-
-
Landing Page
-
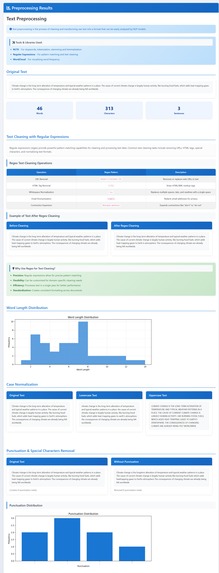
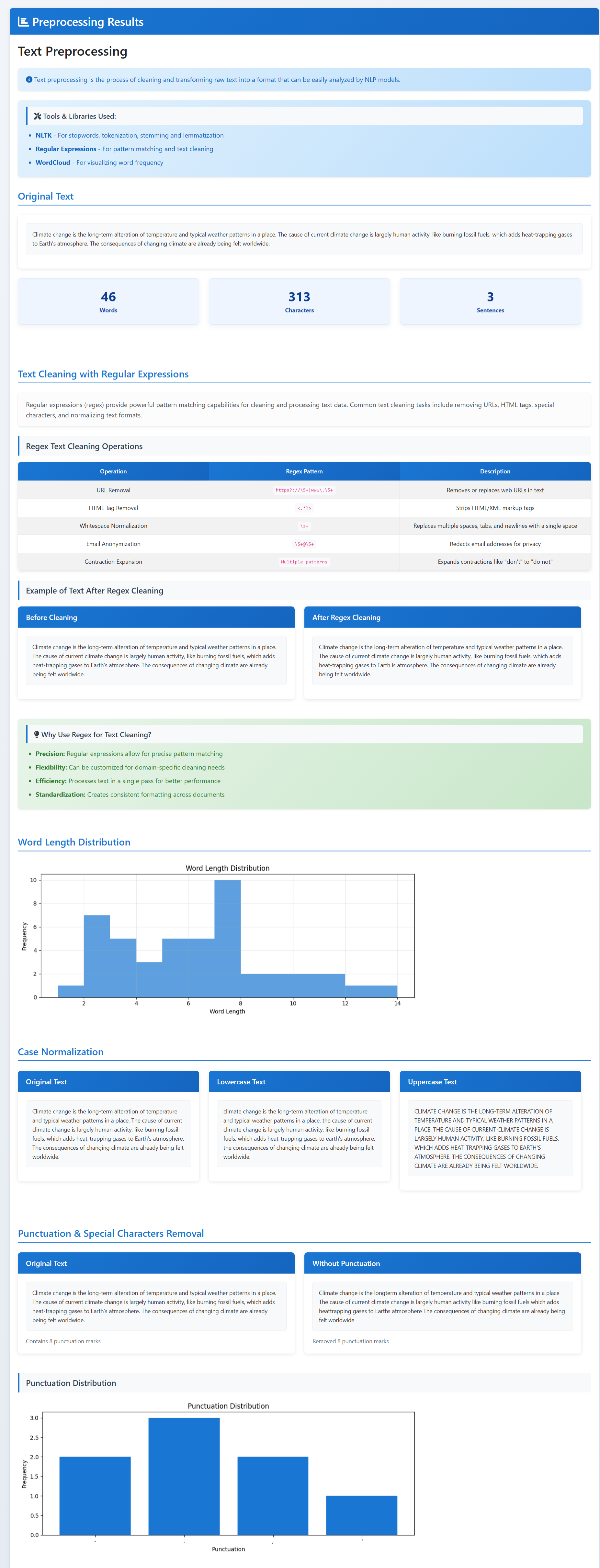
Text Preprocessing
-
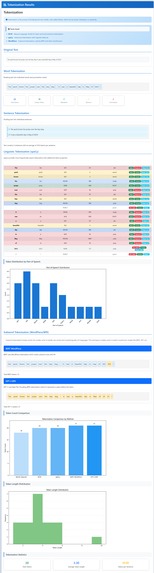
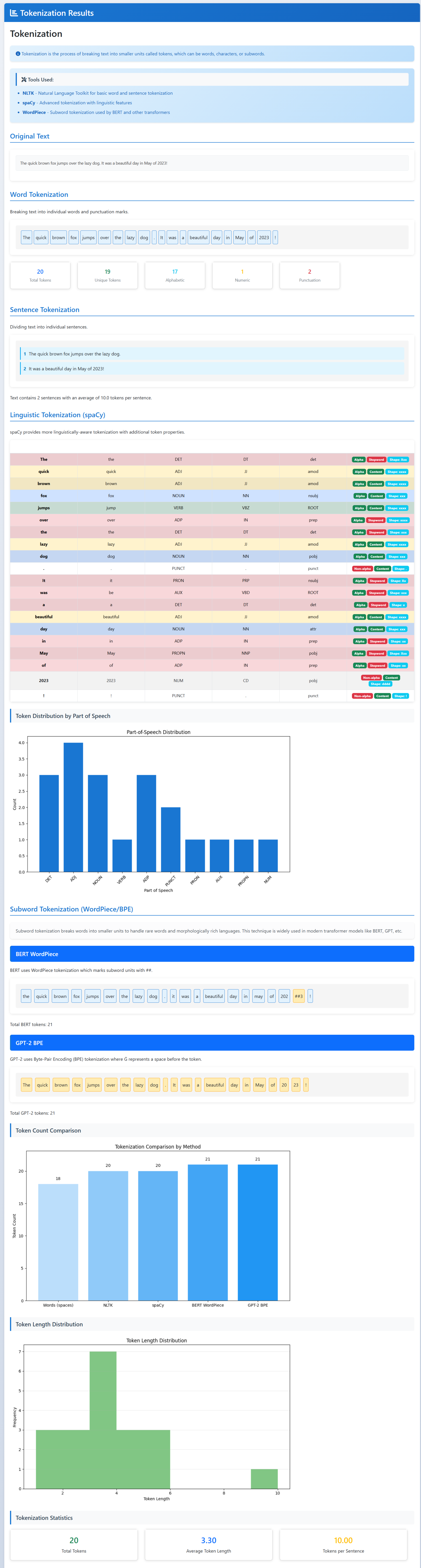
