
Inspiration
The gap between data engineering and business intelligence is notoriously vast. Most companies sit on massive troves of SQL databases but rely on disjointed, manual pipelines to get that data into the hands of decision-makers. We were inspired by the friction experienced by executives who ask simple questions like "What was our return on investment last quarter across product segments?" and have to wait days for a Data Analyst to build a static report. We wanted to build an AI orchestrator that handles the entire pipeline: from language understanding, to SQL execution, to frontend React generation.
What it does
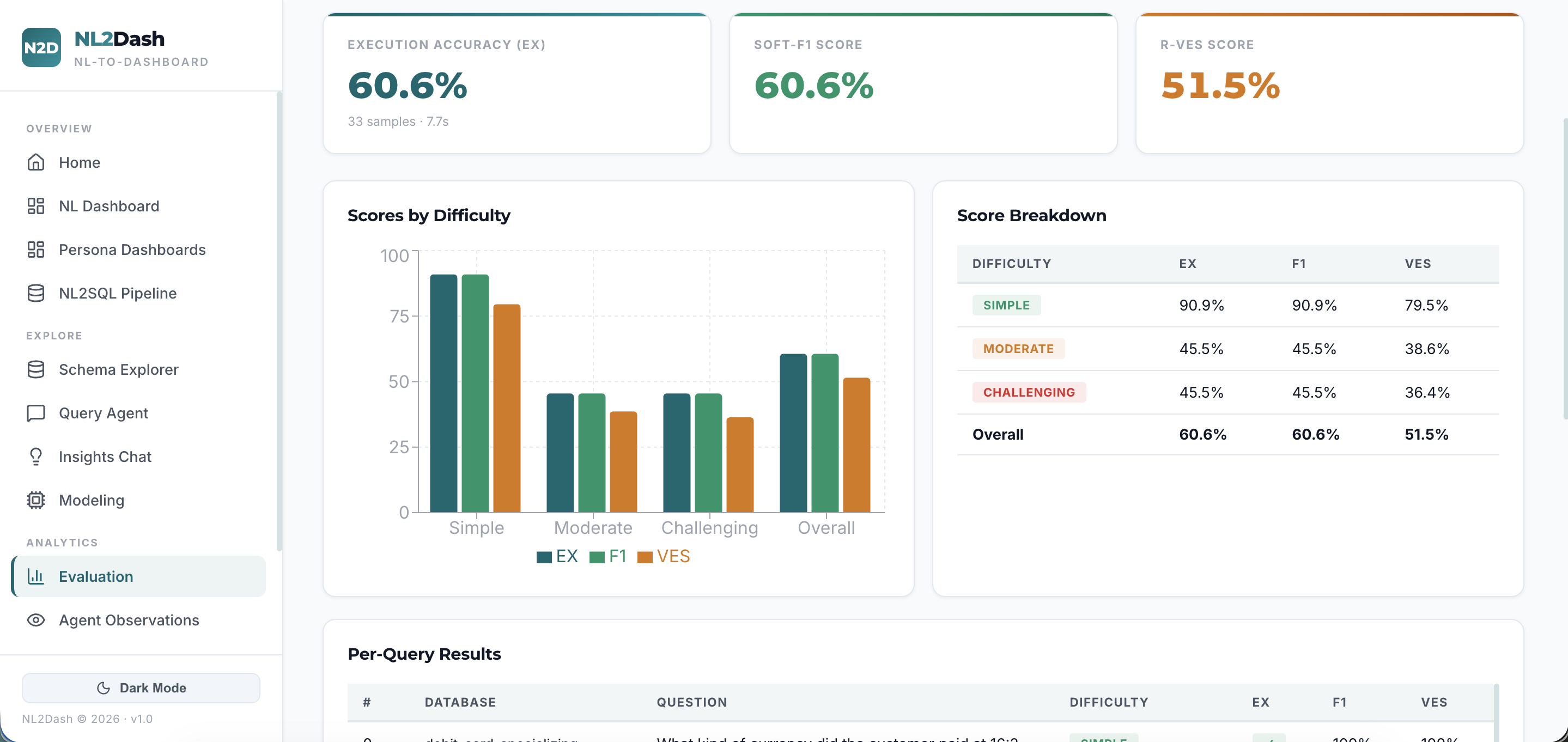
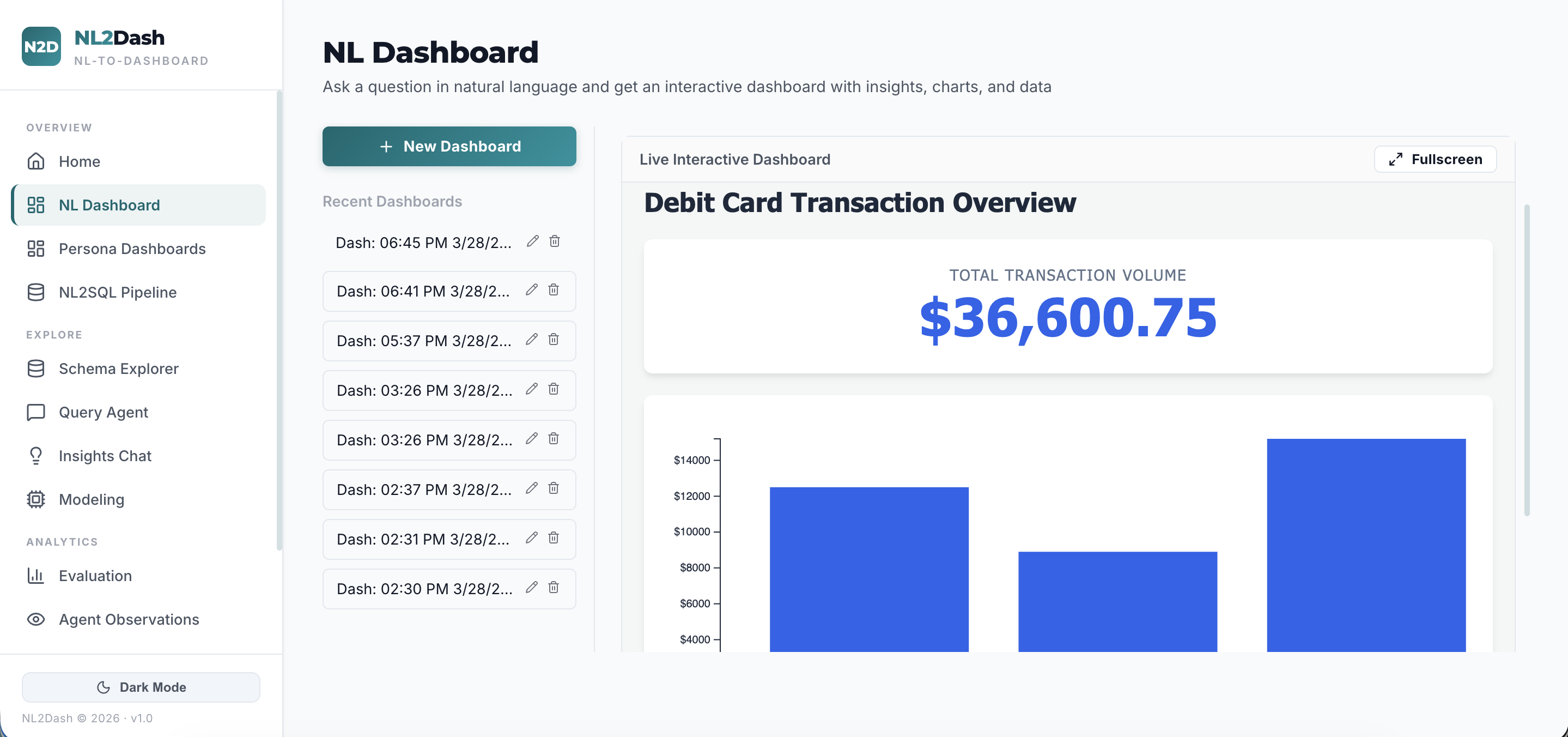
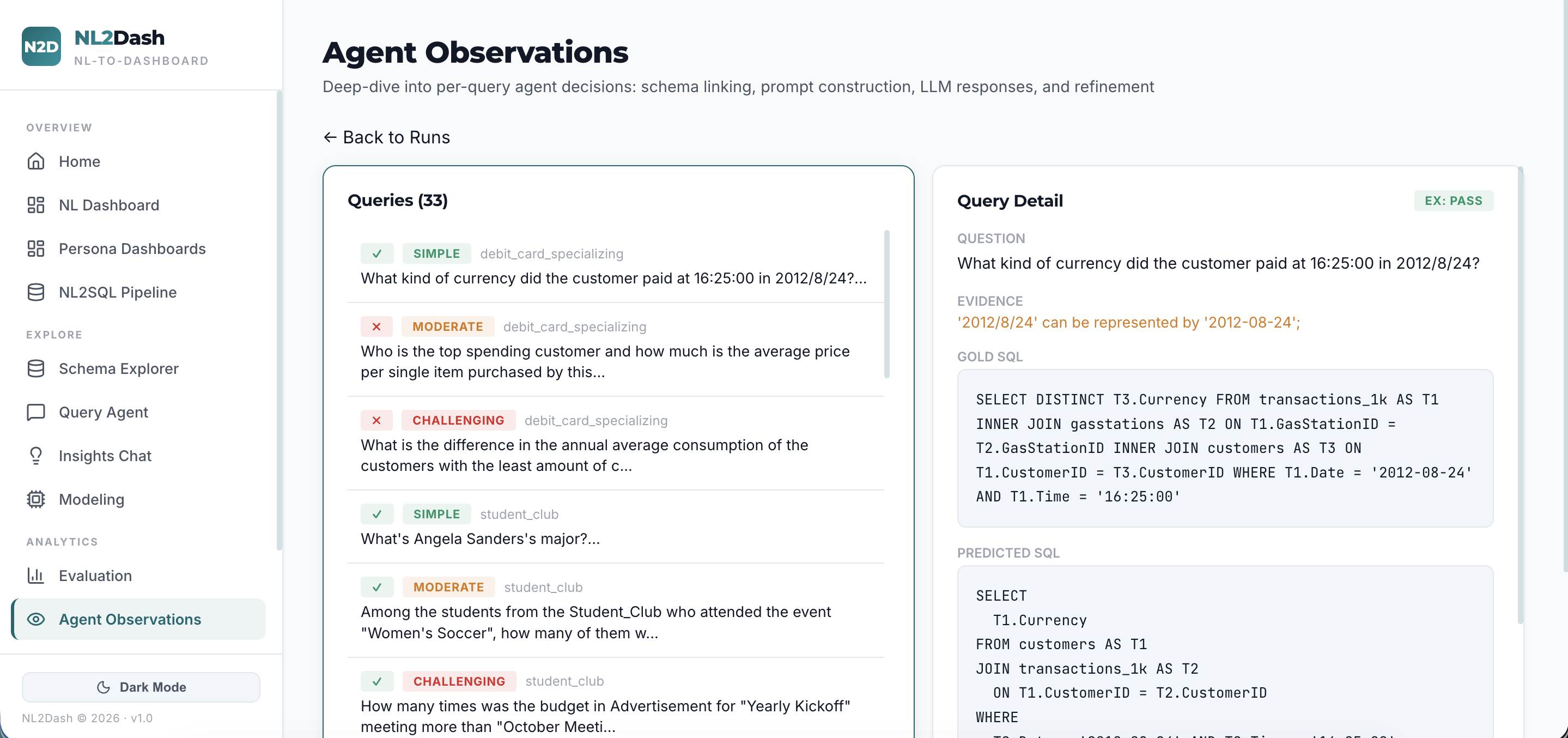
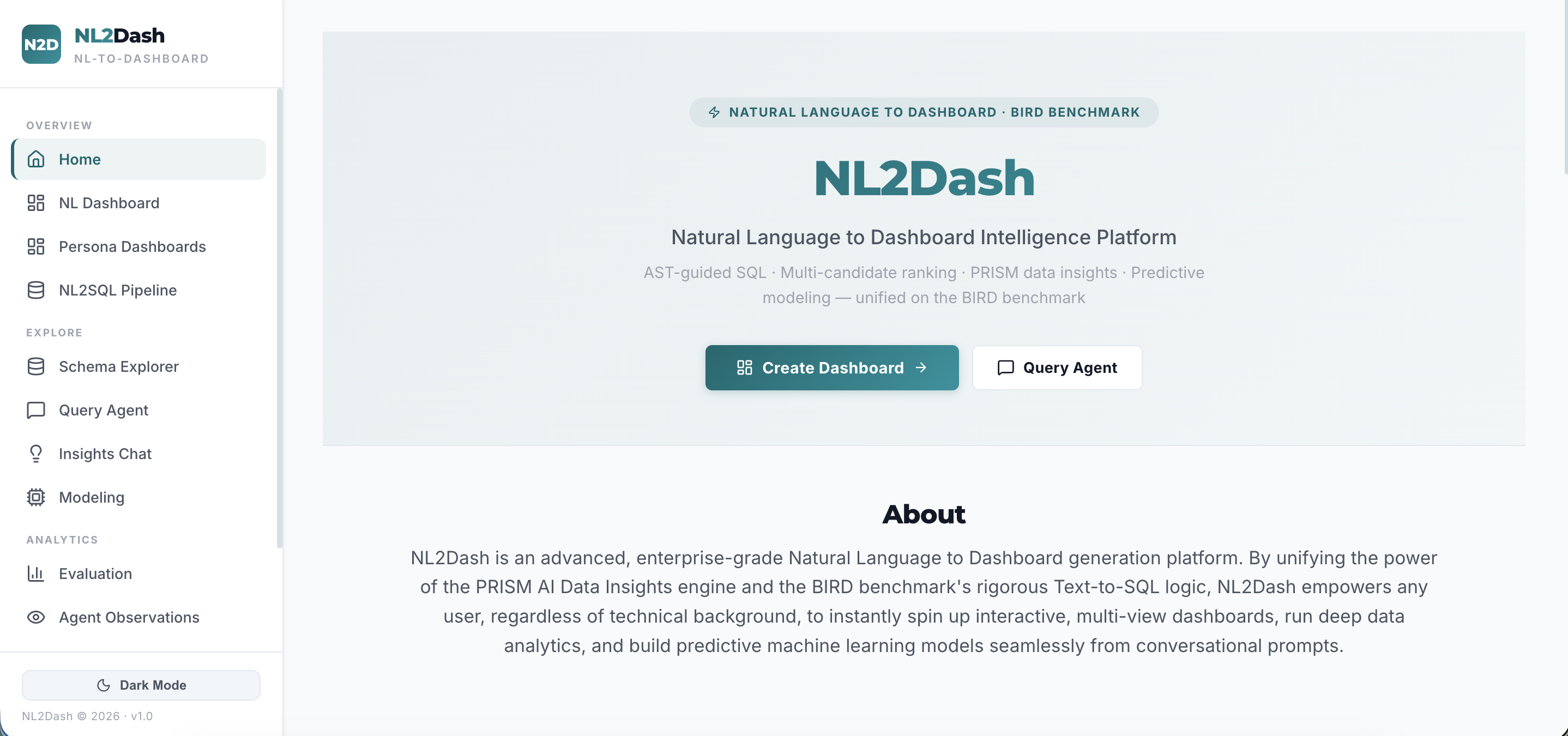
