-
-
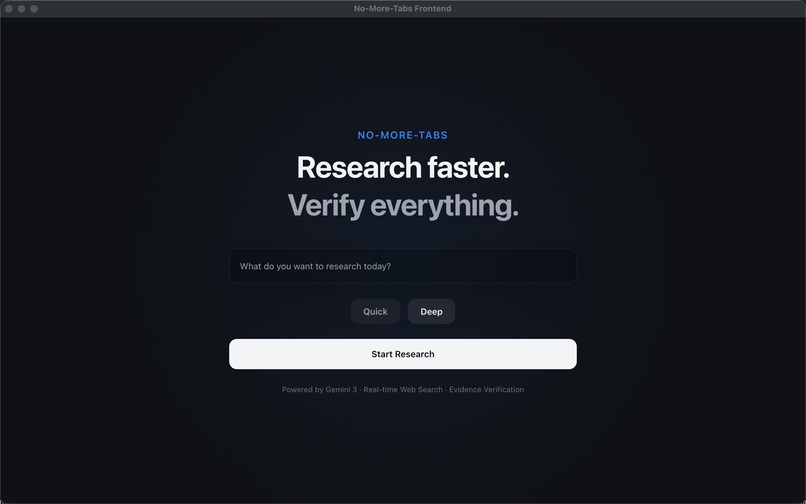
The searching bar
-
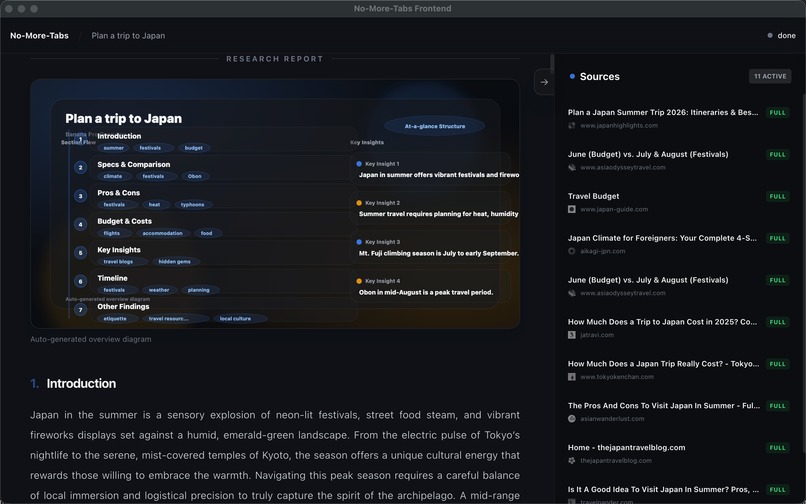
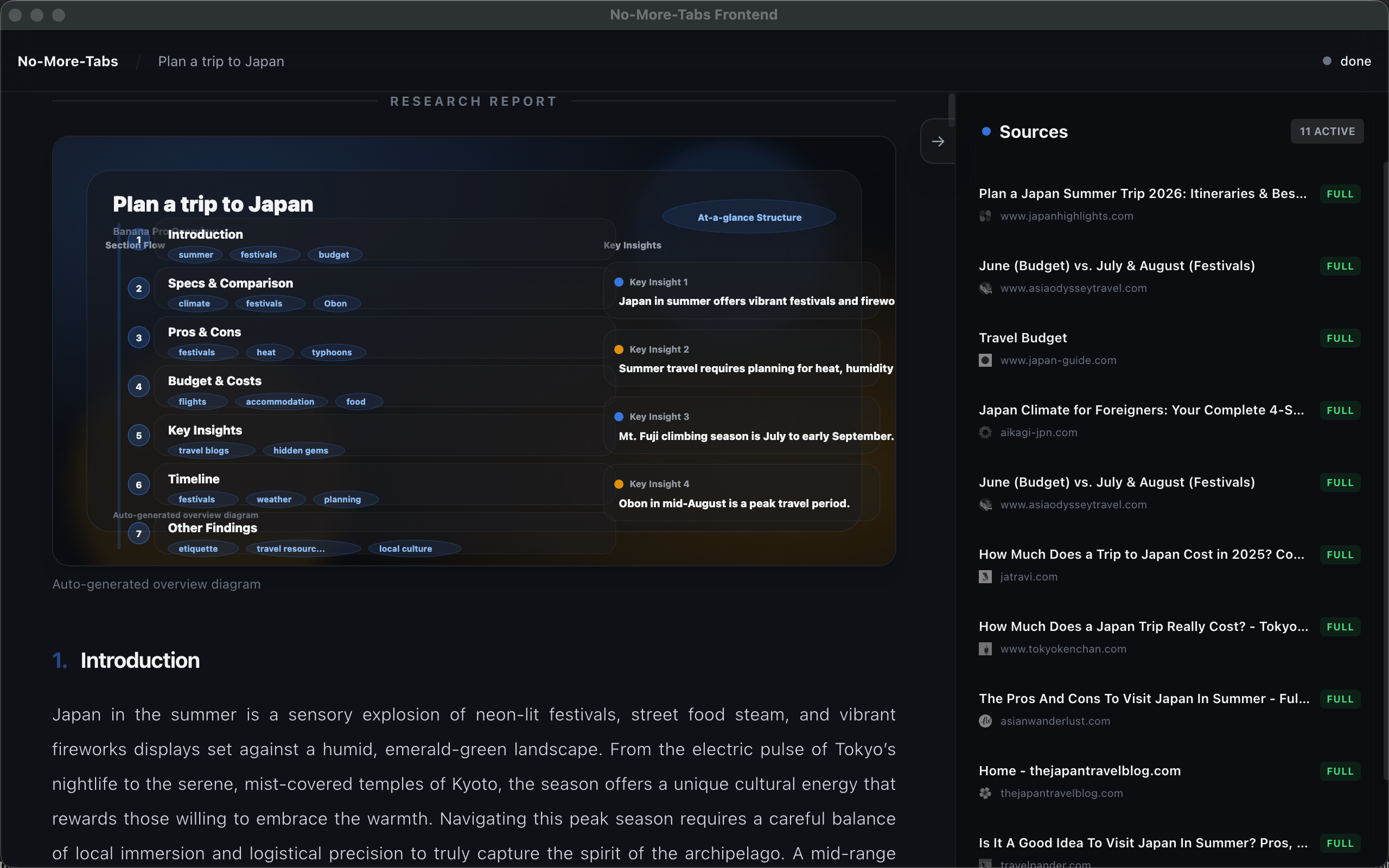
report
-
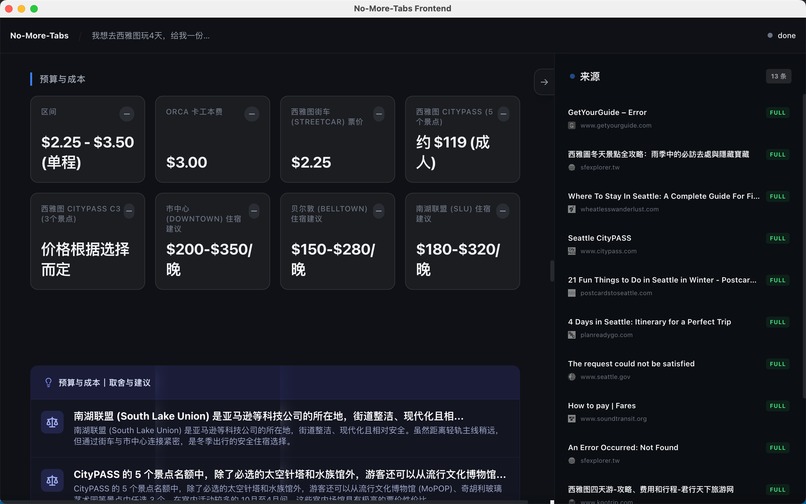
