Every year, Google Cloud Next brings together 30,000+ developers in Las Vegas. Behind the scenes, there's an enormous human assembly line: someone designs invitation emails, someone sends them. Travelers spend hours booking flights and hotels. A presenter walks on stage with a slide deck while someone else advances the slides.
We asked: what if that entire journey was powered by AI agents working together? Not a chatbot. Not a text box. A living system of agents that hear your voice, speak back naturally, see images you share, generate visuals in real-time, and coordinate with each other through the A2A protocol.
The announcement of ADK and A2A at Google Cloud Next '25 gave us the tools to build it. The irony was too good to pass up: we'd use the very tools announced at the conference to recreate the conference experience itself.
What it does
Next Live is a 3-stage interactive AI experience that mirrors the real conference journey:
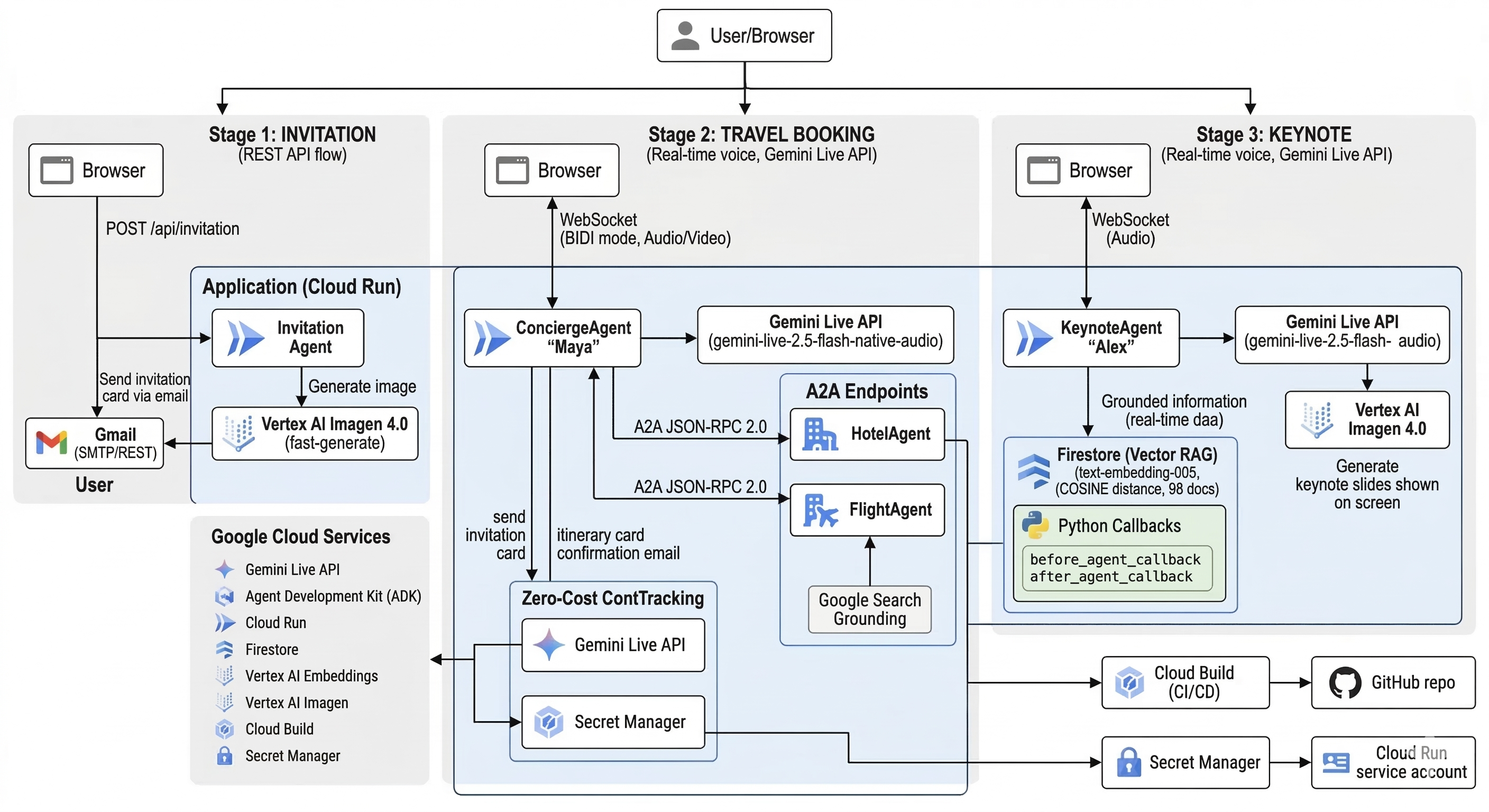
Stage 1: Invitation - Enter your email. An AI agent generates a personalized invitation card using Imagen 4.0 and sends it to your inbox.
Stage 2: Travel Booking - Call Maya, a voice-powered AI travel concierge. Tell her your city. She coordinates with a FlightAgent and HotelAgent through the A2A protocol to find real flights and hotels. Share a photo of a hotel you like and she'll analyze it. She confirms the booking and emails your itinerary.
Stage 3: Keynote - Join Alex, an AI keynote presenter who delivers a structured presentation about what happened at Next '25. He generates slides in real-time with Imagen, grounds every fact in 264 minutes of real session transcripts via Firestore vector search, and you can interrupt him with questions anytime.
