-
-
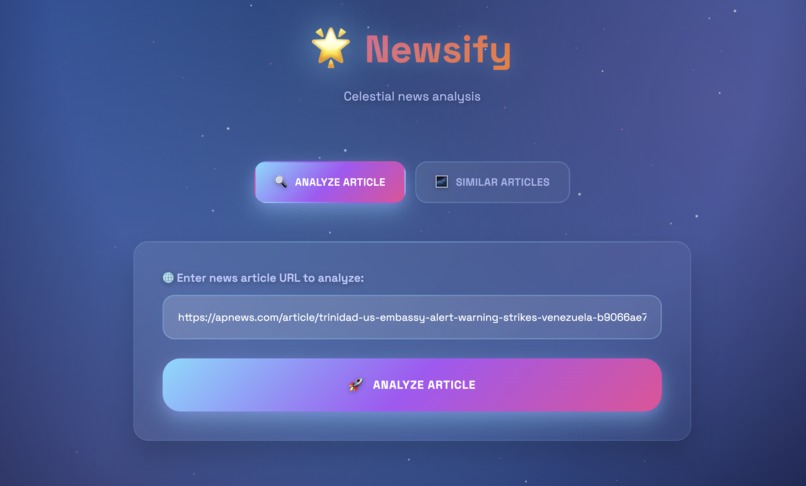
Home Page of Newsify
-
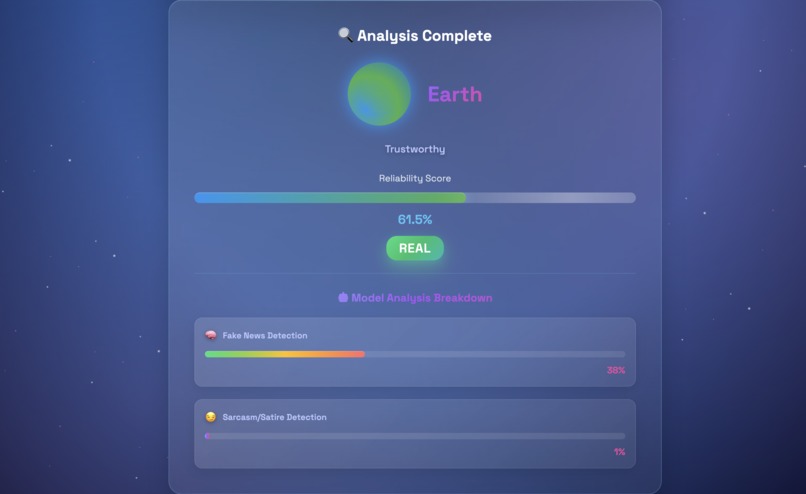
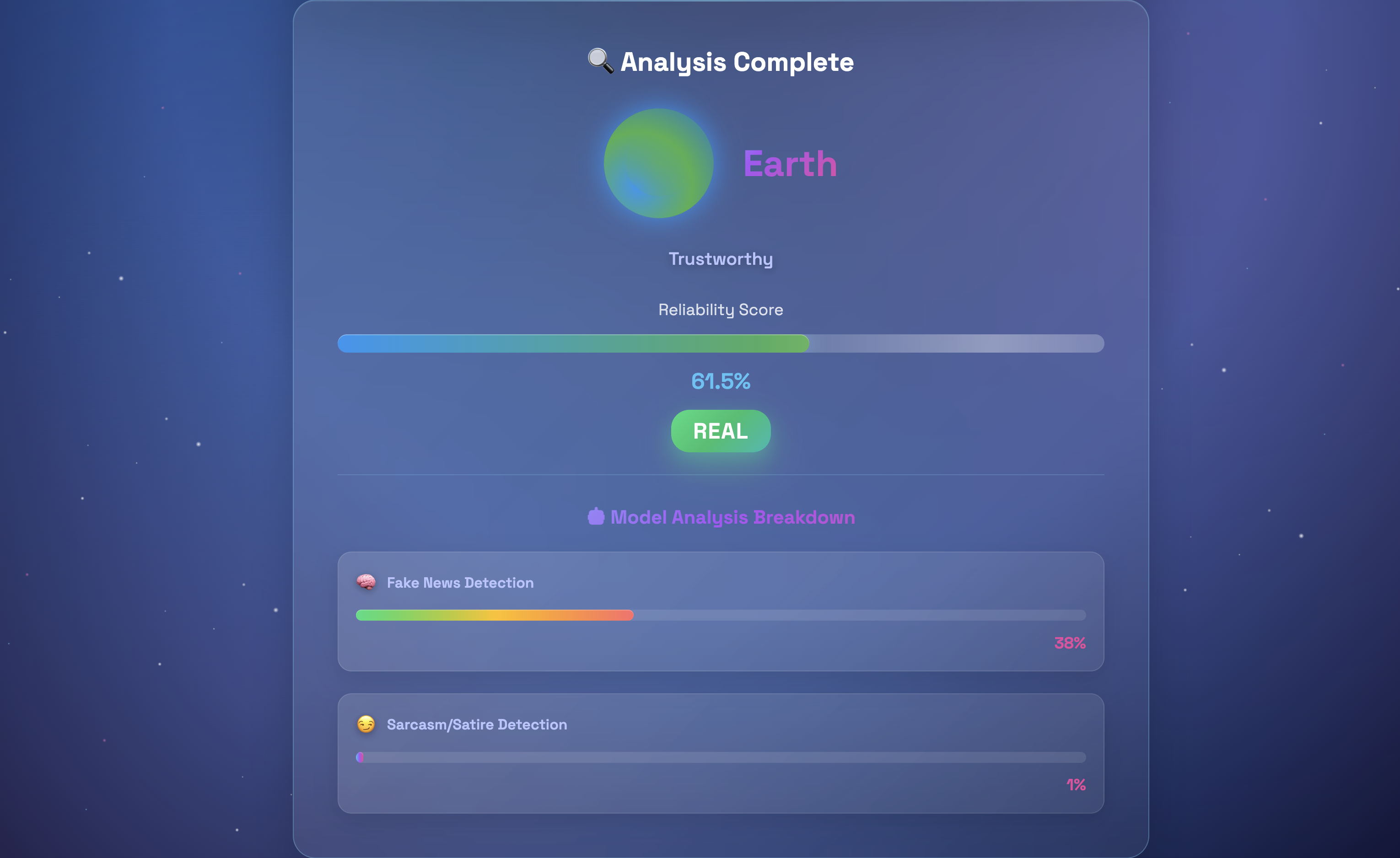
Analysis Overview
-
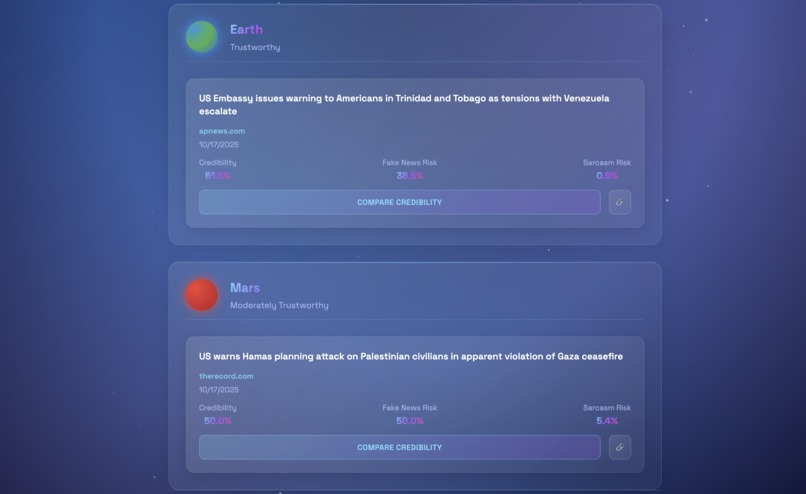
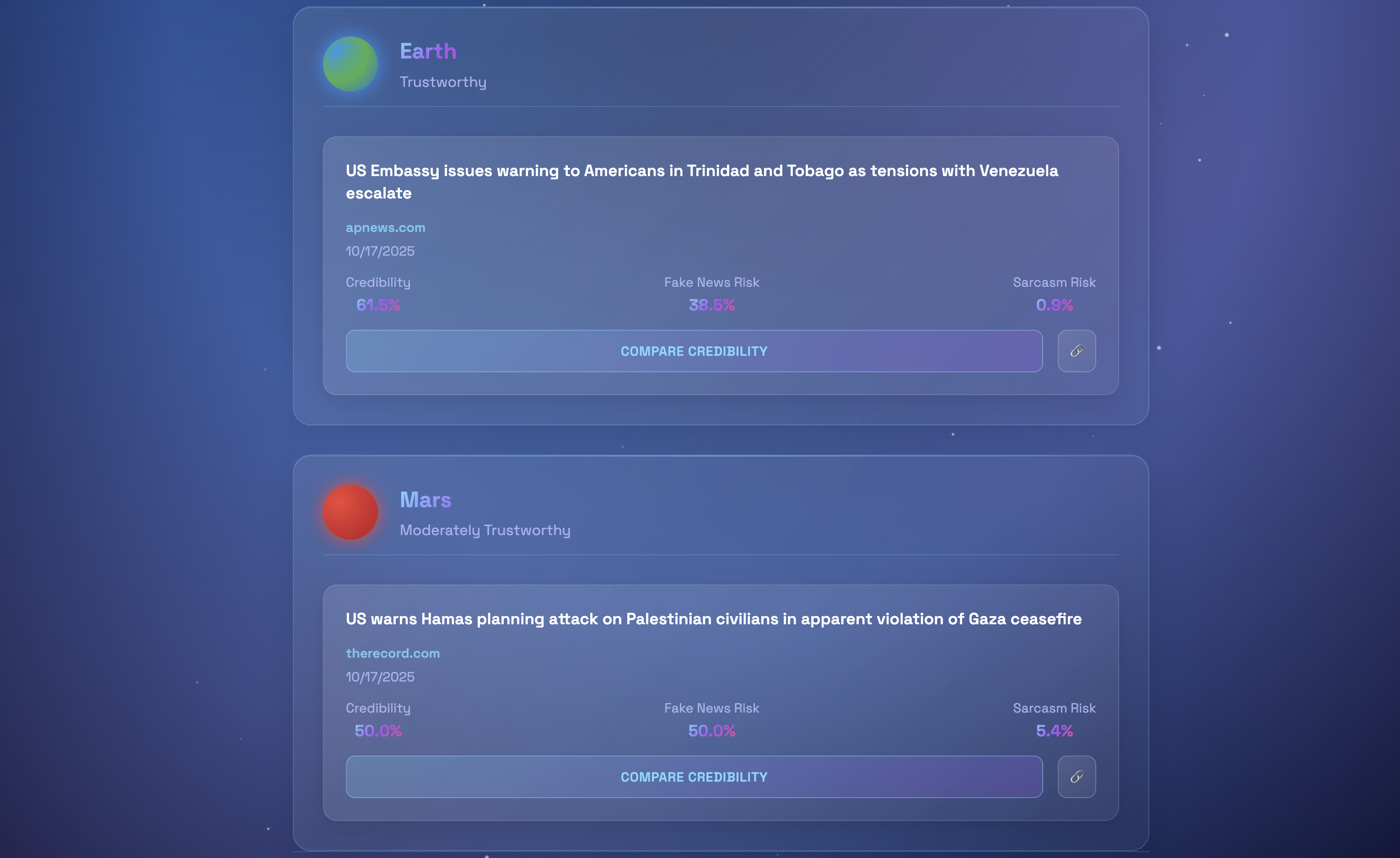
Similar Articles
Inspiration
Many of our family members often had trouble distinguishing between real news, satire, and misinformation. Watching that confusion firsthand inspired us to build Newsify, a tool that analyzes articles and helps users quickly understand whether they can be trusted.
What it does
Newsify evaluates any news article and assigns it a credibility score between 0.0 and 1.0, represented through a solar system metaphor:
- Sun (0.0): Highly trustworthy content
- Neptune (1.0): Likely misinformation or satire
Rather than simply saying an article is "real" or "fake," Newsify explains why. It uses two detection models, one for misinformation and one for satire, to give users a more transparent and detailed view of an article's credibility.
The Technology
Our backend combines multiple systems to ensure reliable and efficient analysis:
Dual-Model Architecture:
- A BERT-based fake news detector trained on over 40,000 articles for accurate classification.
