-
-
No 2 Iceberg Poster
Final Writeup
Title: No 2 Iceberg
Who:
Ian Layzer (ilayzer) Frederick Cushnir (fcushnir) Ermias Genet (egenet)
Introduction:
We were trying to solve the problem of NO2 and CO2 emission tracking in regions where there are no ground level sensors to track these emissions, but we ran into trouble with preprocessing the data so we pivoted to a different satellite data problem: determining whether an object is a ship or an iceberg from satellite radar data. We found this Kaggle competition (https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/overview) and wanted to see how vision transformer architecture would stack up against the winners of the competition.
Methodology:
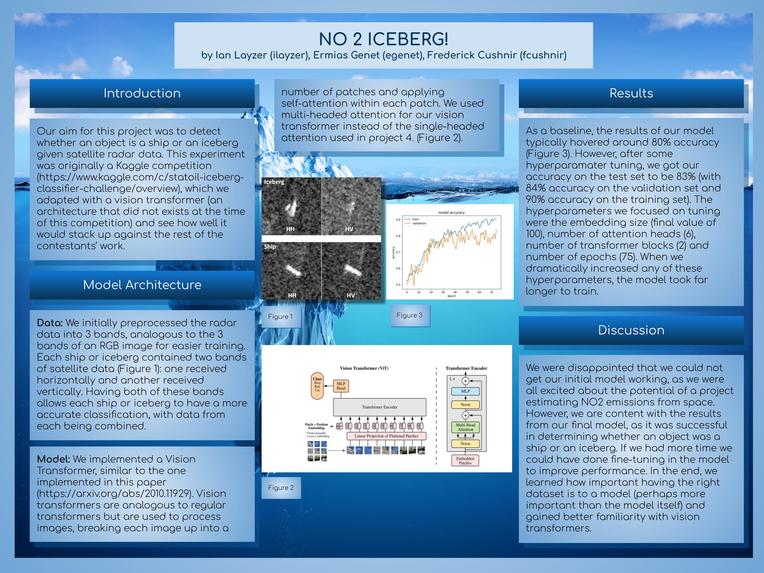
We initially preprocessed the radar data into 3 bands, analogous to the 3 bands of an RGB image for easier training. For the model, we implemented a vision Transformer, similar to the one implemented in this paper (https://arxiv.org/abs/2010.11929). Vision transformers are analogous to regular transformers (like we used in project 4) but are used to process images, breaking each image up into a number of patches and applying self-attention within each patch. We used multi-headed attention for our vision transformer instead of the single-headed attention used in project 4.
Results:
As a baseline, the results of our model typically hovered around 80% accuracy. However, after some hyperparamater tuning, we got our accuracy on the test set to be 83% (with 84% accuracy on the validation set and 90% accuracy on the training set). The hyperparameters we focused on tuning were the embedding size (final value of 100), number of attention heads (6), number of transformer blocks (2) and number of epochs (75). When we dramatically increased any of these hyperparameters, the model took far longer to train, and because we did not have GCP credits we were limited in what we could do. In theory, we may have been able to improve our accuracy further by making a much deeper model, but we felt that the computational and energy resources needed for what would have been a small increase in performance were not worth it.
Challenges:
We ran into many challenges with our initial project proposal. Getting access to the data used in the project proved very difficult, and when we eventually did get access to it there were many bugs in the preprocessing used in the paper that slowed and eventually stopped our progress. Once we pivoted, we had fewer challenges and were able to be successful in our model creation. With the new model, we did have some challenges figuring out how to implement the vision transformer and overfitting to the data, but we were able to figure out our issues successfully. We also had challenges with GCP, as we redeemed our credits before the ed post had details on how to work around the limitations Brown puts in place, so we were not able to use the credits.
Reflection:
We were disappointed that we could not get our initial model working, as we were all excited about the potential of a project estimating NO2 emissions from space. However, we are content with the results from our final model, as it was successful in determining whether an object was a ship or an iceberg. Our base/target/stretch goals became irrelevant when we pivoted projects, but our final accuracy of 90% on the train data, 84% on the validation data, and 83% on the testing data is something we are happy with. If we could do the project over again, we would have chosen a different initial task where we knew we had access to (or could easily create) a clean dataset that we could use in the project. Because we spent the majority of our time on a project that did not end up working, we had to pivot to a less exciting project than one we could have tackled if we had the entire time frame to do it. If we had more time we could have spent more time fine-tuning the model and improving performance. In the end, we learned how important having the right dataset is to a model (perhaps more important than the model itself) and gained better familiarity with vision transformers.
Both of our written reports for the checkins are linked under the same google doc below!

Log in or sign up for Devpost to join the conversation.