-

-
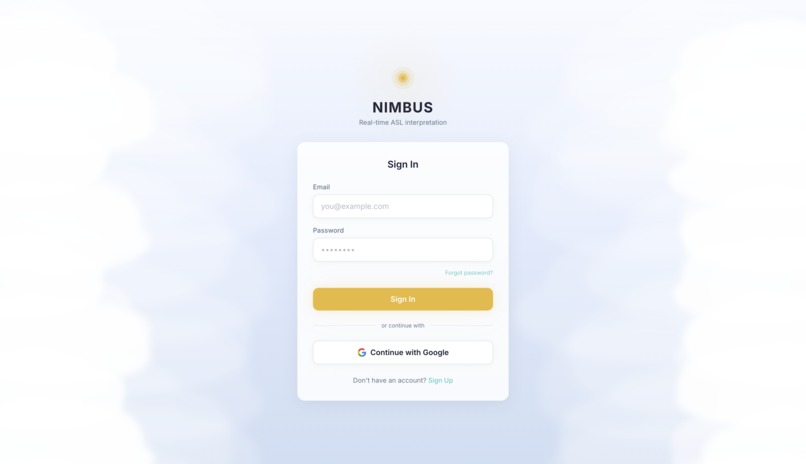
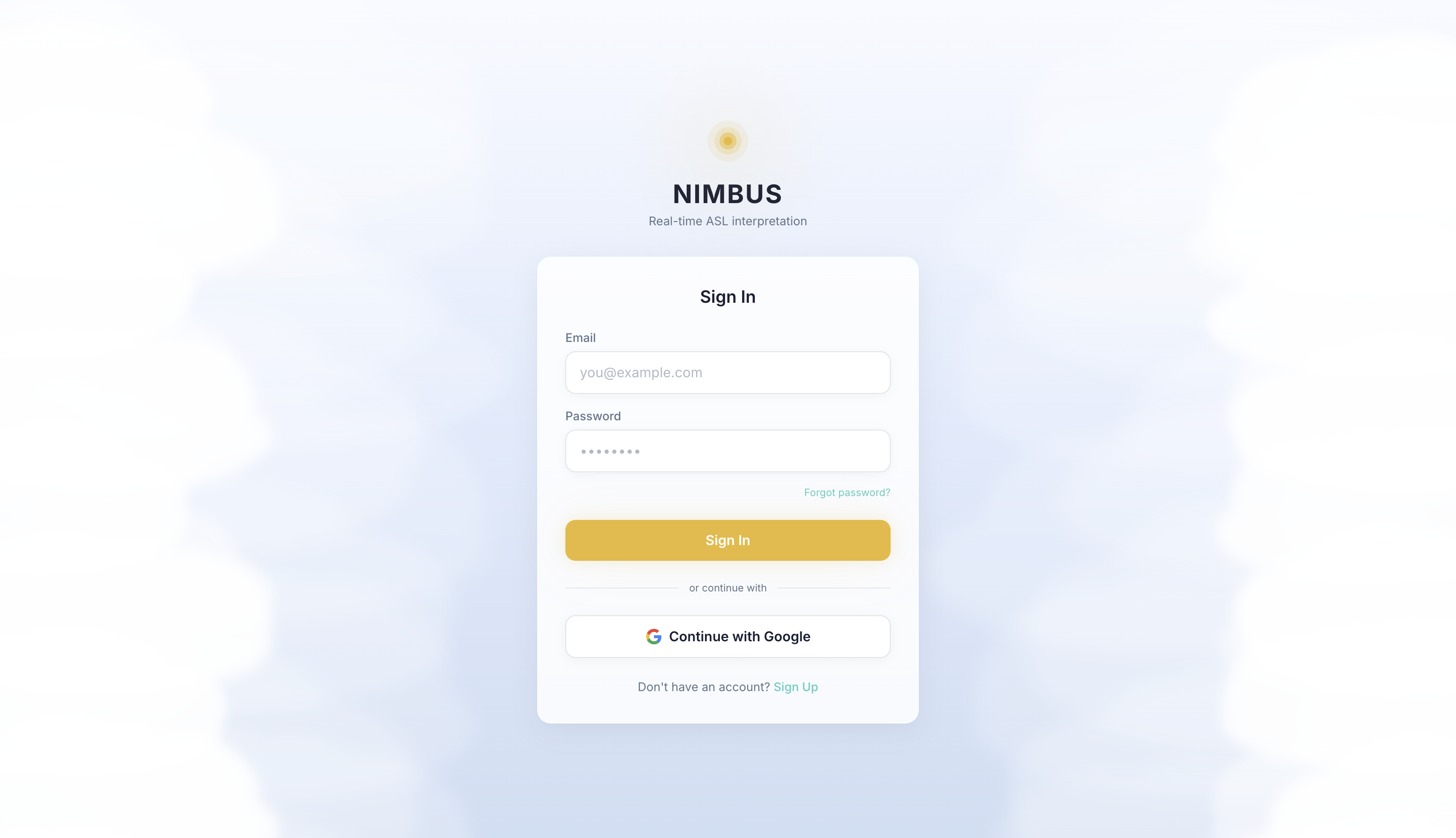
Sign in page
-
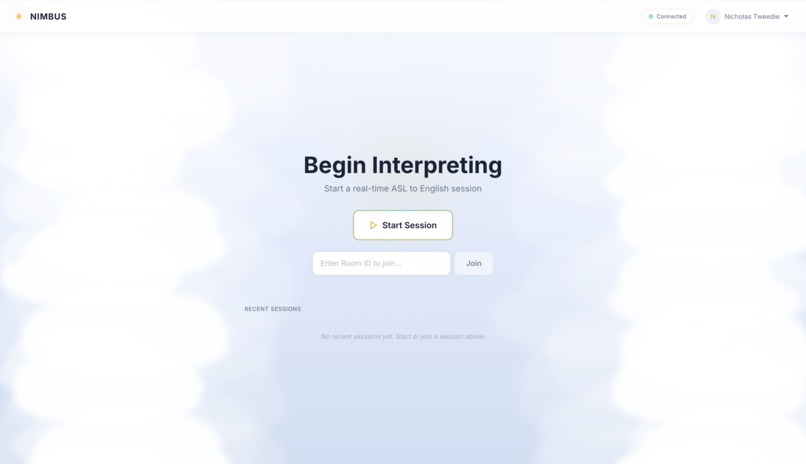
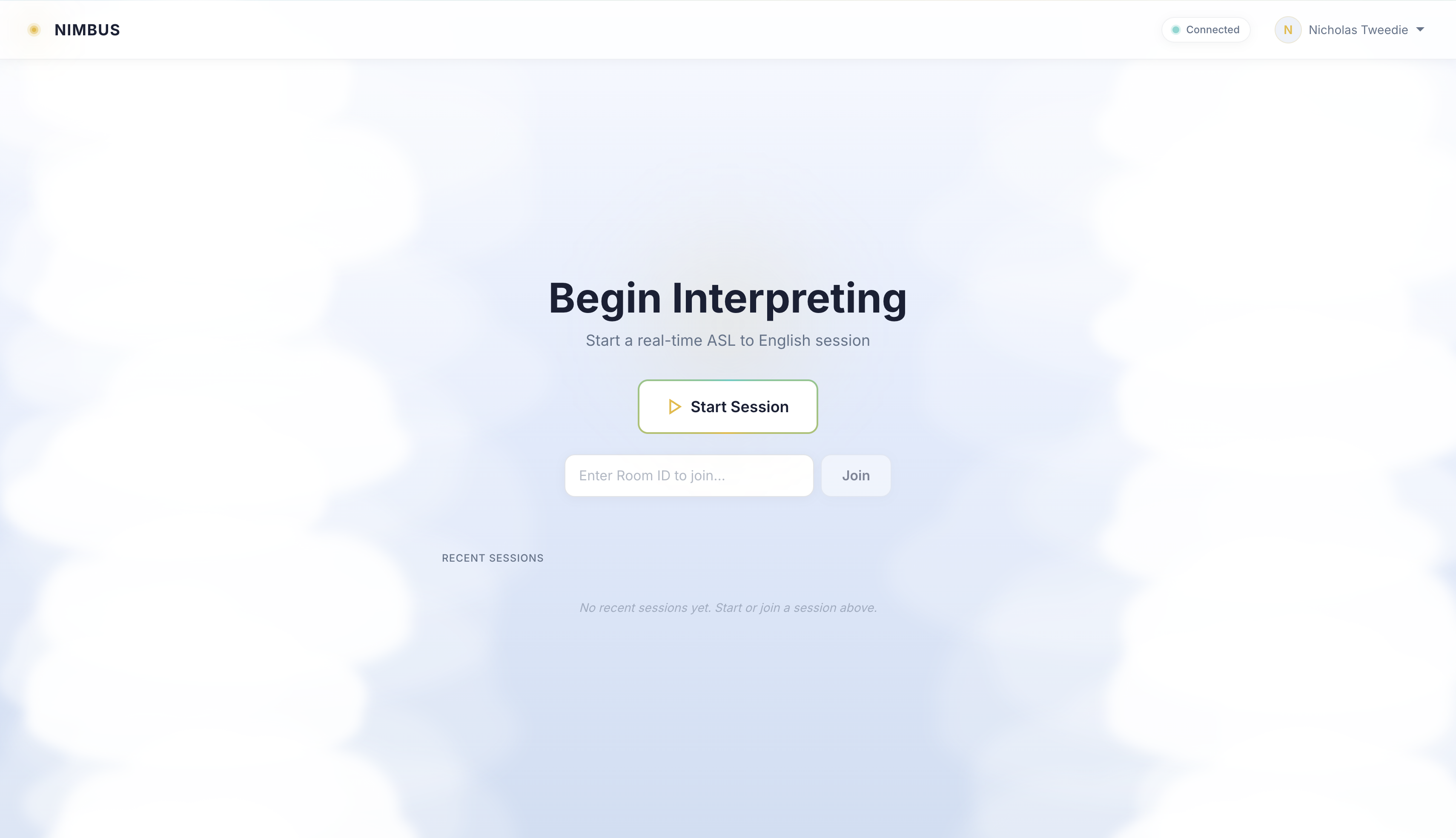
Join/create meeting

Inspiration
Deaf and hard-of-hearing users struggle to access remote meetings on Zoom, Teams, and other platforms. Professional ASL interpreters are expensive, introduce privacy concerns, and are often unavailable at short notice.
We wanted to build an accessible, affordable real-time translation system powered by a scalable cloud-native architecture. Our goal was to leverage AWS to orchestrate real-time AI pipelines while combining it with ultra-low latency edge inference—making remote communication truly inclusive.
What it does
NIMBUS captures American Sign Language (ASL) through a webcam and translates it into fluent, natural language in real time.
It delivers:
- Live captions overlaid directly on the video feed
- Natural speech synthesis using emotion-aware text-to-speech
- Emotion detection to dynamically adjust tone, pitch, and pacing
- Multi-participant sessions with WebRTC-based routing
- Speaker and gallery views for flexible collaboration
- Full transcript history stored and queryable in real time
- Global language output (English, Spanish, French, Japanese, etc.)
The system uses an edge + cloud architecture: fast inference in the browser combined with a fully managed AWS backend for real-time processing, translation, and delivery.
How we built it
Frontend (React + Vite)
- Real-Time Communication: Persistent WebSocket connections to AWS API Gateway
- Media Routing: WebRTC peer connections with Mediasoup SFU
- On-Device ML: MediaPipe extracts 55 keypoints per frame, processed by an ONNX model in a Web Worker (~15ms latency)
- Dynamic UI: Real-time captions, speaker switching, and gallery layouts
- Authentication: Secure login via Amazon Cognito OAuth
Backend (AWS Serverless Architecture — Core Focus)
Our backend is a fully event-driven, serverless system on AWS, designed for low latency and massive scalability.
Amazon API Gateway (WebSockets):
Maintains persistent, bidirectional connections for streaming ASL gloss tokens and system events in real timeAWS Lambda (Microservices Architecture):
9+ Lambda functions orchestrate the pipeline:process_gloss_stream→ buffers incoming tokensnlp_transform→ sends structured prompts to Bedrockemotion_pipeline→ processes Rekognition outputstts_dispatch→ generates and distributes audio- Additional Lambdas handle signaling, retries, session lifecycle, and cleanup
Each function scales independently and executes in sub-100ms windows.