content of report
-
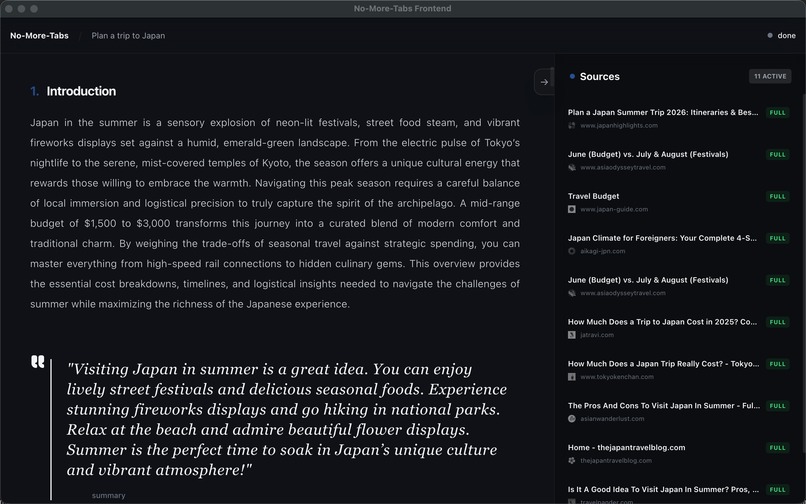
content of report
-
content of report
-
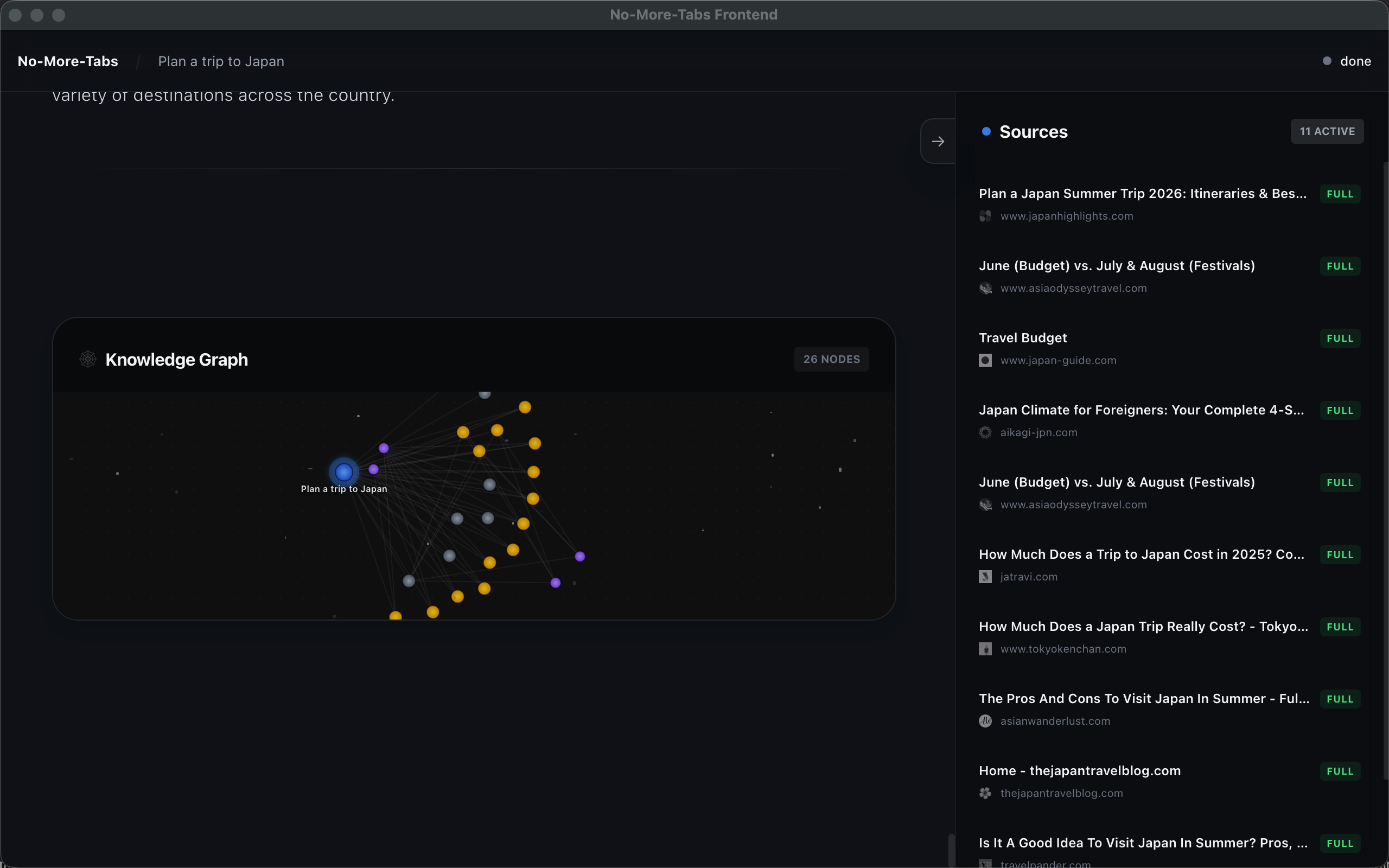
knowledge graph
-
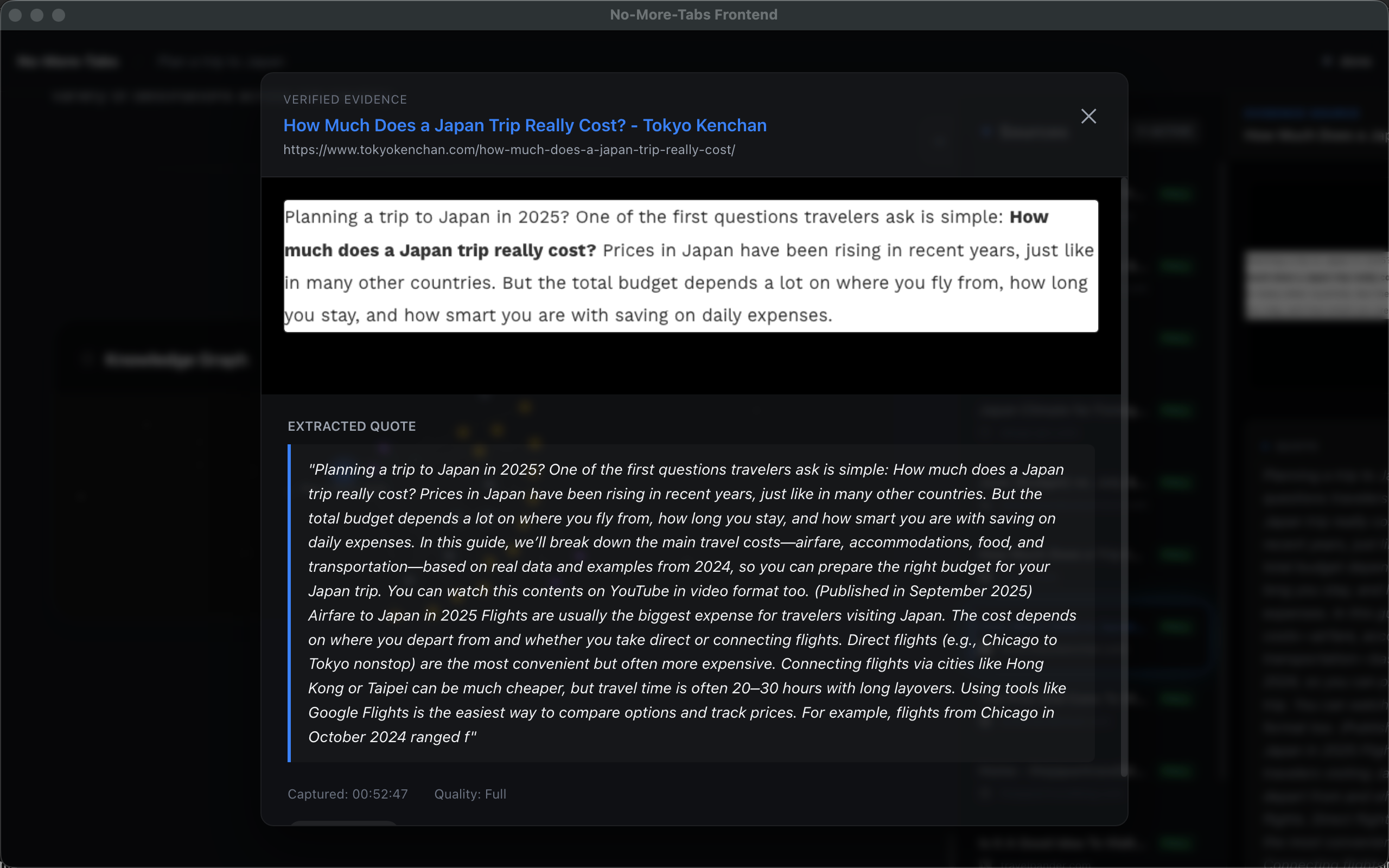
