-
-
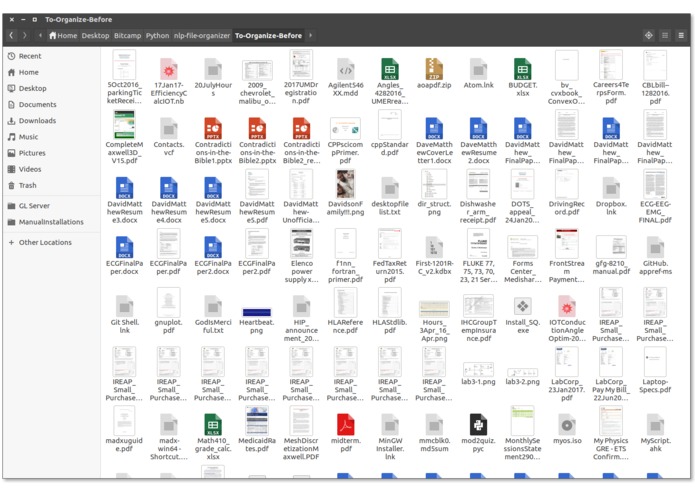
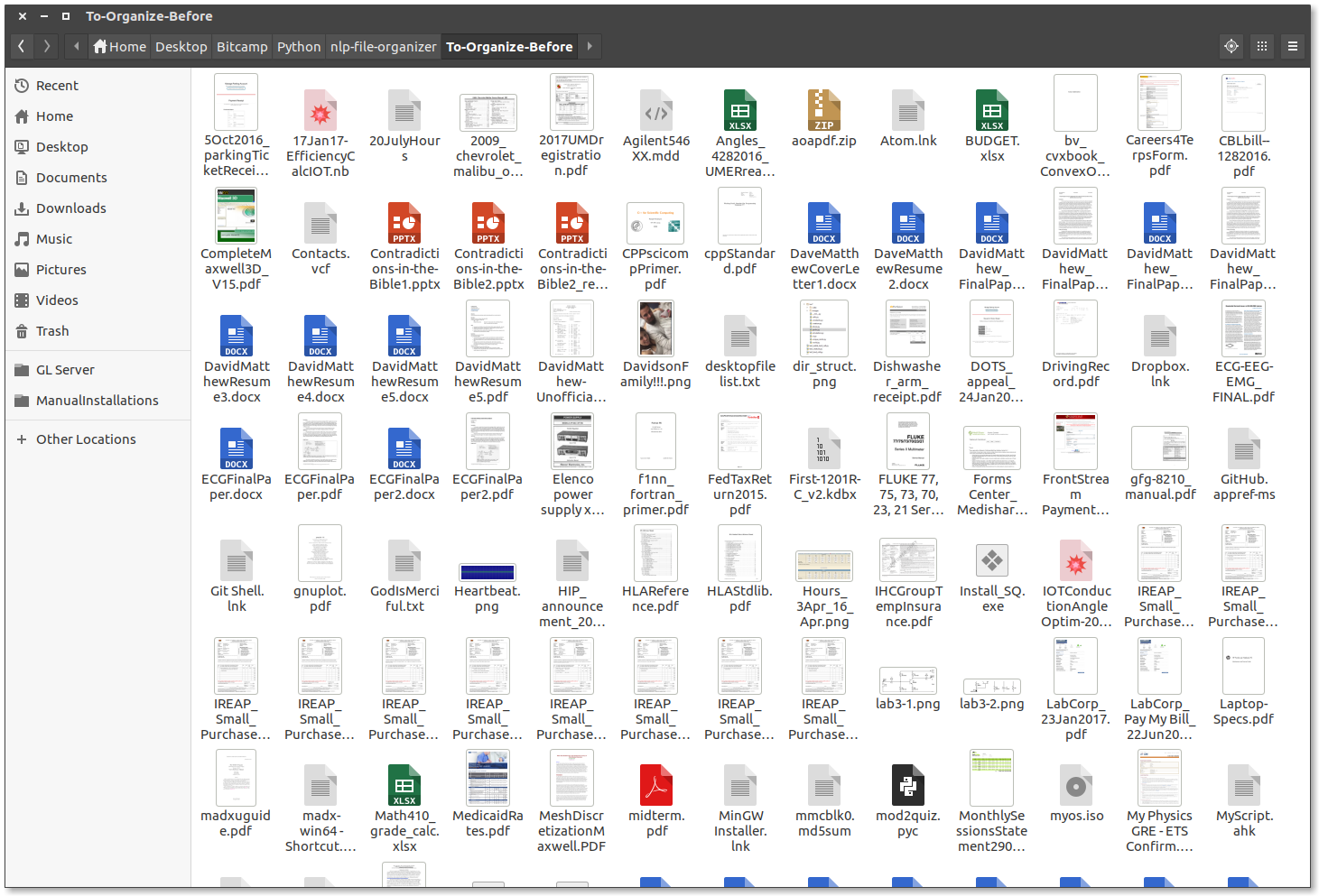
Disorganized Directory
-
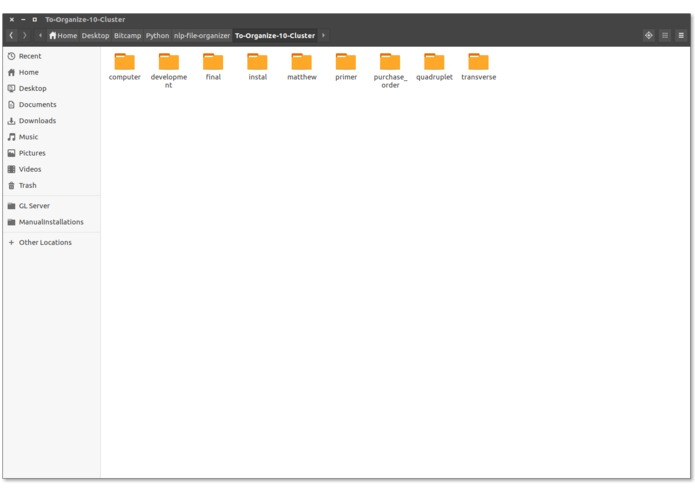
Organized Directory with 10 Clusters
-
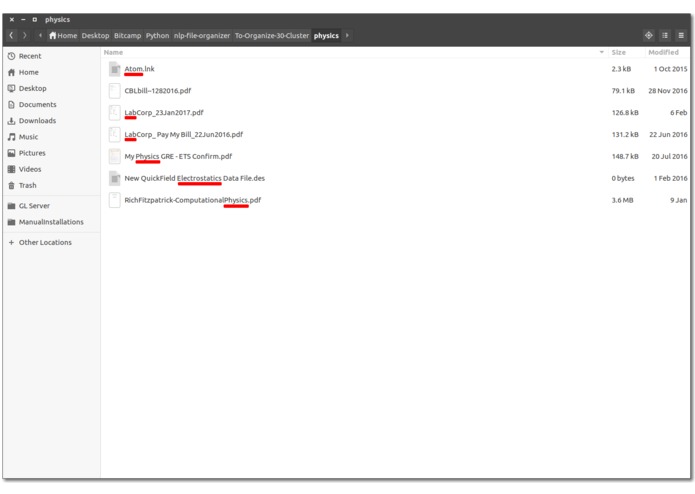
Contents of a physics-focused cluster


Inspiration
I was walking around during the team building activity when my now partner, Dave, was complaining about the clutter on his desktop. I proposed the idea of an automatic organization tool which leveraged Natural Language Processing to automatically organize his Desktop, but this could be useful for many people.
What it does
The NLP File Organizer automatically extracts words out of file names and converts the words to high-dimensional feature vectors. It then uses a clustering algorithm to group files with similar topics together into subdirectories.
How I built it
I'm currently in a Natural Language Processing class and just discussed word similarity and hypernymy, so I decided to apply my knowledge for my class to this prevalent, real-world problem. I knew the theory already and with the help of Dave we managed to put the project together in just 2 days.
The program begins by making n-grams out of characters in the file names and determining if they form English words. It then uses the 5 longest English words it detects on a file to represent the file under an assumption that I made saying the longer a word is, the more meaning it holds.
These representative words are converted into high-dimensional feature vectors and are clustered using K-Means with Euclidean Distance similarity to group the files together.
I then try to find a lowest common hypernym for a cluster's group of representative English word. If I can't find a low enough hypernym I fall back on the longest, most frequent word found among the files. This hypernym or frequent word is used as a cluster title.
