-
-

Our website automatically censors potential spoilers in posts and comments!
-

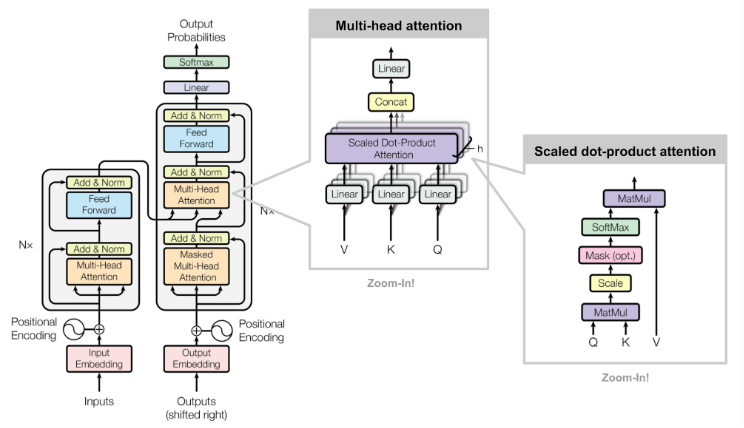
Figure 1. The BERT model relies on a self-attention mechanism to compute vector representations that capture semantic information.
-
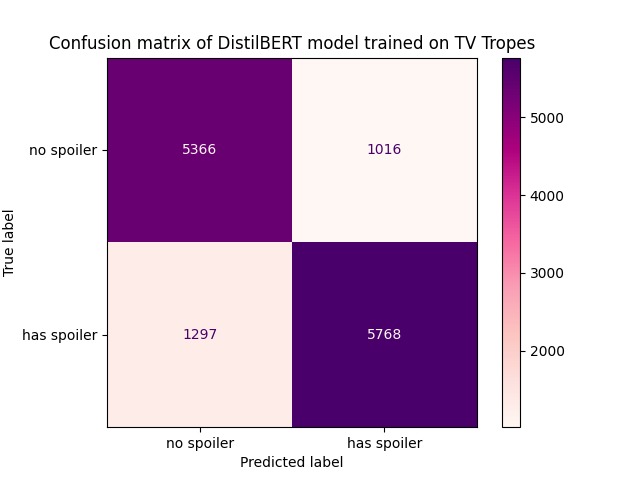
Figure 2. The confusion matrix shows that the DistilBERT model effectively discriminates between spoilers and non-spoilers.
-
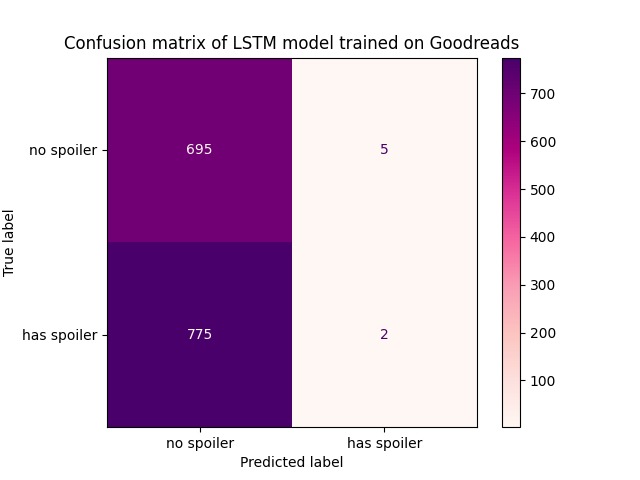
Figure 3. The confusion matrix shows that the LSTM model favors predicting negatively. This renders the model unfit for general use.
-

Figure 4. DistilBERT scores significantly higher than LSTM. Higher AUC means better ability to classify positive and negative samples.