Tokenization
-
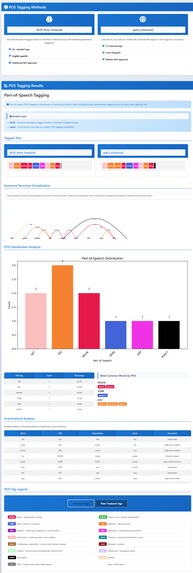
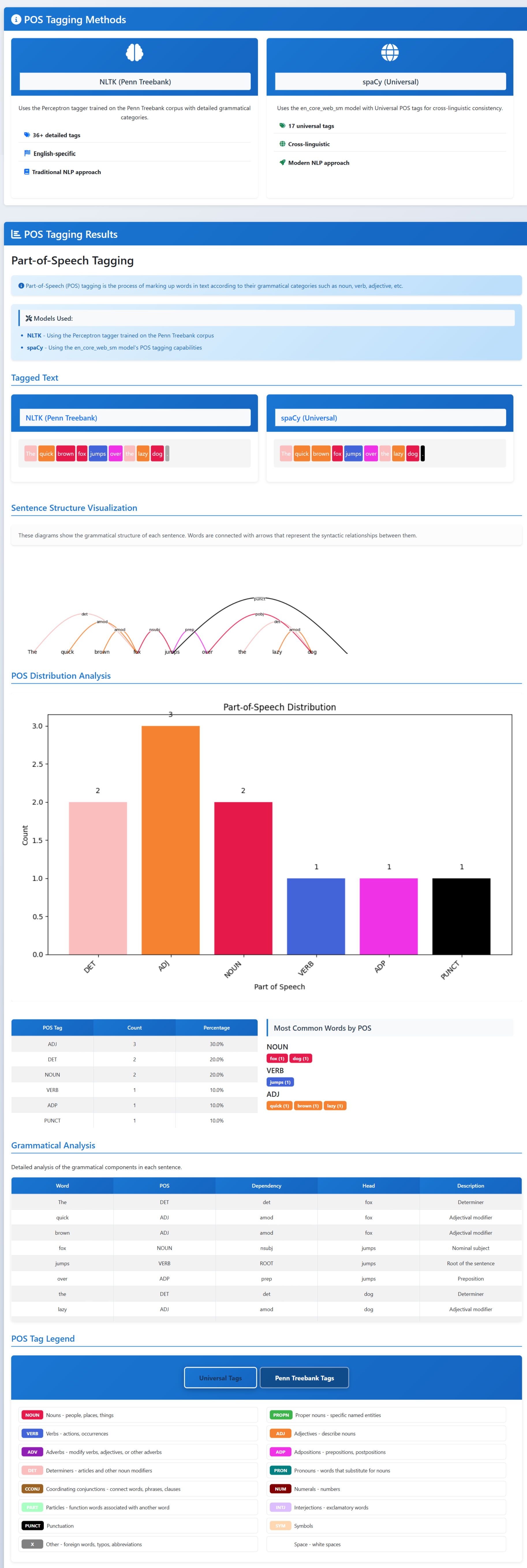
Part-of-Speech Tagging
-
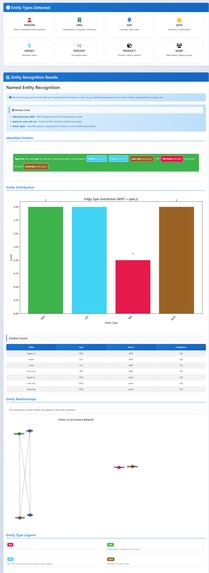
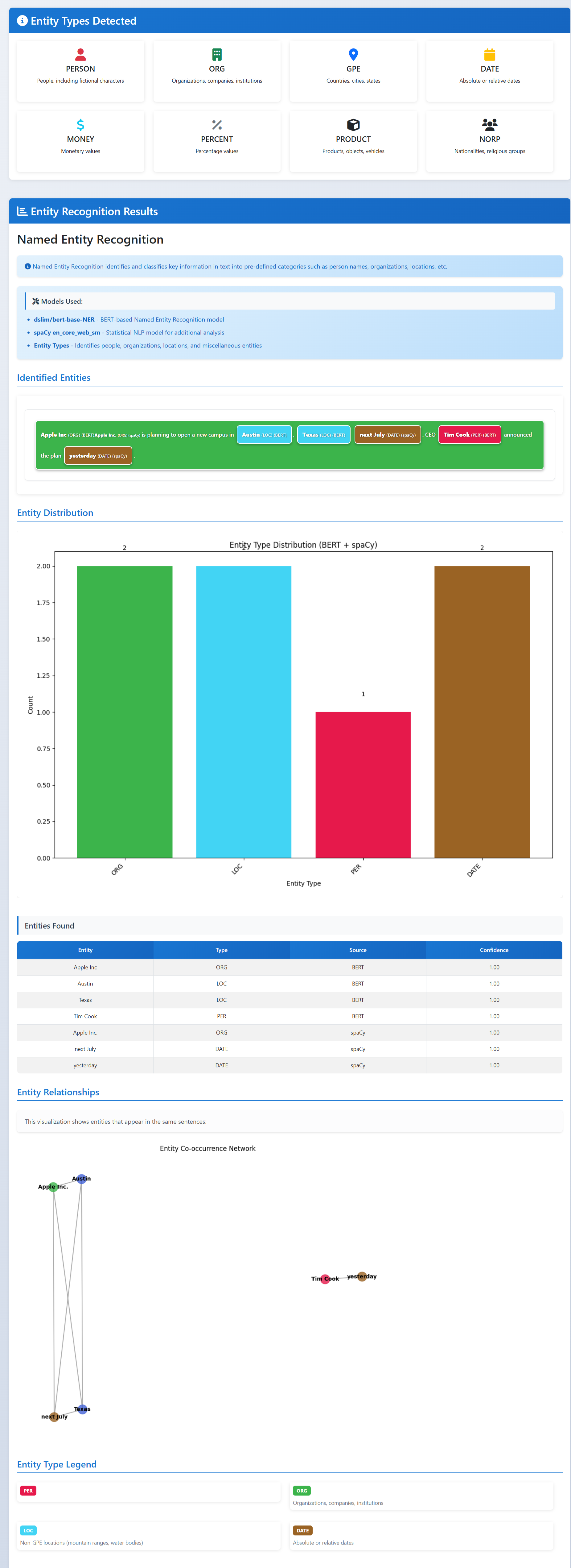
