Inspiration
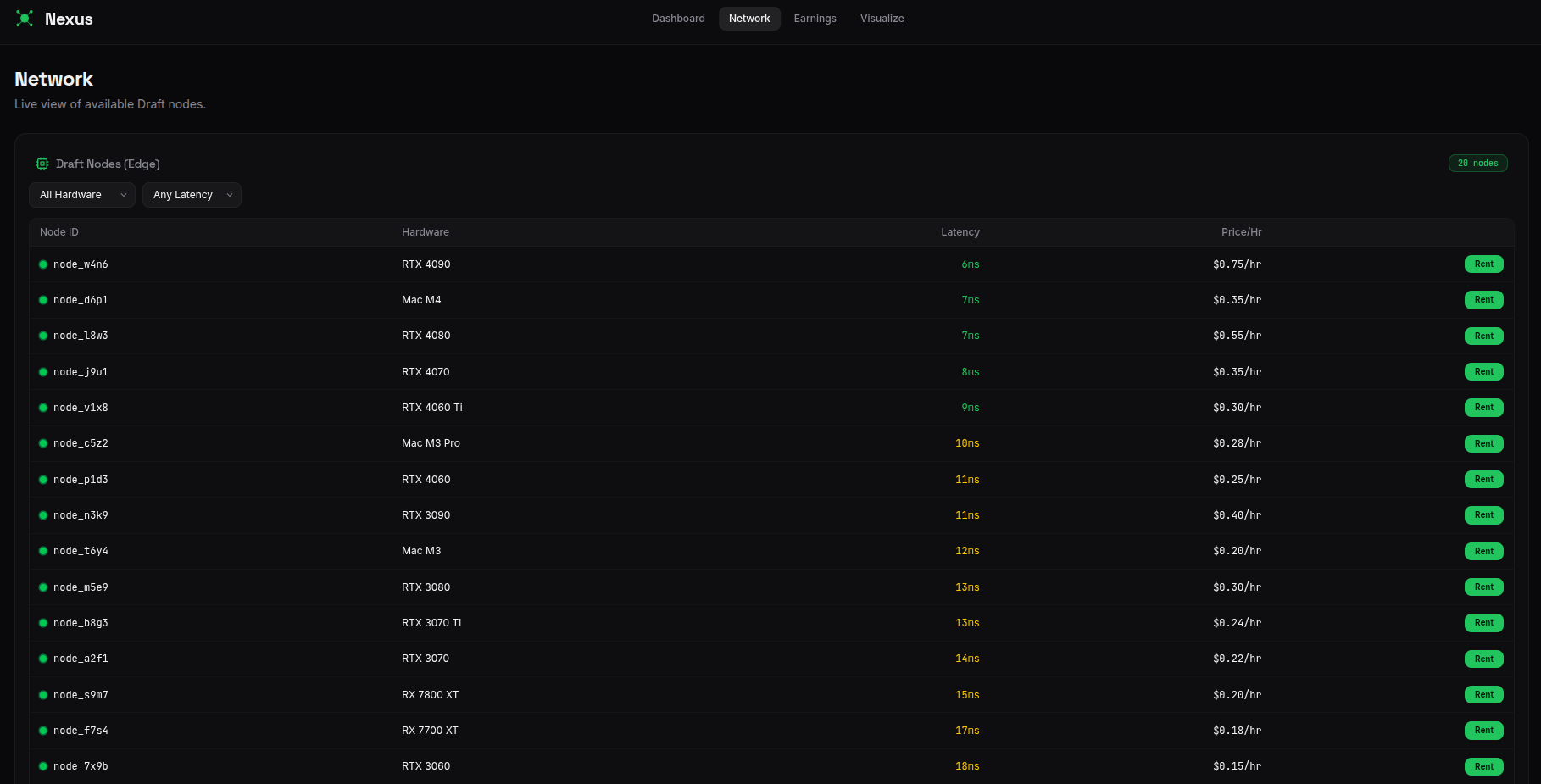
The environmental impact of a single AI conversation is equivalent to running a microwave for one minute and throwing away a bottle of water. Yet today’s AI inference stack still assumes you must run everything inside large, expensive GPU clusters inside data centers. That leaves a massive inefficiency: millions of consumer GPUs (laptops/desktops) sit idle most of the day as cheap and efficient sources of compute.