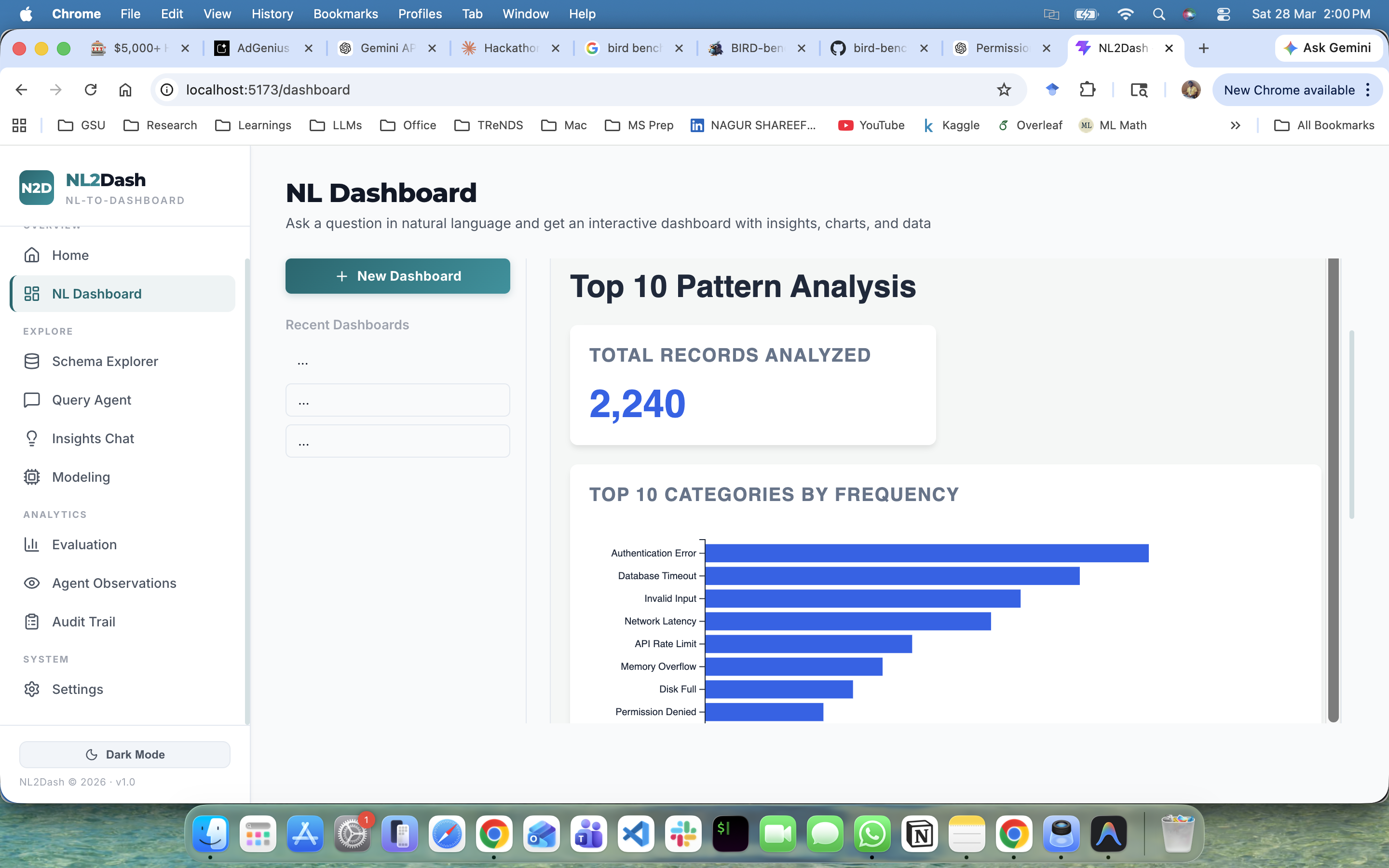
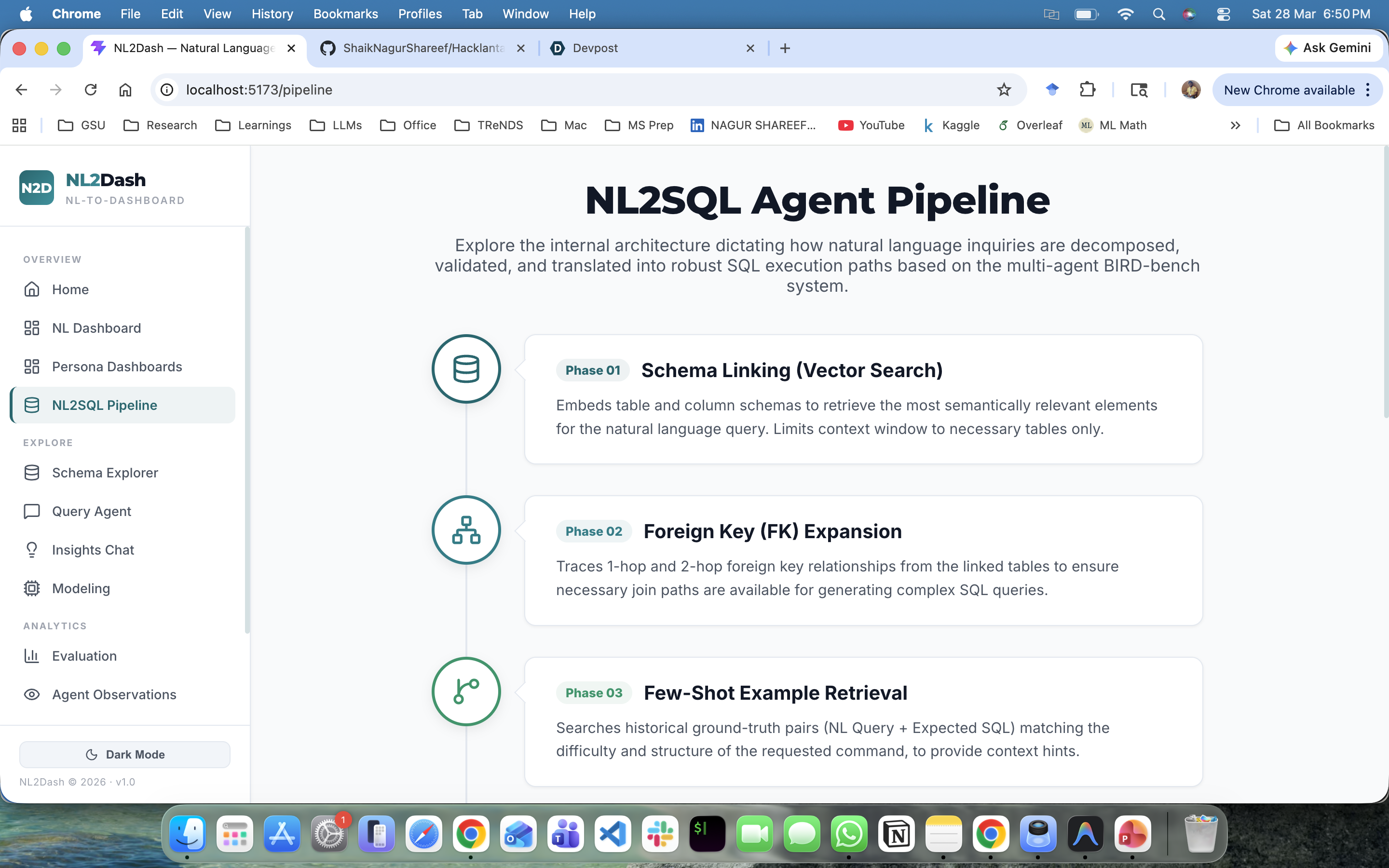
NL2Dash accepts a natural language query, converts it into optimized SQL using a Text-to-SQL engine benchmarked against BIRD-Bench (11 real-world databases spanning finance, education, healthcare, sports, technology, and more), executes it against any connected database, and automatically classifies the user's analytical intent — whether it is a comparison, trend, ranking, correlation, composition, distribution, overview, or drill-down.
