-
-
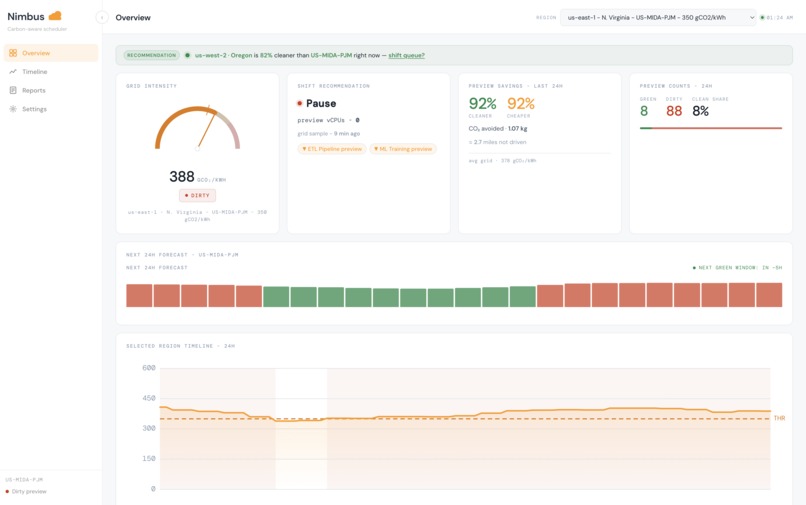
Nimbus - dashboard
-
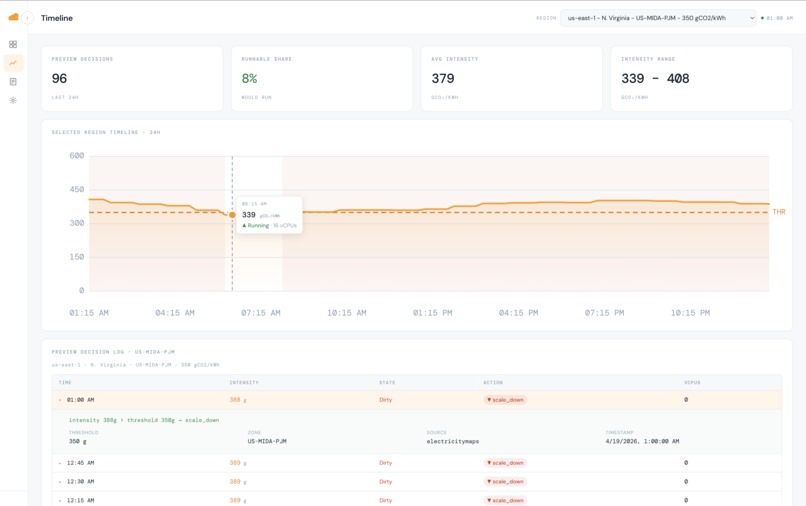
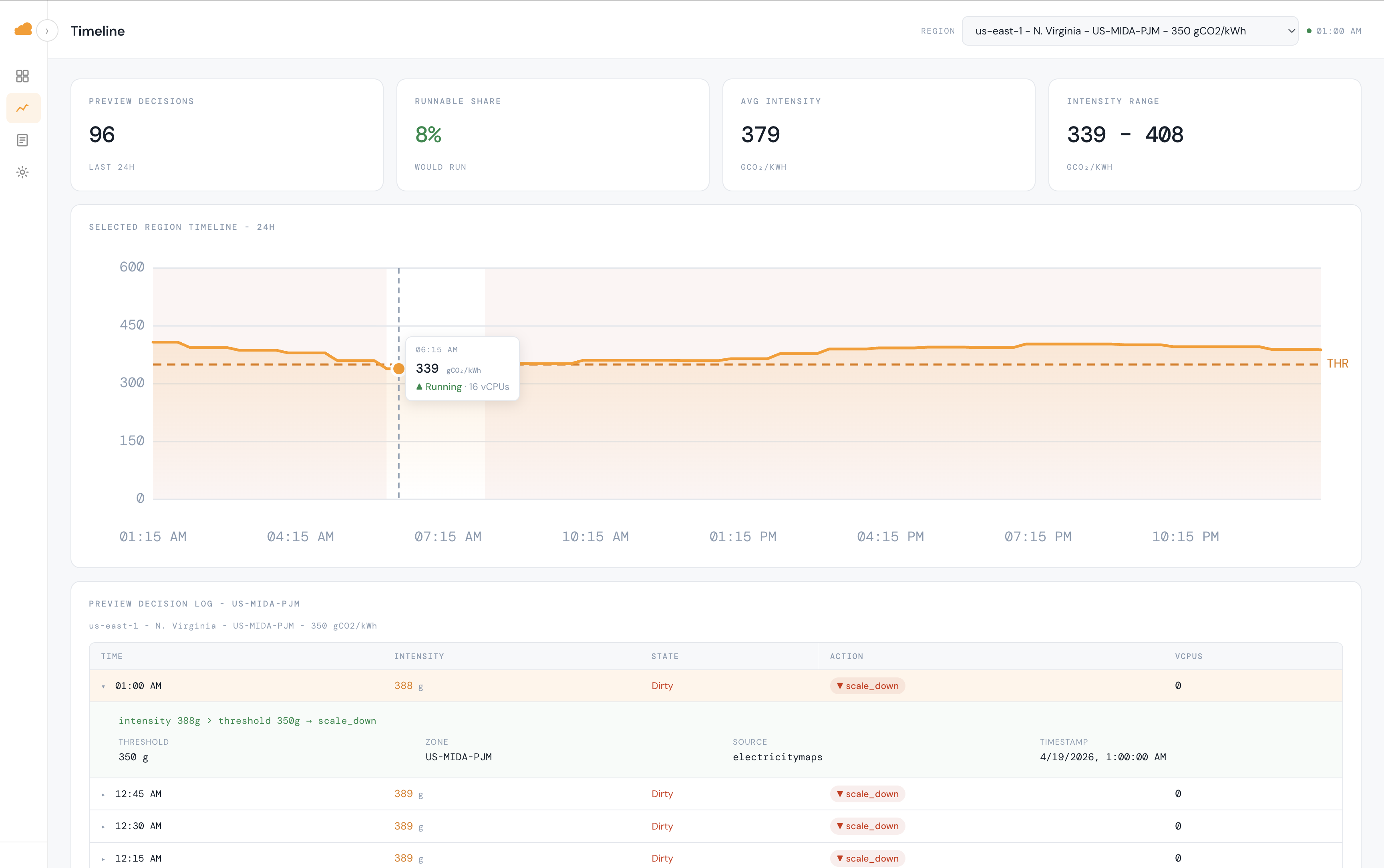
Nimbus - timeline
-
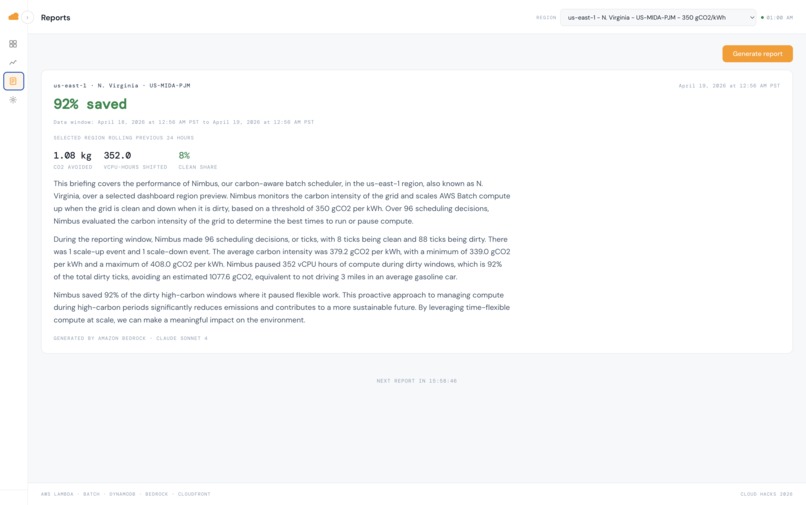
Nimbus - reports

Inspiration
Data centers already use 1–2% of global electricity, and that number is rapidly growing with AI. What stood out to us wasn’t just the scale — it was the fact that the grid isn’t clean all the time.
For example, California at noon can be ~60% solar, while at 2 a.m. it’s mostly natural gas.
Most compute jobs run whenever resources are available, without considering how clean the energy is.
Here’s the key idea: “Dirty energy” = electricity from high-carbon sources (like natural gas or coal) that emit more CO₂ per unit of power. “Clean energy” = low-carbon sources like solar, wind, or hydro.
So we asked: If a job doesn’t need to run immediately, why not run it when energy is clean?
That question became Nimbus.
What it does
Nimbus is a carbon-aware auto-scaler for AWS Batch.
Every 15 minutes, it checks live grid carbon intensity (via ElectricityMaps):
Low carbon (clean grid) → scale compute up High carbon (dirty grid) → scale compute down to zero, jobs wait
This lets flexible workloads (ML training, ETL, video processing):
- Finish the same work
- Meet the same deadlines
- But with a lower carbon footprint
👉 No changes required for developers submitting jobs.
The dashboard makes the decisions legible: a live grid meter, a 24-hour intensity timeline, per-workload breakdowns, and a clickable decision log where every row explains why it fired ("intensity 338g ≤ threshold 400g → scale_up"). A daily Bedrock-generated report translates all of it into an executive summary — the kind a CFO or sustainability officer can actually read and act on.
We also added a lightweight cross-region recommendation: when another region is at least 15% cleaner than the one you're running in, Nimbus surfaces it. We deliberately kept that as a suggestion rather than an auto-action, because if every carbon-aware scheduler flipped to the cleanest region simultaneously, you'd overload that grid and trigger the exact dirty peaker plants you were trying to avoid.