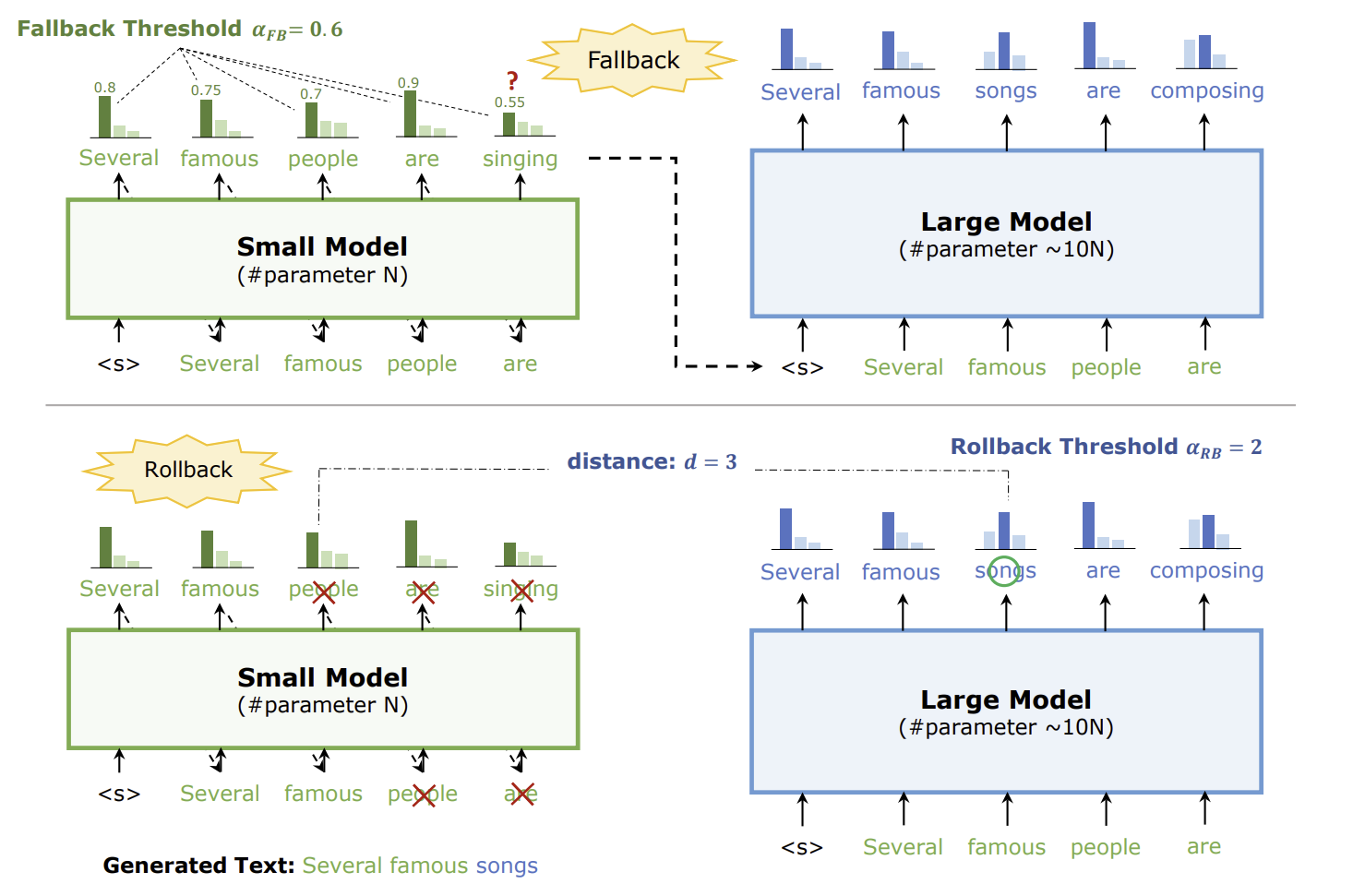
Nexus is motivated by a simple observation: most of the “wasted” work in LLM inference happens during sequential token-by-token generation. Newly developed techniques like speculative decoding can shift much of that work onto smaller models. If we can offload the right compute to otherwise idle GPUs, we can reduce cost and environmental impact without sacrificing output quality.