Inspiration
It’s always a struggle to avoid spoilers for newly released games, even more so when it’s something you’ve anticipated for such a long time. Going around the internet becomes a nightmare when you constantly have to avert your eyes from potential ruination of your future experiences. This is what inspired us to create No Spoilers, a forum for discussing games that uses a state-of-the-art transformer-based machine learning model for natural language processing in order to detect and safely shield your eyes from spoilers. When someone posts about the final battle in the newest pokemon game, you can be shielded from unwanted information.
What it does
No Spoilers is a game discussion forum that allows users to make posts and comments about games. What makes No Spoilers unique is that it can automatically censor potential spoilers from posts in order to assure users that the content they read will be spoiler-free.
How we built it
Our website is built with a stack of React frontend and a Flask backend. We used MongoDB to keep track of all the posts that were created, including information related to the post like title, description, and whether the post contains a spoiler or not. The posts are fed into the machine learning algorithm which determines how much of a spoiler the message contains. If the algorithm determines that the message is a spoiler, then it is marked as such, and the message is hidden from direct view. The user can click on the message to view it, allowing them to see the spoilers that they want to without seeing unwanted spoilers.
The deep learning model is built off of the DistilBERT transformer model, a derivative of the state-of-the-art BERT model published by Google AI (Figure 1). We trained it on a publicly available TV Tropes spoiler dataset (Boyd-Graber et al. 2013) of 13,447 samples, 52.5% of which contain spoilers. This model takes in individual sentences as input and uses self-attention to extract latent semantic features from the text. It aims to predict whether or not the input sentence contains a spoiler, based purely on the semantic information in the sentence alone. We are able to achieve an impressive 83% accuracy on our test set without any other context. Figure 2 details our model’s ability to classify between spoilers and non-spoilers.
Challenges we ran into
We initially tried to train an LSTM model to make binary predictions for whether a sentence contains a spoiler. We used a dataset of reviews scraped from Goodreads, a social cataloging website for literature (basically Yelp for books). However, we discovered that this dataset was heavily negatively skewed; in other words, the dataset contains overwhelmingly more samples without spoilers than samples with spoilers. As a result, the LSTM model is trained on a biased dataset, and the model learned a classification scheme that took advantage of the skewed distribution (Figure 3). Finding this result unsatisfactory, we scoured the internet for publicly available datasets, and even attempted to scrape spoiler data from Reddit to generate our own dataset. Finally, we found the TV Tropes spoiler dataset from a University of Maryland paper, which contains a balanced distribution of spoiler and non-spoiler sentences. This dataset is perfect for our project! We also switched from using an LSTM model to a DistilBERT model to increase performance and trained our model with this new dataset (Figure 4).
Another issue we ran into was that our model was too slow! The time it took to process the text and detect spoilers ended up giving us more problems with our implementation, so we had to spend a lot of time implementing GPU support using CUDA libraries. We decided to favor the lightweight DistilBERT model over the original BERT model to allow us to make a responsive tool that we could use in real time.
The backend was another problem we faced with our project, as we had teammates who were new to database systems and working with MongoDB. Due to the large spread of our tech stack, there were also many conflicts with compatibility that took a lot of time to fix, and we spent a good deal of time integrating the components of our project.
Accomplishments that we're proud of
We managed to build and implement a working machine learning model that accurately determines if the inputted text is a spoiler or not. This was challenging as we were learning a lot about the topic as we implemented it and worked to make it functional. Many of our team members are also new to backend development, and as such we helped them learn about the topic as well.
What we learned
This was the first time we’ve attempted to train and implement a large scale machine learning model into a web development project. However, we were able to experiment a lot with different technologies and try a lot of different methodologies at the early stages of the project. The members of our backend team were able to familiarize themselves with Google Cloud Services, MongoDB, and Flask, which were tools that they had not used before.
What's next for No Spoilers
This project has been much more successful than we originally expected, and we hope to continue working on this project. We want to augment the current model with a knowledge graph containing contextual information from relevant franchises to better detect whether or not a piece of information is a spoiler. We were also impressed by the speed and performance of the model, and we believe that the application of the model as a browser extension would work on other sites with minimal impact on performance. Furthermore, the technology could be applied to streaming sites with live chats as an addition to regular moderation.










Log in or sign up for Devpost to join the conversation.