-
-
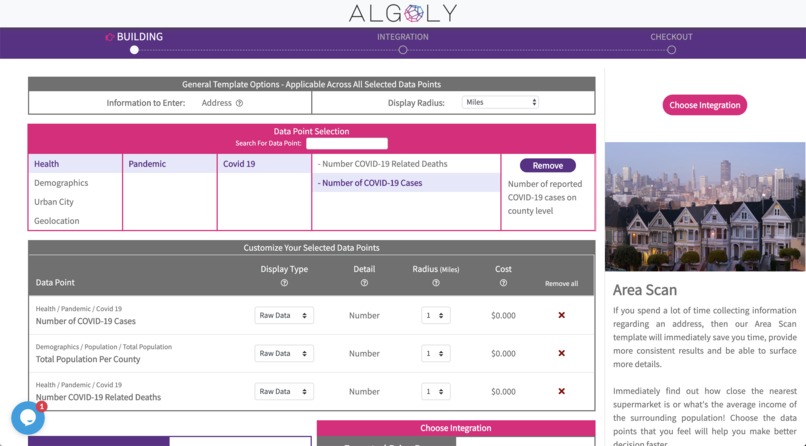
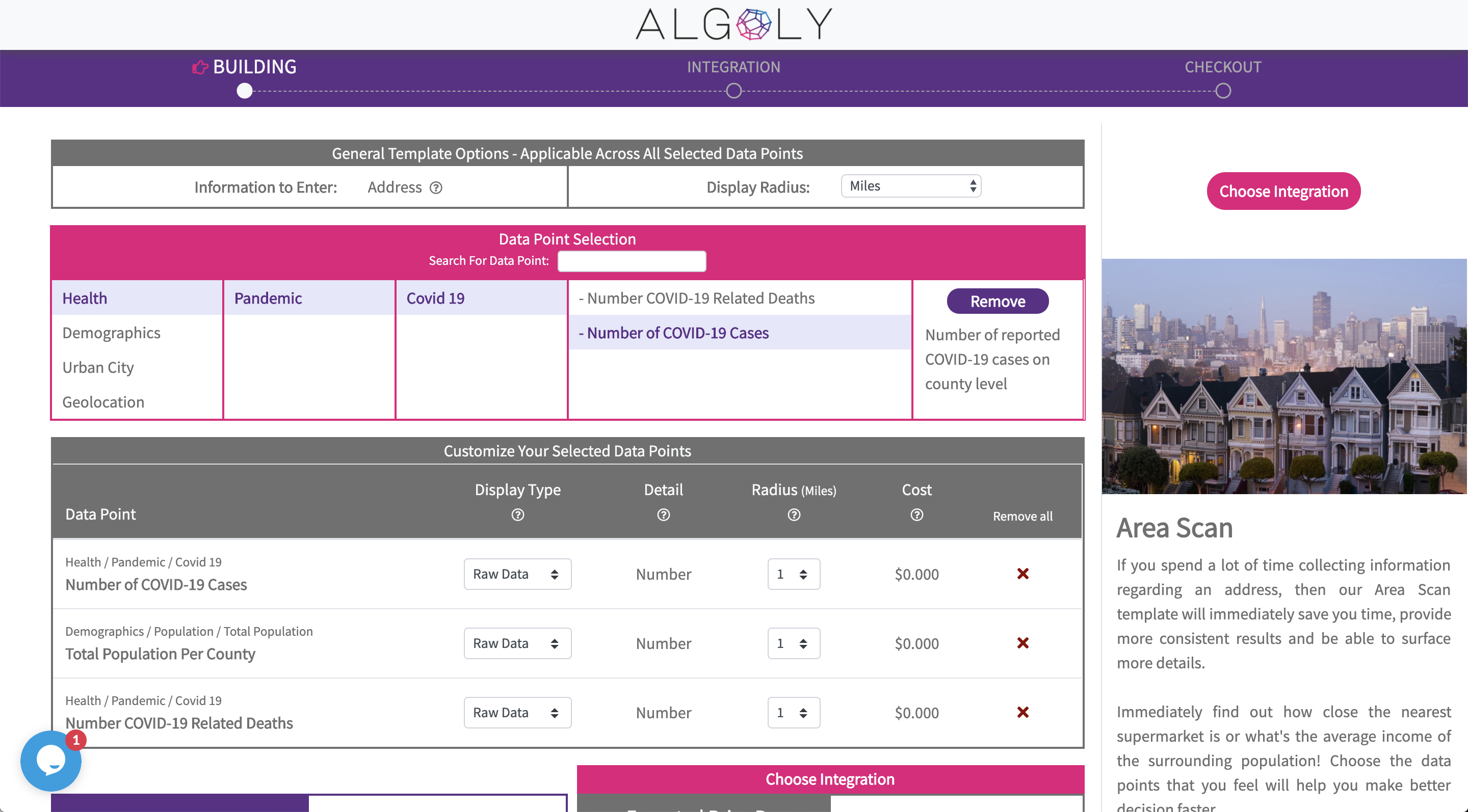
No-Code Data Point Selection Library with COVID-19 Data
-
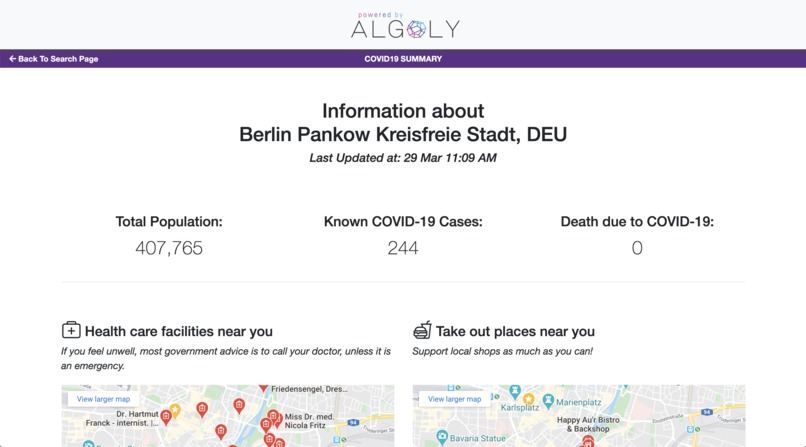
Example Application (COVID-19 Near Me Search Engine)
-
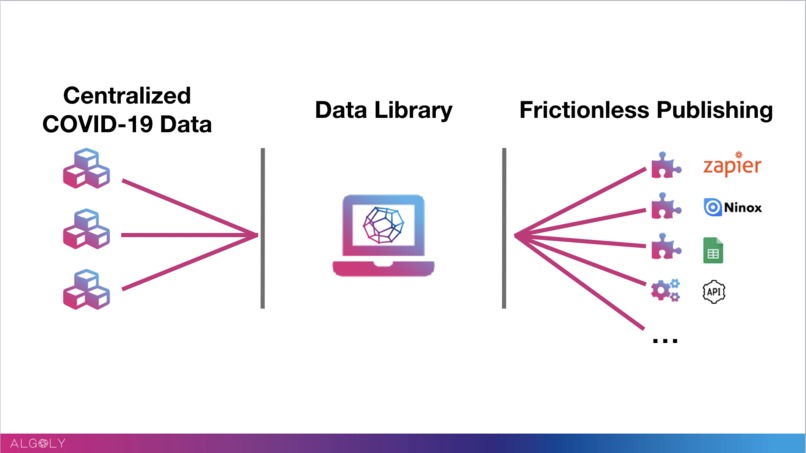
Centralized COVID-19 Data gets harmonized to be used with no-code services

Inspiration
We are a team of coders and non-coders who are passionate about data. Our inspiration is to build a no-code platform to allow for access without friction to data and algorithm technology and is driven by each group's own challenge:
- The non-coders are usually experts in a specific domain and have many great ideas around those. But for many ideas they can't access data and algorithm technology without help from developers.
- The coders rather want to work on harder and complex data science problems than spending time on harvesting, cleaning and harmonizing multiple different data sources.
When the Coronavirus appeared, it was clear to us that many domain experts and interested people who cannot coded will be interested in accessing vetted, cleaned and harmonized data around COVID-19.
Our plan for the _ no-code access to COVID-19 related data points _ project is to expand beyond the directly related COVID-19 information (number of infections, number of deaths, number of cured people, etc.). We are planning to onboard and harmonize indirect COVID-19 data in the categories such as economic impact, health care facility utilization status, changes in logistics supply chain, population foot fall information, etc.
We believe democratizing the access to all of those data points will 1) increase the number of creative and impactful ideas which actually can get realized over time, 2) decrease the needed time to execute those projects as the needed data is readily available 3) prepare everyone for future crises around the world with this the technology.
What it does
With the Algoly data shop COVID-19 expansion anyone can build a custom data stream by selecting any available data points and mix and match them with any other data point (even from different data providers). As the user goes through the selection experience, one can also alternate how the data should be used or compiled. Finally, the user can decide to easily publish the custom data stream with another no-code platform or use a classic API endpoint. (To acknowledging all data sourcing we are sending custom terms & services agreements and a source quotation manual to our users)
For example, if one wants to know the local COVID-19 infection growth and the number of hospitals in that region, she would select "COVID-19 Cases" and "Hospitals" as a data point and alternate the output to "summarizing the information". Then she could publish the data to her Google sheet, use a Zapier connection into thousands of other applications or use an API to freely use the data wherever it helps her most.
How we built it
The system consists of three elements 1) The data implementation, cleansing & harmonization system 2) The custom data stream creation and managing system 3) The no-code interface to make the services available to everyone
We are primarily using Ruby and JavaScript for the front end, AWS technology and SQL for the backend systems.
Challenges we ran into
- One challenge we are anticipating is how we are able to support an increasing number of custom data streams as we are automatically combining external API systems with one another. We are expecting performance challenges as we are dependent on the external API's speed and functionality.