What it does
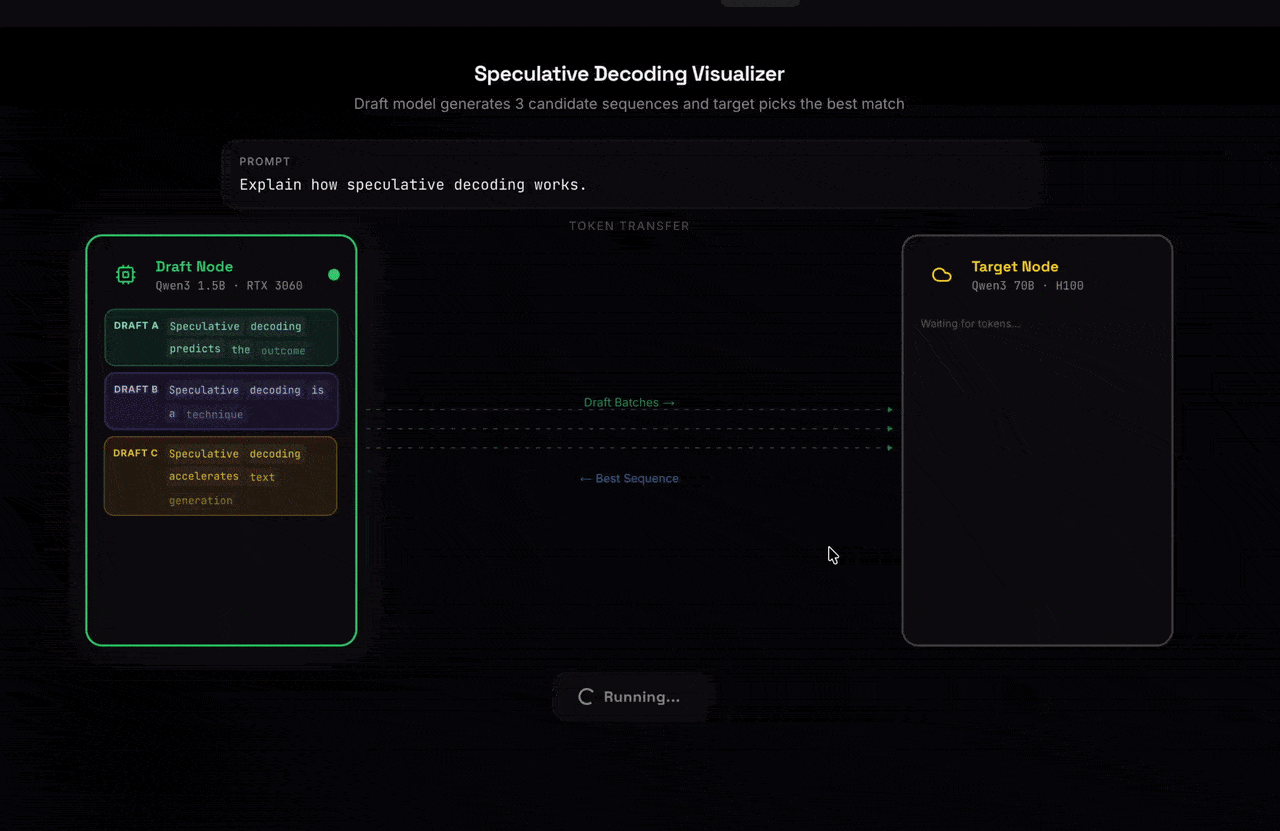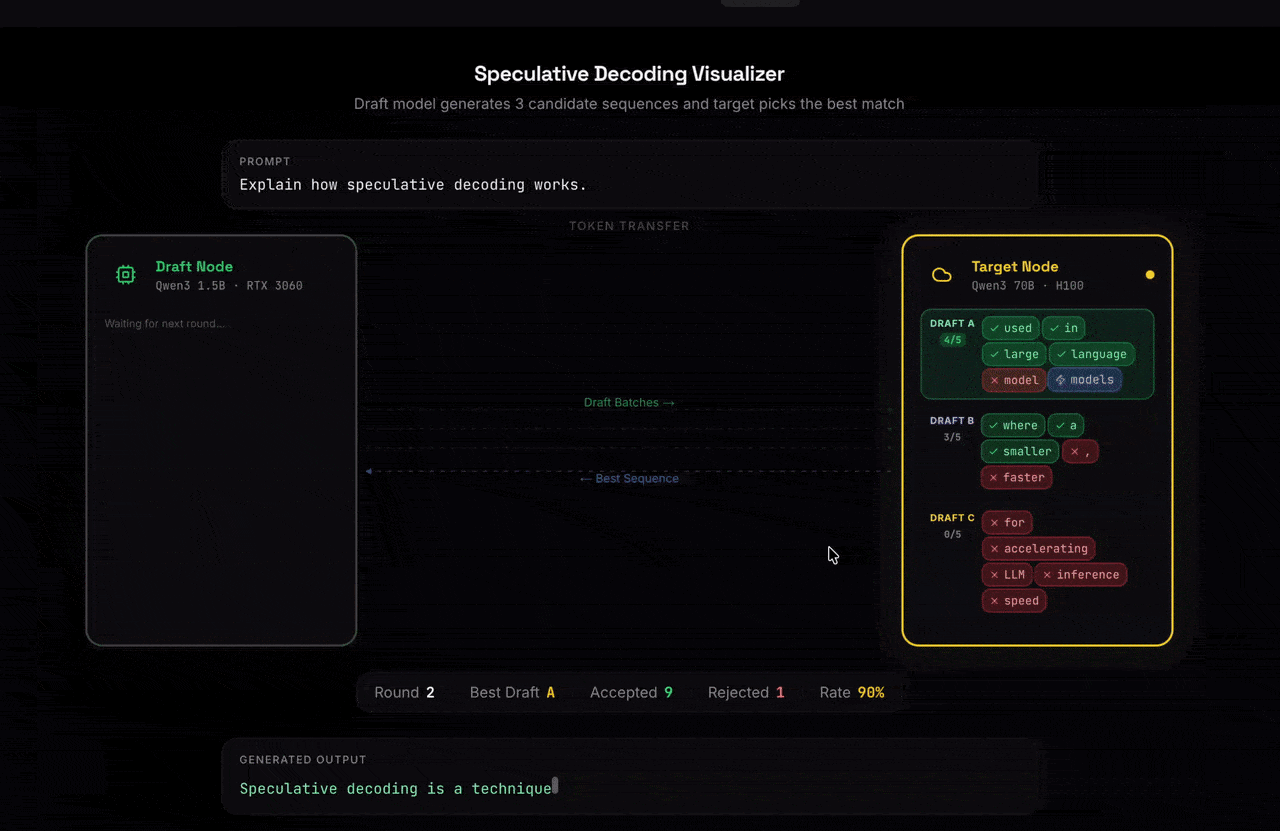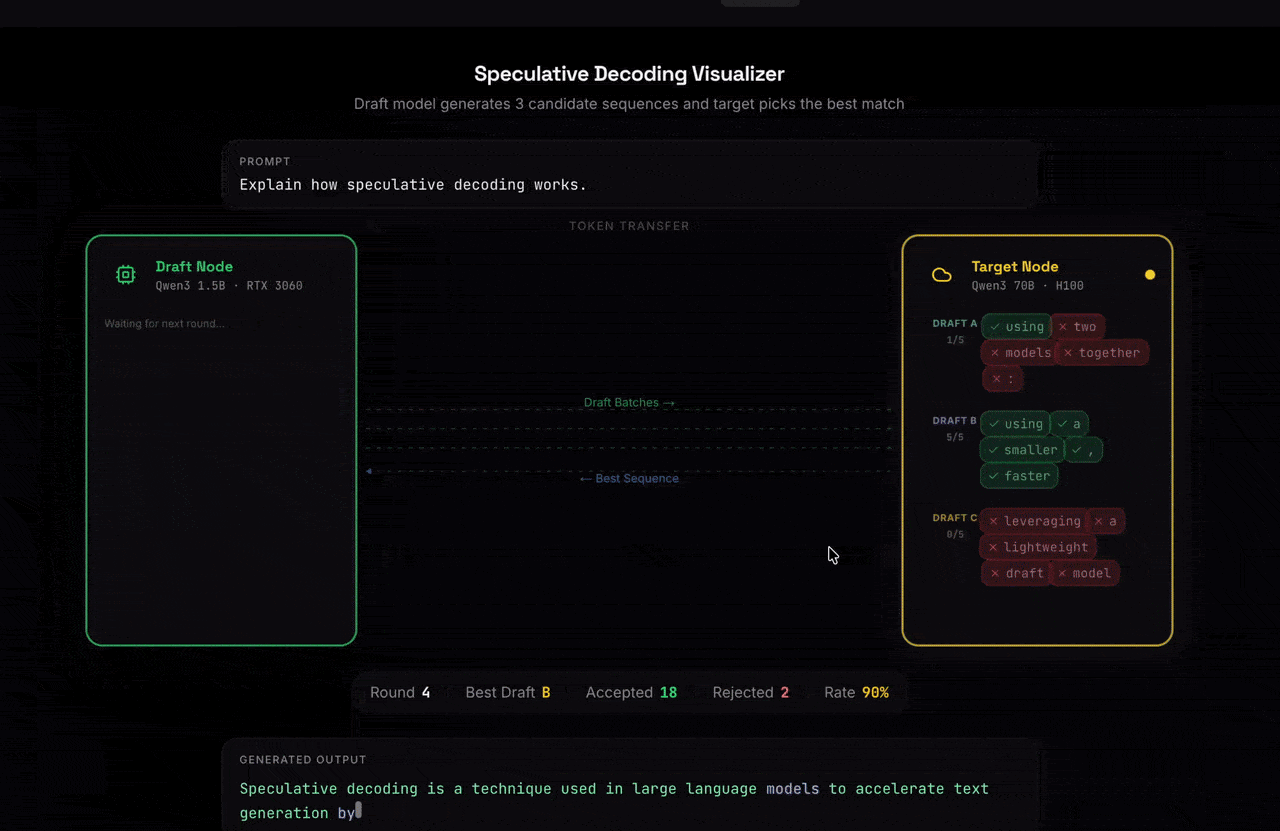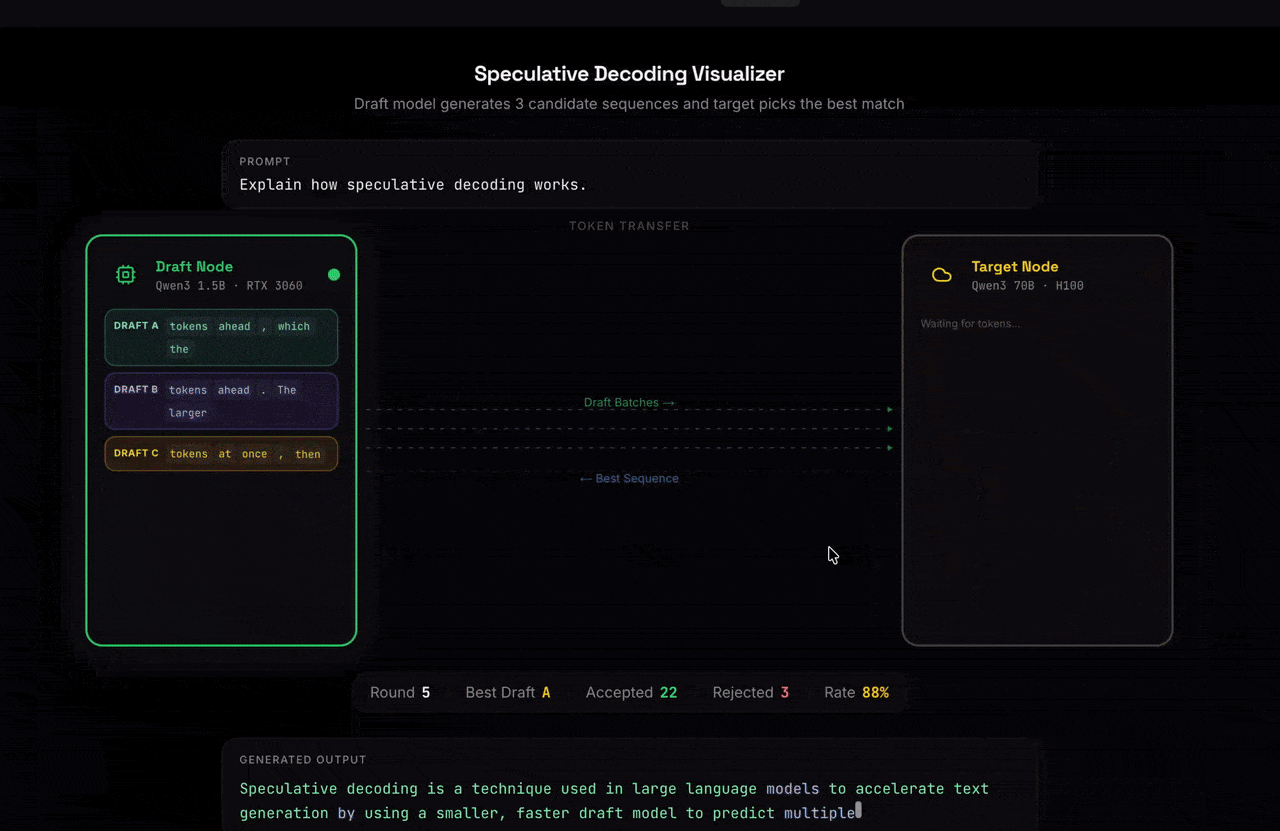
Nexus is a global marketplace for AI inference built on speculative decoding. Users can rent out their