Named Entity Recognition
-
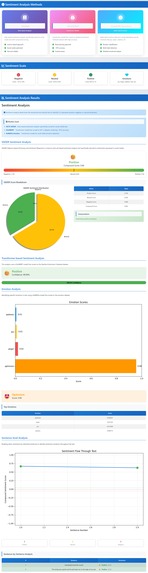
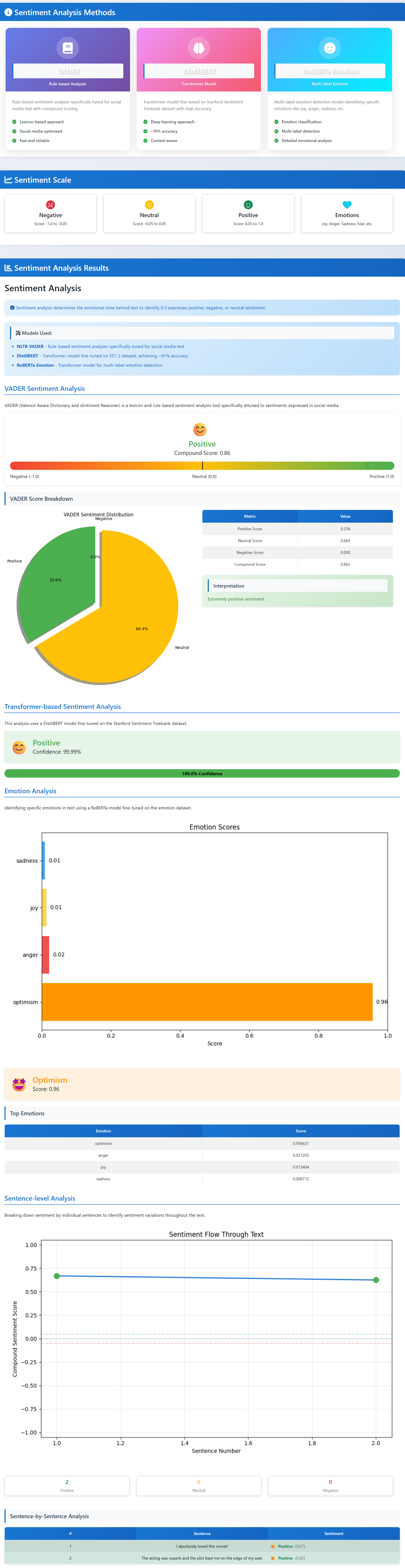
Sentiment Analysis
-

Topic Analysis
-
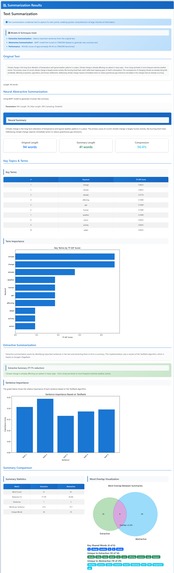