evidence
-
node
-
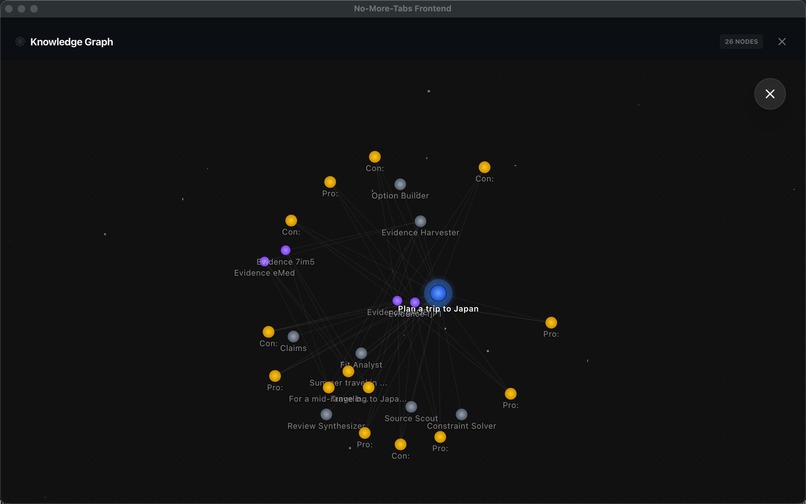
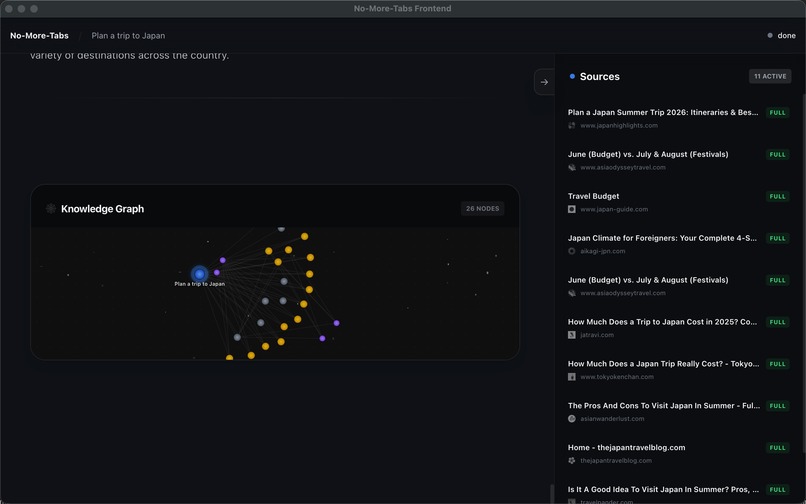
knowledge graph
Inspiration
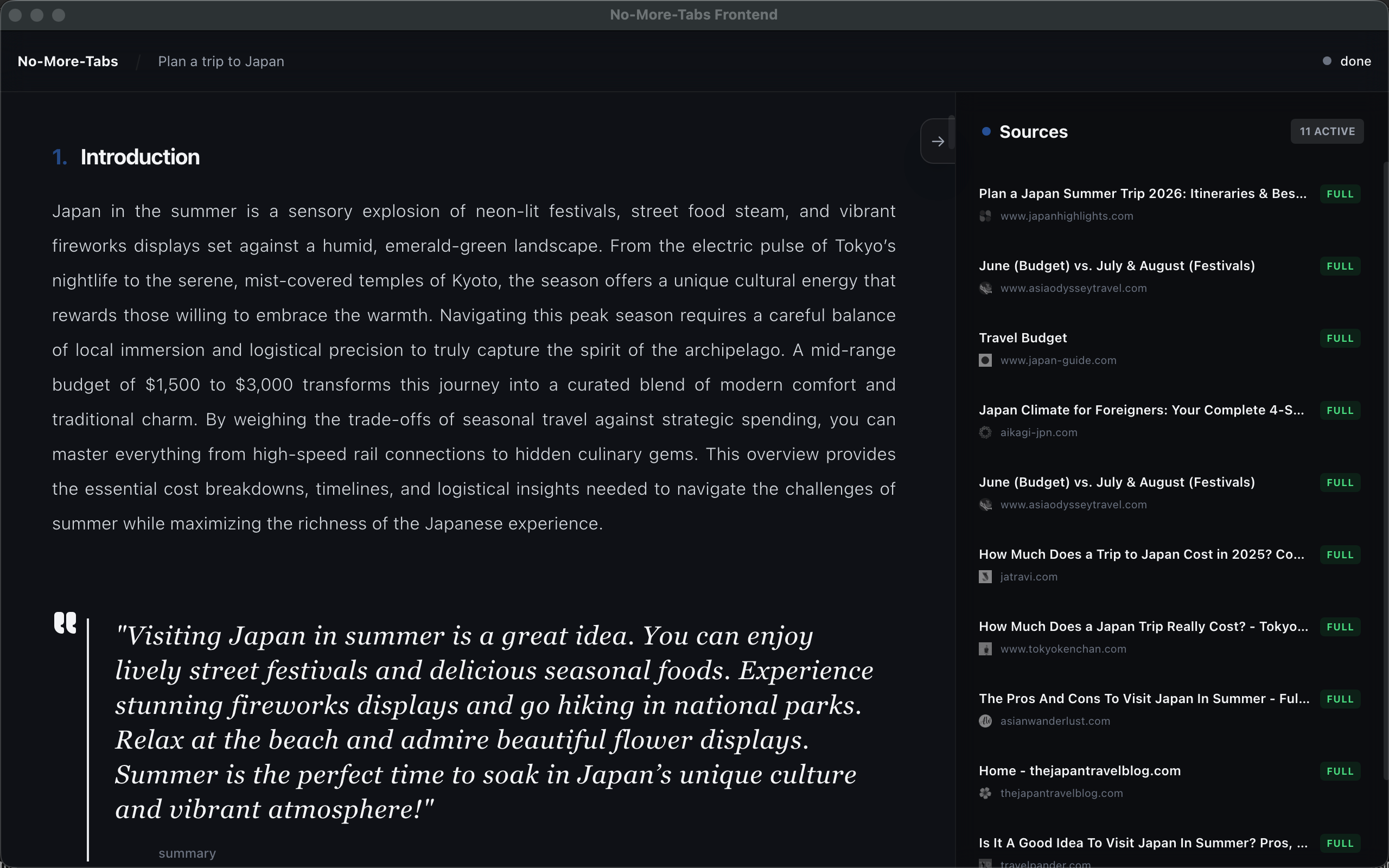
We started with a universal pain point: “Browser Bankruptcy.” You begin with one question, and 30 minutes later you’re drowning in 50 tabs—losing context, patience, and confidence in what you’ve read.
