-
-
No Cap Dashboard
-
No Cap Landing Page
-
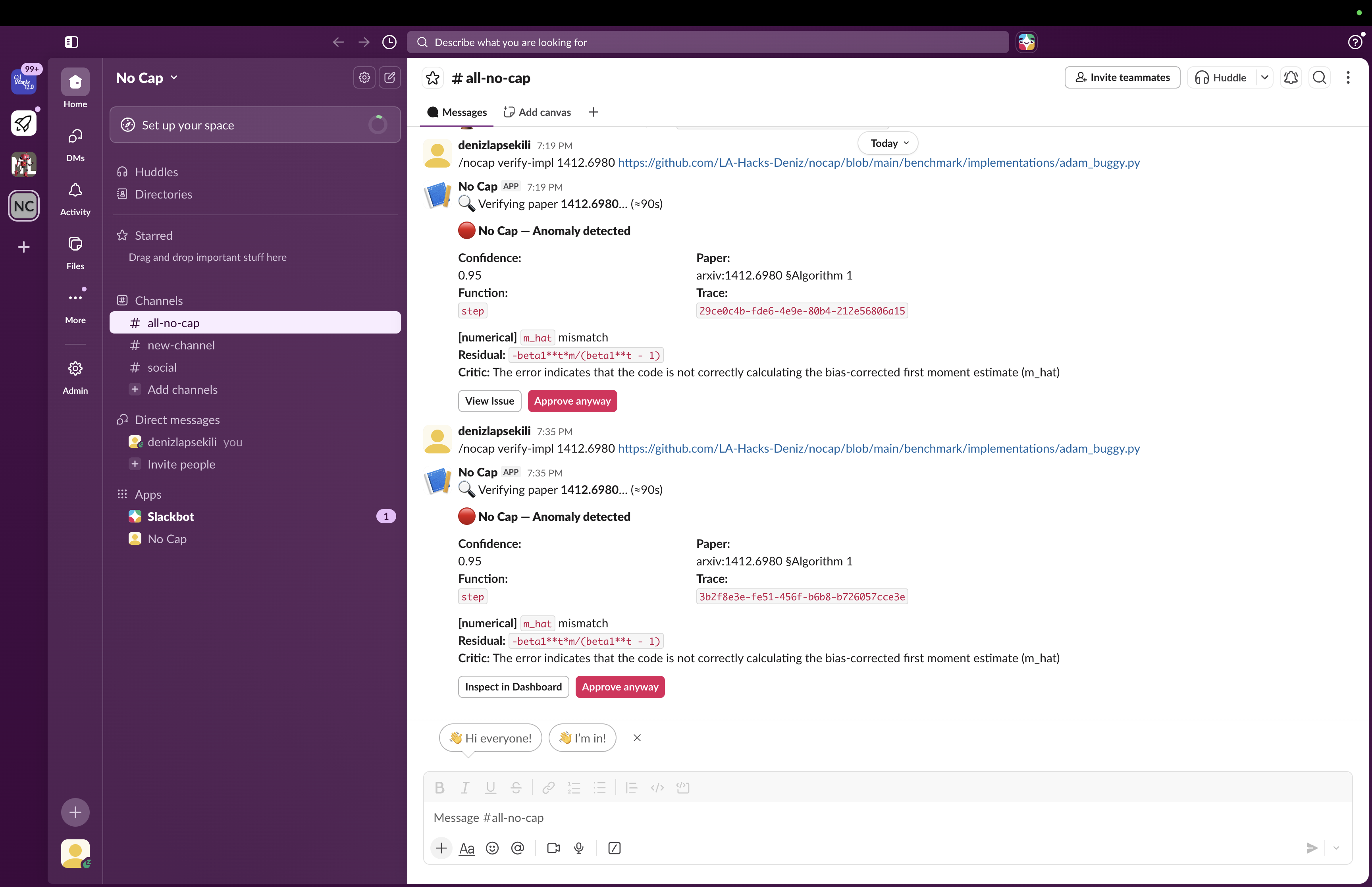
No Cap Slack Integration
Inspiration
Three weeks ago, in the middle of diffusion-model research at Harvard, I found myself staring at a loss curve that should have been monotonically decreasing and instead look like the EKG of a dead mouse. I had kicked the training 16 hours ago asking the agent to do some introductory research by reproducing the paper. The pipeline is a simple transcription from LaTex into PyTorch. The loss diverged at epoch 47. I opened the code, opened the paper, and started reading line by line.
I noticed that the agent silently dropped a single 1/√d_k from the attention normalization. There was no CI Failure, no type error nor a raised exception. Just a single missing mathematical term that is impossible to notice if you don’t know what you’re exactly looking for. The worst part is not wasting 16 hours of compute, it was the realization that this had probably happened many times before, on jobs whose results we have published.