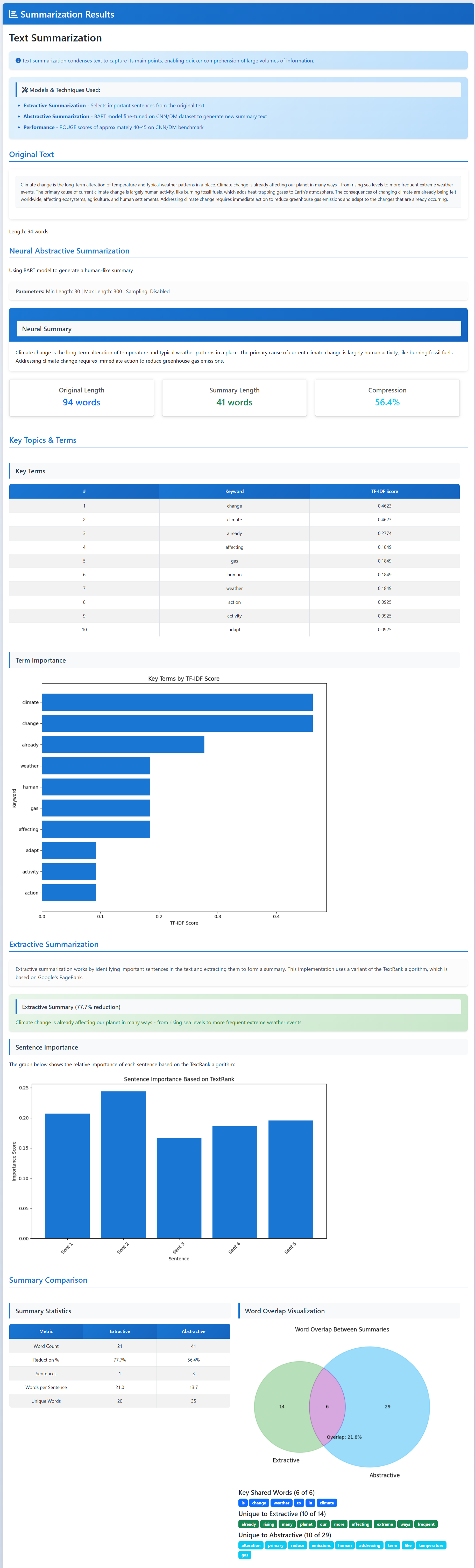
Text Summarization
-
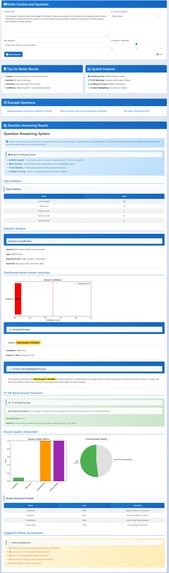
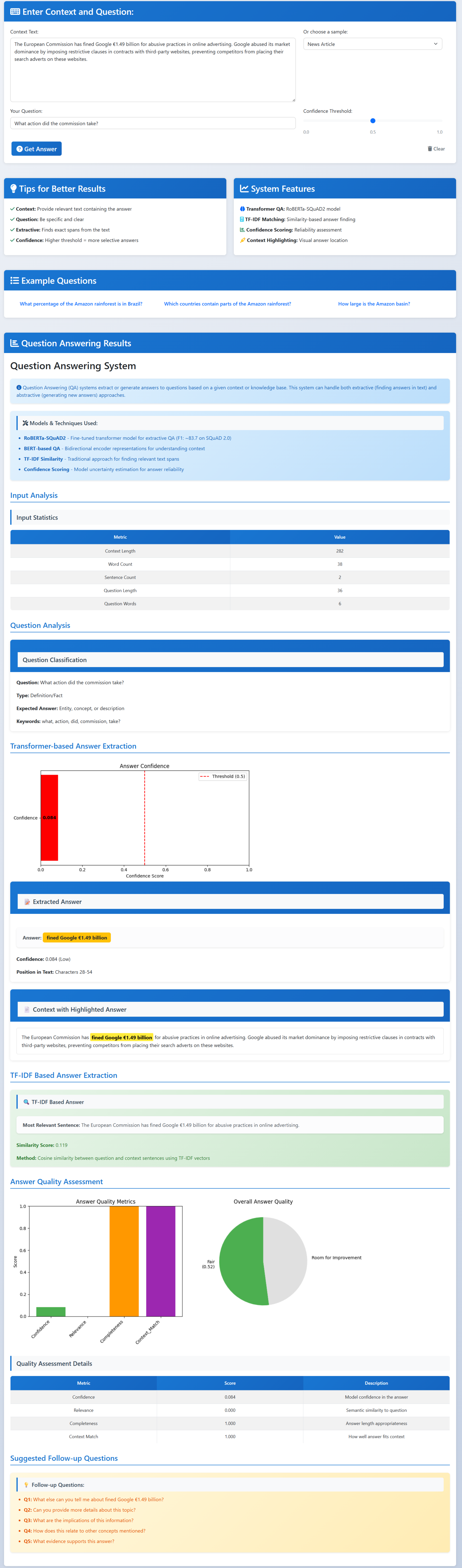
Question Answering
-
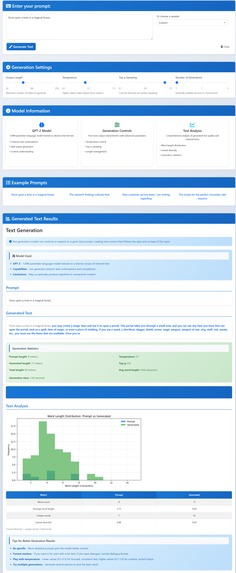
