

Inspiration
Government documents, SOPs, and legal frameworks are often dense and hard to work with. Citizens struggle to understand them, and compliance officers find it difficult to apply them consistently without mistakes. Large Language Models (LLMs) can read and summarize these documents well, but they are probabilistic by nature. Because they can generate inaccurate or fabricated information, they are not reliable for making legal or policy decisions.
Our goal was to bridge this gap: use AI to interpret and understand policies, then rely on traditional, rule-based software to carry them out accurately and consistently.
What it does
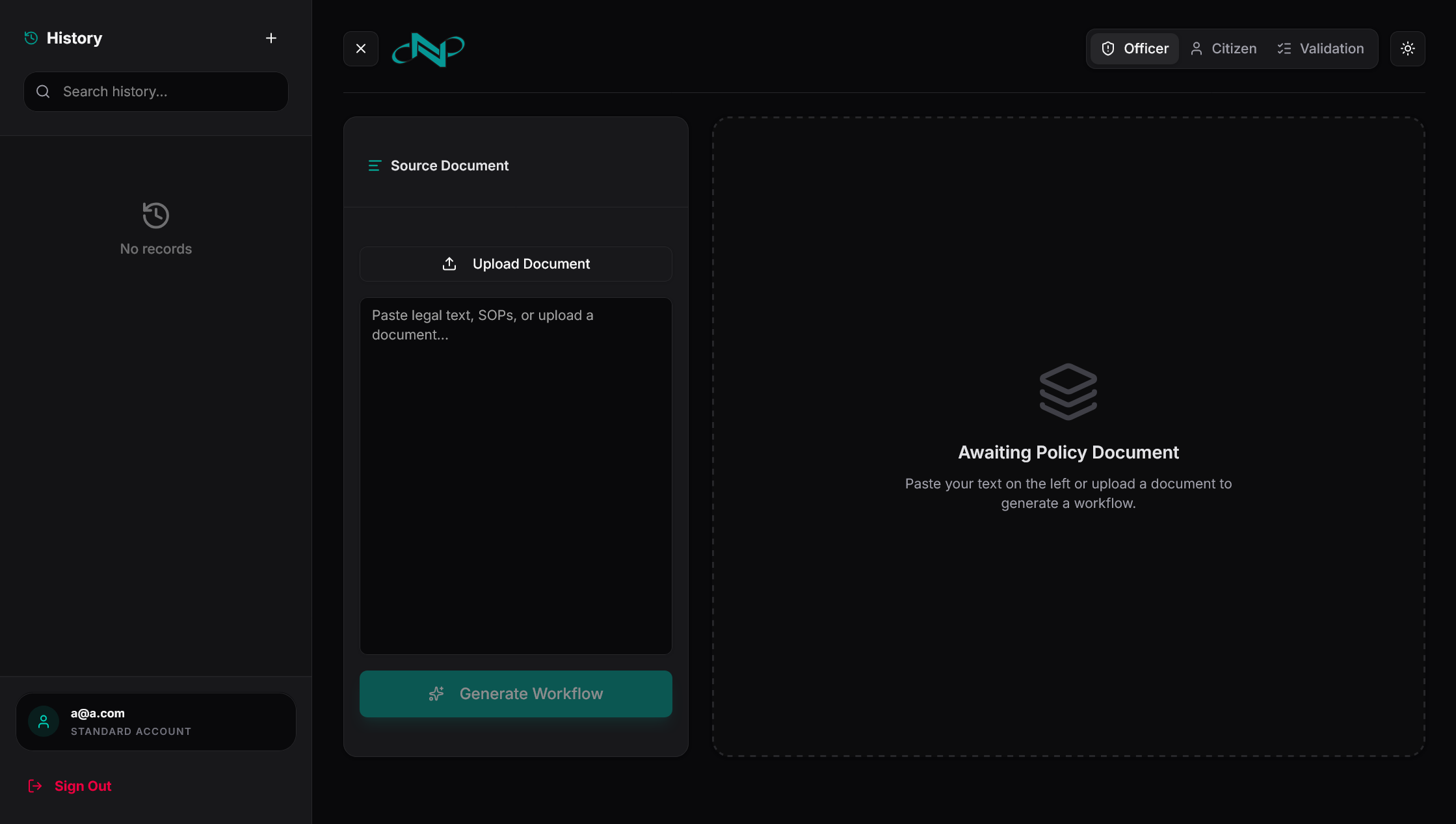
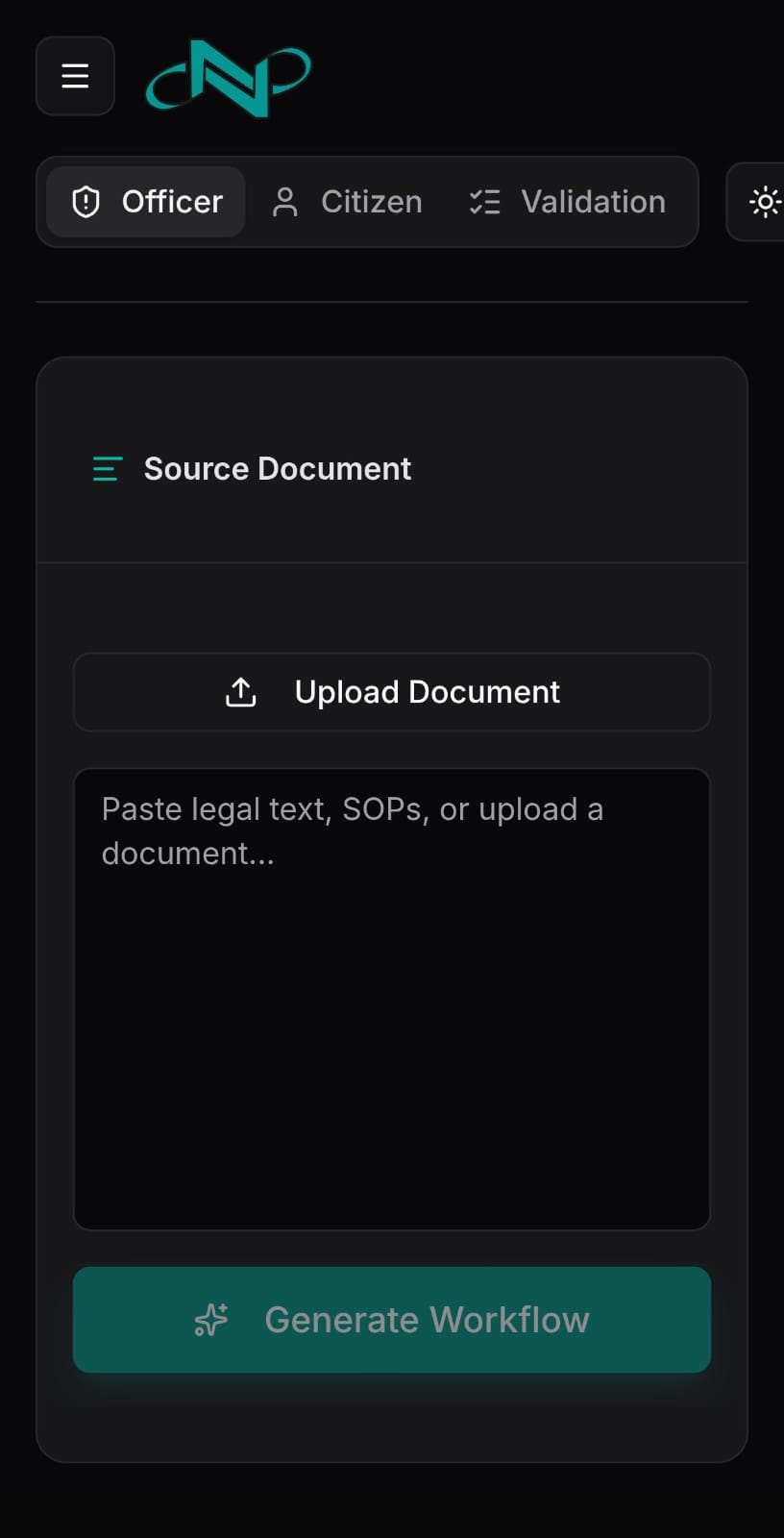
Nityam converts unstructured documents (.pdf, .docx, .txt) into structured, actionable tools through three modes:
Citizen Mode Breaks down complex policies into clear, plain-English checklists. Users see exactly what steps to follow and which documents to prepare.
