-
-
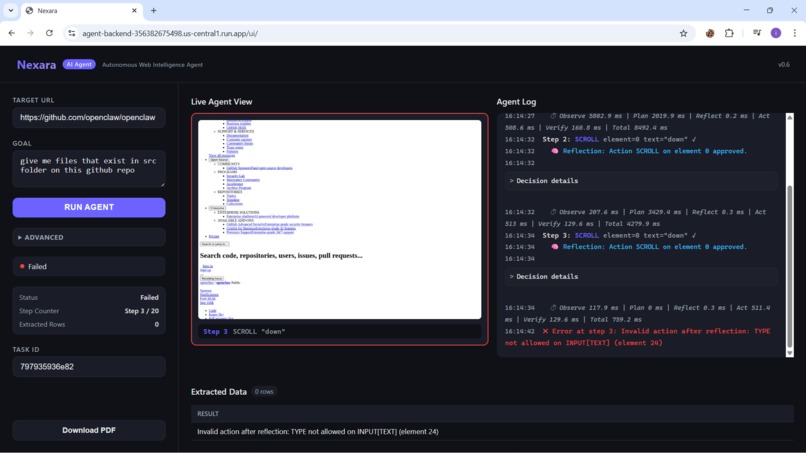
NEXARA agent interface performing autonomous web data extraction
-
Cloud Run deployment dashboard showing the hosted NEXARA backend.
-
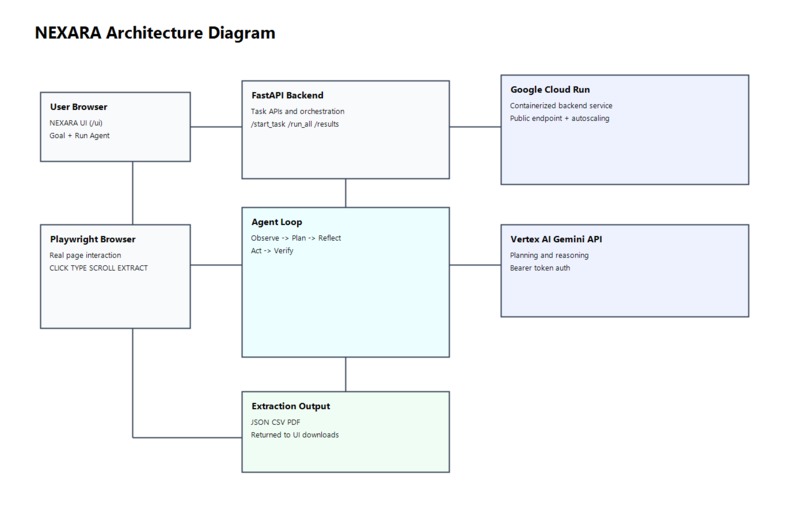