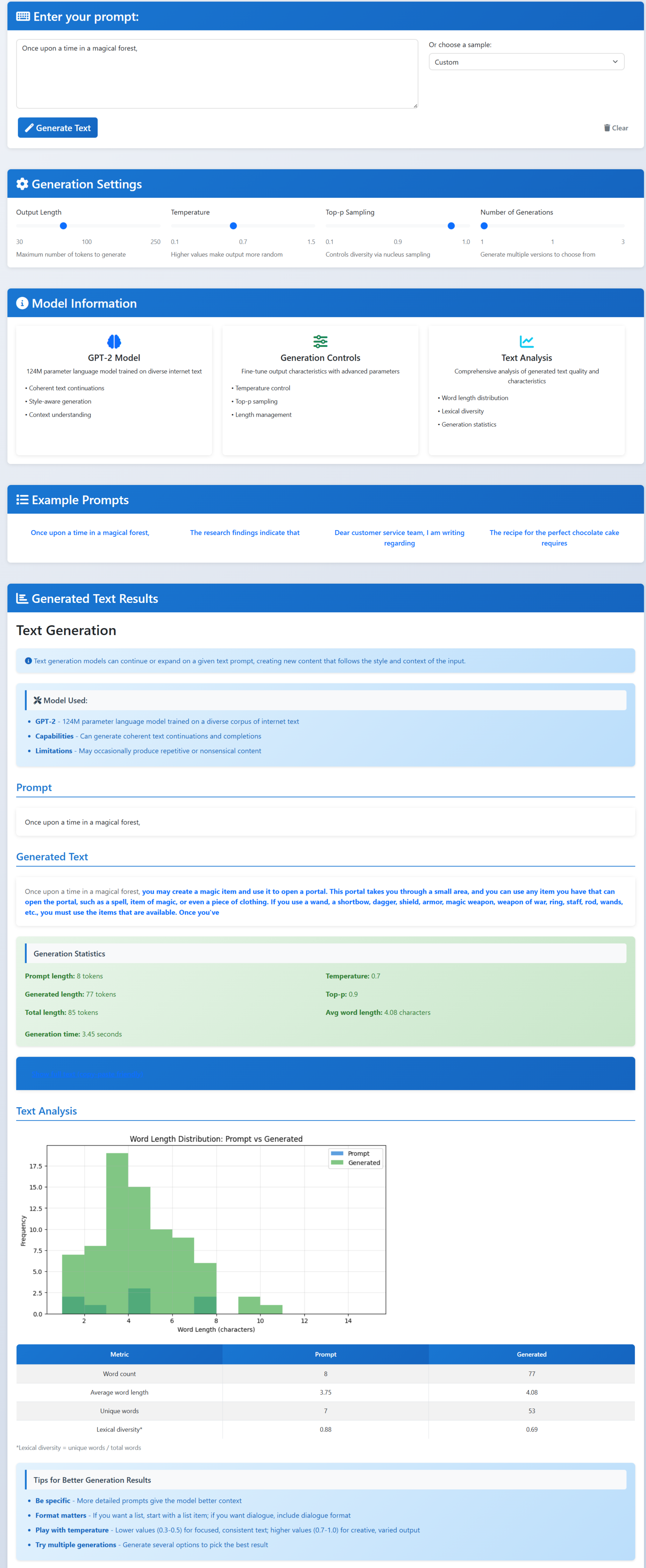
Text Generation
-
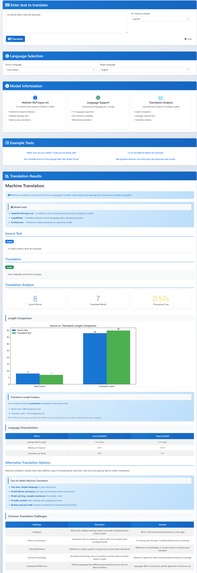
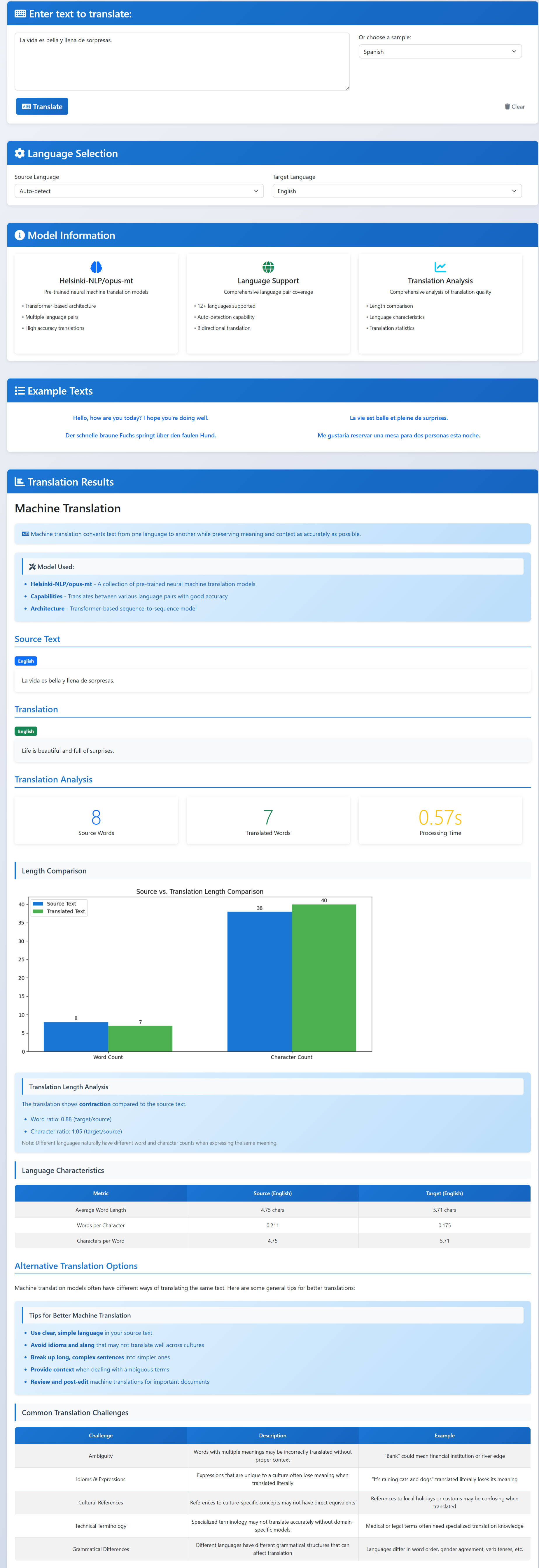
Machine Translation
-