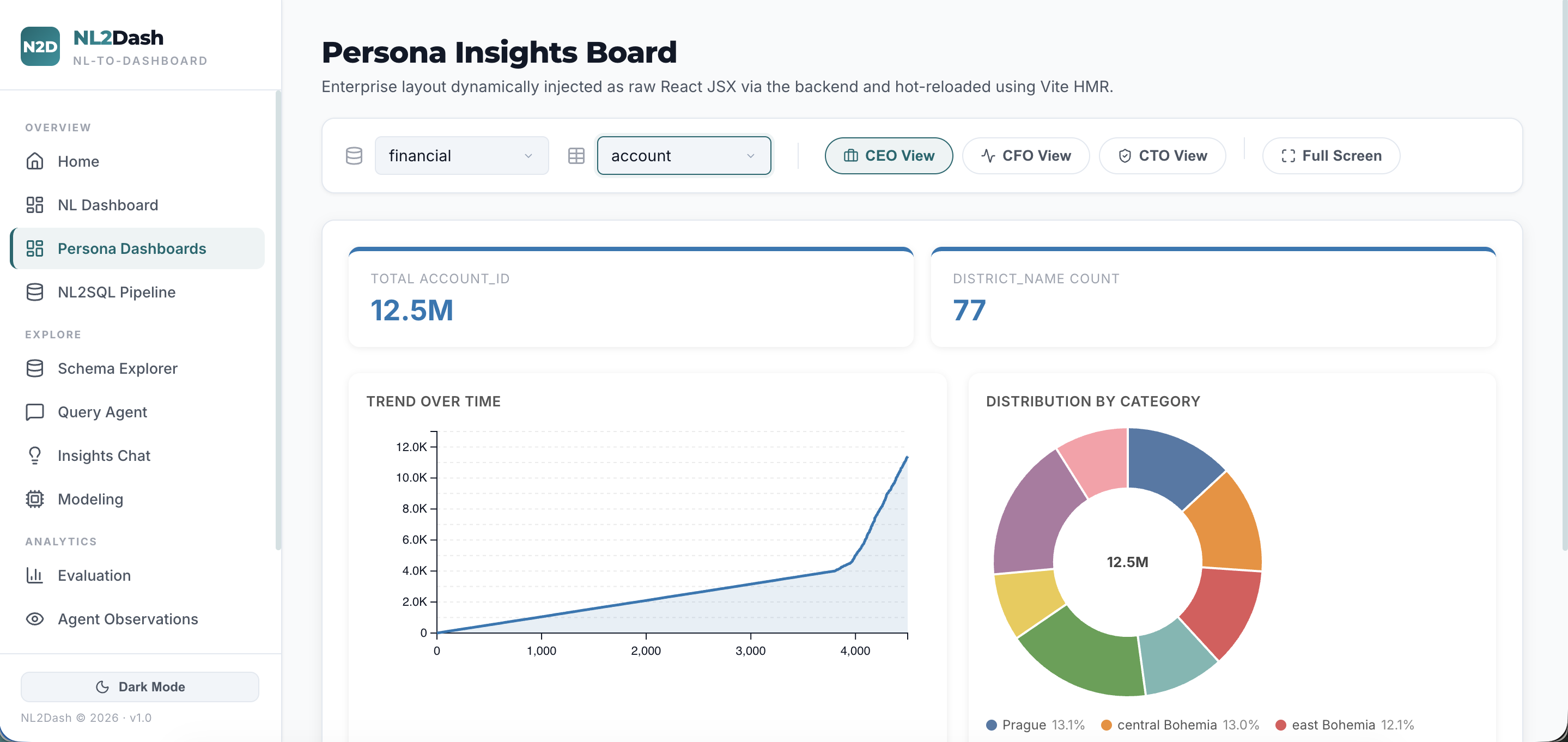
It then identifies the underlying data domain, selects the optimal chart types and layout architecture, and generates a fully interactive, production-ready React + D3 dashboard — visually tailored to the domain and calibrated to the decision-making context of the target persona (CEO, CFO, or CTO). The entire pipeline executes in a single request with zero manual configuration.