Once I've found the clusters I move the files into directories named after the cluster title.
Challenges I ran into
Clustering the files together was relatively easy, but trying to name the new directories wasn't. I initially tried finding a representative word that was most similar to the rest of the document but that resulted in directory titles that were not descriptive and didn't make any sense. I looked back over my class notes and remembered that word similarity wasn't the only metric I could use, so I determined the lowest common hypernym as a primary labelling method and got much more accurate. I still fall back on the most common, longest word in a cluster if a low enough hypernym cannot be found.
Accomplishments that I'm proud of
I'm proud of the fact that the program works as well as it does. On lower levels of clusters (the sweet spot for about 140 files was 15-30 clusters during experimentation) you can clearly see the relationship between different file names and the organization makes pretty good sense. I'm also proud of the fact that it runs in a little under 30 seconds, which is impressive considering how much data the libraries I use have to chug through in order to produce results.
What I learned
No one technique for solving a problem will solve everything. Sometimes you have to approach a problem using multiple methods in tandem in order to tackle it.
What's next for NLP File Organizer
I may or may not continue work on it, but I really want to figure out how to use matplotlib and Singular Value Decomposition to reduce the dimensionality of my words' feature vectors and plot the clusters on a graph to see how the program put the clusters together.

Log in or sign up for Devpost to join the conversation.