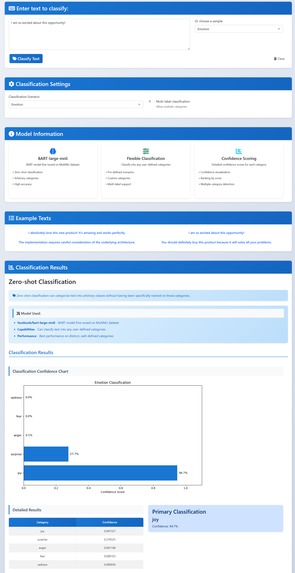
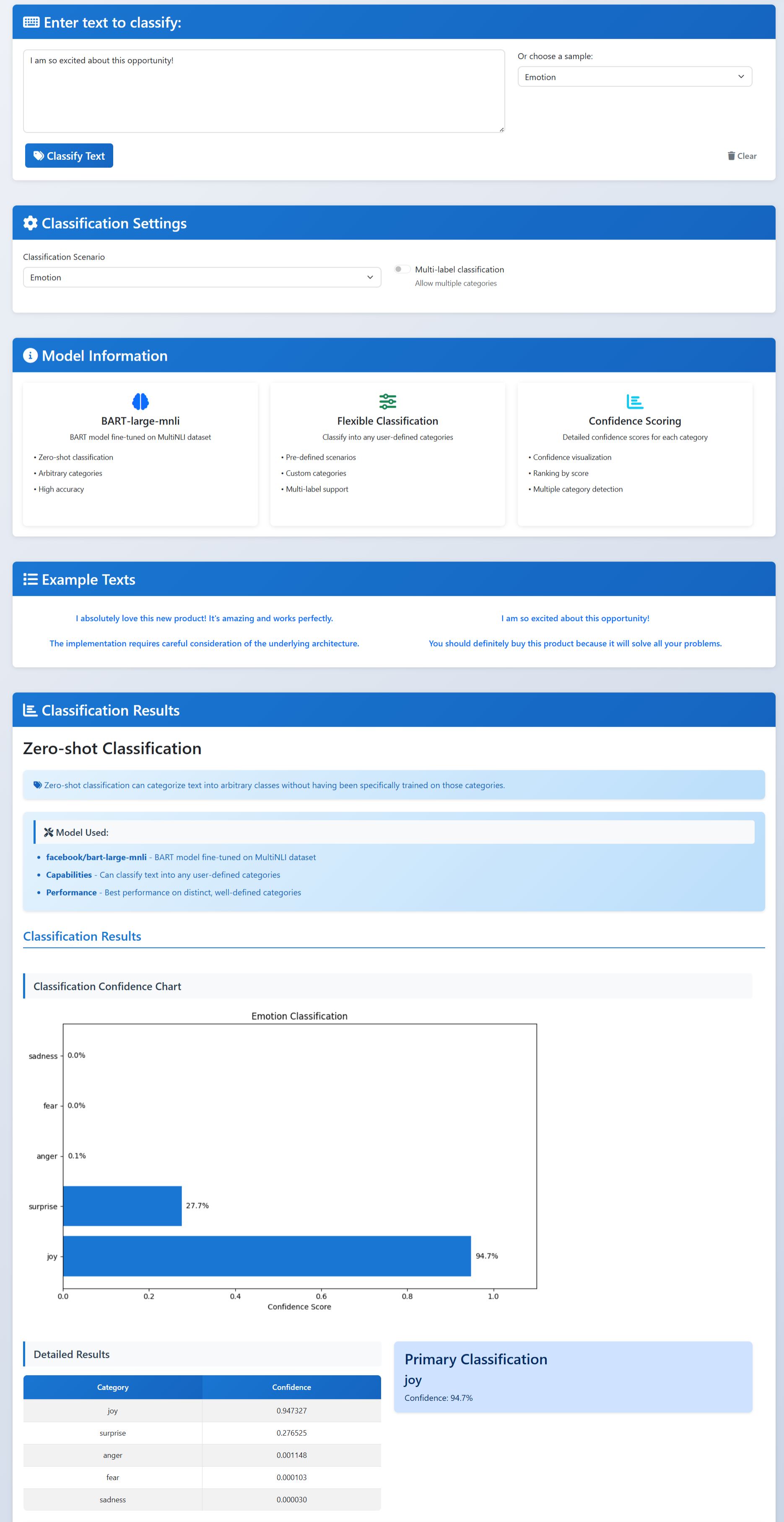
Zero-shot Classification
-
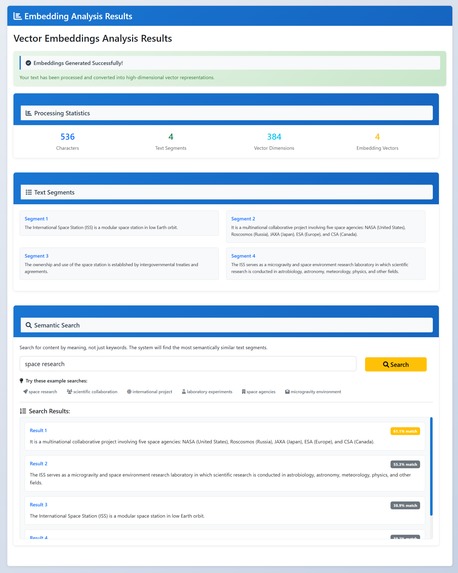
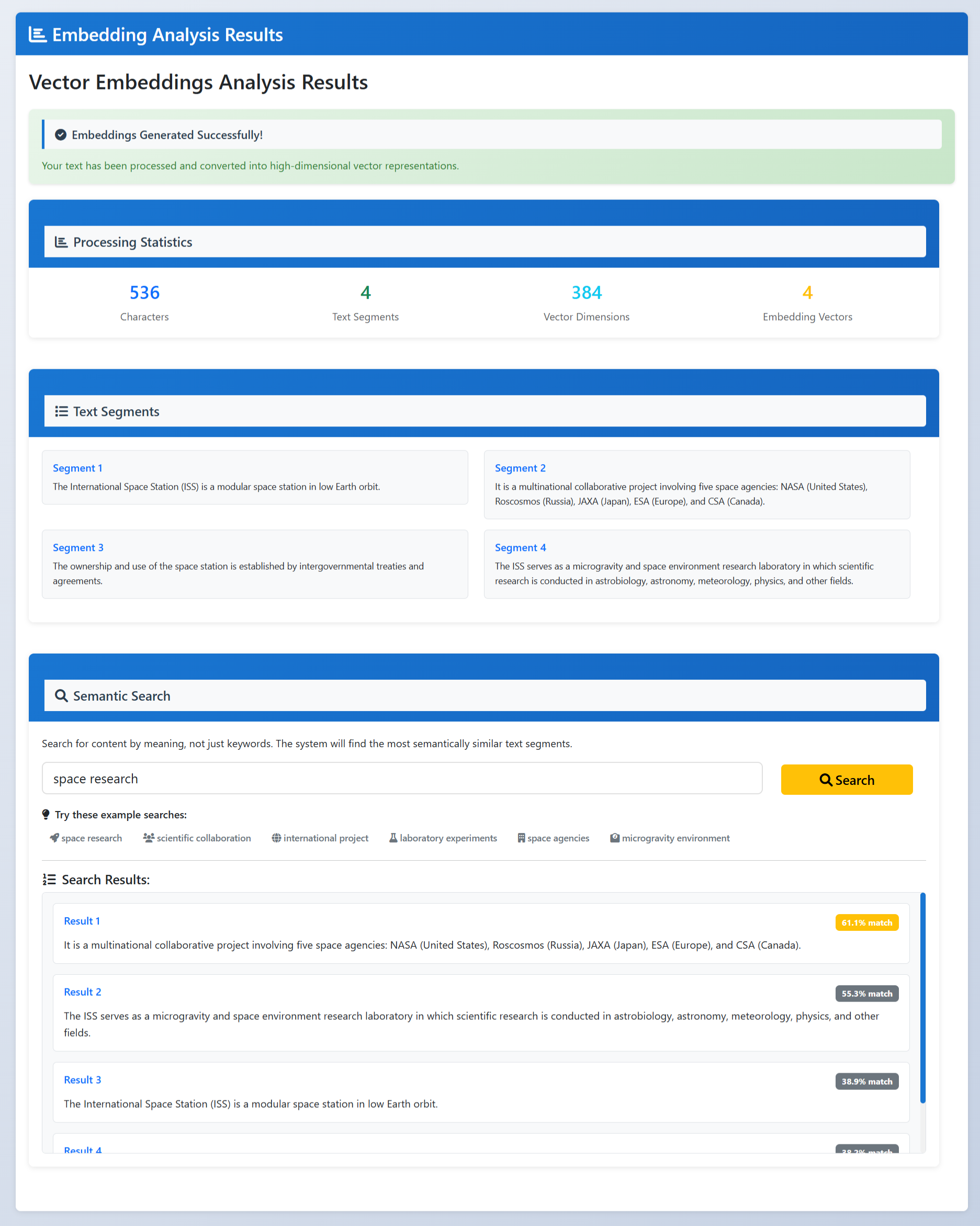
Vector Embeddings & Semantic Search

Inspiration
Understanding NLP is very important when getting into the AI world. It is one of the key foundations behind modern LLMs, but it can be hard to implement in practice.