Mathematical and scientific errors are uniquely difficult to spot. It could be a misplaced sign, a dropped normalization constant, a step of the algorithm changed. None of these would crash the program, none would fail the tests. The code will run end to end, producing convincing results. The errors of the code can often only be caught by the small errors adding up in the millions of steps, producing absurd number values or with a human reading the code and comparing it to the paper line by line.
So I built one. The architecture inspiration is recent and explicit. Walden Yan's single-writer / three-judge post (https://x.com/walden_yan/status/2047054401341370639), OptimAI's Formulator/Planner/Coder/Critic pipeline (https://arxiv.org/pdf/2504.16918), and VIGIL's verify-before-commit pattern (https://arxiv.org/pdf/2601.05755v2). No Cap is the first end-to-end implementation of all three on a single coding agent.
What it does
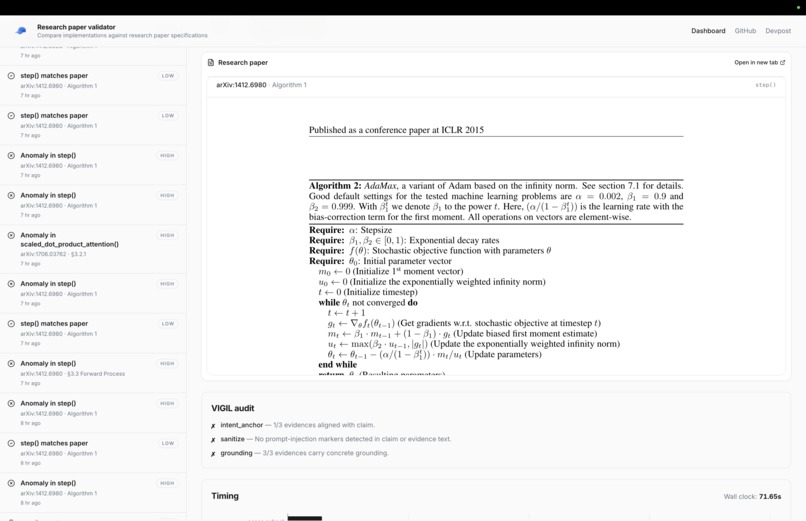
After an agent writes the implementation for a paper, the researchers will activate No Cap within their Slack. Give it the paper (arXiv ID or a PDF) and the implementation of an agent (Python file or PR diff). It will return a verdict: pass or an anomaly, including confidence and per-equation evidence.
- Catches what humans take hours to find: missing math terms, faulty algorithm implementations, dropped normalization constants
- Four checks running in parallel: does the math symbolically match? Does it match when you plug in real numbers? Does the algorithm have the right number of steps? Are the hyperparameters the same as the paper's defaults?
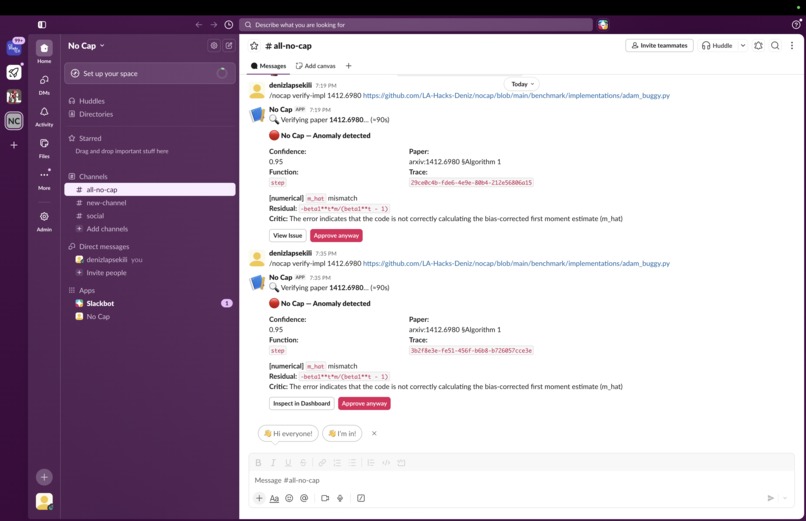
- Accessible from inside the Slack with a single command, so the engineers will not need to adapt to a new dashboard.
@deniz /nocap verify-impl 1412.6980 ./adam.py
🔴 No Cap — Anomaly detected (confidence 0.95)
Paper Algorithm 1, equation 3:
m̂_t = m_t / (1 - β₁ᵗ)
Code line 23:
m_hat = self.m
Residual: m·β₁ᵗ / (1 - β₁ᵗ) (bias correction missing)
From our tests, out of the box agents miss subtle math bugs every time. Without No Cap, the faulty job would run on the cluster for 6 hours. The engineer would have to waste hours to find why the curve diverged and 100s of CPU hours would be wasted.
With No Cap, within 20 seconds, the polygraph would flag the bias correction omission within the specific residual m·β₁ᵗ/(1-β₁ᵗ), saving the researchers hours and wasting 0 CPU hours.
