-
-
Homescreen
-
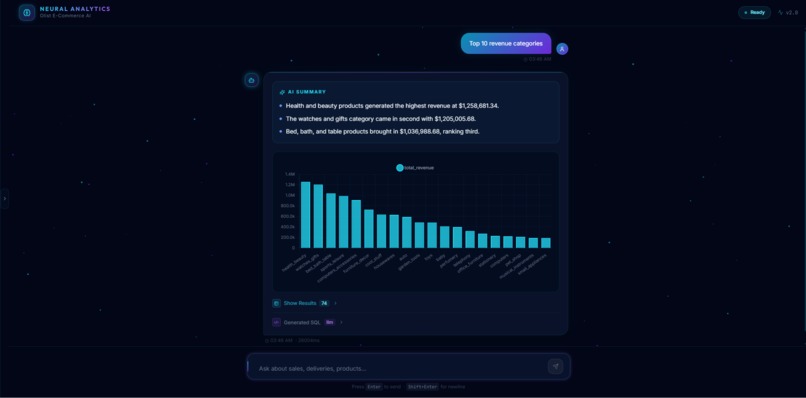
Top 10 sold item
-
Uploading csv dataset for communication
-
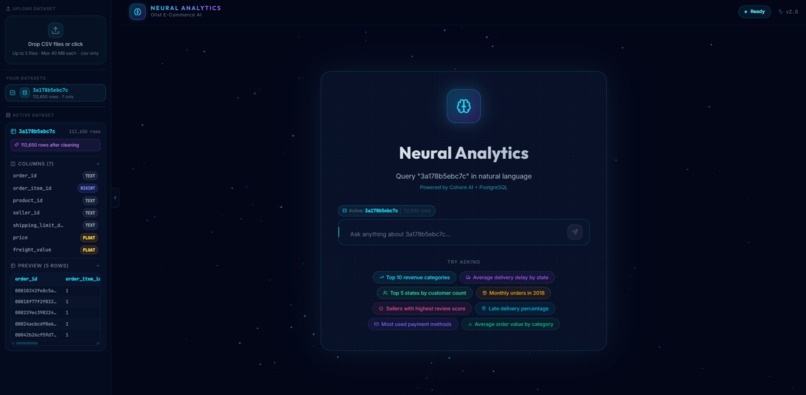
LLM read the dataset
-
Natural Language Query
-
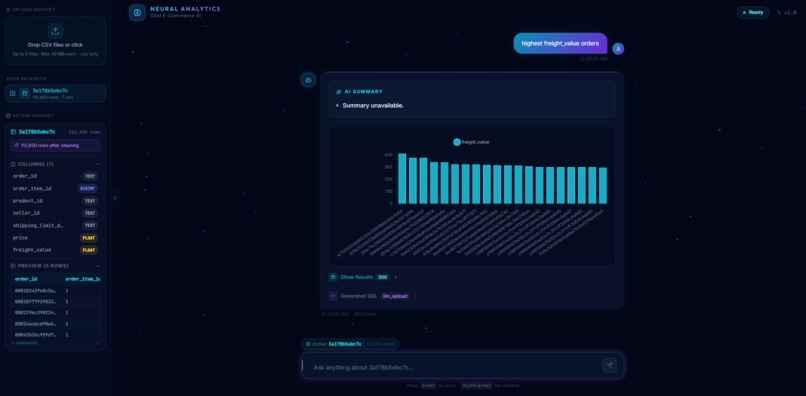
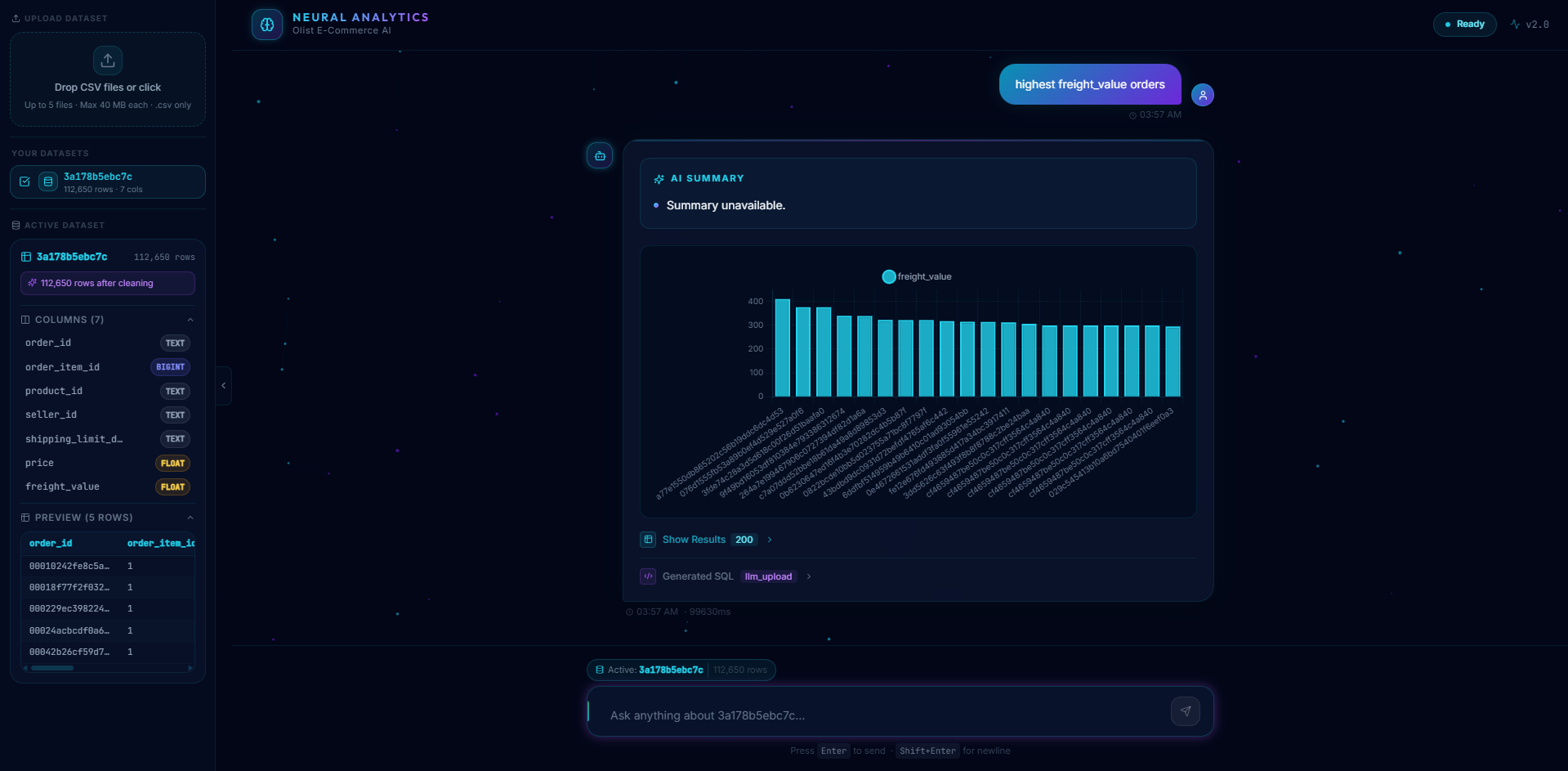
response
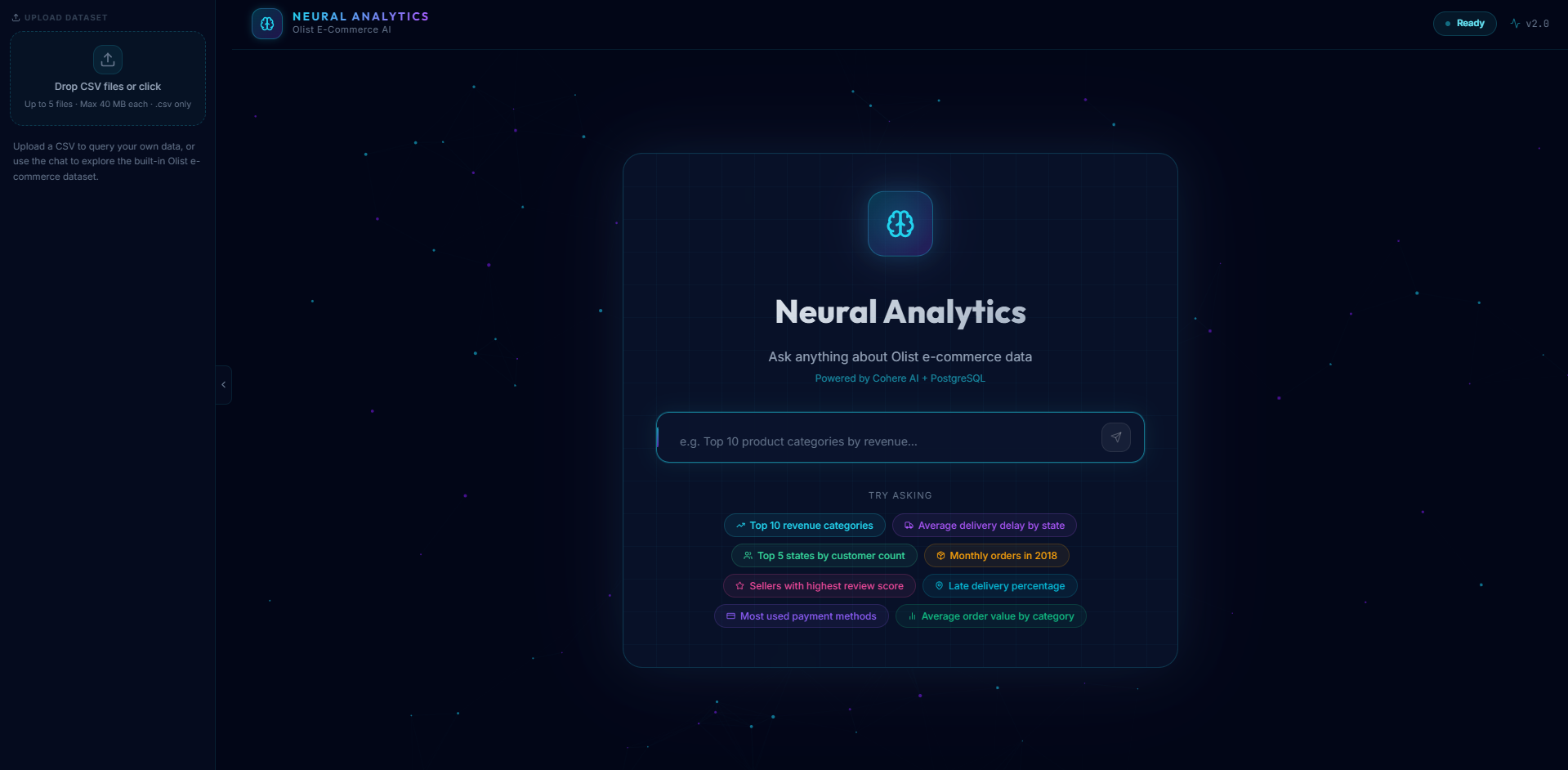
