-
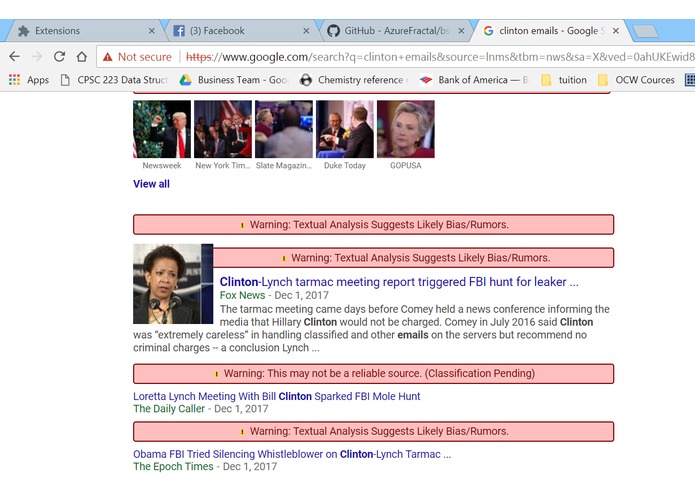
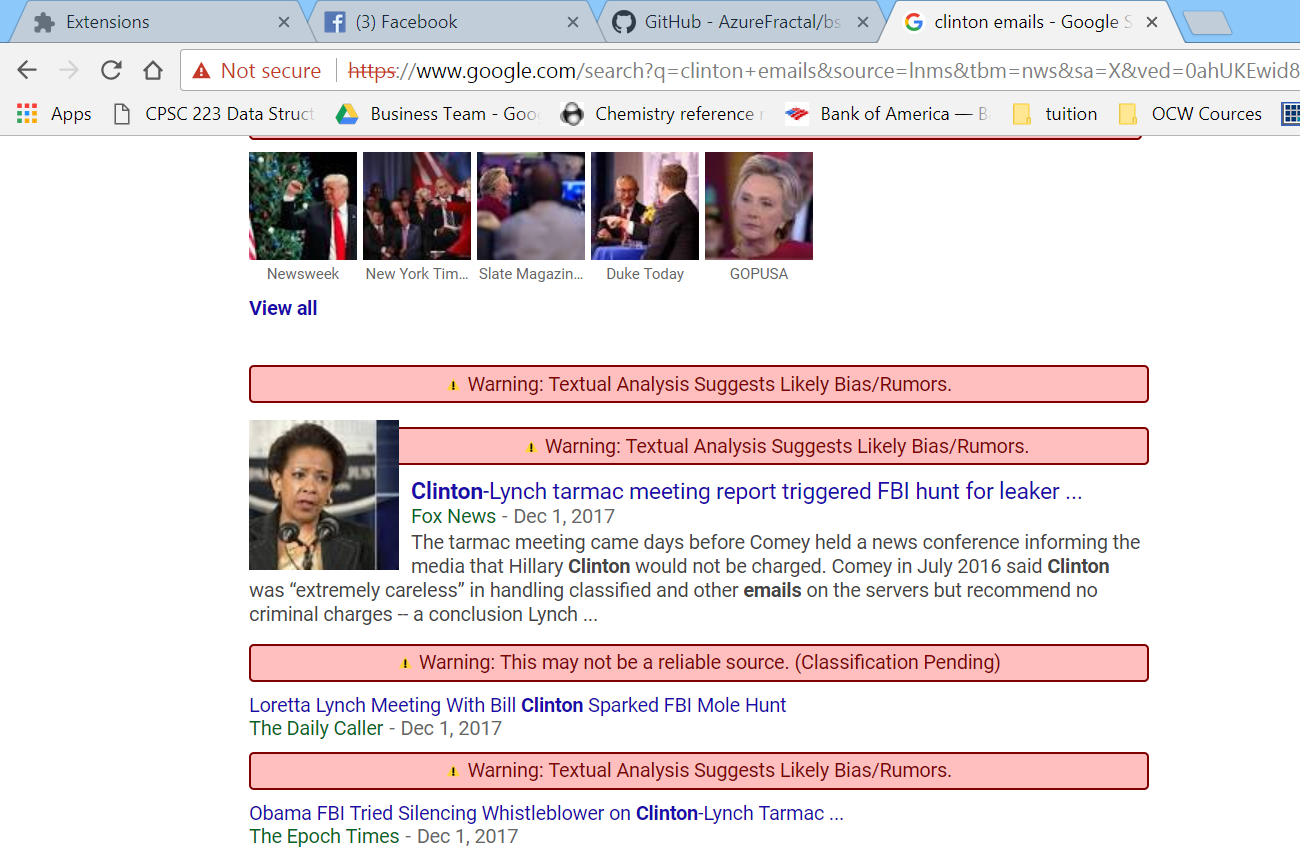
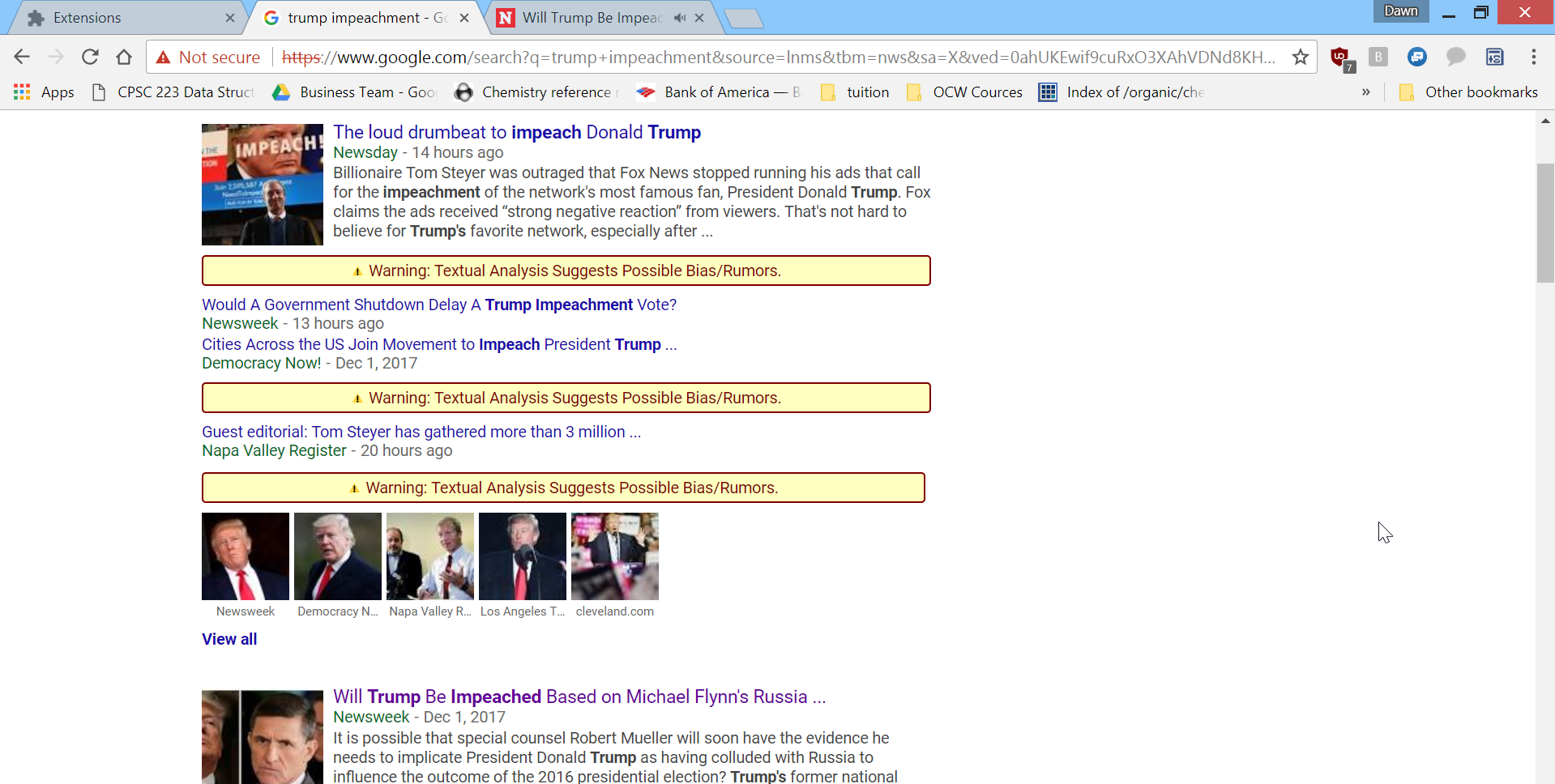
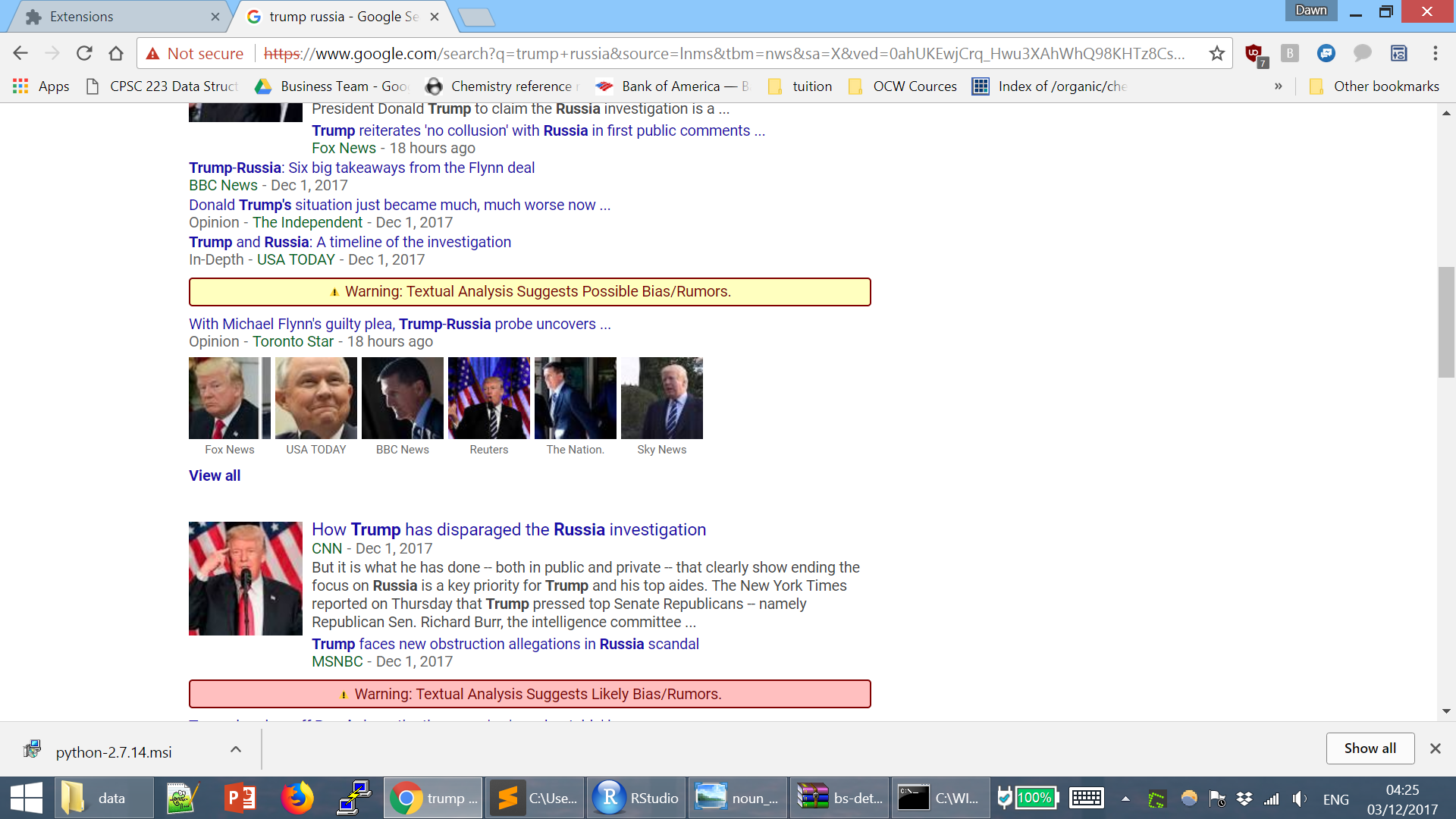
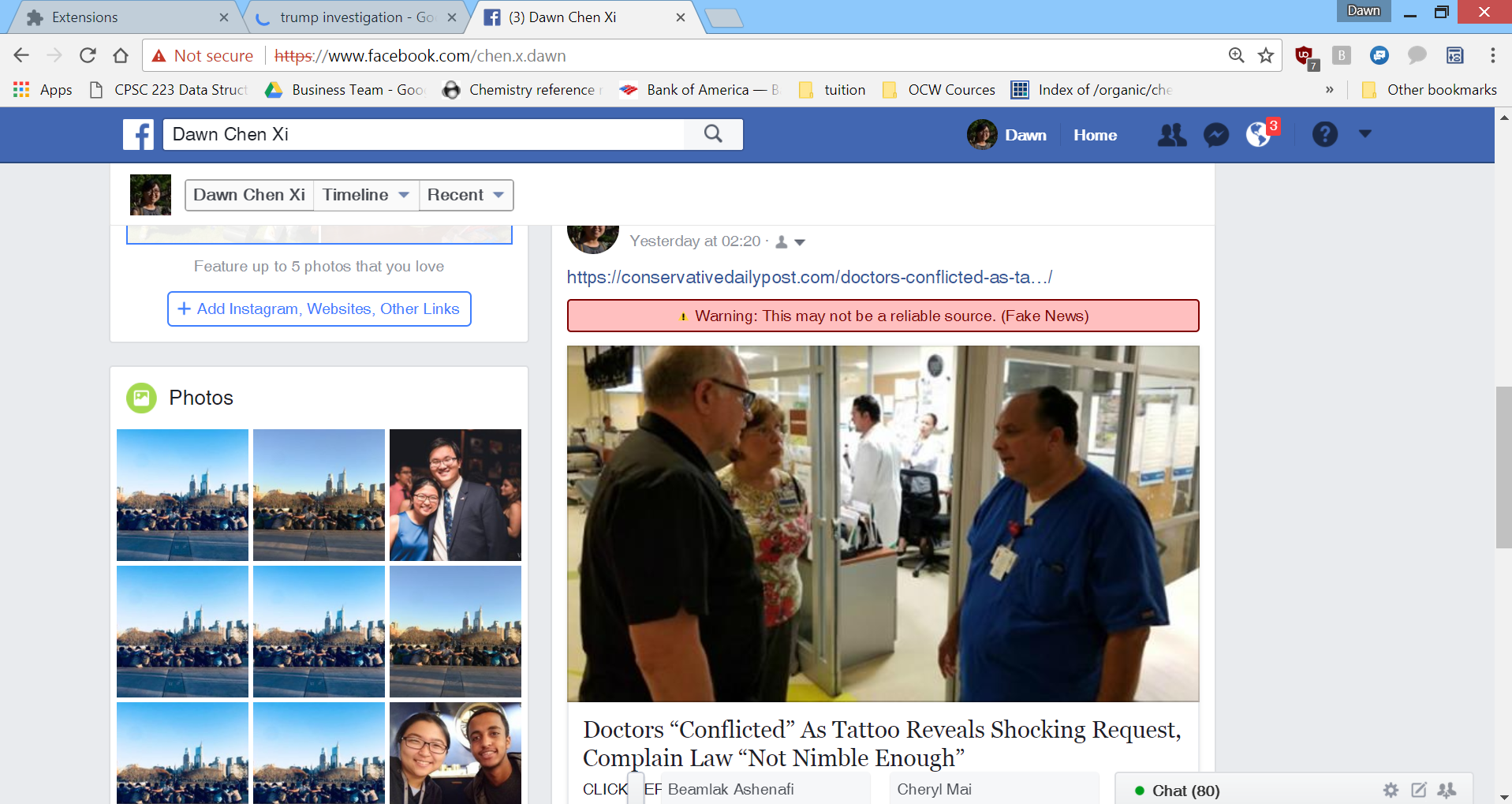
Unreliable sources are marked as red
-
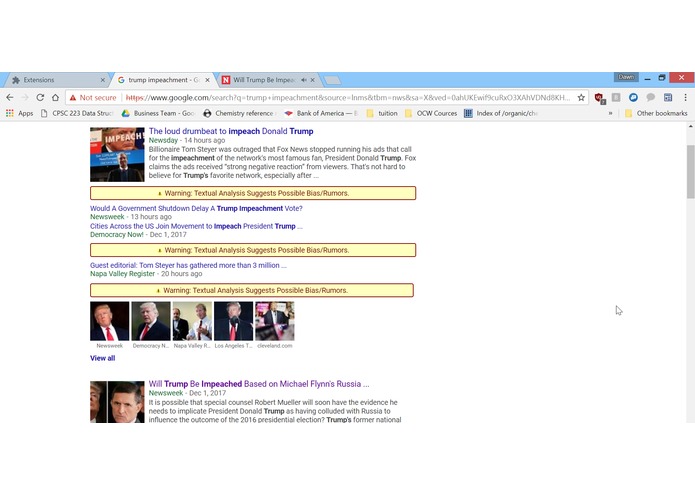
News that are not from reliable sources are analyzed for the quality of their title and text, giving a yellow warning message for bad source
-
-
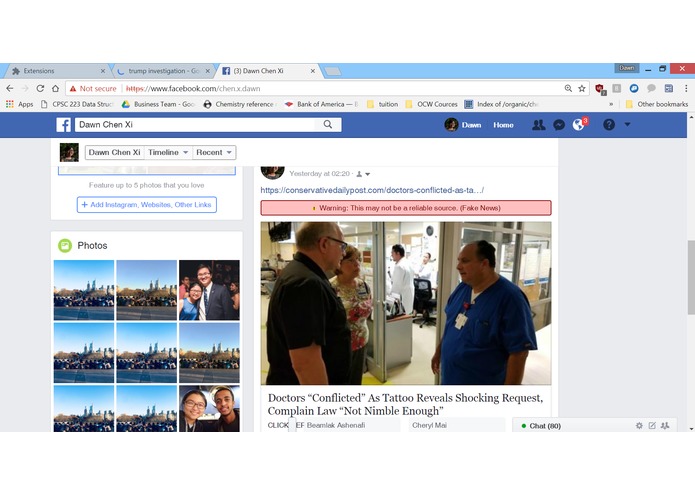
Works for Facebook too!
Inspiration
