GroundTruth
Inspiration
Healthcare "deserts" are not always obvious from raw facility counts. A district can look covered because a dataset lists several clinics, while the actual evidence for the right type of care is thin, stale, duplicated, or unverifiable. The opposite can happen too: a region can look empty simply because the source data is incomplete.
We built GroundTruth around that distinction. The goal is to help planners find real healthcare access gaps without mistaking missing data for missing care. Instead of hiding uncertainty, the app makes confidence a first-class signal and turns low-confidence districts into field-verification workflows.
What it does
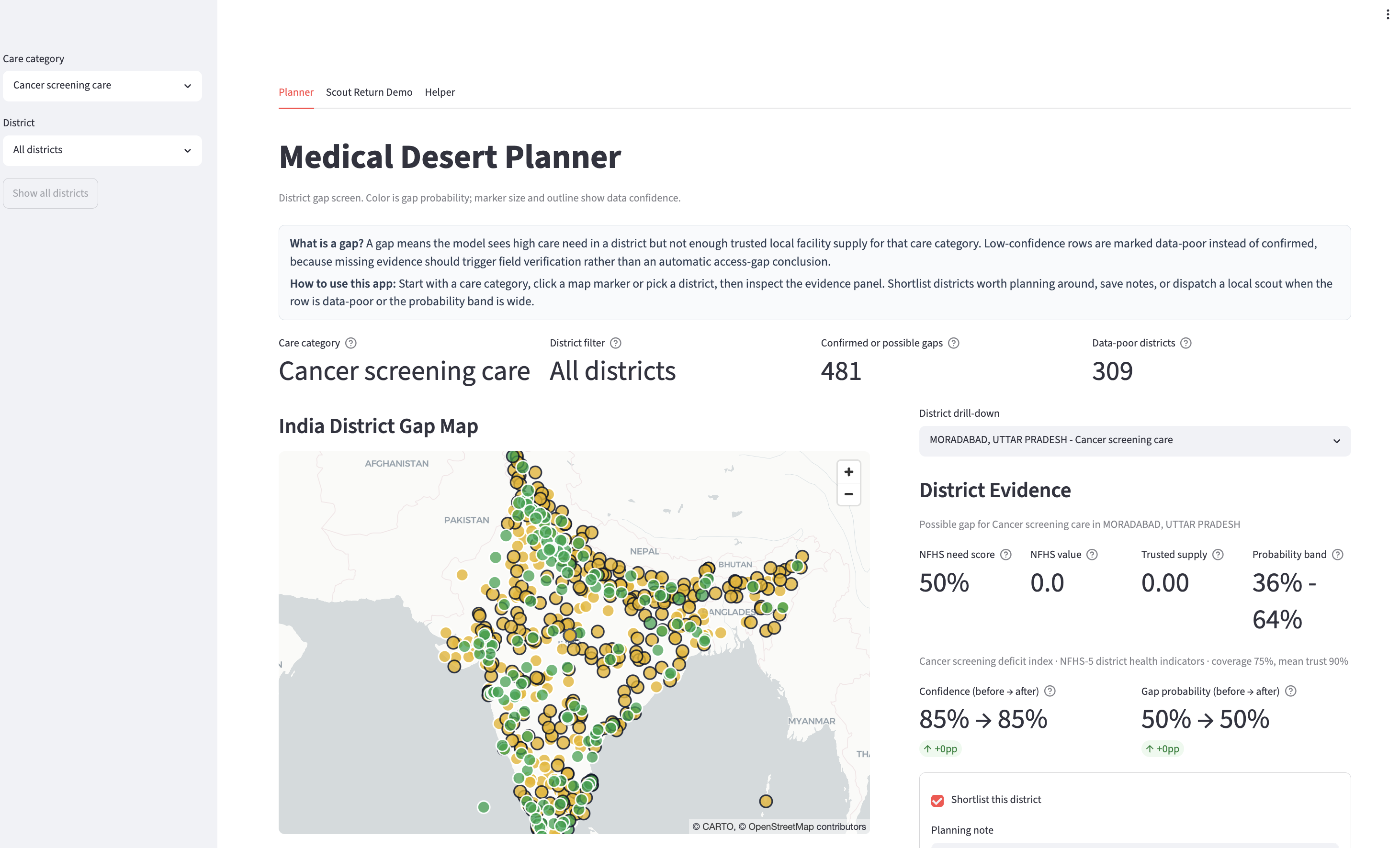
GroundTruth is a Databricks App for identifying medical deserts across Indian districts. A planner chooses a care category, explores an India map, reviews a ranked list of district gaps, and drills into the evidence behind each score.