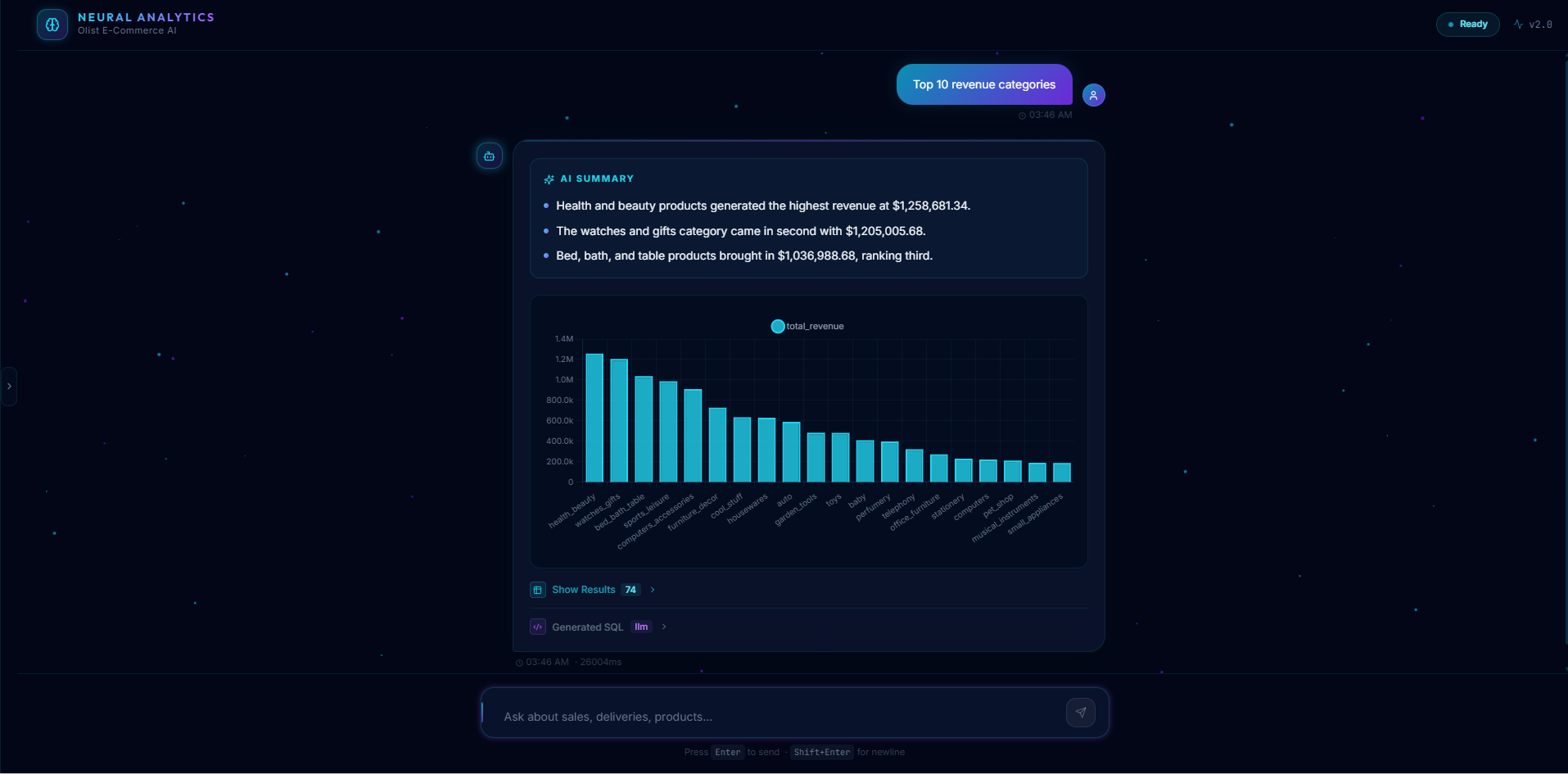
Neural Analytics — Project Summary
Inspiration
Many analysts and business users have CSV data but lack SQL skills to extract insights. Traditional BI tools require weeks of setup, complex schema definitions, and technical expertise. We
asked: What if you could upload a file and ask questions in plain English? The vision was to democratize data analysis by removing the SQL barrier entirely.
What it does
Neural Analytics is an AI-powered data exploration platform that lets users:
- Upload CSVs (up to 5 files, 40 MB each) via drag-and-drop
- Query multiple datasets simultaneously in natural language — no SQL required
- Automatically JOIN tables when questions require cross-dataset insight
- Visualize results with auto-selected charts (bar, line, pie, histograms)
- Get instant summaries of findings in plain English
- Query the built-in Olist e-commerce dataset for learning or existing data exploration
All queries are SELECT-only, with built-in safety guards against SQL injection and prompt injection attacks.