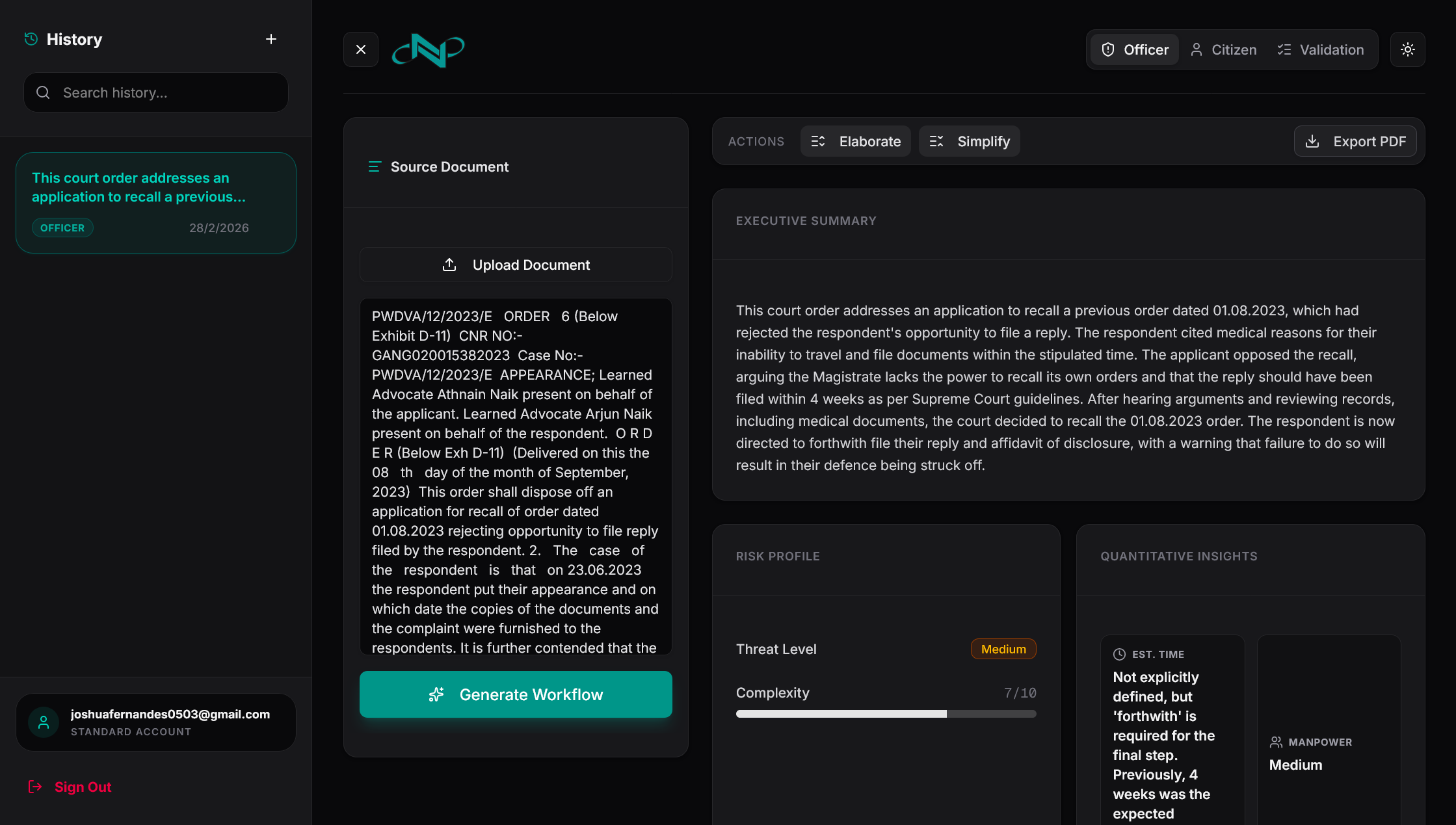
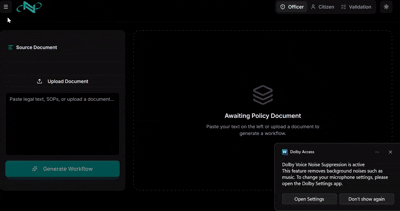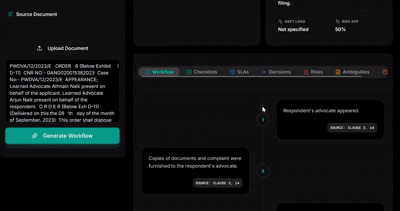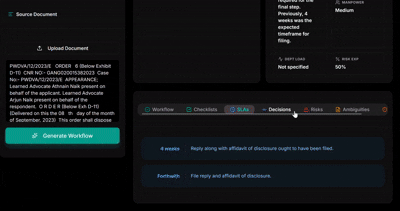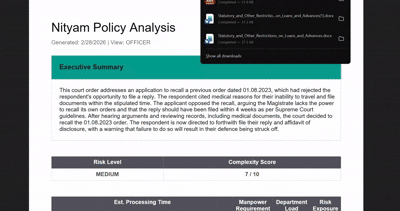
Officer Mode Creates a structured workflow with SLA tracking, risk profiling, compliance gap detection, and a full audit trail. Every required action is traceable to the specific clause in the original document.
