-
-
little photo of the team nothing much
Inspiration
We were inspired by the difficulty that visually impaired individuals face on the daily basis and were then motivated by the plethora of computer vision models found on the Qualcomm AI Hub. Our main focus was to create a practical application that can be used right now.
What it does
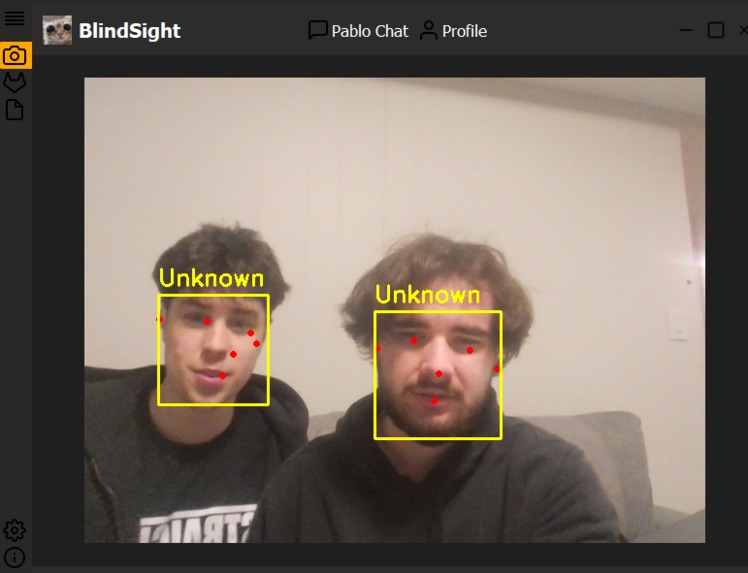
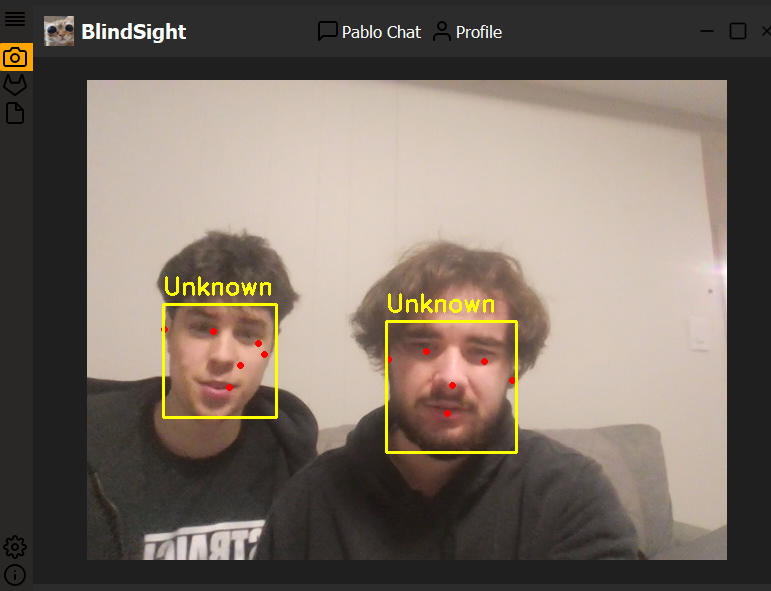
Blindsight is a pair of "smart glasses" that has a local AI assistant called Pablo.AI , leveraging both local AI models found on the Qualcomm AI Hub, and other local models, to allow the visually impaired to interact with their environment more effectively. Based on the given input, blindsight can either detect what objects are in frame, and chat back with a list of the objects it detects, or detect faces in frame. It will either chat back with the name of the person it detects if it has seen them before, or it will prompt the user to name the user in front of them and save images of the person for future detection. Blindsight can be fully interacted with and used by a blind person simply through voice their voice. However we also build a python GUI to better demonstrate our features.
How we built it
We implemented a llama model to process user input and detect under what context the user wants to interact with the environment. Does the user wish to know who they are talking to? Or maybe they wish to know which one of their cats just entered the room. The llama model chooses which model to use based on the user's input: object detection or facial detection. Blazeface and Deepface are used for facial recognition, and the YOLOv3 model is used for object detection. In addition, we implemented the small whisper English model to process user voice input.
Challenges we ran into
Our biggest challenge was building the software around the speed of the local models; we noticed that the facial detection and llama models took the longest. Specifically, blindsight continuously records the user's voice and as such prompting llama every few seconds would take too much time. Additionally, we also noticed that running a facial detection every frame also took a toll on the speed of the program. We addressed these issues by preprocessing and caching user inputs, so that if a user asks a common question we don't need llama to think about the appropriate response, and picking appropriate times to run facial detection.
Accomplishments that we're proud of
Were most proud of both integrating multiple local AI models together seamlessly into a functioning application and tailoring this application specifically for blind people in that it can be fully used via vocal input.
What we learned
We learned how to keep in mind both usability and performance when using local AI models. The limitation in hardware forced us to think of unique ways to process our data.
What's next for Blindsight
We plan to integrate new Text to speech voices and allow inputs of other languages besides English using other whisper models or similar for a more personalized experience. We also would like to plug in more AI models, such as gesture recognition, to increase the use cases of our product.
Built With
- pyqt5
- python
- tensorflow



Log in or sign up for Devpost to join the conversation.