Amazon Bedrock (Claude):
Converts ASL gloss (topic-comment structure) into fluent, grammatically correct language using context-aware promptingAmazon Translate:
Enables real-time multilingual outputAmazon Rekognition:
Detects facial emotion from sampled framesAmazon Polly:
Generates expressive speech using SSML<prosody>tags
Infrastructure (AWS Backbone)
Amazon DynamoDB:
Stores session state, gloss buffers, and transcript history with TTL-based auto-cleanupAmazon S3:
Temporary storage for TTS audio with presigned URLs for efficient deliveryAmazon EC2 (Mediasoup SFU):
Dedicated media routing layer, decoupled from signalingAWS CloudFormation (SAM):
Full Infrastructure-as-Code enabling reproducible deployments
Data Flow
Webcam → MediaPipe (keypoints) → ONNX (edge inference) → API Gateway → Lambda → DynamoDB (buffer) → Bedrock (NLP) → Translate → Rekognition (emotion) → Polly (TTS) → S3 → Broadcast to clients
Accomplishments that we're proud of
Real-Time Serverless AI Pipeline
Achieved end-to-end latency under ~1.5 seconds using AWS servicesEdge + Cloud Hybrid Optimization
Reduced inference latency from ~800ms (cloud) to ~15ms (edge ONNX)Advanced Sentence Boundary Detection
Dynamic triggers (token count, elapsed time, idle detection,[EOS]) produce natural sentence flowFault-Tolerant Distributed System
Every service has graceful fallback:- Bedrock fails → raw gloss displayed
- Polly fails → captions still shown
- No silent failures
- Bedrock fails → raw gloss displayed
Emotion-Aware Speech Pipeline
Rekognition + Polly + SSML produces expressive, human-like outputScalable Multi-User Architecture
WebRTC + EC2 SFU + WebSocket signaling enables real-time collaborationFully Serverless + Cost Efficient
Pay-per-use infrastructure (~$1–2/day per active room) with automatic scaling
What we learned
AWS Enables Rapid System Design at Scale
Combining API Gateway, Lambda, DynamoDB, Bedrock, Rekognition, and Polly allows complex real-time systems to be built quicklyEvent-Driven Architectures Are Powerful
Decoupling each stage of the pipeline improves scalability and reliabilityLatency is Critical
Even small delays compound—forcing optimization of cold starts, payload size, and execution pathsASL Requires Contextual Intelligence
Gloss tokens alone are insufficient; LLMs are necessary for fluencyServerless State Management is Challenging
DynamoDB requires careful handling of atomic updates and TTL cleanupEmotion Improves UX
Expressive speech significantly increases realism and engagement
What's next for NIMBUS
Deep AWS Optimization (SageMaker Integration)
Deploy a full ASL transformer model on SageMaker endpointsZoom & Teams Integration
Inject captions directly into native CC pipelines and route audio seamlesslyVocabulary Scaling
Expand from 100 → 2,000+ ASL signs (WLASL dataset)Multilingual Sign Language Support
Extend to BSL, LSF, and other global sign languagesSpeech-to-ASL Translation
Build a reverse pipeline using 3D avatars for full bidirectional communication
Built With
- amazon-web-services
- aws-api-gateway-v2
- aws-bedrock
- aws-cloudformation
- aws-cloudwatch
- aws-cognito
- aws-dynamodb
- aws-ec2
- aws-lambda
- aws-lambda-powertools
- aws-polly
- aws-rekognition
- aws-sam
- boto3
- docker
- github-actions
- mediapipe
- mediasoup
- node.js
- onnx-runtime-web
- opencv
- pydantic
- pyjwt
- python
- react-19
- react-router
- sagemaker
- stun/turn
- tailwind-css
- tgcn
- typescript
- vite
- web-speech-api
- webrtc-api
- websocket-api
- websockets
- wlasl-2000

Log in or sign up for Devpost to join the conversation.