GPUs to run small, fast draft models that propose a sequence of tokens which are efficiently verified by a large model in parallel. This architecture enables:
- Lower latency: fewer expensive, sequential target-model decoding steps
- Higher throughput: the verifier does fewer passes per response, and draft generation is massively parallelizable
- Lower cost per generated token: expensive GPU time is reserved for verification rather than brute-force generation
- Better hardware utilization: idle consumer GPUs do useful work (drafting) instead of sitting unused
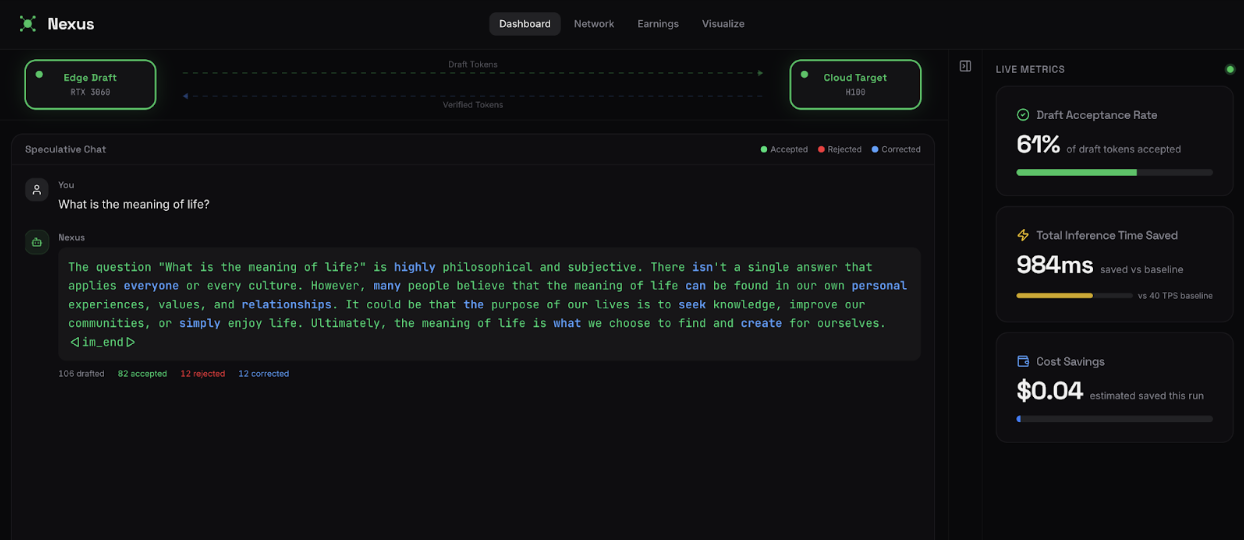
From a user perspective, Nexus exposes a simple inference API. Under the hood, it routes requests across the marketplace, orchestrates draft generation, batches verification, and returns final outputs with high accuracy.