How we built it
Backend (FastAPI + PostgreSQL):
- CSV validation, schema inference, and automatic type detection
- Modular data pipeline: validation → schema detection → cleaning → PostgreSQL ingestion
- Per-table FAISS schema embeddings for semantic column retrieval
- LLM-powered SQL generation (Cohere) with auto-fix on query failure
- Multi-table support with cross-table JOIN capability
- Strict SQL security: SELECT-only enforcement, unauthorized table detection
Frontend (React + Vite + Tailwind):
- Real-time file upload with per-file progress indicators
- Sidebar dataset management with multi-select (up to 5 tables)
- Dataset preview with column types, row samples, cleaning report
- Context-aware chat with active dataset badges
- Animated chart rendering (Chart.js) + SQL viewer + data tables
- Collapsible sidebar for maximized chat space
Architecture:
- Isolated PostgreSQL schema (uploads) for user data, separate from production (olist)
- Metadata registry with JSONB for schema persistence across server restarts
- In-memory FAISS registry with lazy restoration from DB
- Two execution engines: one for Olist, one for uploads schema
- Semantic schema search to reduce LLM prompt size and improve precision
Challenges we ran into
- SQLAlchemy Parameter Binding Conflict — :specs::jsonb syntax error. Fixed by using CAST(:specs AS jsonb).
- Multi-table Prompt Bloat — Combining schemas from 2–5 CSVs caused Cohere API timeouts (35s wasn't enough). Solution: removed redundant schema chunks, increased timeout to 60s, added retry logic.
- False SQL Injection Detection — The security guard flagged SQL keywords (LIMIT, WHERE) as unauthorized tables after stripping allowed table names. Solution: expanded the keyword exclusion list to ~40 SQL keywords.
- Schema Persistence After Restarts — FAISS indexes lost on server restart. Solution: built PostgreSQL _table_registry (JSONB) + lazy restoration on demand.
- Type Inference Edge Cases — Columns with mixed types, datetime detection at high variance. Solution: pandas dtype inference + manual datetime detection at ≥80% parse rate.
- Frontend State Complexity — Managing active dataset vs. querying datasets vs. file upload state. Solution: centralized DatasetContext with selectedTables Set and derived selectedDatasets
array.
Accomplishments we're proud of
✅ Zero-SQL querying — LLM generates correct SQL for arbitrary CSVs, with semantic column retrieval ✅ Multi-table JOINs — User can select 2–5 datasets and chat queries them together automatically ✅ Production-grade safety — Strict SELECT-only, SQL injection guards, prompt injection detection ✅ Semantic schema search — FAISS + Cohere embeddings reduce prompt size while improving relevance ✅ Graceful degradation — Falls back to text-only schema context if Cohere embedding fails ✅ Real-time feedback — Per-file upload progress, auto-cleaning report, chart auto-selection ✅ Modular architecture — 5 clean backend modules (file_handler, schema_inferer, data_cleaner, table_creator, dynamic_retriever), 8+ reusable React components ✅ Auto-fix on failure — LLM corrects broken queries without user intervention
What we learned
- LLM-powered SQL generation is viable when grounded with schema context + semantic search, but prompt size is the bottleneck
- Metadata registry patterns (JSON + DB) solve the cold-start / restart problem for ML pipelines
- FAISS semantic search dramatically improves LLM accuracy by reducing irrelevant schema noise
- Multi-table queries require careful UX — ambiguity about which table to query, so explicit checkboxes + preview are critical
- Type inference is domain-specific — heuristics (e.g., ≥80% datetime parse rate) work better than one-size-fits-all rules
- Frontend state management complexity grows with features — React Context + Set collections handle multi-select cleanly
What's next for Neural Analytics
- Query History & Favorites — Save/share frequently-asked questions across users
- Column Profiling — Auto-generate summaries (cardinality, missing %, distribution) for each column
- Natural Language Joins — "Show me customers and their orders" automatically detects FK relationships
- Real-time Data Integration — Connect to live databases (PostgreSQL, MySQL, BigQuery) without CSV upload
- Data Quality Badges — Auto-detect anomalies (duplicates, outliers, schema drift) and warn users
- Multi-language Support — Generate SQL for any dialect (T-SQL, BigQuery, Snowflake)
- Mobile App — React Native version for on-the-go data exploration
- Team Collaboration — Shared workspaces, comments on queries, audit logs
- Advanced Visualizations — Dashboards, heatmaps, geo maps powered by chart libraries
- Fine-tuned Model — Custom LLM trained on domain-specific SQL patterns for higher accuracy


Log in or sign up for Devpost to join the conversation.