We also noticed something deeper: people still trust human-written blogs more than raw AI chat answers. Not because the prose is better, but because blogs come with structure and proof—screenshots, tables, links, and concrete receipts. Plain LLM output can feel like a black box.
So we built No-More-Tabs to combine the best of both worlds:
- AI does the browsing + synthesis
- The product outputs a visual, verifiable artifact (like a modern blog) backed by evidence you can audit
What it does
No-More-Tabs is a proof-first research runtime that turns a user’s intent into a secure, inspectable visual report.
Instead of “trust me,” it produces an evidence chain that users can verify quickly.
Product workflow (end-to-end)
A typical run turns a question into an auditable report in four steps:
- Plan & clarify: parse the user’s intent and generate a task graph (what to search, what to verify, what to compare).
If the request is underspecified or likely to drift, the system pauses early and asks 1–3 targeted clarifying questions (e.g., budget, constraints, must-haves) before proceeding — like a human consultant keeping everyone aligned. - Browse & collect: agents navigate pages, extract relevant passages, and capture full-page screenshots.
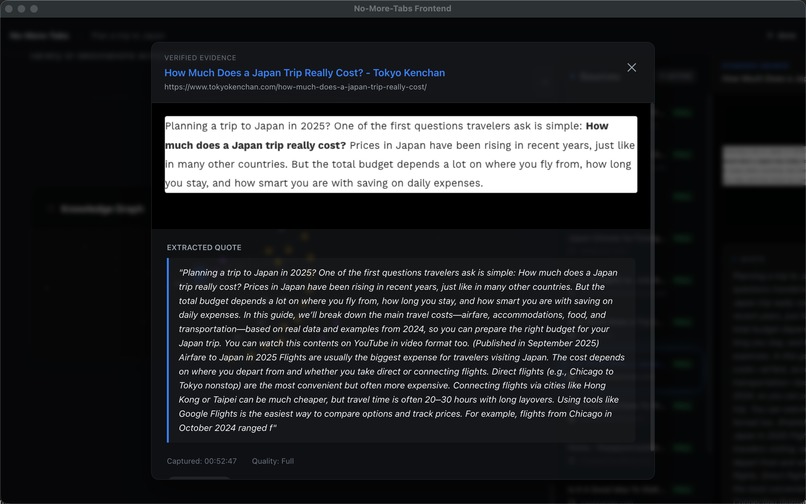
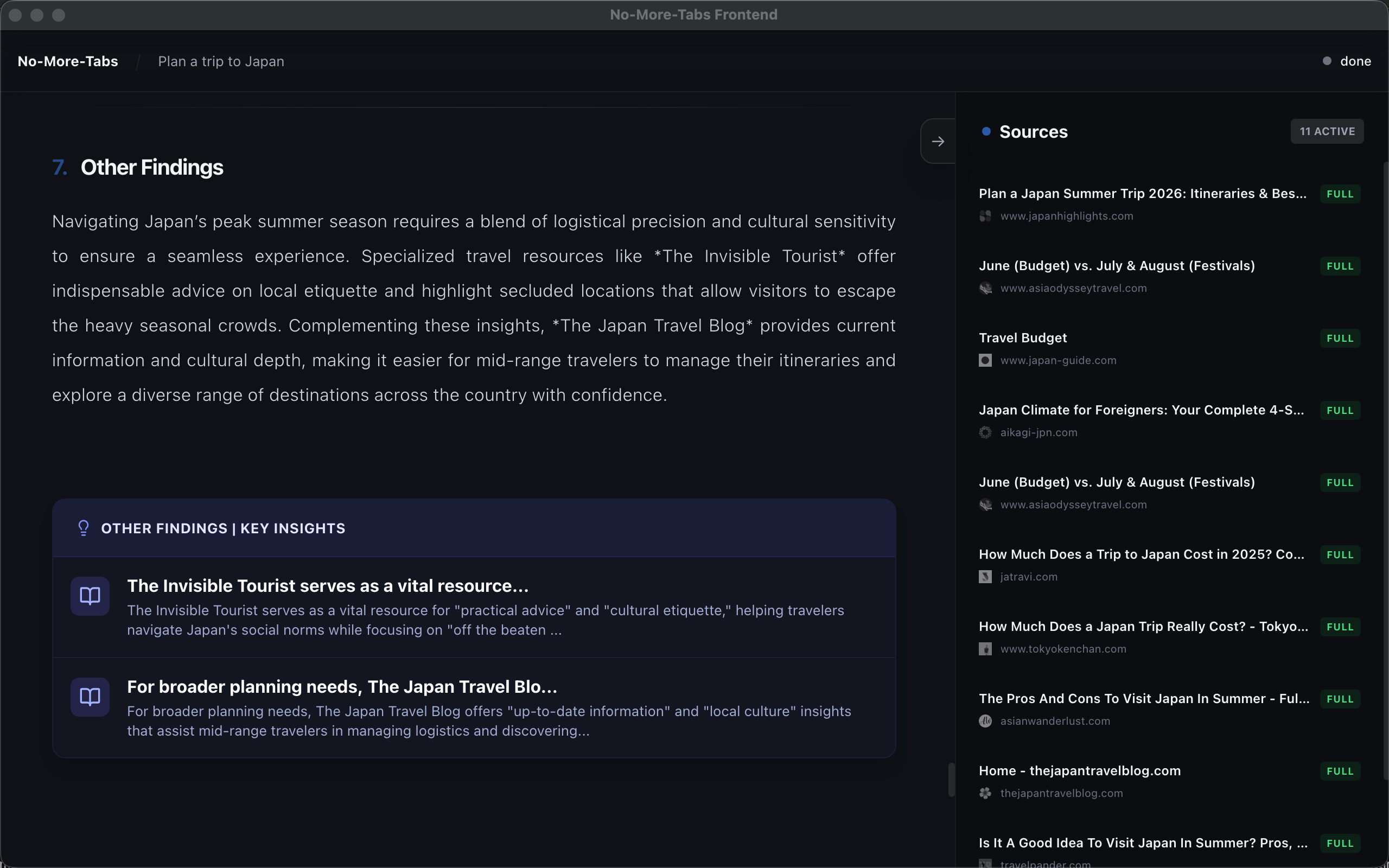
- Bind evidence: for non-trivial claims, the system attaches an EvidenceUnit (snapshot + source + highlighted snippet).