How we built it
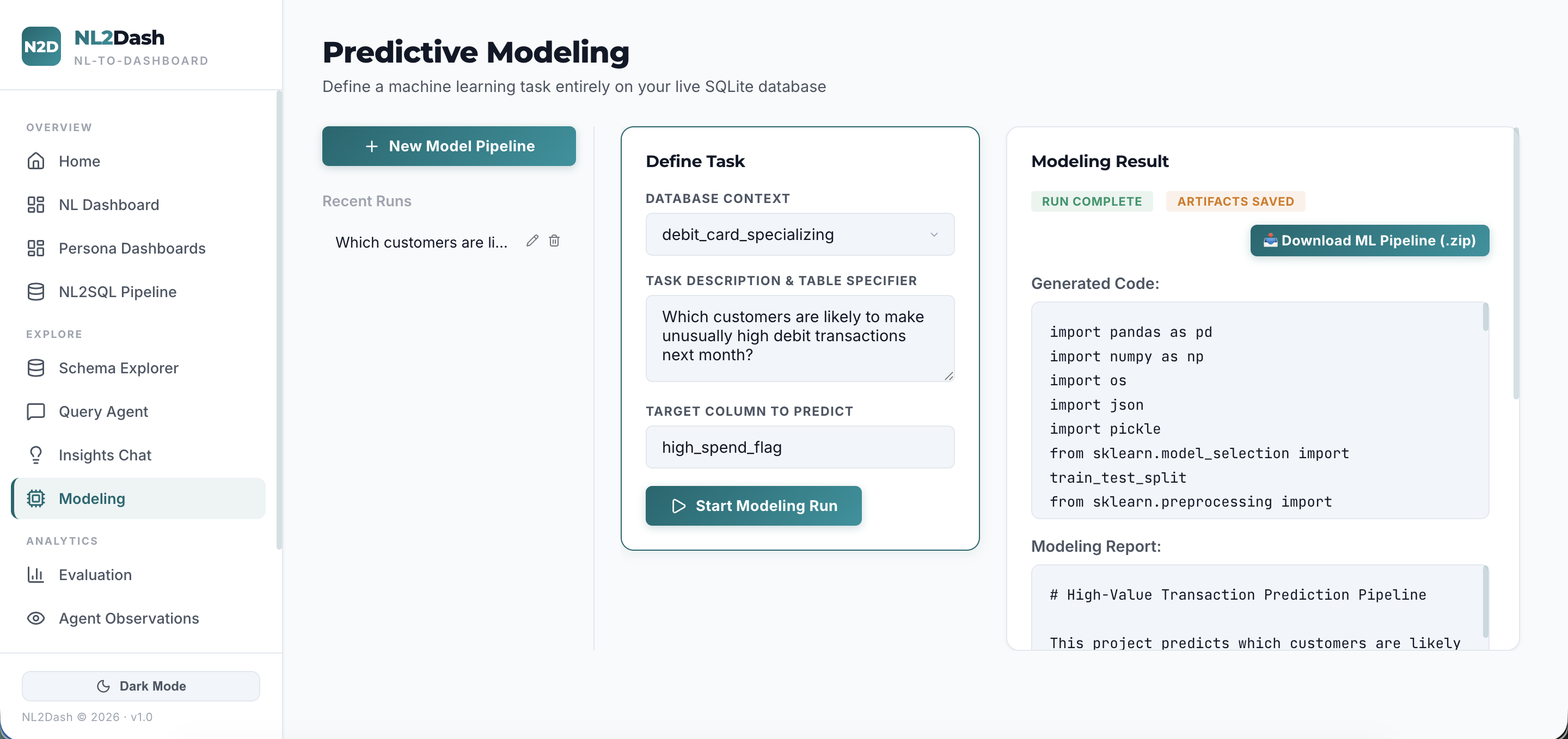
NL2Dash is architected as a monorepo containing: The Intelligence Layer (FastAPI): A unified backend that orchestrates the LangChain agentic workflows. It bridges the BIRD-Bench SQL execution engine and the PRISM insights engine. The Presentation Layer (React + Vite): A blazing-fast frontend utilizing TypeScript, Recharts, and raw D3.js. The Generator Engine: A custom heuristic template mapper (dashboard_template.py) that runs against Pandas Dataframes to execute KPI math and outputs dynamic code artifacts for instant UI rendering.