- A sarcasm detector trained specifically for satirical writing, which helps identify articles from sources like The Onion.
- A BERT-based fake news detector trained on over 40,000 articles for accurate classification.
Smart Text Processing:
- Automatically extracts article text and removes ads, navigation bars, and other webpage clutter.
- Filters out sentences shorter than 20 words to eliminate headlines and fragments.
- Splits long articles into 512-token chunks so that BERT can analyze each part without losing context.
- Automatically extracts article text and removes ads, navigation bars, and other webpage clutter.
Real-World Optimization:
- In-memory caching prevents reanalyzing duplicate articles.
- GPU/CPU auto-detection adjusts performance to the user’s system.
- Robust error handling manages connection issues, broken URLs, and failed extractions.
- In-memory caching prevents reanalyzing duplicate articles.
How we built it
We began by evaluating several pre-trained models since training one from scratch was not feasible within our time frame. After testing various options, we found a model that balanced accuracy and practicality. From there, we built and refined the backend step by step, running frequent tests and improving based on our results.
Challenges we ran into
Model Selection
One of the toughest challenges was choosing a reliable model. Training a new one would have required massive datasets and computational power we didn’t have. We experimented with several models from Hugging Face. Some, like Pulk17/Fake-News-Detection, misclassified legitimate sources as fake. Others, like jy46604790/Fake-News-Bert-Detect, showed strong bias toward labeling everything as false.
Eventually, mrm8488/bert-tiny-finetuned-fake-news-detection proved the most balanced across diverse sources.
The Satire Problem
Our initial model often labeled satirical content as real. Articles from The Onion were being marked as legitimate 95% of the time. To fix this, we introduced a second model, helinivan/english-sarcasm-detector, trained specifically to identify sarcastic and humorous tones.
While it occasionally flagged legitimate opinion pieces, combining both models gave us the best results. If either model detected suspicious content, we took the higher score, ensuring that potential misinformation was not overlooked.
The Chunking Issue
At first, we only analyzed the first 512 tokens of each article due to BERT’s input limit. This caused long articles to lose context. Implementing chunking allowed us to analyze all parts of an article and then average the results.
However, this led to inconsistent scores between chunks, which revealed another issue: our input data still contained unwanted elements like ads and navigation text.
Content Cleaning: The Real Fix
We solved this by strengthening our text preprocessing. We implemented:
- Sentence-level filtering that ignored anything under 20 words
- Removal of common spam keywords and leftover HTML artifacts
- Smarter extraction logic using BeautifulSoup to specifically target article containers
With cleaner data, the models’ accuracy improved dramatically. Reliable sources like CNN stopped being misclassified, and satire was detected more consistently.
MediaCloud Integration
We integrated the MediaCloud API to surface related articles and group them by credibility. To ensure relevant results, we built a custom scoring algorithm that:
- Prioritizes exact phrase matches
- Rewards results with multiple matching keywords
- Penalizes overly long or vague titles
- Expands searches semantically (for example, "climate change" includes terms like "emissions" or "greenhouse gases")
Accomplishments we’re proud of
We are proud of how much the accuracy improved throughout development. In early tests, legitimate sources were often flagged as fake. By refining our data cleaning and chunking strategies, we achieved consistent and realistic scoring. Filtering out short, irrelevant text significantly reduced false positives and improved our overall performance.
What we learned
The biggest lesson was simple: garbage in, garbage out. Clean input data matters far more than fancy models or fine-tuning. Preprocessing, extraction, and validation directly impacted our success.
We also learned that perfection should not delay progress. Combining two imperfect models into a reliable system gave us better real-world results than trying to perfect one.
What's next for Newsify
Our next step is to publish the Chrome Extension on the Google Web Store. The plan is straightforward:
- Prepare the listing with screenshots, a demo video, and required icons (16x48x128px).
- Write a concise description explaining our dual-model approach.
- Pay the $5 developer fee and complete the 1-3 day review process.
After launch, we’ll focus on gathering user feedback, fixing edge cases, and continuously improving detection accuracy based on misclassification reports.
Built With
- beautiful-soup
- huggingface
- javascript
- python
- pytorch



Log in or sign up for Devpost to join the conversation.