architecture-diagram
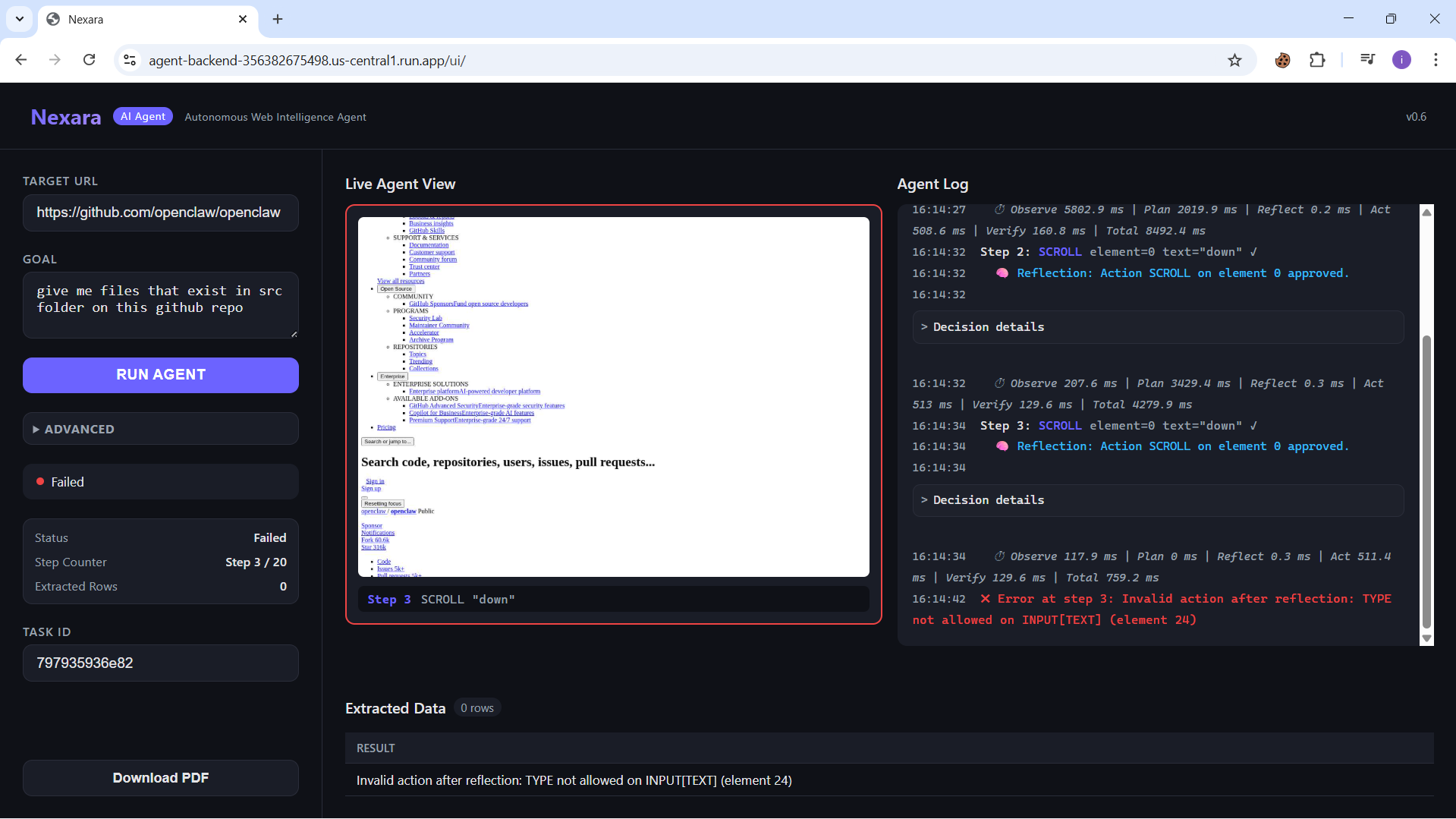
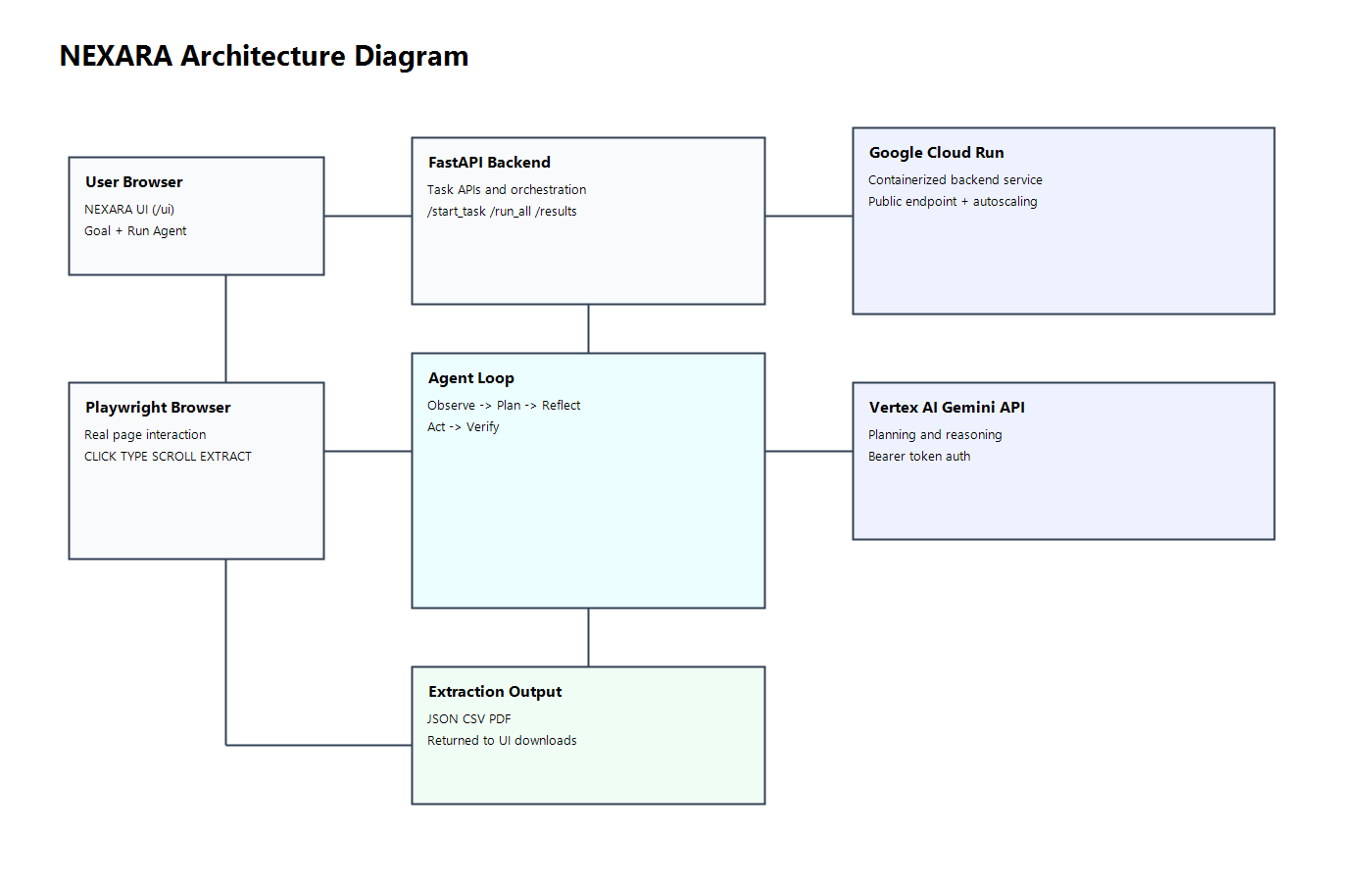
NEXARA is an AI-powered agent that autonomously navigates websites and extracts structured data without fragile selectors.