How I built it
This is a challenge that I am extremely passionate to solve, so I've approached the solution like an engineer, trying different ways for each solution and using quantifiable measures to select the final approach.
- Council: 4 agents to code, spec, plan and polygraph. Code is the only writer while the rest contribute read-only evidence. I've found that a single writer loop time 4x compared to an early multi writer prototype.
- AI software: I used Gemma 3 on spec, plan, pair match and polygraph and Gemma 4 on the hardest task, which is to be the judge. I've seen that this combination works the best compared to a purely Gemma 3 or a Gemma 4 path, since a Gemma 3 judge will miss some of the key mathematical expressions and a pure Gemma 4 approach increases the execution time up to 5 minutes.
- Matchers: Software to run dynamic input into the code and test the hyper parameters alongside the agents.
- Auth0: Universal login using google so each researcher can see the result of their compute in the dashboard and no other research code (might be proprietary) is visible.
- Gateway: Slack implementation using Rust, which routes calls into the python council. This was implemented after I tried it with Node, resulted in 6x lower p99 webhook latency
- Database & UI: Using MongoDB Atlas, Slack Bolt and the frontend is with Next.js hosted on Vercel.
Challenges I ran into
Designing the single writer council: The first prototype let all the roles mutate and write into the code. This resulted in 23% of the runs ending in false positives because two roles wrote concurrently to the same dictionary. Inspired by the OptimAI paper, dropping to a single write agent let us get 0% false positives in the next 217 runs and cut the median debug loop time from 12 minutes to 2 minutes. When a verdict is wrong, there is exactly one agent responsible for it
Async orchestration across 5 LLM calls per verify-impl: parallelization across all council stages hit Google AI Studio's 15 K-tok/min free-tier ceiling — 41 % of runs returned 429s mid-pipeline. Pure-serial fixed the rate-limits but pinned p50 latency at 90 s. We settled on parallelize-within-strategy-buckets + a 5 s sleep across stages, which recovered to 0 % 429 rate and dropped p50 to 28 s.
Connection of Slack, Rust gateway and the Python council: Since slack has a 3 second time limit, this was hard to implement to the average 90 second run time of our agents. The fix is the Rust gateway returning a content-addressable trace_id in <200 ms and posting the verdict via chat.postMessage once the council finishes
LLM Output Reliability: The response schema for Gemma 4 isn't strictly enforced. 30%. of the spec calls came back as malformed JSON. I tried 4 different prompt engineering fixes which increased the success to 85% but the solution was a pydantic validated retry loop that continuously fixed itself in a feedback loop which pushed the success rate to 100%.
Accomplishments that I am proud of
End-to-end working prototype: Live production pipeline with slack implementation, github fetch, dashboard and user management with Auth0. Tested with 6 different papers and codes and had stellar results.
Quantitative Decision Engineering: Every architecture choice was A/B'ed. Single writer dropped race conditions 23% to 0%. Hybrid Gemma 4 integration made sure that the pipeline was fast when it mattered and precise when it needed to be. Parallel implementation cut 429 rate limits to 0. The benchmarks caught 4 errors that would've been shipped otherwise.
Auth0 & MongoDB & Vercel Live Deploy: Universal login and user management flow with saved states for previous runs and slack messages. Live vercel access to the dashboard and login page.
Branding & Domain: I really enjoy products with good branding, using godaddy to register our name nocap.wiki and using the 🧢 for our logo made me enjoy the development process more
What I learned
Going into this solo I knew the multi-agent stuff was going to be the part I'd lose sleep on, and it was. I learned the hard way that "multi-agent" usually means race conditions on shared state, not coordination, and that Walden Yan's single-writer post (which dropped three days before kickoff) is right about pretty much everything. I also learned that prompting an LLM is not the same thing as architecting a council of them, where each role has to hand off typed evidence and survive a 429 mid-run. The biggest takeaway for me: nobody is actually verifying paper-to-code faithfulness, and my lab is going to use this in May.
What's next for No Cap
I'm fired up about where No Cap goes from here. Next steps:
- Pitch to my PI at Harvard: I'm demoing No Cap to the lab the week of May 5 on our actual reproduction backlog. If it lands, the team adopts it as the verification gate before any agent-written code touches the cluster, and the lab becomes the first real-world deployment.
- Suggest-fix module: today the Polygraph emits the residual but stops there. One extra Gemma call after an Anomaly proposes a unified-diff patch and closes the loop.
- CIBA push-confirmation on overrides: the override flow already attests identity through Auth0; the next iteration adds a Guardian push to phone before the override commits.
- Multi-workspace Slack OAuth + Devin CLI install: any team installs No Cap in one click, and verification runs inline with Devin's own work instead of being a tool humans call about agents.
- Startup exploration: I genuinely think this becomes a real product, paper-faithfulness leaderboard and all, and I'd rather find out by trying than by guessing.

Log in or sign up for Devpost to join the conversation.