How we built it
Our inference platform was built on the speculative decoding algorithm, where a small draft model predicts multiple tokens ahead and a large target model verifies them in parallel, reducing the number of expensive decoding steps.
To run the small draft model, we used vLLM, an engine for open-source AI inference with optimizations like KV-cache management, continuous batching, and high-throughput serving. While our architecture is model-agnostic and can support any draft-verifier pair that shares a tokenizer, we selected Qwen 2.5 0.5B as the draft model and Qwen 2.5 70B as the verifier. This pairing provided the strongest empirical performance gains in our speculative decoding framework.
We hosted our Qwen 2.5 70B verifier model on Modal to enable reliable, high-throughput GPU inference without managing infrastructure. Modal’s autoscaling and GPU orchestration allowed us to rapidly iterate on system design and support concurrent draft-model streams. This reduced operational overhead and let us focus on optimizing the speculative decoding pipeline rather than deployment engineering.
Finally, our frontend was designed and hosted using Vercel v0. We chose Vercel for its simplicity and fast deployment workflow, which allowed us to quickly ship and update the application with minimal configuration overhead. Its managed hosting environment provided reliable performance and scalability without requiring us to maintain custom frontend infrastructure.
Challenges we ran into
- Tokenization alignment between draft and target models required strict consistency, small mismatches caused verification failures.
- Acceptance rate tuning was delicate. Too small a draft model reduced acceptance length and too much draft compute reduced cost savings.
- Network overhead between distributed draft nodes and the verifier had to be carefully batched to prevent latency from offsetting compute gains.
- Serving a 70B model under concurrency introduced GPU memory pressure, requiring careful KV-cache and batching strategies.
Accomplishments that we're proud of
Nexus inference is 20% cheaper than comparable modern cloud inference options by combining speculative decoding with distributed idle GPUs. Here’s how we did it:
- Built an end-to-end speculative decoding pipeline with a real draft/verifier pair.
- Demonstrated stable concurrent draft streams feeding a centralized verifier.
- Reduced verifier passes per response by accepting longer draft prefixes in single verification steps.
- Achieved measurable cost reduction without changing the final model output
What we learned
We learned that speculative decoding is less about “clever prompting” and more about systems-level efficiency: memory bandwidth, batching, and acceptance rate distributions matter as much as raw FLOPs.
We implemented and validated three core optimizations:
- Multi-candidate drafting: Instead of generating one draft continuation, we generate multiple candidates per step and batch them for verification. This increases the probability that the verifier can accept a longer prefix in a single pass, improving throughput.
- Optimistic verification: We structured the pipeline so the system proceeds under the assumption that most draft tokens will be accepted, only falling back when divergence is detected. This reduces unnecessary synchronization overhead and improves wall-clock latency.
- KV caching: Efficient cache reuse and management significantly improved throughput, especially under concurrency, and made the verifier layer more stable.
What's next for Nexus
We believe the concept of Nexus can significantly alleviate the current shortage of computing we have, while giving access to the general population to contribute and reap the rewards of the continued usage of LLMs. While we have made significant strides in optimizing Nexus, there are still many optimizations that we want to implement to cut down from 20% to 50% cost savings:
- Decentralize the verifier layer to support multiple providers, route verification to the cheapest/closest GPU that meets latency constraints, add fallback strategies to preserve reliability
- Dynamic draft selection and adaptive speculation to automatically choose draft size and length based on the prompt and acceptance rates
- Real market with spot pricing for draft GPUs, cost tiers, and smart routing based on node performance
These optimizations will make the case for Nexus even stronger and solidify it as a robust platform for distributed model inference.


Log in or sign up for Devpost to join the conversation.