During my M.Tech, these topics were taught, but they were difficult to understand hands-on because many tools had to be installed, configured, and kept working together. I wanted to reduce that setup pain and give a simple place where you can paste your own text and immediately see how these ideas work.
This project turns those lessons into a clear, hands-on experience: less setup, more learning.
What it does
This app lets you paste your own text and see how different NLP tasks work, side by side:
- Preprocessing and cleaning: remove noise (extra spaces, punctuation issues), fix casing, and get the text ready.
- Tokenization: split text into sentences, words, or sub-words so models can read it.
- Part-of-speech tagging: label each word (noun, verb, adjective, etc.).
- Named entity recognition: highlight names of people, places, organizations, and more.
- Sentiment and emotions: estimate if the text feels positive, negative, or neutral (and emotions when available).
- Summarization: create a shorter version that keeps the main points.
- Topic analysis: find the main themes or keywords in longer text.
- Question answering: ask a question about a passage and get an answer from it.
- Text generation: continue writing from a prompt.
- Translation: change the text from one language to another.
- Zero-shot classification: sort the text into your own labels without extra training.
- Vector embeddings and semantic search: compare meanings and find similar sentences.
Each tool has a simple page and an API. You can try them with your own text and compare the results.
How we built it
We used a small Flask app with clear routes in app.py, one handler per module in components/, and light templates/JavaScript for the UI. This kept the structure simple, stable, and easy to extend.
Challenges we ran into
- First tried Streamlit, but session resets and frequent reloads broke multi-step flows.
- Then tried Gradio; custom JS/HTML and a multi-page layout were hard to support.
- First-time model downloads can be large and slow (pulling weights from the hub). Mitigation: load models only when a module is opened and reuse them from cache afterward.
- CPU-only environments with limited RAM: use smaller models and modest batch sizes across modules; for larger datasets, apply efficient embeddings and indexing (e.g., FAISS) where appropriate.
- Different libraries format results differently (labels, spans, scores). Outputs are mapped to simple, consistent schemas (for example, lists of {label, score} and spans with start–end offsets) so the UI renders the same way across modules.
Accomplishments that we're proud of
- Modular codebase: clear separation of concerns (routes in
app.py, per-module handlers incomponents/, shared utilities inutils/). - Implemented 12 NLP modules with matching pages and POST APIs (see routes in
app.py). - Consistent, simple output schemas across modules for labels, scores, and spans.
- Easy to run locally or in containers (Dockerfile provided; simple run steps in README).
- Optimized for CPU use: lazy model loading, caching, and lighter defaults to keep memory and latency reasonable.
- Clear configuration: port via
PORTenv var (use 5000 locally, 7860 on Hugging Face Spaces).
What we learned
- Keep the interface simple; reveal options only when needed.
- Kept the design easy to navigate through all the models.
- Design with modular coding: routes → components → utils improves clarity and maintenance.
- Choose tools and models deliberately: balance accuracy, speed, and memory for CPU use.
- Careful model loading and caching matter on CPU-only setups.
- Consistent input/output contracts let the same backend serve both UI and API.
- Small visuals (scores, tables, simple charts) make learning faster.
What's next for NLP Academy - Interactive Educational Platform
- More math-focused modules (Naive Bayes, TF–IDF, entropy, perplexity).
- Clearer views into attention and transformer internals.
- Better embedding visuals, including simple 3D views.
- Broader language coverage beyond English defaults.
- Optional GPU builds for faster demos.
- Short guided exercises so learners can practice step by step.
Acknowledgments
Thanks to Hugging Face for providing the Space to host this app, and to the open-source community for the libraries and models that made this possible.


Log in or sign up for Devpost to join the conversation.