If evidence cannot be captured, it flags the statement explicitly rather than presenting it as a confident fact. - Render the Visual Artifact: the UI streams structured components as evidence arrives:
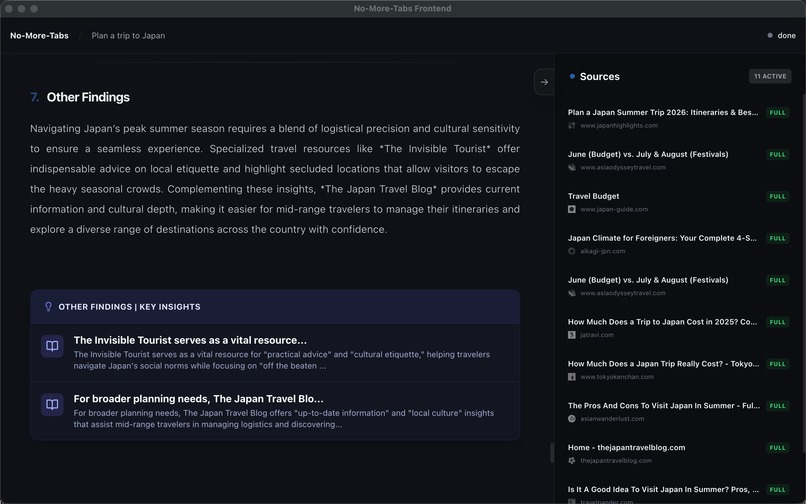
- pros/cons tables with linked citations
- conflict cards when sources disagree
- a source gallery for transparency
- hover-to-verify highlights for quick auditing
- a one-glance “one-pager” hero infographic (generated with Banana Pro) at the top of the report, summarizing the final recommendation, alternatives, key trade-offs, and top risks
Key features & functionality
- Quick vs Deep mode: Quick Mode produces a fast, lightweight report; Deep Mode runs the full workflow for thoroughness.
- Conflict-aware synthesis: when sources disagree, we preserve and present the disagreement with evidence anchors (not opinionated “one true answer”).
- Evidence-first UX: readers can jump from a claim to the exact highlighted region on the original page.
- Safety boundaries: navigation requests are validated before execution (e.g., blocking unsafe URL schemes / local targets) to keep browsing read-only and controlled.
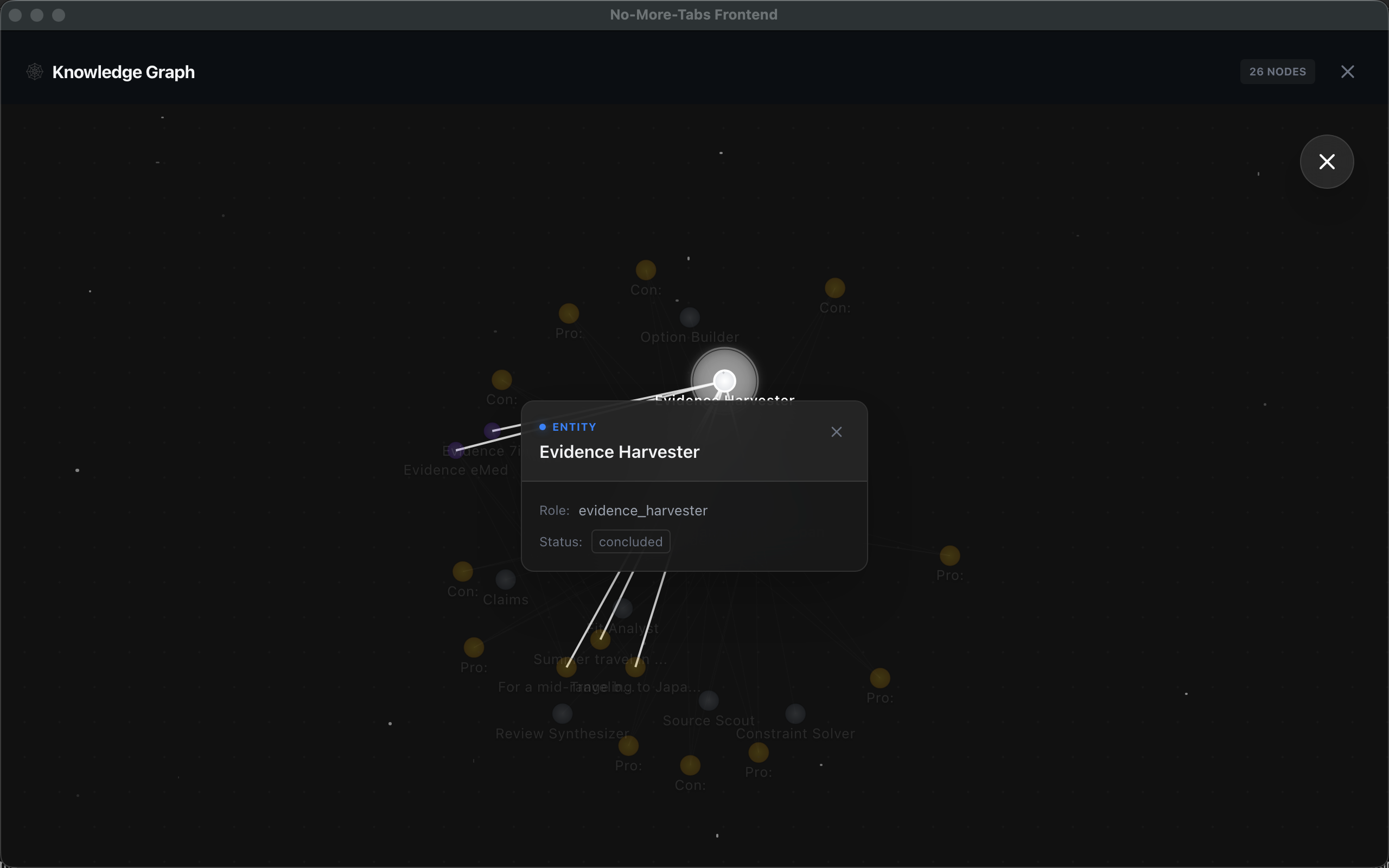
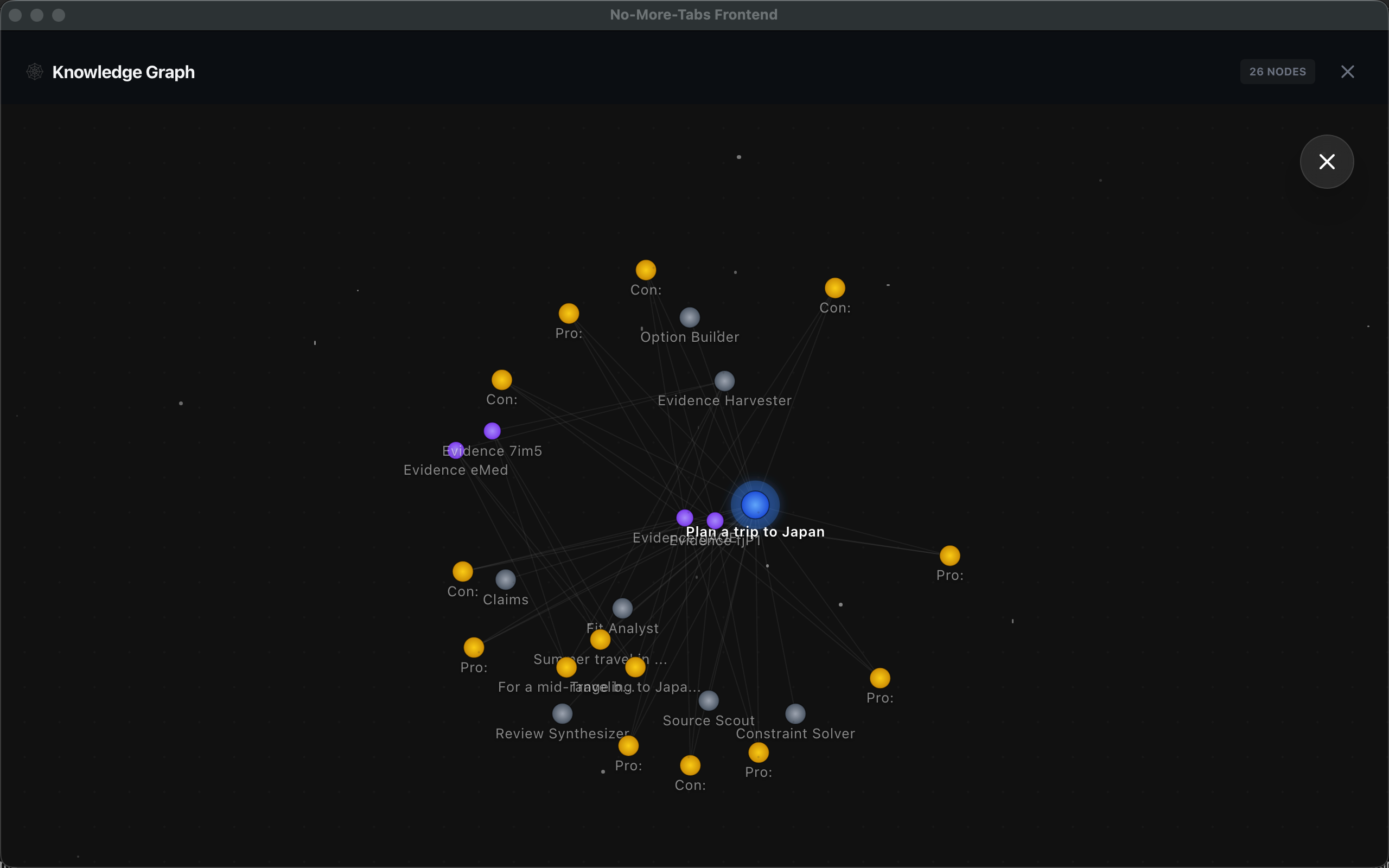
Core capability: multi-agent research (12 agents, orchestrated)
We moved beyond the “single bot” pattern and orchestrate a team that behaves like a human research group:
- Source Scout: finds diverse, high-quality sources (official docs, forums, reviews)
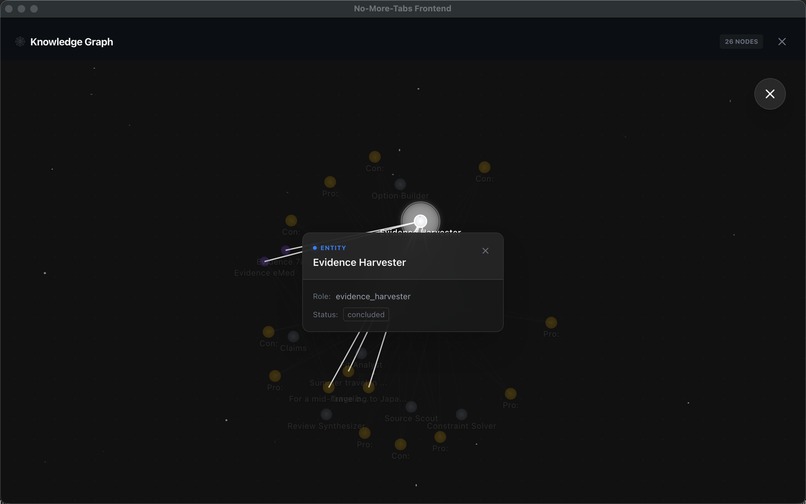
- Evidence Harvester: captures full-page screenshots and exact snippets as proof
- Option Builder: produces clear, comparable options with trade-offs
- Risk Auditor: challenges assumptions and flags contradictions / hidden costs
- Delivery Guard: enforces output quality rules before rendering
Trust layer (EvidenceUnit model)
We model verification as: [ \text{Claim} \rightarrow \text{EvidenceUnit} = (\text{snapshot}, \text{citation}, \text{highlight}) ] This makes it easy to audit key claims without leaving the report.
