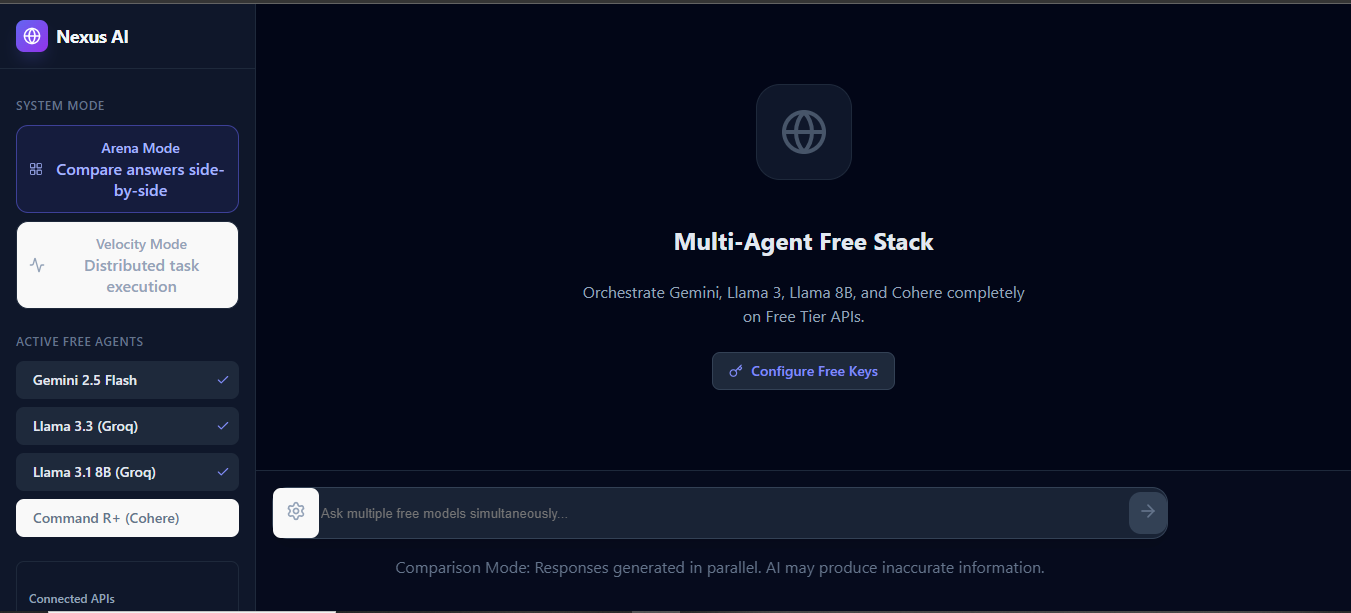
Multi-Agent Nexus: The Free-Stack AI Orchestrator Inspiration The inspiration for the Multi-Agent Nexus came from the rapid fragmentation of the AI landscape. We noticed that users are locked into silos (like ChatGPT or Gemini) due to subscription fatigue. We were driven by the question: "Can we build a system that rivals enterprise-grade AI orchestration using entirely free or open-access APIs?" Our goal was to democratize access to advanced model comparison (Arena Mode) and distributed task execution (Velocity Mode) without requiring the user to spend a dime on inference costs.
How We Built It (Powered by Kiroween) We built this application using a React + Vite frontend, styled with Tailwind CSS. The development process was accelerated by Kiroween’s suite of tools:
Spec-Driven Development: Instead of "vibe coding," we used Kiro to strictly define our "Dual-Mode Architecture" upfront. We specified exactly how Arena Mode would handle parallel API streams and how Velocity Mode would visualize the pipeline before generating logic.
Steering Docs & Error Feedback: This was crucial. When we encountered API errors, we fed the raw console logs back into Kiro’s steering context. This allowed the AI to "self-heal," instantly identifying that llama-3-70b was deprecated and suggesting the migration to llama-3.3-versatile.
Real-Time Preview: We utilized Kiro’s live preview to fine-tune the "Velocity" animation timings, ensuring the complex UI felt responsive even during API latency.
Challenges We Faced The journey was filled with technical hurdles regarding the volatility of the AI ecosystem:
The "API Graveyard": Our biggest challenge was model deprecation. During development, Groq decommissioned their Llama 3 endpoint, breaking our build. We had to rapidly refactor our API handlers to point to stable, newer aliases.
CORS Restrictions: Building a purely client-side app meant battling Cross-Origin Resource Sharing errors. We pivoted from Hugging Face's inference API to running Llama models via Groq’s high-speed, CORS-friendly API to solve this.
Quota Limits: We initially targeted paid providers but hit quota limits immediately. This forced a creative pivot to a "Free Stack" architecture (Gemini Flash + Groq).
Accomplishments We Are Proud Of
The "Zero-Cost" Architecture: We successfully engineered a "Free Stack" that chains Google Gemini Flash, Llama 3.3, and Cohere Trial APIs. We proved you don't need a corporate budget to build complex multi-agent systems.
Privacy-First Design: We implemented a "Bring Your Own Key" (BYOK) system using local storage. No API keys are ever sent to our servers; everything happens directly in the user's browser, ensuring maximum privacy.
Resilient Error Handling: We built a self-diagnosing UI. Instead of crashing, the app detects specific API errors (like "Quota Exceeded" or "Model Not Found") and guides the user to the Settings panel with specific instructions on how to fix it.
What We Learned We learned that the "Free Tier" AI ecosystem is far more capable than most developers realize. By combining the speed of Groq with the reasoning of Gemini Flash, we achieved performance parity with paid systems for many tasks. We also learned the vital importance of "defensive coding" when working with LLMs—expecting APIs to fail or change versions is a requirement, not an option.
What's Next for Nexus AI
Local LLM Support: We plan to integrate Ollama support, allowing users to run models like Llama 3 entirely offline on their own hardware, removing the need for API keys altogether.
Smart Routing: We want to implement an "Auto-Router" agent that analyzes the user's prompt and automatically selects the best model (e.g., Llama for coding, Gemini for creative writing) without manual selection.
RAG & File Uploads: Adding the ability for users to upload PDF documents so the agent swarm can perform distributed analysis on large datasets.

Log in or sign up for Devpost to join the conversation.