Why it matters
Carbon emissions from compute aren’t just about how much you run — but when you run it.
Nimbus turns time into a sustainability lever:
- Same infrastructure
- Same workload
- Cleaner energy usage
Key features:
- Real-time carbon-aware scaling
- Zero-code-change integration with AWS Batch
- Live dashboard
- Grid intensity meter
- 24h timeline
- Per-workload breakdown
- Explainable decision log → Every action includes reasoning like: “338g ≤ 400g → scale_up”
- AI-generated daily reports (Bedrock) → Clear summaries for non-technical stakeholders
How we built it
Backend:
- AWS Lambda
- Amazon EventBridge
- Amazon DynamoDB
- AWS Batch
- Amazon API Gateway
Frontend:
- React
- Vite
- Recharts
AI / Data:
- Amazon Bedrock (Claude Sonnet 4.5)
- ElectricityMaps API
Infrastructure:
- AWS SAM (Serverless Application Model)
Challenges we ran into
AWS Bedrock access and model configuration → Our initial model required an AWS Marketplace subscription we didn’t have, which surfaced as a confusing AccessDeniedException. We resolved this by switching to a direct foundation model ID and simplifying IAM permissions.
Cross-region scheduling tradeoffs (technical + philosophical) → Our first idea was to automatically move workloads to cleaner regions. But at scale, this creates a failure mode: if every system shifts to the same “clean” region, it quickly becomes overloaded, triggering dirty backup energy (like gas plants). → We redesigned this as a recommendation system instead of automation — less flashy, but more correct and sustainable.
Turning logs into explainable decisions → Rendering a table was easy. Making it feel like evidence was not. → We added expandable rows with thresholds, timestamps, data sources, and reasoning, transforming, the log into something users can actually interrogate and trust.
Accomplishments that we're proud of
A real, end-to-end working system
→ Nimbus isn’t a mock or simulation — it queries live grid data, writes decisions to DynamoDB, and actively scales AWS Batch in real time. When the grid turns “dirty,” compute actually scales down to zero.
All metrics are derived, not hardcoded
→ Every number — CO₂ avoided, % cleaner energy, vCPU-hours shifted — is computed from real data and decisions. We intentionally avoided fake or inflated stats to keep the system honest and credible.
Chose the correct design over the flashy one
→ Instead of auto-migrating workloads across regions, we built a human-in-the-loop recommendation system to avoid large-scale grid instability. This reflects a realistic understanding of sustainability at scale.
Decision log as an evidence trail
→ Every action is clickable, timestamped, and fully explained, allowing anyone to trace exactly why a decision was made. This turns Nimbus into a system that can be audited, not just observed.
AI-generated reports that are actually usable
→ We tuned our Bedrock pipeline to produce clear, human-readable summaries — not just raw numbers, but insights that a sustainability officer could directly use in a report or presentation.
What we learned
Carbon intensity can swing 2–3× in a single day → Energy isn’t static — the same region can shift from mostly renewable to fossil-fuel-heavy within hours. This variability is exactly what makes carbon-aware scheduling impactful, but also means you need to consider trends, not just snapshots.
Time-shifting (when you run) is safer than region-shifting (where you run) → Delaying workloads within the same region avoids stressing the grid, while blindly moving jobs across regions can create feedback loops that overload “clean” grids and trigger dirtier backup generation.
Simplicity in architecture (DynamoDB single-table design) goes a long way → By designing around clear access patterns, we avoided joins, reduced operational complexity, and kept the system scalable, fast, and easy to reason about under real-time conditions.
What's next for Nimbus
Marginal carbon intensity instead of average → Average intensity tells you how clean the grid is, but marginal intensity tells you the impact of adding new load. This provides a more precise signal for deciding whether a job should run now or wait — though it’s harder to access and often paywalled.
Per-team carbon budgets and visibility → Teams could track their own carbon footprint over time, set targets, and make informed tradeoffs between speed and sustainability. This shifts Nimbus from a backend optimizer into a decision-making tool for organizations.
Expanding beyond AWS Batch → The same scheduling logic applies to platforms like EMR, SageMaker, and containerized workloads, allowing Nimbus to become a unified carbon-aware layer across cloud infrastructure.
.
🌍 Future impact
Nimbus isn’t about reducing compute — it’s about running compute at the right time. At scale, even small scheduling shifts across millions of workloads could translate into meaningful reductions in global data center emissions — without requiring new hardware or changes from developers.
Built With
- amazon-api-gateway
- amazon-bedrock
- amazon-dynamodb
- amazon-eventbridge
- amazon-ses
- amazon-web-services
- aws-batch
- aws-lambda
- aws-sam
- axios
- claude
- cloudfront
- css
- electricitymaps
- iam
- javascript
- python
- react
- recharts
- vite





Log in or sign up for Devpost to join the conversation.