How we used Gemini 3 (specifically)
We used Gemini 3 Flash and Gemini 3 Pro for different roles:
Gemini 3 Flash (fast loops):
- source scouting and query refinement
- lightweight page digestion (extract “knowledge atoms” from noisy HTML)
- drafting candidate options quickly for downstream review
Gemini 3 Pro (deep reasoning / synthesis):
- conflict analysis across sources and identifying inconsistencies
- risk auditing (what could be wrong, missing, or misleading)
- final report synthesis with stricter evidence-linking expectations
Banana Pro (visual one-pager):
- generates a clean, blog-style single-page infographic from the finalized structured artifact (options, trade-offs, risks, evidence highlights)
- this “at-a-glance” cover sits on top of the final report so readers can understand the outcome before diving into details
Both models are invoked from our Node.js runtime, and results stream to the Electron UI via WebSocket events
(e.g., evidence.ready, artifact.updated) so the report renders incrementally in real time.
How we built it
We designed the system as a desktop-first research product with a streaming, evidence-driven runtime.
Architecture (high level)
- Frontend: Electron + Vite + React (desktop UI + real-time rendering)
- Runtime/Coordinator: Node.js + TypeScript (event-driven multi-agent DAG orchestration)
- Browsing & capture: Playwright (high-fidelity navigation + screenshot + extraction)
- Protocol: WebSocket event stream to keep UI synchronized in real time
(e.g.,run.started,evidence.ready,artifact.updated)
Why this design
- A DAG coordinator prevents agents from stepping on each other and supports retries/timeouts.
- A streaming renderer makes research feel “alive” (evidence appears as it’s found).
- The evidence model makes outputs inspectable and helps reduce hallucinations by making claims auditable.
Challenges we ran into
Balancing “Quick” vs “Deep”