- To make the data points available to non-coders we had to map easy language ("all hospitals") with the equivalent technical connection point. Essentially we had to create a new topology to perform that translation easily.
- Finding high qualitative and reliable data for all those different areas will be challenging. We already have relationships with numerous relevant data sources and will focus on harvesting those in the near term.
Accomplishments that we're proud of
We are proud that we have harmonized and centralized
- directly related COVID-19 data on county level for the USA and Germany,
- point of interest information for dozens of different categories
- demographic data points (educational level, income level) on census block level
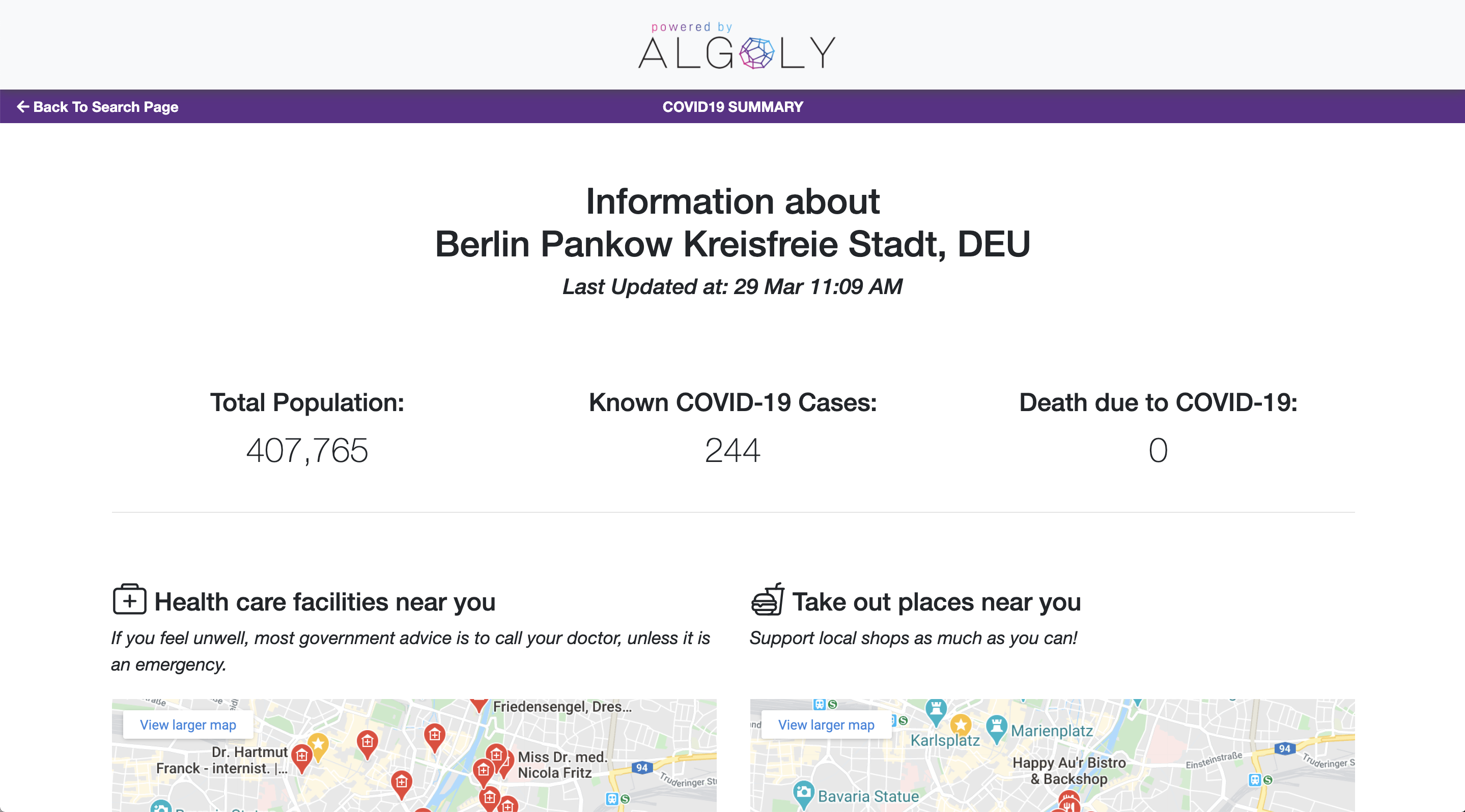
With the achievements, we have been able to build a COVID-19 Near Me search engine, which publishes COVID-19 cases on county level and combines it with available take out options and medical institutes (for Germany). We were able to build the data stream in minutes through our no-code platform rather days.
What we learned
Throughout this project we have learned that different data sources have many ways of structuring their data but in its core most data can be harmonized so that we can mix and match them with one another.
What's next for No-Code access to COVID-19 related data points
The necessary back end and front end system is ready and can be scaled to many more data points. Our next steps will be to identify additional data categories (see above) and the correlating data sources so that we make it available to non-coders.





Log in or sign up for Devpost to join the conversation.