5 AI agents. 2 A2A connections. 8 Google Cloud services. All running on a single Cloud Run instance.
How we built it
Backend: FastAPI server on Cloud Run with two WebSocket endpoints (one for Maya, one for Alex) and two A2A JSON-RPC endpoints (HotelAgent, FlightAgent). All 5 agents built with the Google Agent Development Kit (ADK).
Voice: Both Maya and Alex use gemini-live-2.5-flash-native-audio with bidirectional WebSocket streaming. The model thinks natively in audio, producing natural prosody and enabling mid-sentence interruption.
A2A Protocol: Maya orchestrates. When she needs flights, she sends an A2A JSON-RPC 2.0 message to the FlightAgent mounted at /a2a/flight/. The FlightAgent uses google_search grounding to return real, live flight data. Same pattern for hotels. Both A2A agents run in-process on the same server.
Knowledge Base: We ingested 4 priority YouTube videos from Next '25 (264 minutes), chunked them into 98 documents with 15-second overlap, embedded them with text-embedding-005 (768 dimensions), and stored them in Firestore with a COSINE vector index. Alex searches this before every factual claim.
Slides: Alex calls generate_slide() which hits imagen-4.0-fast-generate-001. The image is pushed to a queue, drained every 100ms by the WebSocket handler, and displayed with a loading skeleton while generating.
Frontend: Vanilla HTML/CSS/JS with Web Audio API worklets for real-time PCM audio streaming at 16kHz (input) and 24kHz (output). No frameworks.
CI/CD: Cloud Build pipeline with cloudbuild.yaml for automated container builds and deployment.
Challenges we ran into
The Async Deadlock. Our A2A tools initially used synchronous HTTP. But the A2A agents are on the same server, so the sync call blocked the event loop, preventing the server from processing the very request it was waiting for. Fix: switched to httpx.AsyncClient with await.
The Infinite Tool Loop. Gemini Live sometimes called the same tool repeatedly instead of presenting results. Despite prompt guards, the model ignored them. Fix: code-level blocking in tool functions. First call goes through, subsequent identical calls are rejected instantly.
Audio Context Isolation. Transitioning from Maya's voice session to Alex's keynote broke the Web Audio API. The AudioContext from the concierge became stale. Fix: Alex runs on a completely standalone page with its own HTML, JS, and AudioContext. Full page navigation guarantees a clean audio pipeline.
Slide Timing. Imagen takes 2-5 seconds to generate a slide. During that time, Alex is already speaking. Fix: we push a loading skeleton to the client immediately when generate_slide is called, then swap in the real image when it arrives. The audience always sees something.
Session State Leaks. Module-level caches (tool blockers, slide queues) persisted across WebSocket sessions on the same Cloud Run instance. Fix: aggressive cleanup of all module-level state at session start, draining stale queues from previous sessions.
Accomplishments that we're proud of
- 1 LLM call per turn for Alex's keynote (down from 4 in our initial architecture). Context tracking runs via Python callbacks at zero LLM cost.
- The meta-story works. Alex explains ADK while being built with ADK. He describes A2A while his colleague Maya just used A2A. The audience is inside the thing being described.
- Maya can See, Hear, and Speak. All three modalities in one agent: she analyzes photos you share, listens to your voice, and responds conversationally.
- Real data, not hallucinations. Every fact Alex states is grounded in 98 Firestore documents from actual conference transcripts. He says "I don't have that in my notes" when he genuinely doesn't.
- True interruptibility. You can cut Alex off mid-sentence and he pivots naturally. Audio buffer clears instantly via a custom AudioWorklet.
- A2A in production. Two working Agent-to-Agent connections demonstrating the protocol with real agents returning real search results.
What we learned
- The Gemini Live API with native audio is a fundamentally different interaction model than text chat. Designing for voice means thinking in 50-word bursts, strategic pauses, and conversational flow rather than paragraphs.
- A2A is surprisingly elegant for in-process agent orchestration. Mounting agents as JSON-RPC endpoints on the same FastAPI server avoids the complexity of separate services while still demonstrating the protocol.
- Prompt engineering for voice agents is harder than text agents. The model needs explicit anti-repetition guards, word count limits, and rhetorical technique instructions to sound like a presenter rather than a chatbot.
- Session isolation on long-running servers (Cloud Run) requires active cleanup. Module-level Python state persists across requests within the same container instance.
What's next for Next Live
- Live audience mode: Multiple users joining the same keynote session simultaneously, with Alex handling questions from different audience members.
- Personalized keynotes: Alex adapts the presentation based on the attendee's role (developer, executive, data scientist) using information from the travel booking stage.
- More A2A agents: A networking agent that connects attendees with shared interests, a schedule agent that builds personalized session itineraries.
- Agent Engine deployment: Moving from Cloud Run to Vertex AI Agent Engine for managed scaling, monitoring, and production-grade agent lifecycle management.
- Expanding beyond conferences: The same multi-agent architecture (invitation, logistics, presentation) applies to corporate training, product launches, and virtual events.
This project was created for the purposes of entering the Gemini Live Agent Challenge hackathon on Devpost. #GeminiLiveAgentChallenge
Built With
- gcp
- python
- secret
- vertex



Log in or sign up for Devpost to join the conversation.