2017 is the year of fake news. Although fake news is not a new phenomenon, extremely biased and false information has found a safe haven to grow and thrive in this age of interconnected, web-based global community. Anyone with a laptop can now create false content and anyone with a smartphone can now share it. Recent developments in politics have brought fake news into the limelight. Some politicians are deliberately blurring the line between real news and fake news by denouncing real news as fake and sharing fake news as real.
The problem is, fake news doesn’t always come in the form of full-fledged conspiracy websites like InfoWars or Occupy Democrats. It disguises itself and creeps into our search results and news feeds with seemingly real names like “Boston Tribune” and “World True News.” Fake news occupies the special niche of allowing people to read the stories they wish they could read. The incognito fake news and its special niche in human emotion often make it more shared and clicked on than real news. For example, the fake “Boston Tribune” is more popular than the rea Yahoo News.
Humans are emotional beings and thus, we often have trouble deciphering fake news especially when we agree with the story. Hence, we need a way to independently determine the veracity of fake news.
What it does
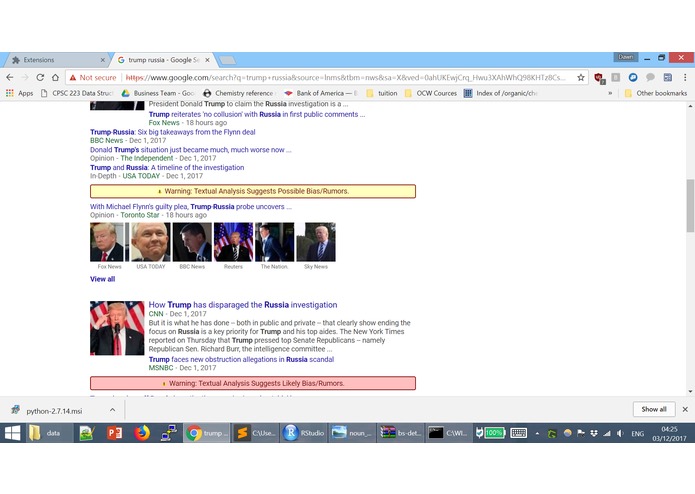
NewsCheck is a web extension that analyzes, in real-time, any links to news articles present on a user’s webpage. For example, such links include those returned by Google search results, or social media links shared by others. NewsCheck’s algorithm analyzes the articles of these links based on their domain, title, and content, and if any them are deemed to be likely biased or fake, they are flagged out to the user. This flag is a color-coded message based on statistical confidence intervals, displayed beside these link in question to alert the user of the possibility of fake news. For instance, a message could read Warning: Textual Analysis Suggests Likely Bias/Rumors.