For each district and care category, the app shows:
- modeled care need from NFHS-5 indicators;
- trust-weighted local facility supply;
- data confidence;
- gap probability and uncertainty band;
- facility-level trust signals and cited source spans;
- workflow state: confirmed gap, possible gap, covered, or data-poor.
The app also lets users save notes, shortlist districts, and dispatch a local scout for data-poor areas. A presenter-ready scout-return demo inserts a synthetic Rent A Human-style field report, runs incremental merge-back, and shows before/after changes in confidence and gap probability.
How we built it
We built the solution as a layered Databricks system, using agentic coding end to end. From 0 to 100, we relied on AI coding agents to generate, wire, test, and iterate on the implementation rather than manually writing code line by line.
The following describes the solution:
- Lakeflow Declarative Pipelines precompute the heavy scoring work into Delta tables.
- Unity Catalog stores the pipeline outputs and source-derived serving data.
- Lakebase serves low-latency app reads and durable
user_actionswrites. - Streamlit and pydeck power the Databricks App UI.
- The Databricks SDK triggers the scout-return merge-back path from the app runtime.
The pipeline starts by normalizing facility geography from the FDR facility dataset using Indian pincode and district references. It then scores facility trust from corroboration, verifiability, completeness, and claim specificity. Capability extraction maps facility text into care categories such as maternal care, child and immunization care, cardiac and NCD care, nutrition and anemia care, and cancer screening care, while keeping the cited source text used for each claim.
District scoring combines NFHS need signals with trust-weighted facility supply. The key design
choice is that supply and confidence stay separate: low confidence never becomes a confirmed gap by
itself. The app reads the resulting district_gap, facility_capabilities, and facility_trust
serving tables, then writes planner actions and scout lifecycle state back to Lakebase.
Challenges we ran into
The hardest product challenge was avoiding false certainty. It would have been easy to color every district with low observed supply as a gap, but that would punish places where the data is simply missing. We had to design the scoring, badges, map, helper copy, and drill-down around a strict invariant: data-poor means "verify," not "confirmed gap."
The data work had its own rough edges. Facility records can have messy pincodes, inconsistent district names, duplicated organizations, vague capability text, stale contact fields, and uneven coverage by region. We needed deterministic fallback logic, explicit schema contracts, and visible evidence so a non-technical planner could understand why a district was ranked.
We also had to wire a demo-ready system across several moving parts: Delta outputs, Lakebase serving tables, temporary Lakebase database credentials, Streamlit app runtime configuration, durable actions, Databricks App deployment, and the scout-return merge-back flow.
Accomplishments that we're proud of
We shipped an end-to-end workflow instead of only a dashboard. The app does not just point at a problem; it gives planners a way to save decisions, track scout dispatches, and feed field evidence back into the scoring loop.
We are proud of the confidence model and UI language. The app makes uncertainty visible everywhere: map markers, ranked cards, badges, probability bands, helper text, and before/after scout results. That keeps the workflow honest and makes data quality actionable.
We also expanded beyond a single proof-of-concept category. The pipeline and UI support multiple care categories without rewriting app logic, and the capability layer preserves cited evidence so the product remains explainable.
What we learned
The biggest lesson was that healthcare access planning needs two models, not one: a model of need and supply, and a model of how much to trust the evidence. Treating those as separate axes led to a better product than trying to collapse everything into one risk score too early.
We also learned that app architecture matters for demo reliability. Precomputing heavy work in Databricks and serving it through Lakebase kept the Streamlit app simple, fast, and stateless, while still allowing live planner writes.
Finally, we learned that human-in-the-loop verification is most useful when it is structured like data engineering. The scout form maps directly to pipeline fields, every field has an evidence type, and merge-back produces measurable changes in confidence.
What's next for GroundTruth
Next, we would harden the field-verification loop with a real Rent A Human integration, multiple independent scouts per district, stronger evidence review, and fraud-resistant consensus checks.
We also want to improve the model with travel-time analysis, facility capacity and staffing verification, freshness monitoring, richer demand and utilization signals, and calibration against observed scout outcomes.
Longer term, GroundTruth could support a volunteer verification network for public-interest health planning. Data-poor districts would become a queue of concrete evidence tasks, and every verified report would make the planner smarter for the next decision.
Built With
- databricks-sdk
- delta-lake
- geospatial-analytics
- lakebase
- lakeflow-declarative-pipelines
- pandas
- postgresql
- pydeck
- pyspark
- python
- streamlit
- unity-catalog

Log in or sign up for Devpost to join the conversation.