Users sometimes want a fast answer, sometimes a full investigation. We implemented:- Quick Mode: a single optimized pass for speed
- Deep Mode: the full multi-agent workflow for thoroughness
Visualizing disagreement without confusing users
Sources often conflict. We iterated on UI patterns to make conflicts actionable:- “Source A claims X, Source B claims Y”
- each side anchored to evidence, not vibes
Defending against prompt injection from the open web
We learned that safety can’t rely on prompt instructions alone. The biggest progress came from enforcing constraints at the request/interception layer (validating navigation requests before execution).Keeping UI state consistent during streaming
When evidence and agent outputs arrive asynchronously, the UI can desync. We solved this with a strict event protocol and incremental rendering rules.
Accomplishments we’re proud of
- A stable multi-agent coordinator that runs as a controlled task graph (instead of chaotic loops)
- A streaming “Blog Engine” renderer that converts evidence JSON into structured UI components in real time
- Hover-to-Verify that makes verification low-friction by linking claims to highlighted source context
What we learned
- Context is currency: raw HTML is slow and noisy → we added a “knowledge atom” compression step before agents reason.
- Structure beats chat for complex research: users prefer reading an artifact over back-and-forth dialogue.
- Security must be enforced structurally: request-level controls matter more than “please ignore injections” prompts.
What’s next
- More visual widgets (pricing charts, feature matrices, richer comparison views)
- Video intelligence: extract evidence from YouTube reviews like text sources
- Self-healing task graphs: allow the planner to rewrite the plan mid-run when it hits dead ends
Built With
- electron
- evidence-based
- gemini-(flash-&-pro)
- multi-agent-orchestration
- node.js
- playwright
- react
- typescript
- vite
- websocket

Log in or sign up for Devpost to join the conversation.