NewsCheck thereby allows users to be more discerning towards articles that are likely to be fake news, by priming them with the possibility of it being fake news even before they start reading it (if they then choose to do so). This minimizes the risk of a fake news article being able to play to the users’ emotions to convince them of its truth, as compared to a situation whereby users read the article without any conscious awareness that it could be fake news.
How we built it
NewsCheck was developed upon an existing open-source project, B.S. Detector. B.S. Detector is a currently available browser extension that searches all links on a given webpage for references to unreliable sources, where “unreliable” is determined by checking against a manually pre-compiled list of domains that are deemed to be unreliable or otherwise questionable.
Piggybacking off the Javascript used in B.S. Detector, we captured all links on a given webpage, and piped these links to our local Python HTTP server, where we conducted two separate strands of analysis (written in Python).
The first strand of analysis involves applying Natural Language Processing techniques to the article’s title. By converting the titles as textual strings into a Document-Term Matrix, NewsCheck projects the words onto a 30-dimensional vector space and compares an article’s vectors to that of a trained data set. This gives a likelihood that an article is fake news, based on the wording of its title (e.g. whether it contains emotionally charged words).
The second strand of analysis involves a regression analysis on various contextual parameters of the article’s contents, such as the average sentence length, the average word length, and the number of exclamation points and question marks used in the article. By comparing an articles’ parameters to a regression model trained on about 1000 each of real and fake news, this analysis gives us an independent likelihood that an article is fake news, based on the contextual parameters of its contents.
After combining the likelihoods of the article being fake news from domain analysis (from B.S. Detector), title analysis, and content analysis, we again piggyback the open-source Javascript to display color-coded messages to the user beside the links.
Challenges we ran into
The main challenge in creating NewsCheck was the difficulty in obtaining a large and clean data set to train and test our model via Natural Language Processing techniques. In particular, we were able to find a large data set of news article titles for 2015-2016 from Kaggle, but we were unable to find a similar data set for the contents of the articles.
Further, because articles from different domains were typically formatted differently and sometimes encoded differently (in HTML), it was a challenge to scrape clean data to use as our data set for regression analysis on contextual parameters of the article’s contents. Often, we had to make domain-specific tweaks to our Python code for scraping article contents, in order to obtain the cleanest data possible, which was time consuming.
Accomplishments that we’re proud of
We’re proud of the fact that we have managed to create a seamless data flow between the front-end user interface and the back-end data processing, with a turnaround time of only a few seconds. Considering that NewsCheck is doing intensive regression analysis of articles in the back-end, being able to seamlessly pipe the data between the front-end and the back-end via a Python HTTP server, such that color-coded messages can be displayed to the user in real-time, is a major accomplishment that we are proud of.
What we learned
It is somewhat surprising to us, that NewsCheck is able to perform so well in terms of identifying fake news from real news, even though it only considers the wording of its title and contextual parameters of its content. For example, for the regression analysis of the Natural Language Processing of article’s titles, our model had a training accuracy of 96.8% and a testing accuracy of 92.6%.
That is, we learnt that even though fake news is prevalent on the web in this age, it is not difficult to discern fake news from real news, as long as we keep a critical eye. The success of NewsCheck indicates that the differences between fake news and real news extends far beyond just the factual content of the article, into the writing style and linguistic parameters of the article.
What’s next for NewsCheck
First, the obvious step for an improvement for NewsCheck would be to increase the size of the data set that we are training it on, and the number of contextual parameters that we are considering, in order to derive a better regression model and get higher confidence intervals when we return the likelihood of an article being fake news to users.
However, beyond this, a more crucial and fundamental flaw of our current version of NewsCheck, is that it is still unable to check for the truth of specific facts in the article (literal fact-checking). Therefore, anyone who knows the specific back-end regression model of NewsCheck will be able to craft a well-written but fake news article that will pass the test of NewsCheck easily.
Therefore, an important next step to improve NewsCheck (but not an easy one) would be to integrate factual analysis. That is, to allow NewsCheck to extract single pieces of factual information from articles (e.g. “UK Prime Minster Theresa May is due to meet EU Commission President Jean-Claude Juncker on Monday”), then to conduct independent online searches to verify these facts, and finally to use these verifications to re-evaluate the likelihood of an article being fake news.
Built With
- javascript
- nltk
- python
- sckit-learn
- spacy
- text2vec


Log in or sign up for Devpost to join the conversation.