Built and developed independently as a solo hackathon project.
Inspiration
Anyone who has tried web scraping knows the pain.
You spend hours writing selectors, the script works perfectly… and then the website changes one class name and everything breaks.
Traditional scrapers are fragile because they depend on fixed rules in a constantly changing environment.
A simple question started the project:
What if scraping worked more like a human browsing the web?
A person doesn’t rely on CSS selectors. They look at the page, understand what’s relevant, decide what to click, and adapt if something changes.
That idea became NEXARA — an AI agent that can observe, reason, and extract information from websites autonomously.
Built on Google Cloud using Vertex AI Gemini endpoint with an autonomous browser agent workflow.
What it does
NEXARA is an AI-powered web extraction agent.
Instead of writing scraping code, the user simply provides:
• a website URL • a description of the data they want
The agent then:
Opens the site in a real browser Understands the page content Plans how to extract the requested information Interacts with the page if needed (scrolling, clicking, navigating)
It can handle:
• dynamic websites • JavaScript-heavy pages • multi-step workflows • structured data extraction
The extracted information can be exported in JSON, CSV, or PDF.
In short, NEXARA turns web scraping into an autonomous reasoning task instead of a brittle script.
How it was built
NEXARA combines AI reasoning with real browser automation.
The backend is built with FastAPI, which manages requests and coordinates the agent workflow.
For reasoning and decision-making, Gemini on Vertex AI is used to analyze the webpage and generate plans for extracting the requested data.
For execution, Playwright is integrated to control a real browser environment.
The system runs through an agent loop:
Observe → Plan → Reflect → Act → Verify
This loop ensures the agent evaluates its plan before executing actions, improving reliability and safety.
A lightweight UI allows users to define extraction goals and download results.
Challenges
Building an autonomous extraction system introduced several challenges.
Early versions of the agent often returned generic page information such as titles or URLs instead of the specific data requested by the user.
Another challenge involved enforcing strict output constraints. For example, when users requested “the first 5 results”, the agent sometimes returned more or fewer items.
AI hallucination also had to be addressed. When requested information was missing from the page, the model sometimes attempted to infer or fabricate results.
To prevent this, deterministic verification logic was added so the system clearly returns “not found” instead of guessing.
Deploying Playwright reliably in a cloud environment also required careful browser configuration and tuning.
Accomplishments
NEXARA successfully demonstrates autonomous structured data extraction from real-world dynamic websites.
The system produces consistent results while enforcing deterministic limits and reducing hallucination risks.
The project includes a full working workflow consisting of:
• hosted API • interactive UI • structured data exports • deployment on cloud infrastructure
This makes NEXARA more than a prototype — it is a functional system.
What was learned
Developing an AI agent highlighted the importance of guardrails, not just model intelligence.
Without verification and constraints, even powerful models can produce unreliable outputs.
Extraction quality improves significantly when the system dynamically adapts its context instead of relying on rigid rules.
Cloud deployment also revealed how important architecture decisions are when combining LLMs, browser automation, and APIs.
What's next for NEXARA
Future improvements include supporting authenticated workflows so the agent can operate on logged-in platforms and protected dashboards.
Multi-page crawling and memory will also be improved so the system can gather information across entire websites rather than single pages.
Additional benchmark datasets and evaluation metrics will be introduced to measure extraction reliability across domains.
The long-term goal is to develop an AI agent capable of reliably understanding and extracting information from the web at scale.
Built With
- css
- fastapi
- google-cloud-run
- html
- javascript
- playwright
- python
- vertex-ai-(gemini)

Log in or sign up for Devpost to join the conversation.