Automated Validation Transforms policy text into a strict, machine-readable JSON schema covering entities, states, and conditional rules. The system generates a dynamic input form and applies a deterministic rules engine to evaluate case data. The outcome (e.g., Approved or Rejected) is fully predictable, with precise rule violations clearly identified.
How we built it
The application was built with Next.js, using the App Router for the frontend and API routes for the backend. Document ingestion runs entirely client-side, with pdfjs-dist and Mammoth.js extracting text from PDFs and Word files.
Unstructured text processing is handled by the Google Gemini 2.5 Flash model, prompted to produce strictly formatted JSON schema outputs.
The backend uses Supabase with PostgreSQL. By relying on the JSONB column type, the system stores highly variable data ranging from simple citizen summaries to complex, executable rule schemas in a single table without frequent schema migrations. The interface is styled with Tailwind CSS, animations are implemented with Framer Motion, and jsPDF generates the final reports.
Challenges we ran into
At first, we asked the AI to both interpret policies and evaluate cases. This led to inconsistent outcomes, including fabricated exceptions and rule deviations. The solution was to split the system into two distinct phases:
Probabilistic Compilation: The AI reads the policy and extracts rules into a structured format.
Deterministic Execution: A standard JavaScript rules engine evaluates case data against those rules, ensuring fully predictable results.
Dynamic UI Generation Since the AI extracts entities and variables dynamically from each uploaded document, the input form cannot be predefined. A dynamic form renderer was built to generate fields at runtime and safely handle strings, numbers, and booleans based on the compiled schema.
Strict JSON Enforcement Ensuring the LLM consistently returned valid, structured JSON without markdown wrappers, malformed objects, or missing arrays required extensive prompt design and careful tuning of the generation settings.
Accomplishments that we're proud of
We designed an architecture that uses AI safely in legal and government contexts. The AI handles interpretation and rule extraction, but it does not make final decisions. Execution is handled by deterministic logic, making the system legally reliable and fully auditable.
Zero-Migration Database Architecture By structuring the Supabase backend around PostgreSQL’s JSONB type, we evolved the product from a simple analysis tool into a full validation engine without changing the underlying SQL schema.
UX/UI Design The dashboard remains clean and responsive while supporting multiple views, including timelines, checklists, metrics, and dynamic forms, without becoming cluttered or difficult to navigate.
What we learned
The main takeaway is that LLMs work best when they turn messy, unstructured language into clean, structured logic. They are great at translating rules, but they should not be the ones enforcing or executing them. Parsing PDFs and Word files on the client side takes pressure off the server and reduces API calls. The result is a faster, more responsive experience for users.
What's next for Nityam
Nested Data Validation The schema and rules engine were expanded to handle arrays and nested objects. This allows the system to validate structured data such as multiple previous addresses or a list of past employment records against policy rules.
Batch Processing Compliance officers can upload a CSV file containing thousands of cases and run them through the compiled deterministic engine in one go, receiving immediate results.
API Webhooks External e-governance portals can send structured JSON case data directly to Nityam’s compiled policy endpoints and receive automated, real-time approval or rejection responses.
Built With
- gemini
- next.js
- shadcn
- supabase
- tailwind

Log in or sign up for Devpost to join the conversation.