Challenges we ran into
Schema Diversity: The system had to be completely generic. Making our dashboard generator work perfectly across 11 distinctly different databases (from highly normalized financial transactions to toxicology atomic layouts) required robust error handling and pandas dtype inferences.
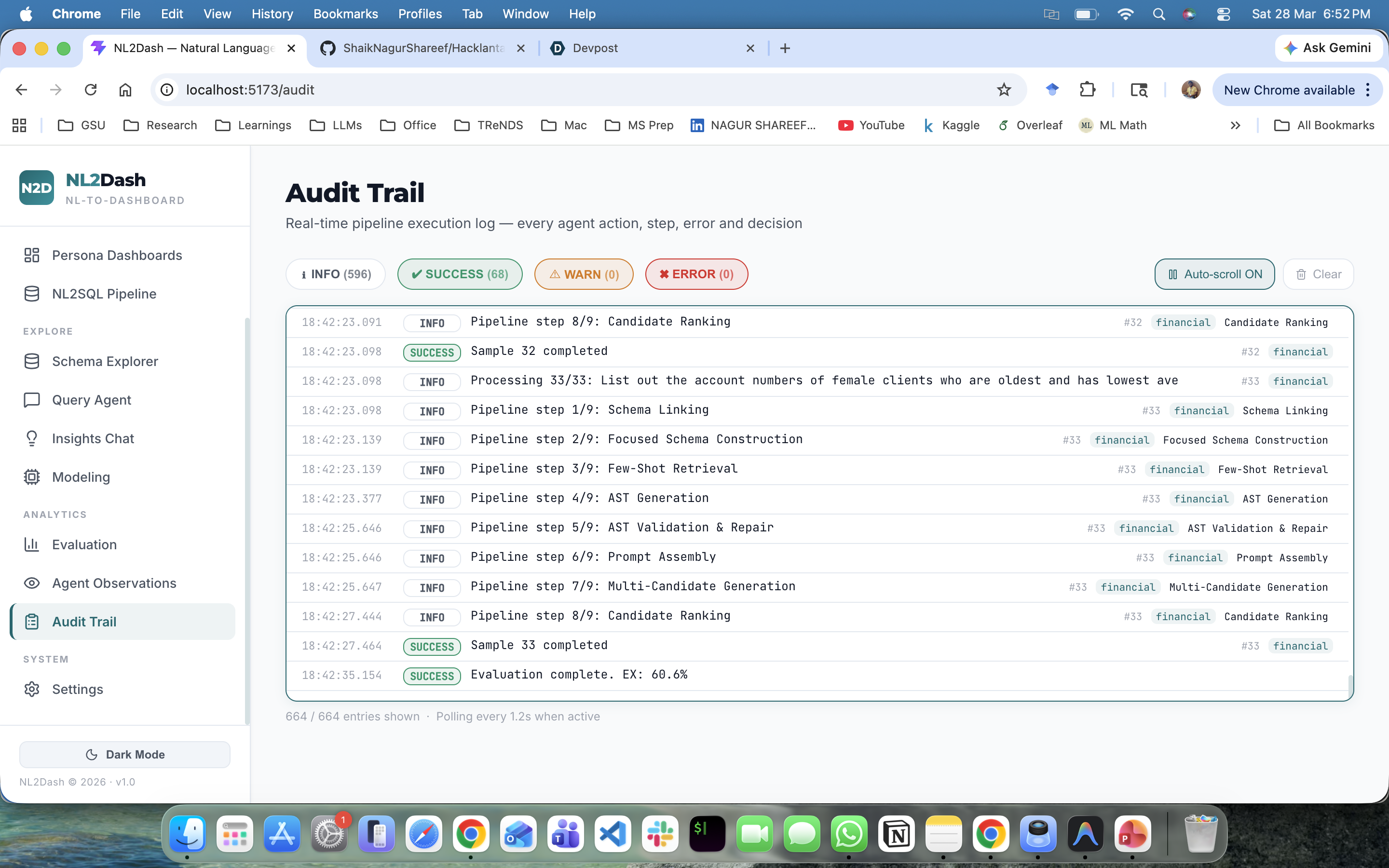
LLM Hallucinations: Restricting the AI from outputting invalid SQL or malformed React code. We solved this with strict validation loops and predefined JSON-schema specifications.

Log in or sign up for Devpost to join the conversation.