mode with a 400 error, and the TypeScript SDK types were inconsistent with what the API actually accepted at runtime. We had to strip out all JSON mode configuration and build our own extractJSON() helper that strips markdown fences, extracts balanced JSON from free-form output, and feeds it through Zod validation with an automatic retry before falling back to safe defaults. Losing JSON mode meant we had to lean entirely on prompt engineering to get structured output reliably.
MediaPipe added its own friction. Iris landmarks require a refineLandmarks: true option missing from the TypeScript types, so we had to spread-cast it to avoid a build error, and without it eye contact silently reports 0%. MediaPipe also predicts landmarks for off-screen body parts with falsely high confidence, so calibration had to check coordinate bounds rather than visibility alone. Posture scoring produced wildly different results based on camera distance until we normalized all thresholds against shoulder width. On Windows, Turbopack crashes on paths with spaces, and one --webpack flag later, we moved on.
Accomplishments that we're proud of
Shipping a full end-to-end interview product in 24 hours with voice, video, LLM scoring, and a persistence dashboard, with zero server-side video processing. The verbal delivery pipeline (filler words, speaking pace, pauses, and acoustic hesitations) runs entirely in the browser via Web Speech and Web Audio APIs, feeding directly into Gemma's scoring rubric as a named dimension alongside content and structure. The fallback system means the app degrades gracefully: no mic leads to typed answers, no camera skips CV, and TTS failure falls back to browser speech.
What we learned
Privacy-first architecture is worth the constraint. Keeping webcam frames in the browser simplified our backend dramatically and made Vercel deployment straightforward. We also learned how fragile LLM output parsing is in production and how much value a single well-designed retry and fallback layer adds. Hackathons reward ruthless prioritization: we cut several features and the app is better for it.
What's next for NodeBud
We want to make CareerPrep AI a complete interview preparation platform. First, users will be able to upload their resume and LinkedIn profile so Gemma can map their actual experience to the job description and give personalized coaching — pointing out exactly which of their past projects or skills to highlight in each answer rather than generic advice.
On the interview side, we want to add peer-to-peer mock interviews where two users interview each other and receive AI feedback on both sides. We also want a post-interview replay mode where the AI identifies your three weakest answers and runs targeted drill sessions until you nail them.
Longer term, we want a question bank organized by company, role, and difficulty, spaced repetition tracking so the app knows which competencies you consistently struggle with, and a mobile app so you can practice during a commute. The infrastructure is already minimal enough that most of this is a frontend and prompt engineering problem, not an architecture one.
Built With
- css
- elevenlabs
- google-gemini-api
- mediapipe
- next.js
- react
- shadcn
- tailwind
- typescript
- vercel
- web-speech-api




Log in or sign up for Devpost to join the conversation.